本文主要是介绍1.2 debug的六种指令的使用,四个通用寄存器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
汇编语言
首先进入环境
mount c d:masm //把c挂载在d盘中的masm当中
c: //进入c,进入到编译环境
dir //查看文件,可有可无
- Debug是DOS、Windows都提供的实模式(8086 方式)程序的调试工具。使用它可以查看CPU各种寄存器中的内容、内存的情况和在机器码级跟踪程序的运行。
我们用到的Debug功能:
首先输入debug进入debug模式
1. 用Debug的R命令查看、改变CPU寄存器的内容
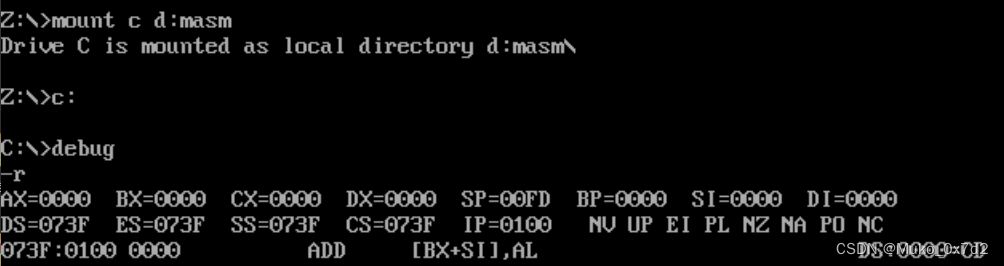
这里的数都是16进制表示,相当于右边的值赋值给左边的变量
修改一个寄存器中的值
可以用r命令后加寄存器名来进行
如下:

这样子ax的值就变成了5678.
2. 用Debug的D命令查看内存中的内容
-
如果我们想知道内存10000H 处的内容,可以用
d 段地址:偏移地址的格式来查看
如下:
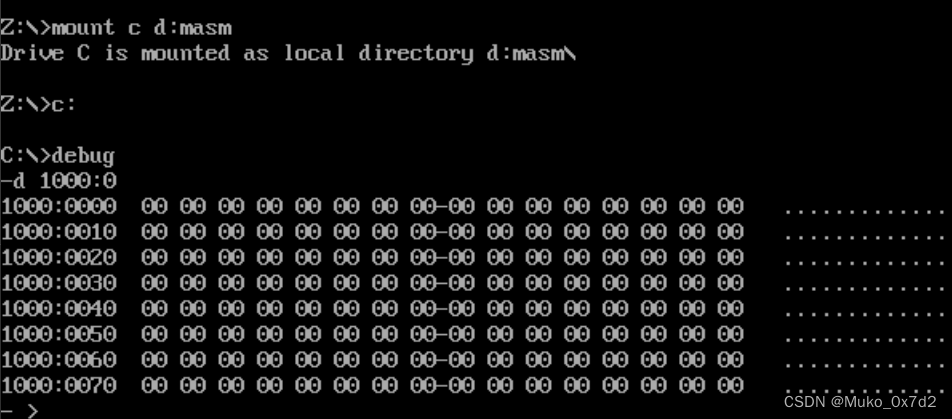
-
如果一直输入d,会发现地址偏移,在汇编中,用两个数来代表一个内存

-
在偏移地址后输入值,可以限制值的展示

-
用d 1000:9查看1000:9处的内容

Debug从1000:9 开始显示,一直到 1000:88 ,一共是128个字节。第一行中的1000:0到1000:8 单元中的内容不显示。
3. 用Debug的E命令改写内存中的内容
e 段内地址:偏移地址 值 值……
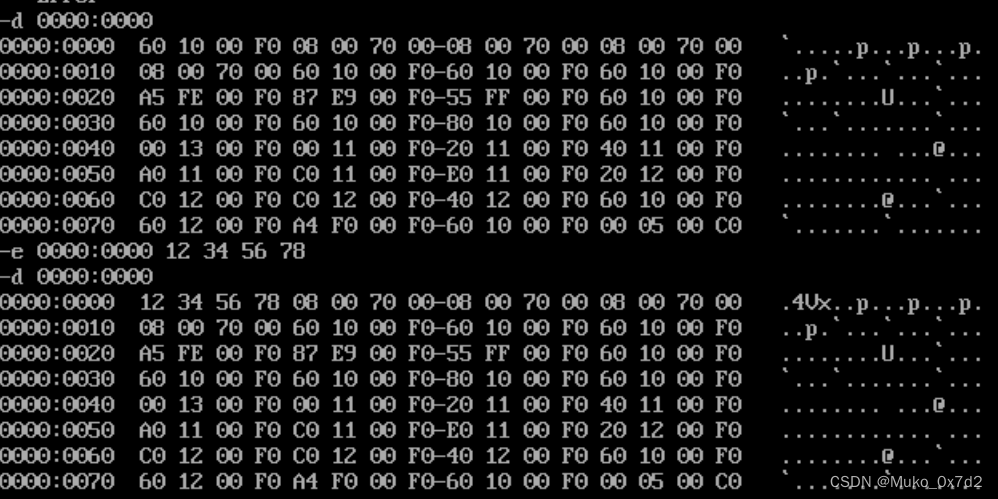
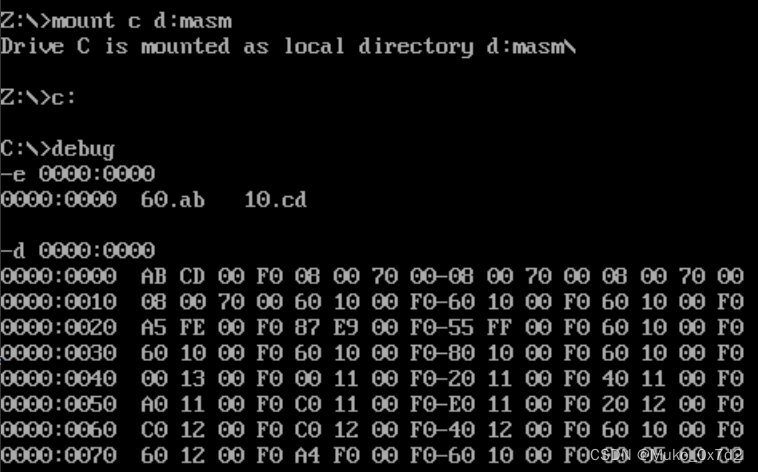
- 可以输入
e 段内地址:偏移地址回车,可以一个个修改值,空格显示下一个修改的值
4. 用Debug的U命令将内存中的机器指令翻译成汇编指令
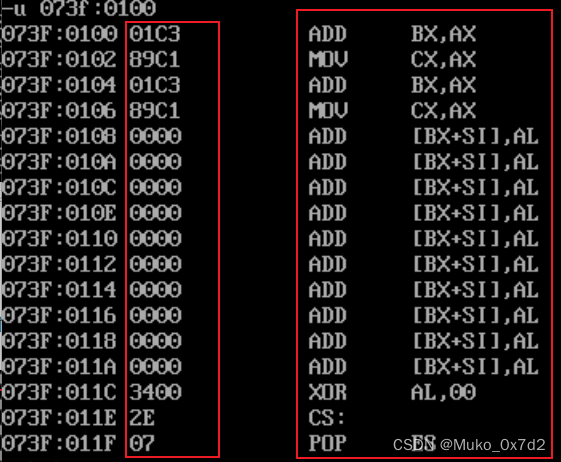
左边是机器码,右边是翻译过后的代码,代码也是有内存的,用机器码存放到内存当中,u指令就是来翻译这些机器码
5. 用Debug的T命令执行一条机器指令
6. 用Debug的A命令以汇编指令的格式在内存中写入一条机器指令

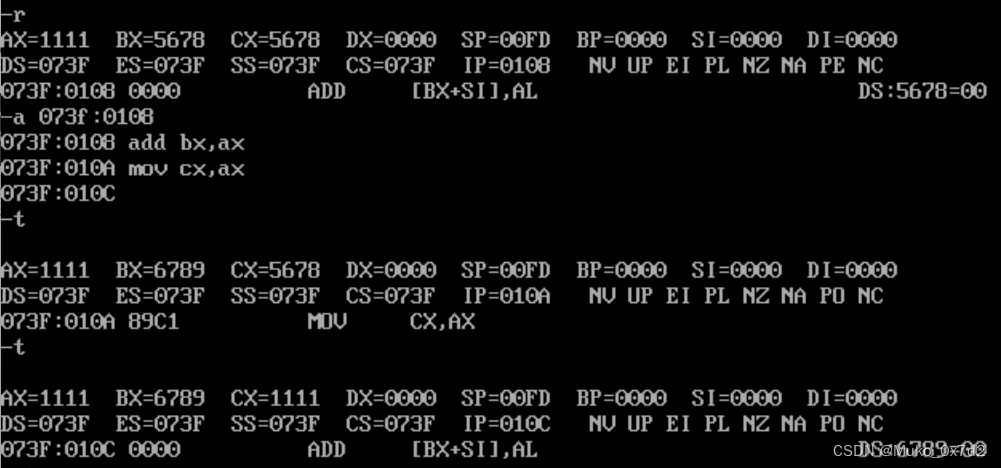
- 先输入r,查看寄存器的内容,其中cs和ip是寄存器
- 写入指令
a 073f:0108
add bx,ax //将bx与ax的值相加再赋值给bx
mov cx,ax //将ax的值拷贝一份给cxt //一个t命令执行一条机器指令t //一个t命令执行一条机器指令
7. 记忆方法(true ad)
R:register
D:display
E:edit
U:upgrade ,向上升级以便于翻译成代码
T:execute
A:add
这篇关于1.2 debug的六种指令的使用,四个通用寄存器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




