本文主要是介绍为什么Kafka这么快(Kafka高吞吐、高性能),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 问什么 Kafka 可以这么快?
- 消息发送端
- 消息存储
- 1.零拷贝机制
- 2.磁盘顺序读写
- 3.稀疏索引
- 4.页缓存
- 5.分区和副本
- 6.分段存储的好处
- 消息消费
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。kafka主要使用了以下几个方式实现了超高的吞吐率,Kafka是一个号称能用普通的PC机也能处理超千万亿的消息吞吐量的实时消息流处理平台。
问什么 Kafka 可以这么快?
发送端、存储端、消费端
发送端:异步发送+多分区并行+消息批量发送
存储端:零拷贝技术+磁盘顺序写入+稀疏索引+分区和副本+页缓存
消费端:消费者群组+并行消费+批量拉取
消息发送端
异步发送+多分区并行+消息批量发送
1.异步发送:生产者可以异步发送消息,不必等待每个消息的确认,这大大提高了消息发送的效率。
2.多分区并行:通过将数据分布在不同的分区(partitions)中,生产者可以并行发送消息,从而提高吞吐量。
3.数据压缩+消息批量发送,节省网络IO开销
消息存储
零拷贝技术+磁盘顺序写入+稀疏索引+分区和副本+页缓存
1.零拷贝机制
零拷贝技术:karka使用零拷贝技术来避免了数据的拷贝操作,降低了内存和cpu的使用率,提高了系统的性能。
零烤贝,首先要了解操作系统的o流程,因为有内核态和用户态的区别,为了保证安全性和缓存。
操作系统的虚拟内存分成两部分,一部分是内核空间,一部分是用户空间。这样就可以避免用户进程直接操作内核,保证内核安全。如图所示:
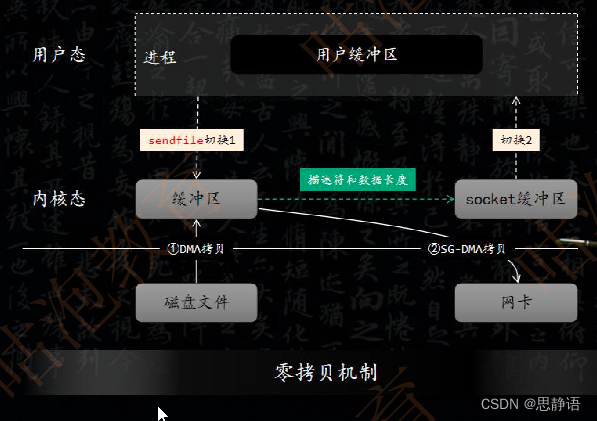
正常情况下,如果用户要从磁盘读取数据,必须先把数据从磁盘拷贝到内核缓冲区,然后在从内核缓冲区到用户缓冲区,最后才能返回给用户。
在Linux操作系统里面提供了一个sendfile函数,可以实现“零拷贝”。意思就是不需要经过用户缓冲区,可以直接把数据拷贝到网卡。
而Kafka中文件传输最终调用的是Java NIO 库里的 transferTo 方法,实际上最后就会使用到Linux sendfile() 系统调用函数。零拷贝技术可以大大地提升文件传输的性能。
2.磁盘顺序读写
磁盘顺序写入:kark把消息存储在磁盘上,且以顺序的方式写入数据。顶序写入比随机写入速度快很多,因
为它减少了磁头寻道时间,避免了随机读写带来的性能损耗,提高了磁盘的使用效率。
3.稀疏索引
Kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引
也就是说,Kafka插入一批消息才会产生一条索引记录。后续利用二分查找,可以大大提高检索效率。
稀疏索引:kafka存储消息是通过分段的日志文件,每个分段都有自己的索引文件,这些索引文件中的条目不
是对分段中的每条消息都建立索引,而是每隔一定数量的消息建立一个索引点,这就构成了稀疏索引,稀疏索
引减少了索引大小,使得加载到内存中的索引更小,提高了查找特定消息的效率
4.批量文件压缩
Kafka默认不会删除数据,它会把所有的消息都变成一个批量的文件。如图所示,它会把相同的Key合并为最后一个Value。这样对消息进行合理的批量压缩,可以减少网络IO损耗。
4.页缓存
kak将其数据存储在磁盘中,但在访问数据时,它会先将数据加载到操作系统的页缓存中,并在页缓存中保留一份副本,从而实现快速的数据访问。
页缓存:kaka将其数据存储在磁盘中,但在访问数据时,它会先将数据加载到操作系统的页缓存中,并在页缓存中保留一份副本,从而实现快速的数据访问。
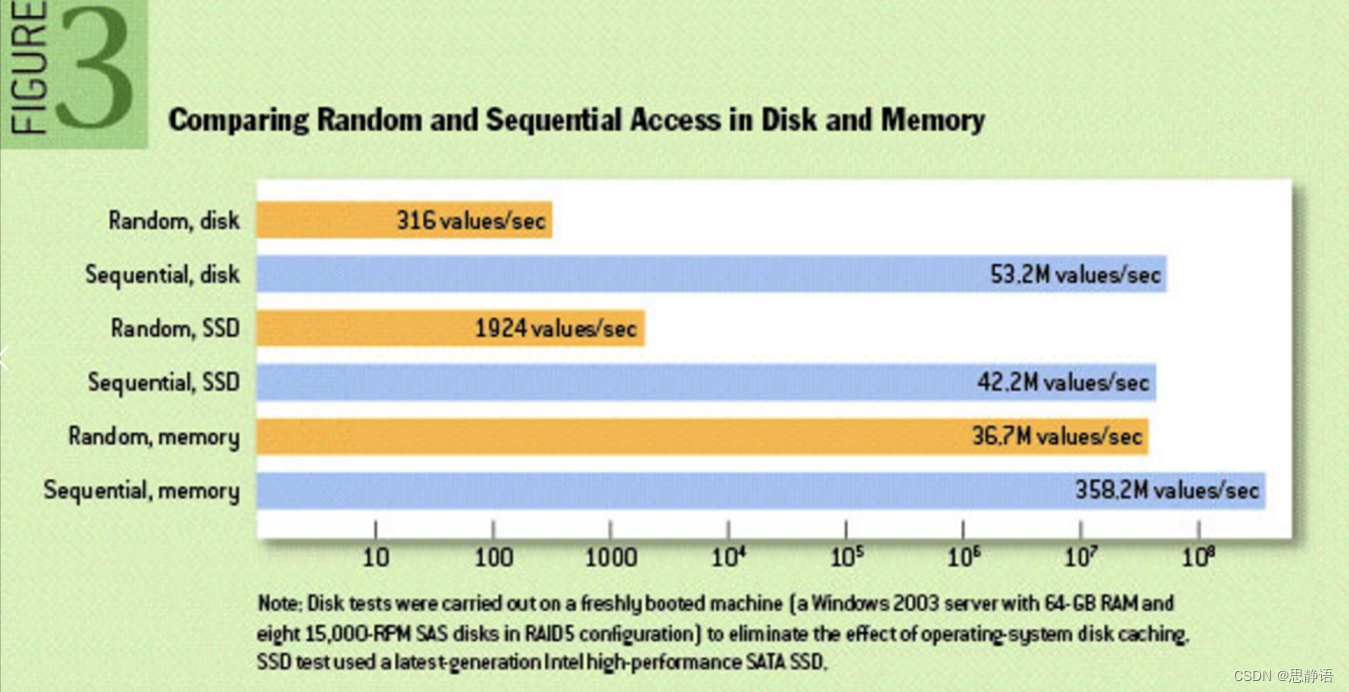
这个是磁盘的构造。磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形轨迹,这个就叫磁道。从内到位半径不同有很多磁道。然后又用半径线,把磁道分割成了扇区(两根射线之内的扇区组成扇面)。如果要读写数据,必须找到数据对应的扇区,这个过程就叫寻址。
如果读写的多条数据在磁盘上是分散的,寻址会很耗时,这叫随机I/O。
如果读写的数据在磁盘上是集中的,不需要重复寻址的过程,这叫顺序I/O。
而Kafka的Message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升。
在一定条件下测试,磁盘的顺序读写可以达到53.2M每秒,比内存的随机读写还要快。
5.分区和副本
kaka采用分区和副本的机制,可以将数据分散到多个节点上进行处理,从而实现了分布式的但
高可用性和负载均衡。
6.分段存储的好处
1、读取效率高
2、方便消息清理,仅删除,无修改
消息消费
1,消费者群组:通过消费者群组可以实现消息的负载均衡和容错处理。
2,并行消费:不同的消费者可以独立地消费不同的分区,实现消费的并行处理。
3,批量拉取:kak支持批量拉取消息,可以一次性拉取多个消息进行消费。减少网络消耗,提升性能
这篇关于为什么Kafka这么快(Kafka高吞吐、高性能)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





