本文主要是介绍ext4_dirty_inode与ext4_do_update_inode函数详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、ext4_dirty_inode
定义在fs/ext4/inode.c中,其内容如下:
void ext4_dirty_inode(struct inode *inode, int flags)
{handle_t *handle;if (flags == I_DIRTY_TIME)return;handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);if (IS_ERR(handle))goto out;ext4_mark_inode_dirty(handle, inode);ext4_journal_stop(handle);out:return;
}在ext4_dirty_inode函数中,一共调用了三个函数,分别为:
①ext4_journal_start函数
②ext4_mark_inode_dirty函数
③ext4_journal_stop函数
在ext4_dirty_inode中定义了handle_t *handle,然后将ext4_journal_start函数的返回值赋值给了这个handle,这个handle再作为参数被传递进ext4_mark_inode_dirty函数中。
1、ext4_journal_start函数
上面讲述了ext4_journal_start返回了handle,ext4_journal_start函数涉及ext4文件系统使用的jbd2日志模块,它将启用一个新的日志handle(日志原子操作)并将应该同步的inode元数据block向日志jbd2模块transaction进行提交(注意不会立即写日志和回写)。其中ext4_journal_start函数会简单判断一下ext4文件系统的日志执行状态最后直接调用jbd2__journal_start来启用日志handle。
jdb2__journal_start函数定义在linux\jdb2\transaction.c文件中,这属于jdb2模块的相关内容。
2、ext4_mark_inode_dirty函数
在ext4_mark_inode_dirty函数中内容还是挺多的,其内容如下:
int ext4_mark_inode_dirty(handle_t *handle, struct inode *inode)
{struct ext4_iloc iloc;struct ext4_sb_info *sbi = EXT4_SB(inode->i_sb);static unsigned int mnt_count;int err, ret;might_sleep();trace_ext4_mark_inode_dirty(inode, _RET_IP_);err = ext4_reserve_inode_write(handle, inode, &iloc);if (ext4_handle_valid(handle) &&EXT4_I(inode)->i_extra_isize < sbi->s_want_extra_isize &&!ext4_test_inode_state(inode, EXT4_STATE_NO_EXPAND)) {/** We need extra buffer credits since we may write into EA block* with this same handle. If journal_extend fails, then it will* only result in a minor loss of functionality for that inode.* If this is felt to be critical, then e2fsck should be run to* force a large enough s_min_extra_isize.*/if ((jbd2_journal_extend(handle,EXT4_DATA_TRANS_BLOCKS(inode->i_sb))) == 0) {ret = ext4_expand_extra_isize(inode,sbi->s_want_extra_isize,iloc, handle);if (ret) {ext4_set_inode_state(inode,EXT4_STATE_NO_EXPAND);if (mnt_count !=le16_to_cpu(sbi->s_es->s_mnt_count)) {ext4_warning(inode->i_sb,"Unable to expand inode %lu. Delete"" some EAs or run e2fsck.",inode->i_ino);mnt_count =le16_to_cpu(sbi->s_es->s_mnt_count);}}}}if (!err)err = ext4_mark_iloc_dirty(handle, inode, &iloc);return err;
}首先,在ext4_mark_inode_dirty函数中调用了ext4_reserve_inode_write,该函数内容如下:
int ext4_reserve_inode_write(handle_t *handle, struct inode *inode, struct ext4_iloc *iloc){int err;err = ext4_get_inode_loc(inode, iloc);if (!err) {BUFFER_TRACE(iloc->bh, "get_write_access");err = ext4_journal_get_write_access(handle, iloc->bh);if (err) {brelse(iloc->bh);iloc->bh = NULL;}}ext4_std_error(inode->i_sb, err);return err;}在这个函数里面首先调用了ext4_get_inode_loc函数,返回值为err,如果返回为0,则调用ext4_journal_get_write_access函数,返回值赋给err。首先进入到ext4_get_inode_loc函数中看其具体实现:
int ext4_get_inode_loc(struct inode *inode, struct ext4_iloc *iloc)
{/* We have all inode data except xattrs in memory here. */return __ext4_get_inode_loc(inode, iloc,!ext4_test_inode_state(inode, EXT4_STATE_XATTR));}ext4_get_inode_loc顾名思义,该函数可能要做的工作就是get inode location,进入到__ext4_get_inode_loc查看是否如此。__ext4_get_inode_loc同样定义在fs\ext4\inode.c中,其中有一个重要的数据结构struct ext4_iloc:
struct ext4_iloc
{struct buffer_head *bh;unsigned long offset;ext4_group_t block_group;
};该结构用于描述一个inode在磁盘和内存中的精确位置。在__ext4_get_inode_loc中基本就是在为ext4_iloc结构赋值,得到buffer_head。__ext4_get_inode_loc执行成功,返回值为0,那么必定会执行ext4_journal_get_write_access函数。
该函数实现定义在fs\ext4\ext4_jdb2.c中:
int __ext4_journal_get_write_access(const char *where, unsigned int line,handle_t *handle, struct buffer_head *bh)
{int err = 0;might_sleep();if (ext4_handle_valid(handle)) {err = jbd2_journal_get_write_access(handle, bh);if (err)ext4_journal_abort_handle(where, line, __func__, bh,handle, err);}return err;
}其中调用了jdb2_journal_get_write_access函数,现在进入到该函数中查看该函数的具体实现。该函数定义在fs\jdb2\transaction.c中,其内容如下:
int jbd2_journal_get_write_access(handle_t *handle, struct buffer_head *bh)
{struct journal_head *jh;int rc;if (jbd2_write_access_granted(handle, bh, false))return 0;jh = jbd2_journal_add_journal_head(bh);/* We do not want to get caught playing with fields which the* log thread also manipulates. Make sure that the buffer* completes any outstanding IO before proceeding. */rc = do_get_write_access(handle, jh, 0);jbd2_journal_put_journal_head(jh);return rc;
}该函数用于获取写权限。
获取写权限之后,简单做一些判断操作,最后再调用ext4_mark_inode_dirty函数,在该函数中又调用了ext4_do_update_inode,这两个函数在下一节进行讲解。
总结:
ext4_mark_inode_dirty函数会调用ext4_get_inode_loc获取inode元数据所在的buffer
head映射block,按照标准的日志提交流程jbd2_journal_get_write_access(获取写权限)-> 对元数据raw_inode进行更新 -> jbd2_journal_dirty_metadata(设置元数据为脏并添加到日志transaction的对应链表中);
调用链如下所示:
ext4_mark_inode_dirty
——ext4_reserve_inode_write
————ext4_get_inode_loc获取ext4_iloc
————ext4_journal_get_write_access获取写权限
——————jbd2_journal_get_write_access
——ext4_mark_iloc_dirty
————ext4_do_update_inode
3、ext4_journal_stop函数
最后ext4_journal_stop->jbd2_journal_stop调用流程结束这个handle原子操作。这样后面日志commit进程会对日志的元数据块进行提交(注意,这里并不会立即唤醒日志commit进程启动日志提交动作,启用largefile特性除外)。
二、ext4_do_update_inode
ext4_do_update_inode定义在fs\ext4\inode.c中,作用是将内存中的inode信息赋值给表示磁盘inode信息的on-disk inode,即ext4_inode_info->ext4_inode,但是这个ext4_inode不是立即刷回的。
对于ext4_do_update_inode采用“溯源法”,查看其上层调用,使用Source Insight查看内核源码,通过搜索ext4_do_update_inode可得如下图片中的信息。
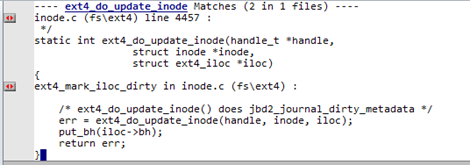
对于ext4_do_update_inode的调用只能来自,ext4_mark_iloc_dirty函数,所以下一个需要了解的函数就是ext4_mark_iloc_dirty。
在ext4_do_update_inode中,还调用了ext4_handle_dirty_metadata()函数,用于将handle添加到transaction中。
1、ext4_mark_iloc_dirty
该函数定义在fs\ext4\inode.c中,其内容如下:
int ext4_mark_iloc_dirty(handle_t *handle,struct inode *inode, struct ext4_iloc *iloc)
{int err = 0;if (IS_I_VERSION(inode))inode_inc_iversion(inode);/* the do_update_inode consumes one bh->b_count */get_bh(iloc->bh);/* ext4_do_update_inode() does jbd2_journal_dirty_metadata */err = ext4_do_update_inode(handle, inode, iloc);put_bh(iloc->bh);return err;
}从该函数内容可以看出,函数并不复杂,通过get_bh获取到buffer_head,然后通过函数ext4_do_update_inode更新ext4_inode。从代码的注释可以得知如下信息:
(1)do_update_inode消耗一个bh-> b_count
(2)ext4_do_update_inode()does jbd2_journal_dirty_metadata
(3)该函数的调用者必须事先调用ext4_reserve_inode_write()函数,确保调用者已经获得了对iloc->bh的写权限。
2、总结
ext4_dirty_inode
——ext4_mark_inode_dirty
————ext4_reserve_inode_write
——————ext4_get_inode_loc获取ext4_iloc
——————ext4_journal_get_write_access获取写权限
————————jbd2_journal_get_write_access
————ext4_mark_iloc_dirty
——————ext4_do_update_inode
这篇关于ext4_dirty_inode与ext4_do_update_inode函数详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





