本文主要是介绍详解IPFS技术架构与应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
IPFS是什么?
星际文件系统(InterPlanetary File System)
本质上是一种内容可寻址、版本化、点对点超媒体的分布式存储、传输协议,目标是补充乃至取代过去20年里使用的超文本媒体传输协议(HTTP),希望构建更快、更安全、更自由开放的互联网时代。
Ipfs最核心的技术是p2p,原来是中心化的服务器在分发内容,现在我们想要下载某一个内容,可以直接建立一个连接,也可以跟其他人连接,迅雷也是这种模式,它是一个虚拟的p2p中心网络,这里不多细讲。
为什么需要IPFS?
HTTP的中心化是低效的, 并且成本很高
油管上,鸟叔的“江南style”这个视频,累计被播放30亿次,假设这个文件100MB大小,则播放这个视频浪费300Petabytes(1P=1,000,000GB)的网络流量,按照0.01USD/GB算CDN成本,谷歌将支付300W美金给ISP服务商。
使用HTTP协议每次需要从中心化的服务器下载完整的文件(网页, 视频, 图片等), 速度慢, 效率低。如果改用P2P的方式下载, 可以节省近60%的带宽。
Web文件经常被删除
http的页面平均生存周期大约只有100天,Web文件由于存储成本太高经常被删除,无法永久保存。
IPFS提供了文件的历史版本回溯功能(就像git版本控制工具一样), 可以很容易的查看文件的历史版本, 且数据无法删除,可以得到永久保存。
中心化限制了web的成长
现在使用的互联网其实是由数百万个分布在世界各地的服务器构成的。世界最大的芯片制造厂商 Intel 有大约10万台服务器,Facebook有3万台,美国最大的电话公司 AT&T 也有2万台,而 Google有超过100万台服务器。
在现有的http协议下,所有的数据都保存在这些巨头的服务器上,这是高度中心化的。巨头不但对我们的数据有绝对的控制权和解释权,各种各样的监管,封锁,监控一定程度上也极大的限制了创新和发展。
建立在去中心化的分布式网络上的IFPS很难被中心化管理和限制,互联网将更加开放。
互联网应用高度依赖互联网主干网
过于中心化,为了支撑http协议,服务器7*24小时开启,对于大流量公司,比如百度、腾讯、阿里等,投入大量资源维护服务器和安全隐患,防止DDoS,XSS,CSRF等攻击。
主干网络受制于战争,自然灾害,中心服务器宕机等因素,都可能造成整个互联网中断服务。
IPFS可以极大的降低对中心主干网络的依赖。
IPFS如何工作?
IPFS为每一个文件分配一个独一无二的哈希值(文件指纹: 根据文件的内容进行创建), 即使是两个文件内容只有1个比特的不相同,其哈希值也是不相同的。所以IPFS是基于文件内容进行寻址, 而不像传统的HTTP协议一样基于域名寻址。
IPFS在整个网络范围内去掉重复的文件, 并且为文件建立版本管理, 也就是说每一个文件的变更历史都将被记录(这一点类似版本控制工具git,svn等), 可以很容易个回到文件的历史版本查看数据。
当查询文件的时候, IPFS网络根据文件的哈希值(全网唯一)进行查找。 由于每个文件的哈希值全网唯一, 查询将很容易进行。
如果仅仅使用哈希值来区分文件的话,会给传播造成困难,因为哈希值不容易记忆,就像ip地址一样不容易记忆,于是人类发明的域名。IPFS利用IPNS将哈希值映射为容易记的名字。
每个节点除了存储自己需要的数据,还存储了一张哈希表, 用来记录文件存储所在的位置,用来进行文件的查询下载。
IPFS的架构
IPFS 协议栈
身份 S/Kademlia生成 对等身份信息生成
网络 任意传输层协议 ICE NET & NAT穿透
路由 分布式松散哈希表(DSHT) 定位对等点和存储对象需要的信息
交换 BitTorrent& BitSwap 管理区块如何分布
对象 Merkle-DAG 内容可寻址的不可篡改、去冗余的对象链接
文件 类似Git 版本控制的文件系统:blob,list, tree, commit
命名 具有SFS(Self-CertifiedFilesystems)IPNS:DAG对象命名可变
应用 在IPFS上运行的应用程序利用最近节点提供服务提供效率、降低成本
身份层和路由层
对等节点身份信息的生成以及路由规则是通过Kademlia协议生成制定,KAD协议实质是构建了一个分布式松散Hash表(distributedhash table),简称DHT,每个加入这个DHT网络的人都要生成自己的身份信息,然后才能通过这个身份信息去负责存储这个网络里的资源信息和其他成员的联系信息。
网络层
LibP2P可以支持任意传输层协议。
ICE NAT traversal框架整合STUN、TURN和其他类型的NAT协议,该框架可以让客户端利用各种NAT方式打通网络,从而完成NAT通信,这对于IPFS的p2p网络非常重要。
交换层
类似迅雷这样的BT工具,IPFS团队把BitTorrent进行了创新,叫作Bitswap,它增加了信用和帐单体系来激励节点去分享,用户在发送给其他节点数据可以增加信用值,从其他节点接受数据降低信用值。如果用户只去接收数据而不分享数据,信用分会越来越低而被其他节点忽略掉。
对象层和文件层
共同管理IPFS上80%的数据结构。
大部分数据对象都是以MerkleDag的结构存在,这为内容寻址和去重提供了便利。
文件层是一个新的数据结构,和DAG并列,采用Git一样的数据结构来支持版本快照。
命名层
具有自我验证的特性(当其他用户获取该对象时,使用指纹公钥进行验签,即验证所用的公钥是否与NodeId匹配,这验证了用户发布对象的真实性,同时也获取到了可变状态),并且加入了IPNS这个巧妙的设计来使得加密后的DAG对象名可定义,增强可阅读性。
应用层
IPFS核心价值就在于上面运行的应用程序,可以利用它类似CDN的功能,在成本很低的带宽下,去获得想要的数据,从而提升整个应用程序的效率。
IPFS家族
IPFS项目其实很大,并不是一个东西,IPFS是由很多模块组成,每一个模块现在都已经独立成项目了,并且有自己的主页。
协议实验室的主页:https://protocol.ai/projects/
在协议实验室的主页上面,可以找到目前的五个项目,来简单看一下IPFS家族成员:

Filecoin
IPFS只是一个协议, 并不是挖矿软件本身。Filecoin系统才是挖矿软件本身, 代币名字是 FIL。Filecoin使用了IPFS 协议来运行系统。
FIL代币总共有20亿枚。分配方案,总共有四个部分组成:
70%作为挖矿的回报:像比特币一样根据挖矿的进度逐步分发
15%预留Protocol Labs:作为研发费用, 6年逐步解禁
10%分配给ICO投资者: 根据挖矿进度, 逐步解禁
5%预留给Filecoin基金会: 作为长期社区建设, 网络管理等费用, 6年逐步解禁
私募时间:2017.07.21-2017.7.24
成本:0.75美元
行权期:1-3年,折扣额0-30%
参与人数:150+人
募集金额:0.52亿美元
公募时间:2017.08.07-2017.09.07
成本:1-5美元
行权期:1-3年,折扣额0-30%
参与人数:2100+人
募集资金:2.05亿美元
Filecoin与挖矿市场
Filecoin存储市场(Filecoin Storage Market)
数据存储市场所需要贡献的就是硬盘存储空间,越多的硬盘空间,挖矿能力就越高,存储市场采用的工作量证明是PoS(Power of Storage)证明,根据存储的数据大小来按比例分配FIL
Filecoin数据检索市场(Filecoin's Retrieval Market)
数据检索市场贡献带宽,根据访问数据的流量来分配FIL
Filecoin场景
用户场景:
1.用户提交数据存储订单(PUT)给Filecoin系统
2.用户提价数据检索订单(GET)给Filecoin系统
3.如果上述订单达成,用户支付FIL以获取相应的服务
存储矿工场景:
1.在区块链上注册自己硬盘空间,注册完成后硬盘空间将被记录到区块链的配置表里面
2.接受订单,用户提交的存储订单(PUT)
3.订单交易达成后,双方对交易进行签名,矿工完成数据存储,交易完成后该交易被记录到区块
4.用户获取到对应的支付
检索矿工场景:
1.接受订单,用户提交数据查询订单(GET)
2.交易达成后,双方对交易进行签名,矿工把数据发送给用户,该交易提交到区块
Filecoin证明
数据持有性证明(Provable Data Possession ,PDP):用户发送数据给矿工进行存储,矿工证明数据已经被自己存储,用户可以重复检查矿工是否还在存储自己的数据
可检索证明(Proof-of-Retrievability,PoRet):和PDP过程比较类似,证明矿工存储的数据是可以用来查询的
存储证明(Proof-of-Storage ,PoS):利用存储空间进行的证明。工作量证明的一种,Filecoin上一篇论文使用了这个名字,新的论文则升级为PoRep
复制证明(Proof-of-Replication,PoRep):新的 PoS(Proof-of-Storage),PoRep可以保证每份数据的存储都是独立的,可以防止女巫攻击,外源攻击和生成攻击
工作量证明(Proof-of-Work,PoW):证明者向检验者证明自己花费了一定的资源,PoW被用在加密货币,拜占庭共识和其他各种区块链系统。BTC使用的就是这种类型的证明,依赖巨量的哈希计算和能源消耗来建立共识和保证btc网络的安全性
空间证明(Proof-of-Space,PoSpace):Filecoin提出的概念,存储量的证明,PoSpace是PoW的一种,不同的是PoW使用的计算资源,而PoSpace使用的是存储资源
时空证明(Proof-of-Spacetime,PoSt):时空证明,矿工证明自己花费了spacetime资源,即:一定时间内的存储空间的使用,PoSt是基于PoReps实现的
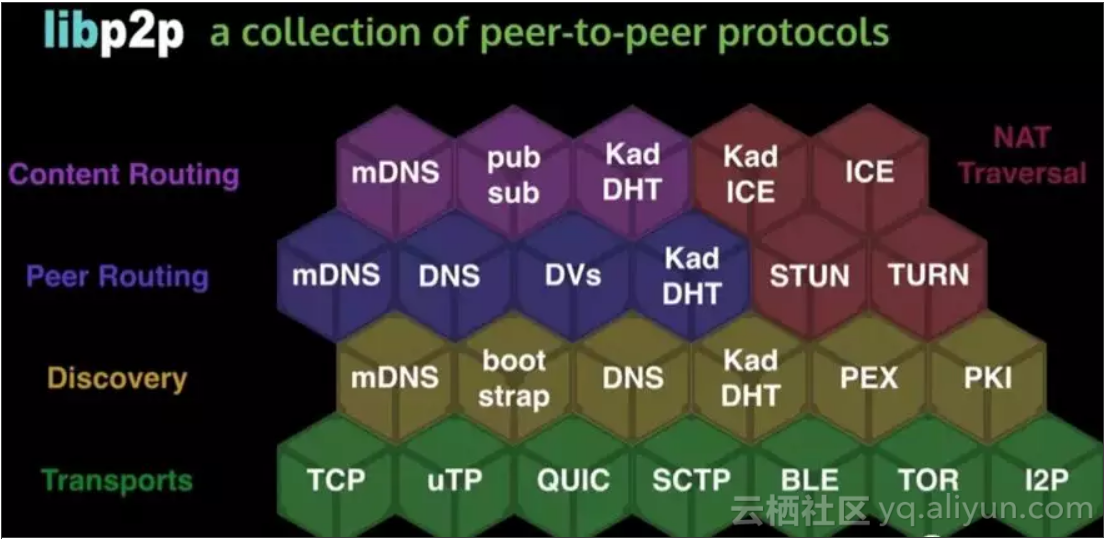
Libp2p
IPFS团队将点对点(peer-to-peer)网络的网络层从IPFS工程里面分离出来,形成一个独立的项目,这就是libp2p。该项目不仅可以供IPFS使用,也可以提供其它项目使用,作为一个p2p工程的底层协议存在。
主要功能:
发现节点
连接节点
发现数据
传输数据
IPLD
IPLD定义了基于内容寻址的统一数据结构类型。它是一个转换器,可以把现有的异构的数据结构(基于内容寻址)统一成一种格式,方便不同系统之间的数据交换和互操作。
通过哈希进行内容寻址的技术已经广泛应用于各种分布式系统。从加密货币的区块链到备份代码的每一次提交,再到各种web内容,他们背后的逻辑几乎是相同的,然后由于数据结构的不兼容,造成了这些数据无法互相操作。IPLD作为中间层统一了这些异构的数据结构,使得不同的数据可以进行数据交换。
IPLD的组成:
CID(Self-describingcontent-addressed identifiers for distributed systems):基于内容寻址的自我描述标识
IPLDtree:基于 JSON、Protobuf和路径导航的跨协议的数据模型
IPLD Resolvers: IPLD转换器,可以添加新的协议到IPLD里面
Multiformats
Multiformats是一系列协议的集合,它在现有协议基础上对值(值:通常是具有某一项表达意义的)进行自我描述改造,即从值上就可以知道该值是如何产生的。
当前multiformats协议里面包含以下协议。
multihash- self-describing hashes
multiaddr- self-describing network addresses
multibase- self-describing base encodings
multicodec - self-describingserialization
multistream- self-describing stream network protocols
multigram(WIP) - self-describing packet network protocols
通常情况下我们使用的哈希计算方法都是某一种实现方式,比如sha1,sha2-256等。哈希计算在软件工程里面几乎随处可见,特别是区块链项,multiformats将所有的哈希值计算统一成同样的格式,为系统开发带来很多好处
以multihash为例:
升级后的哈希值的结构为:
<hash-func-type><digest-length><digest-value>
<哈希函数类型><摘要长度><摘要值>
有一个使用sha2-256函数生成的哈希值(如下),其长度为32(16进制0x20):
41dd7b6443542e75701aa98a0c235951a28a0d851b11564d20022ab11d2589a8
规定sha2-256的代表数字为12(16进制),于是得出来新的哈希值:
122041dd7b6443542e75701aa98a0c235951a28a0d851b11564d20022ab11d2589a8
新的哈希值具有自我描述性质,它说明了自己是怎么来的
IPFS应用及意义
可以为内容创作带来一定的自由
代表应用:
Akasha( https://blog.akasha.world )是一个基于以太坊和IPFS的社交博客创作平台,用户创作的博客内容通过一个IPFS网络进行发布,而非中心服务器。
同时,用户和以太坊钱包账户进行绑定,用户可以对优质内容进行ETH打赏,内容创作者能以此赚取ETH,如同人脑挖矿一样。它没有太多监管的限制,也没有中间商抽成,内容收益直接归创作者所有。
可以降低存储和带宽成本
代表应用:
Dtube(https://d.tube)是一个搭建在Steemit上的去中心化视频播放平台,其用户上传的视频文件都经过IPFS协议进行存储,具有唯一标识。相较于传统视频网站,它降低了同资源冗余程度,同时大大节约了海量用户在播放视频时所产生的带宽成本。
可以与区块链完美结合
代表应用:
EOS引以为傲的是可以支持百万级别TPS的并发量,其中除了DPOS共识机制的功劳之外,还归功于其底层存储设计是采取IPFS来解决大型数据的传输效率。
EOS将自己打包好的区块数据通过IPLD进行异构处理,统一成一种便于内容寻址的数据结构类型,并挂载到IPFS的link上,让IPFS网络承担存储和P2P检索的逻辑,而不消耗EOS区块链系统本身太多的计算资源。
原文发布时间为:2018-04-18
本文作者:朱清
本文来自云栖社区合作伙伴“中生代技术”,了解相关信息可以关注“中生代技术”。
这篇关于详解IPFS技术架构与应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




