本文主要是介绍服务器数据恢复-服务器RAID5上层XFS文件系统分区数据恢复案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
服务器数据恢复环境:
MD1200磁盘柜中的磁盘通过RAID卡创建了一组RAID5阵列,分配了一个LUN。在Linux操作系统层面对该LUN进行了分区,划分sdc1和sdc2两个分区,通过LVM扩容的方式将sdc1分区加入到了root_lv中;sdc2分区格式化为XFS文件系统。
服务器故障:
服务器重装系统后,磁盘分区改变,sdc2分区丢失,无法访问。
服务器数据恢复过程:
1、将故障服务器中所有磁盘编号后取出,经过硬件工程师检测没有发现磁盘存在硬件故障。将所有磁盘以只读方式进行扇区级的全盘镜像,镜像完成后将所有磁盘按照编号还原到原服务器中,后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
2、基于镜像文件分析raid5阵列的盘序、条带大小等raid结构相关信息,利用分析出来的raid信息虚拟重构raid5阵列。
3、定位到xfs文件系统的分区起始位置,校验xfs文件系统的完整性及正确性。北亚企安数据恢复工程师对丢失的xfs文件系统的进行检测后发现xfs文件系统头部的超级块及部分节点、目录项丢失。
4、根据超级块备份及xfs文件系统中的目录树结构,北亚企安数据恢复工程师对xfs文件系统的超级块结构修复。
修复完成的超级块: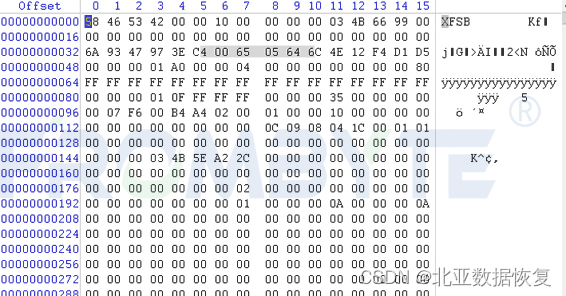
5、对xfs文件系统中丢失的节点及目录项进行修复。
修复完成的根节点:
重做的目录项: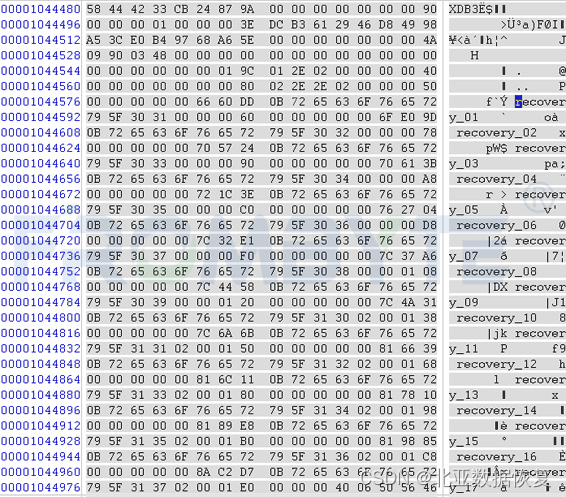
6、修复完成后,北亚企安数据恢复工程师编写程序解析xfs文件系统,提取其中的数据。
修复完成的目录结构: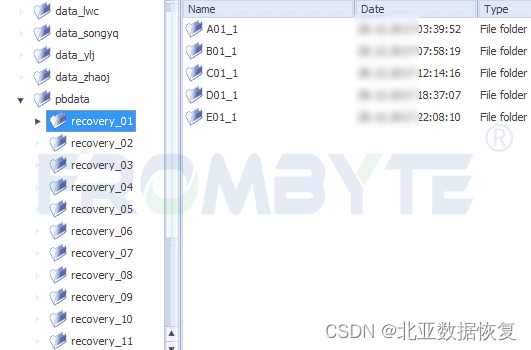
服务器数据恢复总结:发现服务器数据丢失之后,用户方没有做任何破坏性的写入操作,所以丢失的数据才得以完整恢复。
这篇关于服务器数据恢复-服务器RAID5上层XFS文件系统分区数据恢复案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





