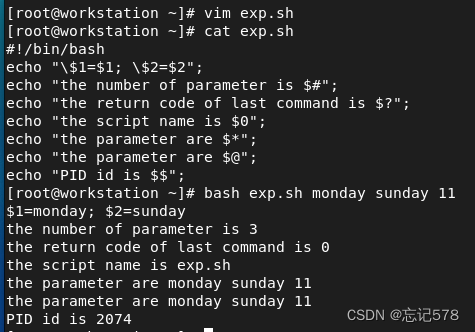
本文主要是介绍rhcsa(rh134),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
shell
查看用户shell
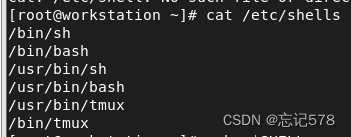
a、如下查看/etc/shells文件列出了系统上所有可用的 shell(具体的可用的 shell 列表可能会因不同的红帽版本和配置而有所不同)
(如下图/etc/shells文件包含/bin/tmux并不意味着tmux是一个shell。实际上,/etc/shells文件列出了系统上所有可用的shell,而不仅仅是那些可以直接用作默认登录shell的shell。可能是因为它是一个可执行文件,并且可能在某些上下文中被用作一个shell(例如,当使用tmux命令时),但并不意味着它是一个常规的shell。这也可以解释后面的示例中为什么用tmux不可以用来执行脚本)
补充:
要确定tmux是否是一个shell,我们需要查看其定义和功能。Tmux是一个终端复用器,它允许用户在单个窗口中创建和管理多个终端会话。虽然tmux提供了类似于shell的命令行界面,但它并不是一个完整的shell,而是用于管理终端会话的工具。)
图中/bin/bash和 /usr/bin/bash 都指向 Bash shell,但它们位于不同的目录中。/bin/bash: 这个路径是 Bash 的标准位置,通常在大多数 Linux 系统中都可以在这个位置找到 Bash。这个目录包含系统需要的核心命令和程序,因此权限设置得比较严格。通常只有 root 用户或具有相应权限的用户才能执行或修改这个目录下的文件。/usr/bin/bash: 这个路径是另一个常见的位置,用于存储用户级别的应用程序和工具。这个目录通常对所有用户开放,以便他们可以轻松地执行或使用其中的程序。由于权限要求较低,用户通常在这个目录下安装或配置他们自己的软件和脚本。
在用bash 执行脚本文件时,实际使用的可能是/bin/bash或 /usr/bin/bash 中的某一个,具体取决于系统的配置和安装情况。系统管理员可以根据需要更改或配置默认的路径。
要查看系统中 Bash 的实际路径,可以在终端中执行以下命令
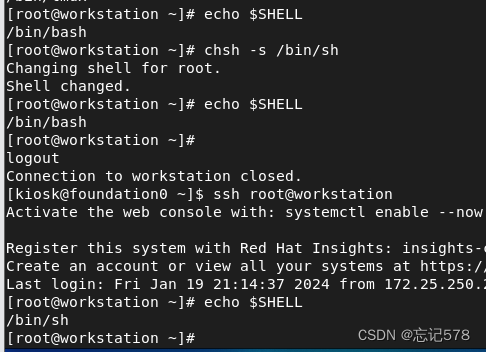
b、如下查看当前用户的shell
$SHELL变量通常包含了用户的默认 shell,但也可以在登录后使用chsh命令更改自己的默认 shell更改或覆盖。如下更改自己的shell,发现是需要重新启动终端或重新登录才能使更改生效。
在大多数情况下,
$SHELL的值是用户在登录时所使用的 shell 的完整路径。例如,如果用户使用的是 bash shell,那么echo $SHELL可能会返回/bin/bash。如果用户使用的是 zsh shell,那么echo $SHELL可能会返回/bin/zsh。(记得之前我们创建用户也有指定shell的选项,useradd -s /bin/bash 来指定shell)
创建并执行BASH SHELL脚本
shell脚本:当命令不在命令行中执行,而是从一个文件中执行时,该文件就叫shell脚本)
至于bash shell脚本应该可以用是使用bash shell编写的脚本,即用指定解释器为/bin/bash执行的脚本来解释。
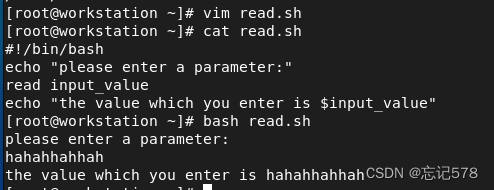
编写脚本
1\可以通过在文本编辑器中打开新的空文件来创建Bash shell脚本
(注意一般脚本文件以.sh为后缀,如果一开始创建没有加后缀,则编辑时不会显示高亮,在下次打开时则会显示高亮,)
上图为第一次vim but 创建时编辑脚本,没有以.sh为后缀
如下时第二次vim but即在保存退出后用vim查看编辑时发现有了高亮
2\脚本第一行以符号#!开头指定命令解释器
eg:#!/bin/bash 或者省略直接写脚本内容
如上没有指定解释器仍旧可以运行
(通常情况下,红帽系统的默认解释器是bash。因此,如果没有指定解释器,脚本将使用bash来执行。如果脚本的第一行指定了其他解释器,那么系统将使用该解释器来执行脚本)
补充:
Shebang(也称为Hashbang)是一个由井号和叹号构成的字符串行(#!),其出现在文本文件的第一行的前两个字符。Shebang用于指定命令的解释器。在类Unix系统的脚本中,第一行通常包含一个shebang,其后跟着一个或多个空白字符,然后是解释器的绝对路径。当直接调用脚本时,系统的程序载入器会分析shebang后面的内容,将这些内容作为解释器指令,并调用该指令,将载有shebang的文件路径作为该解释器的参数,执行脚本。如果没有shebang或者指定的不是一个可执行文件,那么执行时会默认采用当前Shell去解释这个脚本(即:$SHELL环境变量)。
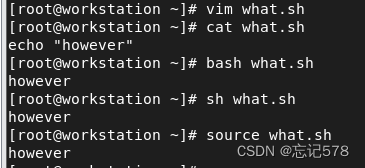
3\编写脚本内容,保存退出即可
执行脚本的方式
如上所示,方法一中需要有文件的执行权限,通常情况下,只应该允许脚本文件的拥有者和具有适当权限的用户执行脚本。设置所有人都有执行权限可能会带来安全风险,因为它允许任何用户运行该脚本。
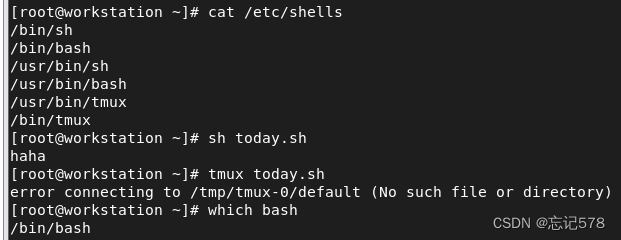
chmod u+x 脚本文件名 # 仅为用户设置执行权限 chmod g+x 脚本文件名 # 仅为组设置执行权限 chmod o+x 脚本文件名 # 仅为其他用户设置执行权限方法二(脚本文件可以没有执行权限)中也可以用sh执行脚本,即sh date.sh
执行
cat /etc/shells命令会显示系统上可用的shell列表。在这个列表中大部分都可以用来执行脚本。
除上面三种方法外,也可将脚本放在PATH环境变量中所列的某个目录下,则可以像其它命令那样单独用文件名来体调用用shell脚本
(如下所示具有的环境变量)
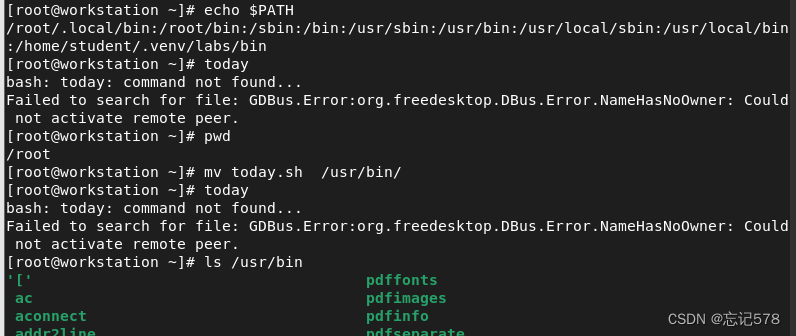
(即我们可以把脚本放在如上环境变量的其中一个目录即可用文件名执行脚本)
如上将today.sh移动到环境变量之一的目录/usr/bin中,再去执行today发现不行,且可以看到在/usr/bin下的文件大都是绿色的可执行文件,但是我们可以发现我们的脚本文件不是
可能是没有执行权限,所以即使加入到环境变量中,也无法像命令一样执行
(上面出现两个问题,一个是我们应该写文件全名去执行,而不是像上上图中用today,另一个问题就是上图所示的权限问题)
如上图所示,则可以用文件全名当命令一样去执行。
如何添加环境变量呢?
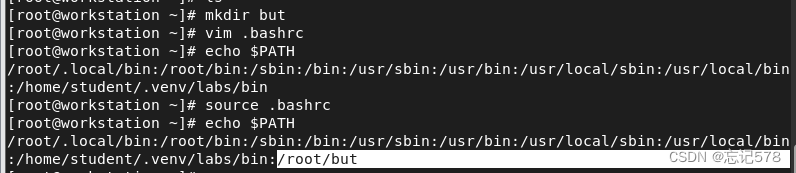
a、编辑.bashrc文件可以添加环境变量,但是这是给单个用户添加,
vim .bashrc插入上图命令,后用source执行以下文件,再次查看PATH环境变量
还可以用临时命令添加环境变量,其效果也是单个用户生效,且在重启后则会失效
如上图则是通过命令让添加临时的环境变量。
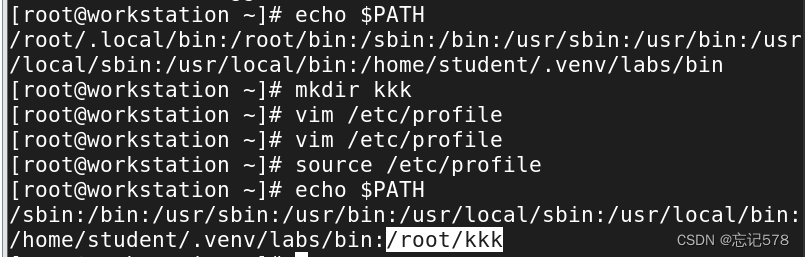
b、修改/etc/profile文件。如果要让所有用户都生效,则要修改全局配置,记得要source 命令执行文件,用于重新加载系统环境变量文件 ,以便使修改后的环境变量生效。
注意我按图中添加环境变量的命令是写在文件最后的,如果再最前面写,则效果如下
至于为什么,我看网上说如果在文件的开头添加了环境变量,它可能会覆盖其他已经存在的同名环境变量。不知道和这个有没有关。😶
shell脚本变量就是在shell脚本程序中保存,系统和用户所需要的各种各样的值。shell脚本变量可以分为:系统变量、环境变量和用户自定义变量。
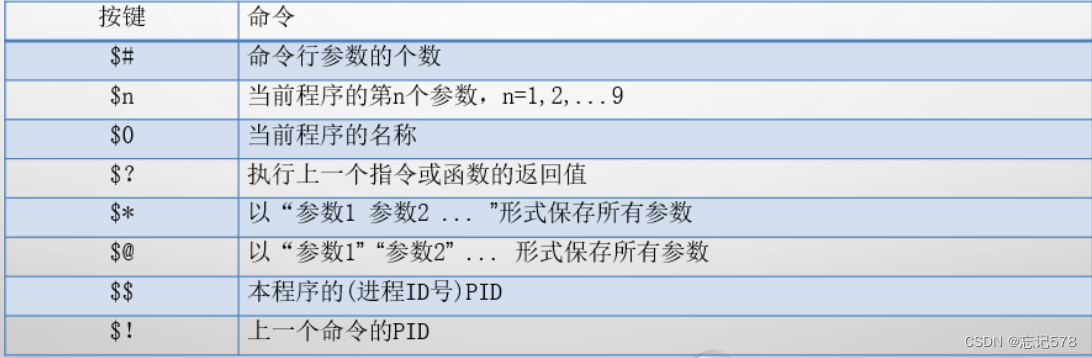
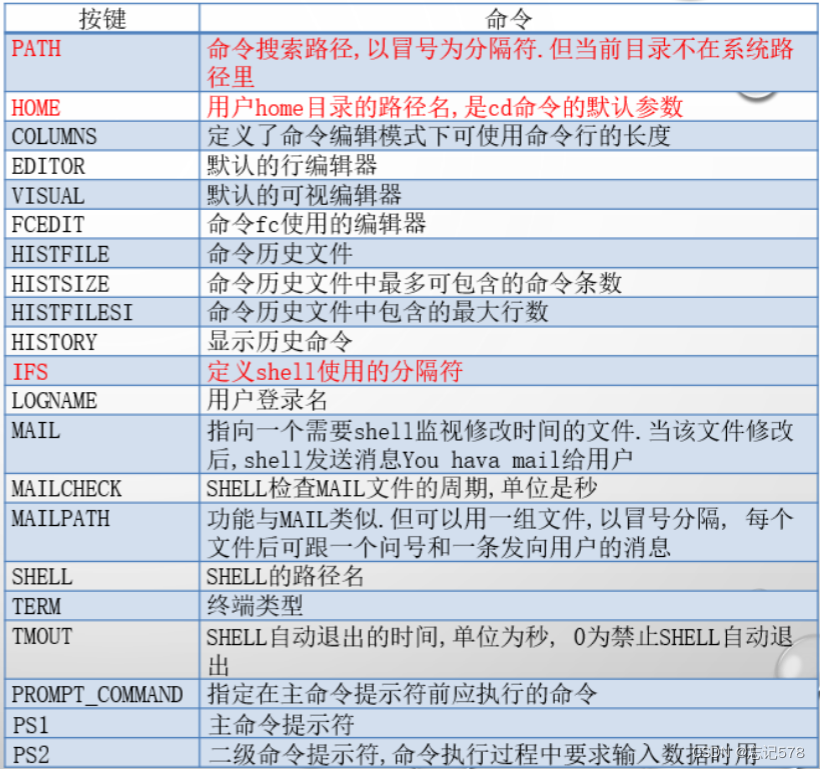
常用系统变量如下,可进行参数检测
在编写代码时,把这些变量的值写入即可
用env命令查看环境变量
环境变量,例如上上面提到的用echo $PATH查看的变量,如下常用环境变量
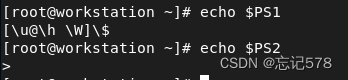
PS1设置为显示当前用户、主机名和当前工作目录,PS2设置为">"。
(补充:关于PS1和PS2:
在红帽系统中,PS1和PS2是环境变量,用于定义命令行提示符的格式。
PS1是主要的命令行提示符,它通常显示当前登录用户、计算机名、当前工作目录和其他有用的信息。
PS2是第二级命令行提示符,当bash等待输入更多的信息以完成命令时将显示它。默认情况下,PS2的值为">"。
要永久修改PS1和PS2的值,可以在~/.bashrc文件中进行修改。在该文件中添加相应的行来设置PS1和PS2的值,然后使用source命令重新加载~/.bashrc文件,使修改生效。例如
可以参照这个表来设置PS1 PS2的值
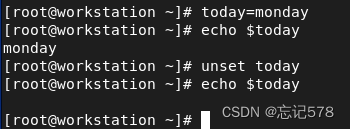
自定义变量
规则:首字母必须为字母,中间不能有空格,可以使用下划线_,不能使用标点符号,不能使用bash里的关键字
赋值方式:变量名=值 (等号两边不能有空格)
使用方法:echo $变量名 (可以用{ }将变量名括起来,如果包含在其它字符串里)
如图,可用unset命令清空变量的值。(一些有条件的替换${today:-monday},如果today没有赋值则会输出moday,但是实际没有给today赋值,${today:=monday}未定义或为空时,则会将monday赋值给today。${today:+monday}若today已赋值,在输出时会用monday替换,但实际没有改变原来的赋值。)
(补充:
shell的输入输出
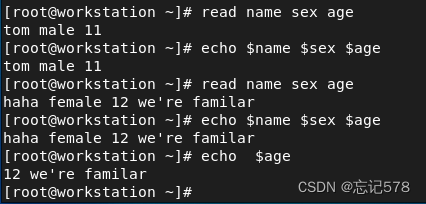
用read命令
如上图使用,用空格作为多个变量之间的分隔符。shell将输入文本域超长部分赋予最后一个变量。
如果想在脚本执行过程中动态地获取用户输入并将其赋值给变量,可以使用
read命令
可以看到我们在代码中使用read去输入值,后面执行也是同步进行,而不用在执行脚本时全部输入值,例如 bash read.sh what (即在脚本名称后直接输入参数值,多个参数之间用空格空开)
用echo命令输出












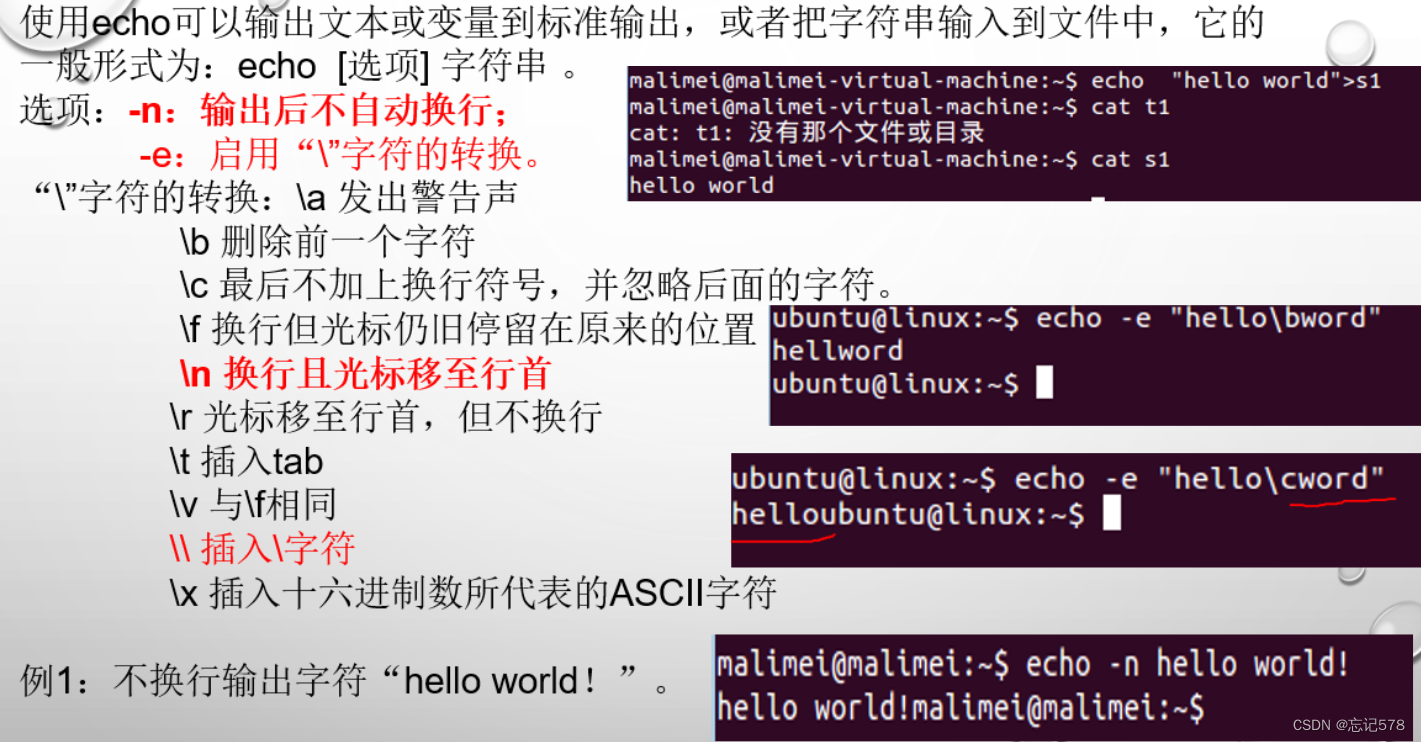
使用循环来迭代命令
参数与参数之间用空格来分开
如上图所示记得定义的变量我们的使用方法,是加一个$,
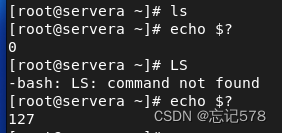
在脚本中使用退出代码
如下当我执行完一个脚本(或者命令)用echo $?输出最后执行的命令的退出状态,再执行一个错误的命令,
再执行命令echo $? 得到的该命令结果退出状态
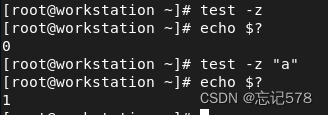
用test命令测试脚本输入
字符串运算符
上图红色标记,记得空格
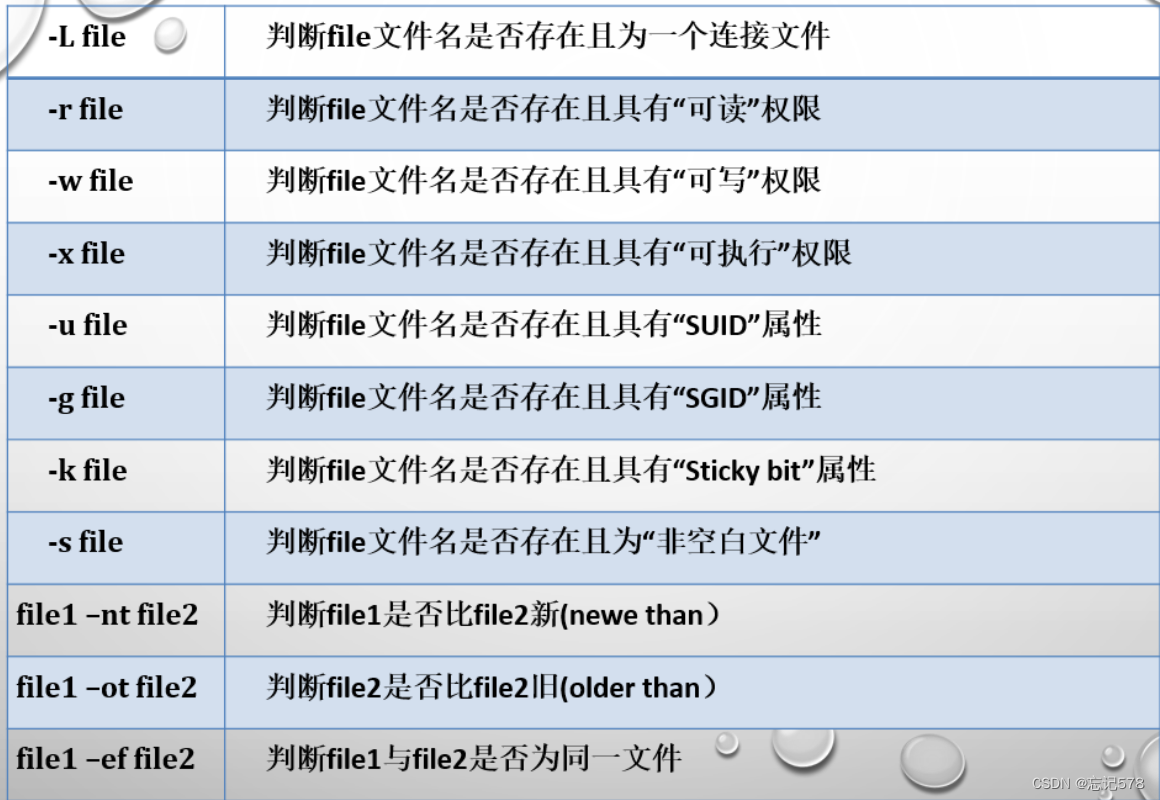
文件运算符(用于文件和目录属性比较
不用写test只要使用它的参数就好,(记得test的结果,为真则为0)如下
逻辑运算符
如图所示,第一个命令想表达12大于11或10小于9,我们知道因为时逻辑或,所以只要一个关系式满足就算为真,所以后面输出的状态结果为0.
第二个命令是想表达read.sh和hhh.txt这两个文件是不是都存在,都在则为真,因为后者不存在,所以返回是大于0的值
条件结构
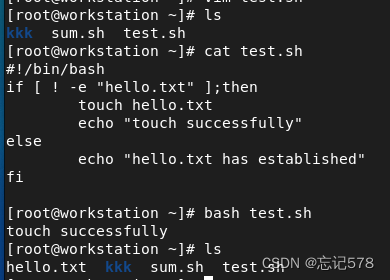
if语句
必须在左括号和右括号的左侧各加一个空格,否则会报错。
command也要小心用空格,例如[ $a = $b ]
也可以用c语言的方式表示(右边代码)
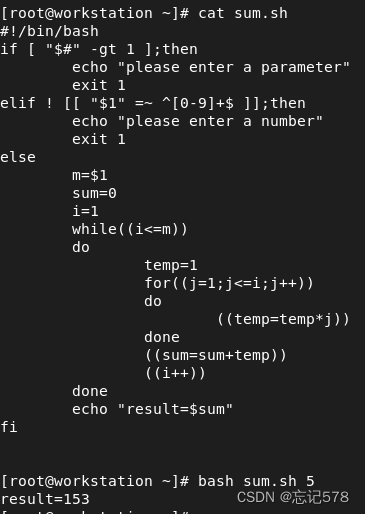
也可以写成下面这样计算1+2!+3!+.......
#!/bin/bash if(($#==1));thenm=$1 elseecho "执行格式为:$0 number"exit 0 fi tmp=`expr $m + 1 2>/dev/null` if [ $? -ne 0 ] thenecho "传入参数类型错误,需要传入一个整数"exit 0 fisum=0 item=1 for((i=1;i<=m;i++)) doitem=$[$item*$i]sum=$(($sum+$item)) doneecho $sum
tmp=expr $m + 1 2>/dev/null``: 使用expr命令尝试将m加1。如果m不是整数,此命令会返回非零状态码,并把错误信息重定向到/dev/null。了解了一下expr命令
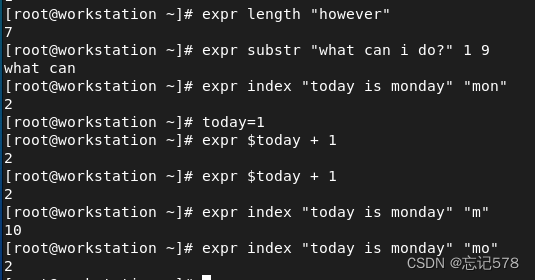
如上图所示,计算字符串长度(however的长度)、提取子串(从第一个字符到第九个为what can 包括空格)、模式匹配(匹配字符或字符串,如图如果是一个字符,则会一个字符这样比较,字符串则一个字符串为单位进行比较),计数(expr在循环中用于增量计算。例如esult=`expr $no1 + 1`,初始化循环值为0,然后循环值加1,可以使用反引号替代命令实现增量计算)
不同括号的表示意思
$( )用于给变量赋值(括号里面是命令,不是普通的变量值)
${ }用于变量替换,和$变量名一个意思
$[ ]用于算数计算,[ ]里面出现的只有数字
$(( ))和$[ ]相同,都是计算,出现非数字就报错
在语句判断中,
(( ))、[ ]和[[ ]]都用于条件判断。但它们之间存在一些关键差异,主要涉及变量扩展、模式匹配和算术比较等方面。
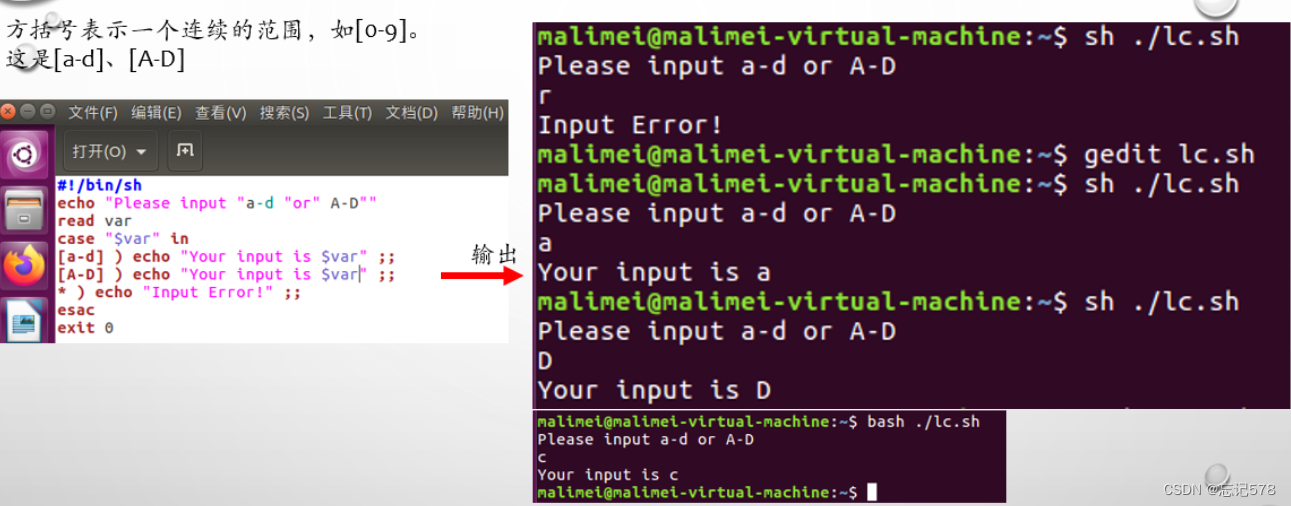
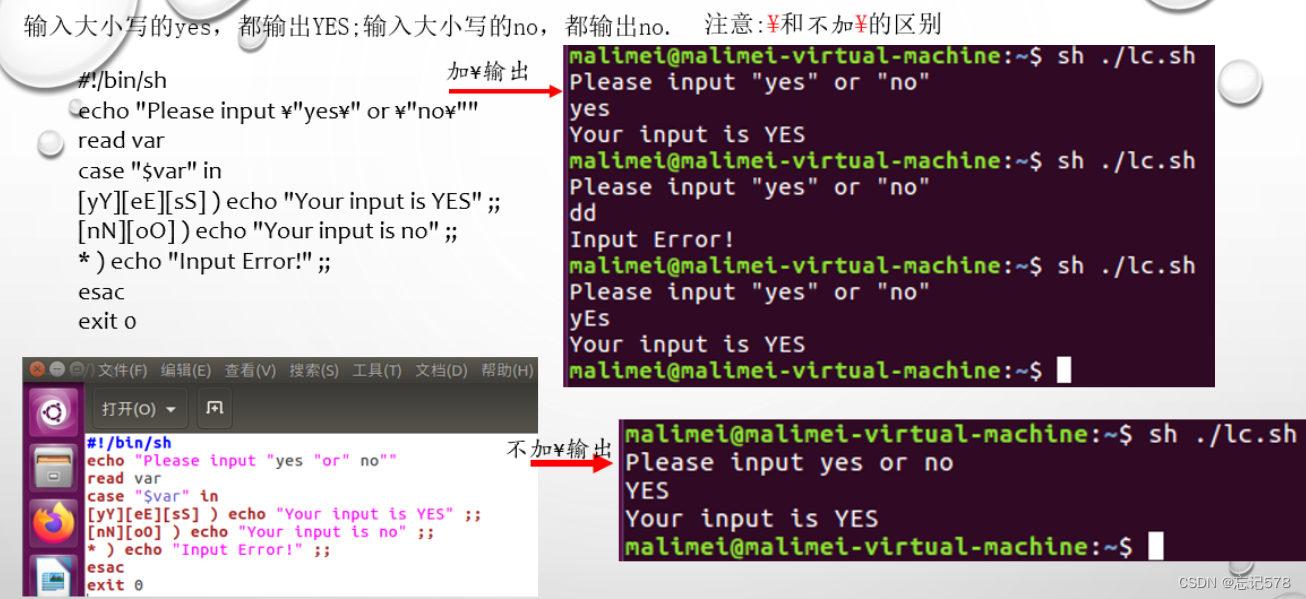
case语句
case 变量 in 模式1) 命令1;; 模式2) 命令2;; ... 模式N) 命令N;; *)默认执行的命令序列 ;; esac说明:case行尾必须为in,每一个模式必须以)结尾,以两个分号表示命令序列结束,
匹配模式中可使用方括号表示一个范围,如
使用竖杠符号| 表示或,最后的*)表示默认模式,(必要)
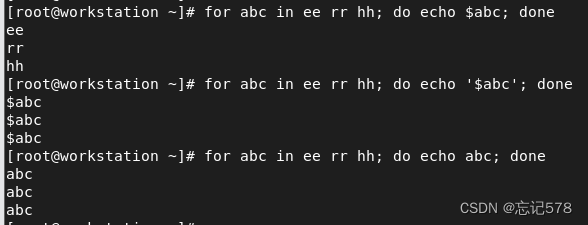
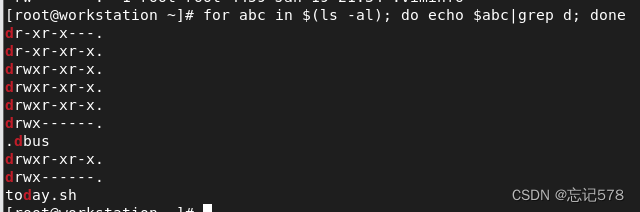
for语句(也可以写成c语言的形式,记得要用(( ))括起,这样就不用in了)
for 变量 in {开始数字..结束数字} do # 要执行的代码 donewhile语句和until语句都是下面这样的形式
while/until 条件 do # 要执行的代码 done但是二者有区别,与
until语句的关键区别在于条件测试的时间点:while在每次迭代时都检查条件,而until只在循环开始时进行一次条件测试。如果你希望在某个条件下立即停止循环,那么使用
while语句可能更合适;如果你希望在条件不再满足后仍然执行完循环体内的所有语句,那么使用until语句可能更合适。










使用正则表达式匹配命令输出文本
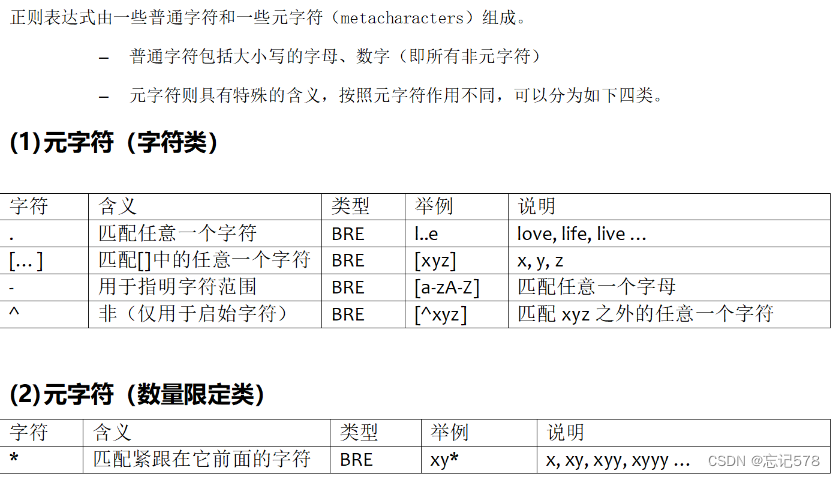
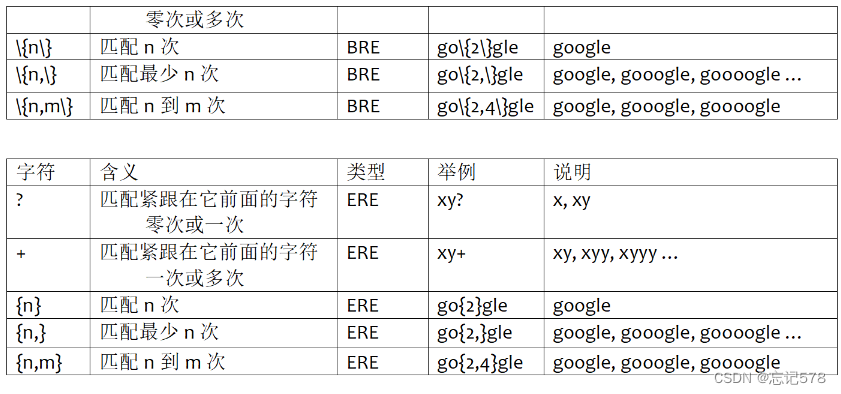
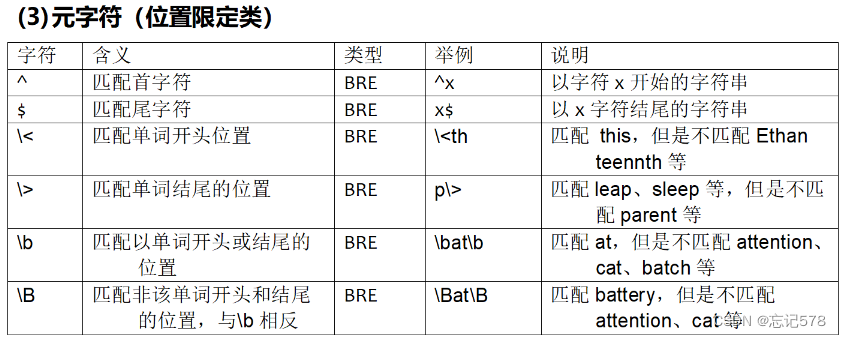
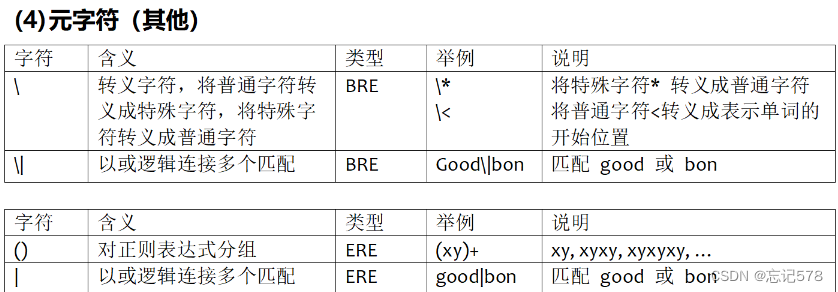
正则表达式也有分类,这里主要说的是基本正则表达式(BRE)和扩展表达式(ERE,是BRE的扩展版本,具有更强的处理能力,并且增加了一些元字符,)
元字符(Meta Character)指的是键盘上可输入的、对于Shell来说具有其他特殊含义的字符。这些字符具有特殊的意义,可以替代其他的字符,简化字符串的匹配过程。不同的Shell中,元字符的具体含义和用法可能有所不同。
(上图可以明显发现ERE除用于转义,在限定数量时没有\组成,
注意^在[ ]内是非的意思,即不匹配。^$如果中间什么内容都不加,表示匹配空行,注意空格也算字符
正则表达式在命令中的应用
注意:单引号和双引号都可以用来包围正则表达式,因为正则表达式本身不包含特殊字符。但是,如果你需要在正则表达式中使用元字符,并且希望它们被解释为特殊含义,那么应该使用双引号(如果你的输入中没有空格、管道符、分号等特殊字符,那么加不加引号可能没有区别)为了避免潜在的错误和不确定性,建议总是使用引号来包围正则表达式。
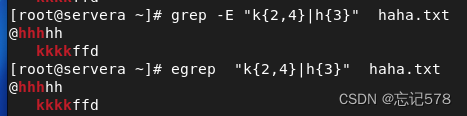
grep、sed和awk通常被称为文本处理的三剑客。(一般都以行为单位进行处理)grep:默认使用基本正则表达式(BRE),但可以通过
-E选项启用扩展正则表达式(ERE),或者用egrep命令,这时使用扩展正则表达式。grep用于搜索匹配正则表达式的行,并将这些行打印出来。
如上图的文本内容,我们匹配k出现2-4次或者h出现3次及以上的行,或者如下用扩展正则表达式来匹配
sed(Stream EDitor):是一个流编辑器,用于对输入流(或文件)进行基本的文本转换。默认使用基本正则表达式(BRE),但同样可以通过
-E选项启用扩展正则表达式。sed用于对文本进行编辑和转换,如替换、删除、插入等。awk:使用一种类似于扩展正则表达式的语法,但也有一些自己的特殊功能和语法。
awk是一个强大的文本处理工具,用于报告生成和数据提取。发现这篇文章对这三个个命令有很详细的介绍,Linux 文本处理三剑客:grep、sed 和 awk - Beritra的文章
补充:关于通配符和正则表达式
正则表达式:主要用于文本处理,如搜索、替换、匹配等。它是对字符串(包括普通字符和特殊字符)操作的一种逻辑公式,用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,用来表达对字符串的一种过滤逻辑。语法较为复杂,包含许多元字符和特殊结构,用于创建复杂的搜索模式。例如匹配任意字符,
*匹配前面的字符0次或多次(而通配符是匹配任意次)。通配符:主要用于文件名匹配,特别是在shell命令行中。例如,使用通配符来匹配多个文件名(
*.txt会匹配所有以.txt结尾的文件),且相对简单,主要包括*(匹配任意字符序列)、?(匹配任意单个字符)和[](匹配方括号中的任意一个字符)等。



计划将来的任务
1、一次性的任务
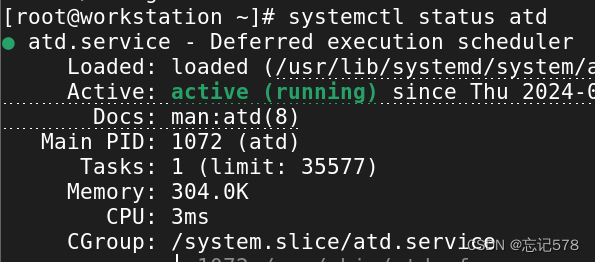
at命令需要atd服务的支持才能正常运行。在一些系统中,atd服务可能默认未启动,你需要手动启动它才能使用at命令。可用service atd start或是systemctl start atd来启动。
(补充:查看atd服务状态时,如下两个命令都可以,
service atd status和 systemctl status atd 都是用于检查 atd服务状态的命令,但它们适用于不同的操作系统和系统管理工具。
service atd start: 这个命令是在较老的系统版本中使用,它依赖于系统的 init 脚本系统来管理服务。在一些较旧的 Linux 发行版或某些系统中,service命令是用来管理服务的常用工具。service status atd: 这个命令是在使用 systemd 的系统上使用的,它是较新的系统和服务管理工具。systemd 已经成为许多现代 Linux 发行版的默认初始化系统和服务管理器。
在选择使用哪个命令时,需要考虑你的操作系统版本和系统管理工具。如果你的系统使用的是较旧的 init 脚本系统,那么应该使用 service atd status。如果你的系统使用的是 systemd,那么应该使用systemctl status atd 。
用at命令创建计划任务
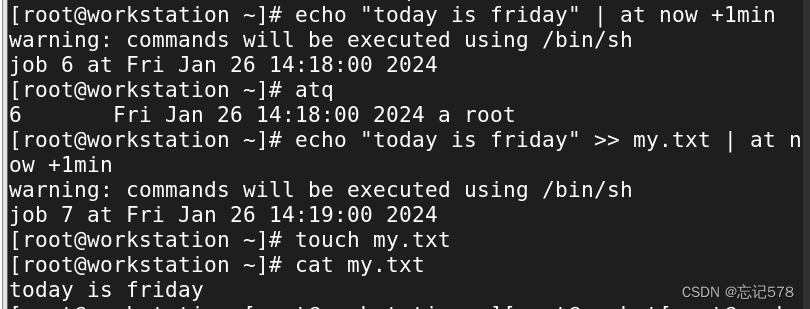
只要在at后面加上要执行的时间即可
如上图所示,一开始我设置了一个计划是在一分钟后打印一句话,但是到时间后并没有像我预想的那样在屏幕输出,但其实这个计划已经设置成功,如上用atq即可查看任务队列。接着我又创建了一个计划,将话输入到一个文本中,可以发现到预定时间后成功打印。
同时我们可以用watch去监控我们的计划,当时间一到,执行完后将会消失在队列中,
(默认情况下,上述watch命令将每隔2s更新一次atq的输出,从队列中删除延迟作业后,按ctrl+c退出watch并返回到shell提示符)
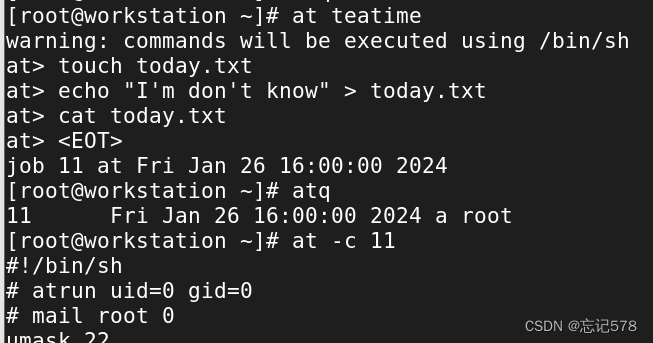
也可以不用管道符分隔,直接先输入指定时间后在输入执行的操作,写完之后,ctrl+D即可退出继续编辑任务。
上面是用命令at -c 作业编号,查看作业内容,可以看到中间还有很多内容输出,最后几行部分才是我们设置的作业内容。
at命令用于在指定时间执行一次性任务,而atq命令用于列出当前用户的所有at作业。
atq命令用于列出当前用户的所有at作业。它可以显示作业的作业号、提交时间、执行时间等信息。
atrm 作业编号,可删除作业
at -q 参数用于指定队列名称,可以使用一个字母来指定队列名称。默认情况下,at 命令将作业添加到默认队列中,可以使用 -q 参数来指定其他队列。例如,要将作业添加到名为 "b" 的队列中:echo "date" | at -q b 17:00
2、周期性的任务
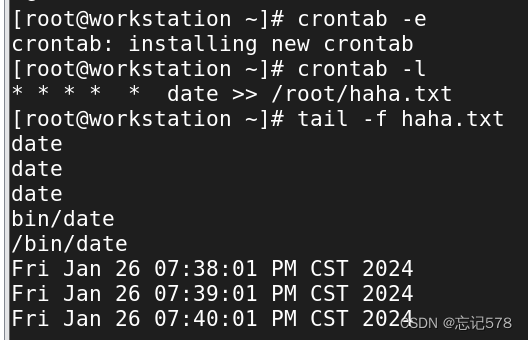
使用crontab命令创建任务
1\打开crontab编辑器。在终端中输入
crontab -e,将会打开默认的文本编辑器(通常是vi或nano),用于编辑crontab文件。
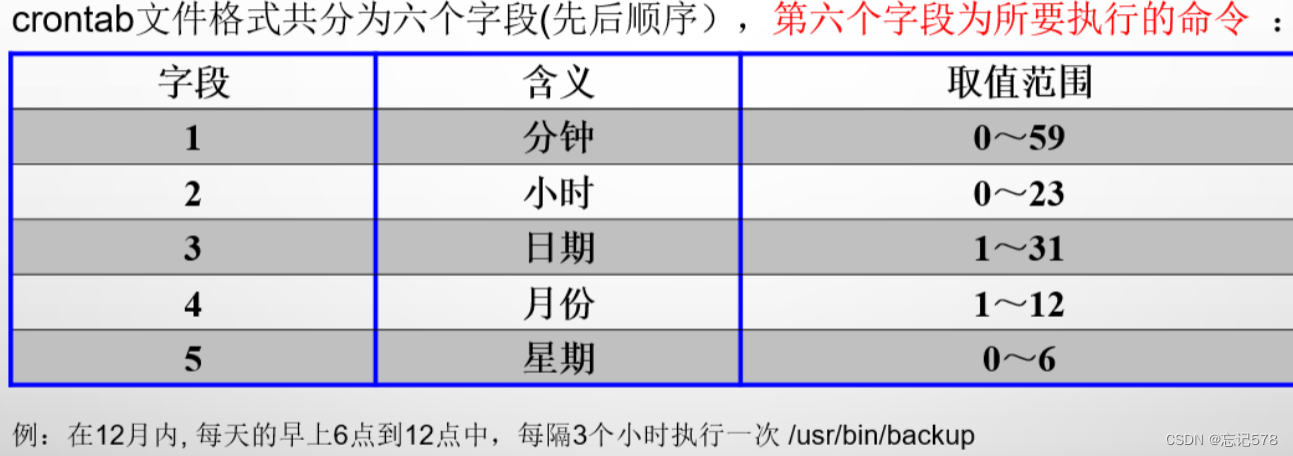
2\添加任务。在编辑器中,按照crontab的格式添加任务。Crontab的格式由五个字段组成,用空格隔开,分别是分钟、小时、日期、月份和星期。每个字段可以是一个数字、一个星号或一个连字符,表示不同的值或范围。例如,
* * * * *表示每分钟执行一次任务,0 * * * *表示每小时的第0分钟执行一次任务。4\保存并退出编辑器。
在终端中输入crontab -l查看当前用户的crontab任务,将会列出当前用户的crontab任务。
crontab -r将会删除当前用户的crontab任务。如果需要修改crontab任务,可以再次打开crontab编辑器,找到要修改的任务进行修改,然后保存并退出编辑器。
如上记得编辑执行的文件的文件其需要写绝对路径,如上/root/haha.txt,
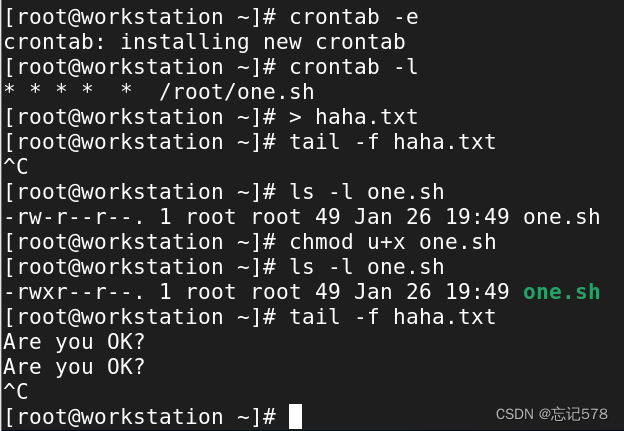
如上图,当我想执行一个脚本时,因为其没有执行权限所以在指定时间也没有什么反应,没有成功执行。而后添加执行权限后就可以了。
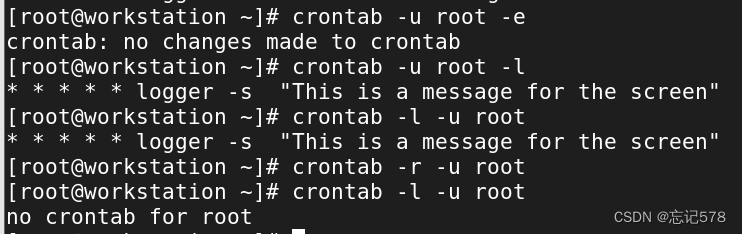
如上各个选项都可以搭配-u 用户名来使用。
可以知道即使是用echo创建任务去定时输出也不会在屏幕上显示出来。







调优系统性能
通过设置调优参数和调整进程的调度优先级来提高系统性能
tuned守护进程利用反映特定工作负载要求的调优配置文件,以静态和动态两种方式应用调优调整。
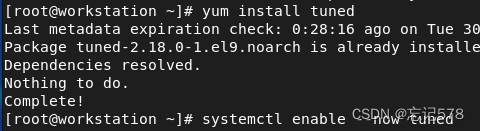
安装并启用tuned
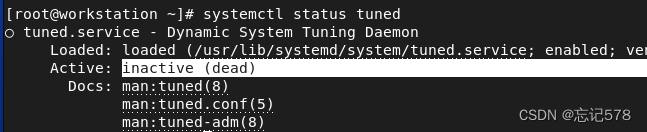
如果本来就安装好了,可以用以下方式查看并启用
查看服务是否启动
启动该服务
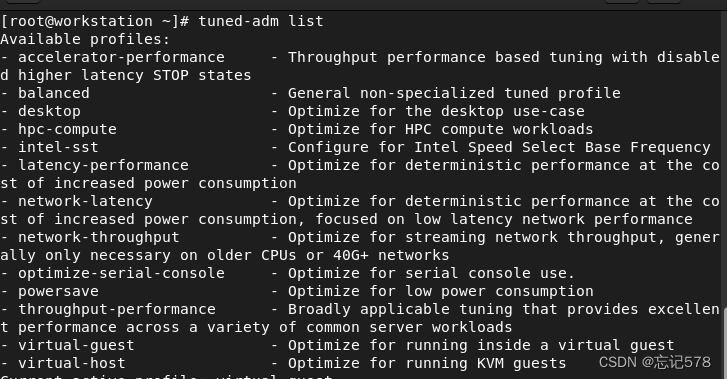
选择调优配置文件
tuned-adm是一个调优配置命令,tuned-adm list命令可以查看当前系统支持的所有调优配置文件。
如下
如果要查看当前系统处于什么调优配置模式,可以用如下命令
可以看到当前系统是virtual-guest模式,如果想修改模式,可以用命令tuned-adm profile 调优配置文件名这个命令来设置,比如设置省电模式,用powersave调优配置文件,则用如下命令
如图一开始是virtual-guest修改成powersave
如何为系统选择建议的tuned配置并设置为默认值?
如上用tuned-adm recommend命令查看系统推荐的模式,然后按照命令设置,查看




使用ACL控制对文件的访问(ACL访问控制列表)
目的:为了让不同的用户或者组对同一个文件具有不同的访问权限
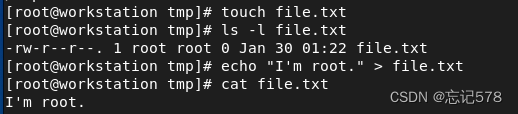
例如一个文件的信息如下
rw-r--r-- root root file.txttom用户想要rw权限 student用户想要r-x hello用户需要r--权限如上不同用户需要不同的权限,但是用chmod不能满足多种情况,所以可以用ACL列表来设置,把不同用户的需求写到列表里,并设置需要的权限
如下图,我们创建一个内容如下的文件,可以发现对于其它用户,只有可读权限
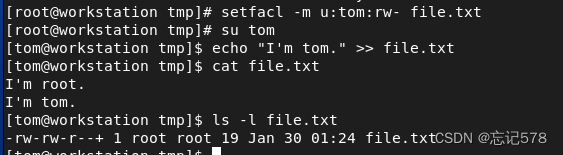
对于tom,student,hello等其它用户来说,对file只有可读权限,这是可以用setfacl命令对各个用户需要的权限进行设置
如下没有设置时去访问该文件被拒绝
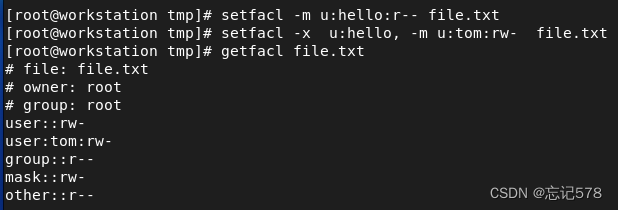
用setfacl命令对tom对file.txt文件的权限设置为rw-,则下面成功对该文件进行读写
设置完成后再次查看可以发现file.txt文件的权限字段中多了一个+,这个代表该文件的其它用户具有扩展权限,而我们用ls -l这个命令对该文件权限的查看是不完整的,我们用ls -l查看到的第二个字段由r--变成的rw-是表示的是tom用户的权限,而+号前面的r--则是用户组的权限,其它用户的权限没有显现出来,不能用ls -l完整查看
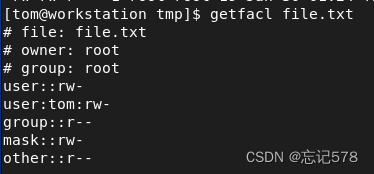
getfacl专门用来查看设置了acl列表文件的权限
我们在对两个用户的权限进行设置
上面是对用户进行设置,用u,对组则用g,对组设置后,则为自定义用户组权限
对上面的查看到文件的权限字段进行分析,
user::rw- 文件拥有人权限 user:student:r-x 自定义用户权限 user:tom:rw- 自定义用户权限 user:hello:r-- 自定义用户权限 group::r-- 文件拥有组权限 mask::rwx 掩码(限制) other::r-- 其它用户权限掩码限制自定义用户,自定义组的权限,限制它们的权限不可以超过掩码,即如果掩码为r--,则我们用setfacl设置某个用户的权限为rw-时,因为权限超过掩码,所以会变成r--
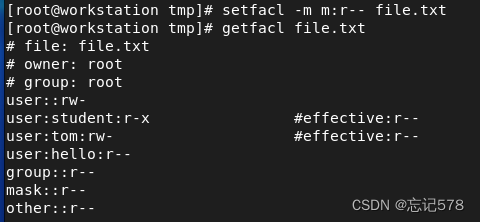
当然我们也可以设置掩码的值,用m:掩码值
如上可以发现,超过掩码的值则会做出相应的变化,如右边真正生效的权限所示
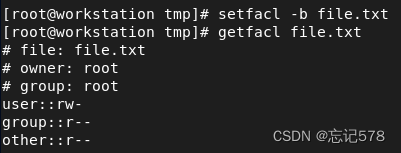
如果要删除所有用acl列表设置的权限,用选项-b
我们也可以删除对某个用户或组的权限,用选项-x ,u指定用户,g指定组,当然也可以在删除的同时,设置,只要用逗号隔开就好。
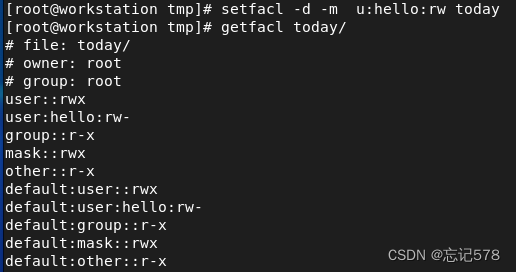
对文件夹我们也可以设置对应的权限,如果是对文件夹本身设置时,那么和对文件设置的命令一样,但如果是对文件夹内的文件需要设置一样的权限,则需要递归设置,
需要用选项-R进行递归设置(放在-m之前),如下
上面的-R是对文件夹内存在的文件或文件夹进行递归设置,但如果要对在文件夹内未创建的文件或文件夹进行设置,则需要用d(有两种表现形式),d表示default
把d放在u前面也可以,如下
如果想要设置,文件夹里的文件没有执行权限,文件夹有执行权限,则可以用X来设置,这样即使递归也会同步分开设置好。


管理SELinux(Security-Enhanced Linux)安全性
SELinux在Linux内核中提供了一种基于域-类型模型的强制访问控制机制,旨在增强传统Linux操作系统的安全性(传统是对用户/组/其它权限安全模型的访问控制),解决传统Linux系统中自主访问控制(DAC)系统中的各种权限问题(提供更加复杂的规制控制,称为强制访问控制)。
启用SELinux后,进程无法随意访问不包含在任务之中的文件或路径,从而增强了系统的安全性。
可以用getenforce命令查看系统使用的是哪个模式,如下图所示显示当前是强制模式
许可模式未permissive,禁用模式为disabled,
如果想要修改模式可以用命令setenforce,例如修改当前模式为permissive,如下图修改并查看
但是禁用模式是不能设置的,如下图只有两种设置模式
即设置enforcing强制模式也可用命令setenforcing 0来表示,permissive为1
注意用setenforce命令设置模式是临时的,如果重启则又会失效,如果想修改并永久生效,则要修改配置文件。(配置文件有两个修改路径)
如上图所示的/etc/sysconfig/selinux和/etc/selinux/config,前者是后者的软链接,修改二者之一即可。如下图修改其中一个配置文件为例,将文件中下面的模式修改自己想要设置的模式即可(修改配置文件好像可以设置disabled),保存退出。并重新启动机器才会生效。
selinux是如何对系统进行保护的:
selinux是基于策略(安全上下文的类型)对文件、目录进行保护,当类型相同时,可以访问,不同则不可以访问。(对于每一个文件或是进程,都有对应的安全上下文)
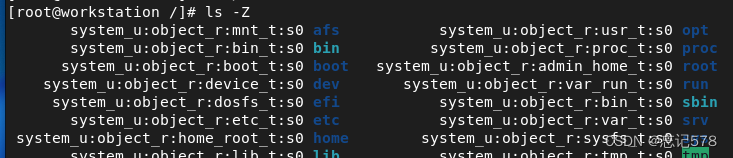
查看安全上下文,可以用ls -Z命令查看(如下,查看根目录下文件的安全上下文),每一个文件在创建时都有自己的安全上下文。
安全上下文一共由四个字段组成(用户、角色、类型、敏感度)
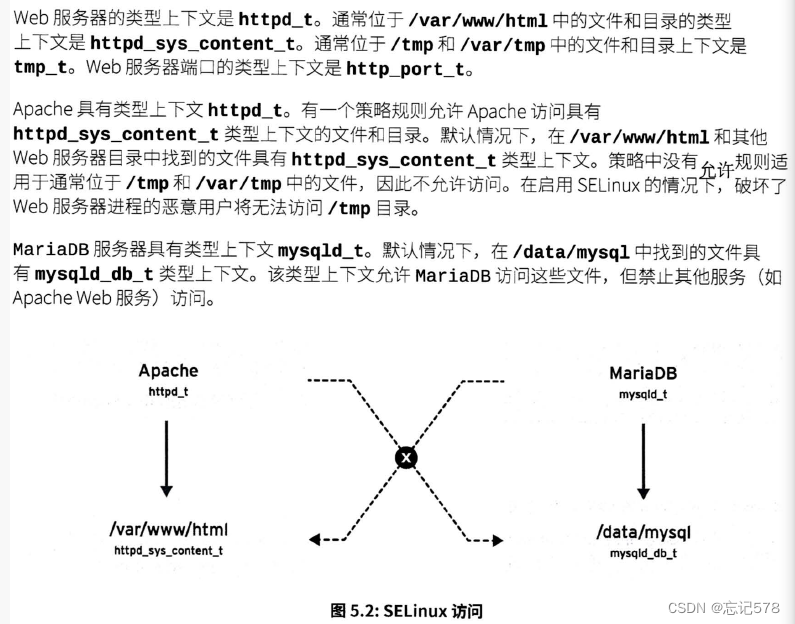
当上面第三个字段的type相同时(指访问和被访问的上下文类型相比较,当开头相同时)就可以访问,例如:httpd_t和httpd_sys_content_t相同,和tmp_t不同。
如下图示例,
左右箭头指向,代表可以匹配并访问,中间打x因为上下文不匹配,拒绝访问。
当上下文不同不匹配时,可以
1、临时关闭selinux来访问,访问完后再打开(即使用setenforce命令修改selinux模式)
2、直接修改文件安全上下文,使用chcon -t命令
如果想将文件夹的文件内容都递归设置(用restorecon -R(v) 命令),可以用restorecon命令,但是如果使用chcon命令修改文件夹的上下文后有使用restorecon修改则文件夹的上下文有会变回原来默认的上下文。
所以用永久修改上下文的规则,则在使用restorecon命令进行修改之前用semanage fcontext命令(该命令要配合扩展的正则表达式)。这样就不会还原回原来的上下文
即使用semanage fcontext修改要修改上下文的文件,再用restorecon命令即可永久修改上下文。
如上图使用semanage fcontext后再用restorecon对上下文进行修改。
selinux端口安全(使用系统防火墙和selinux规则来控制与服务网络连接)
selinux端口标记(端口和安全上下文之间的对应)
查看当前计算机所有端口对应的安全标签是什么,或者说获取当前端口标签分配概述,
用命令semanage port -l 查看(下图我只是查看关于http的端口标记)
接着我们用80端口访问一下服务器,发现可以成功访问
但我们可以用80端口访问时因为系统对80端口添加了selinux标签(http_port_t)代表80端口等允许去访问(打了标签代表被放行可以去访问)
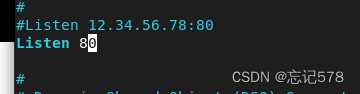
同样的也可以改变http服务器默认的80端口,如下改为89
编辑/etc/httpd/conf/httpd.conf 修改如下数字,将80改为89
查看改行已经修改为89,修改完记得要重启一下服务才会生效(毕竟是修改了配置文件)
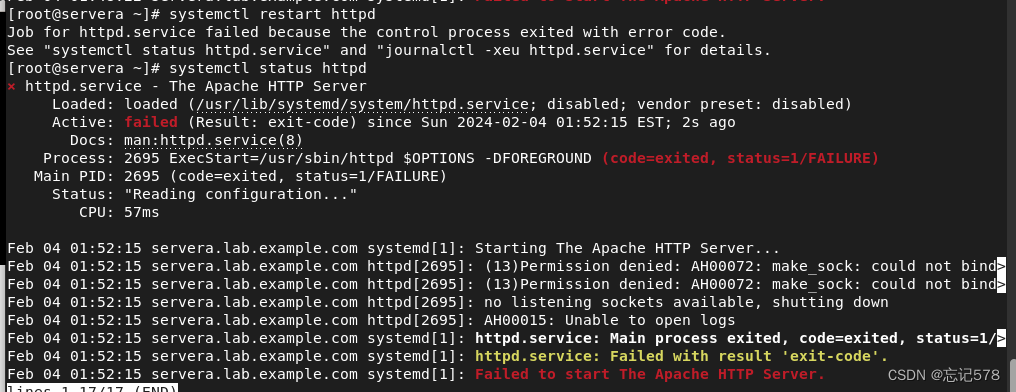
但是可以发现我们重启服务失败。查看httpd服务状态也是异常
这是因为我们修改了默认访问端口为89,但是我们知道该端口并没有被打上标签,如下该标签的端口中,没有89(下面有81,443等,这些被打上标签的端口如果设置成默认访问端口则可以正常访问)
虽然知道原因所在,也可通过报错提示去访问一下日志信息,进一步验证错误
可以发现上图就是在说89端口访问被拒绝
解决办法有两种:
1、修改selinux模式,即关闭selinux(只要强制模式才会限制访问)
如上图修改为permissive模式后可以正常启动服务并用89端口访问
2、将端口打上标签,我们设置的端口一位内没有selinux标签而拒绝访问,所以我们可以打上标签,semanage port -a -t 标签名 -p 协议 端口号
如上图所示,利用命令打上标签后,查看到该标签确实有了89端口,且我们重启该服务,并且将selinux模式设置回强制模式,在用89端口可以成功访问服务器页面
(补充:一开始没找到httpd服务
如上都查不到httpd服务,后面发现原来是自己没有安装服务
如下先安装服务,再启动服务
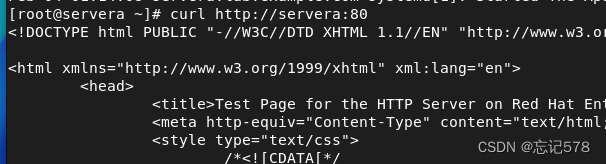
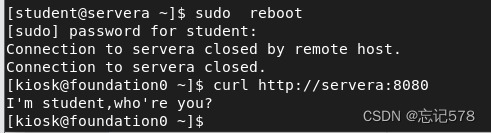
启动后再用curl命令访问一下(curl是一个用于传输文件的命令行工具,支持多种协议,如HTTP、FTP等)
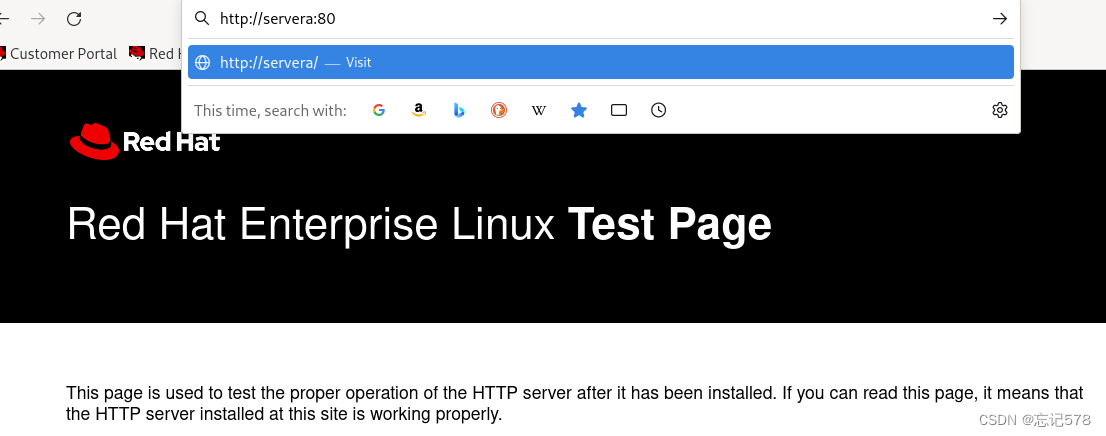
上面查看到的是界面源代码,如下在浏览器输入http://servera:80查看((浏览器会解析和渲染网页内容,而
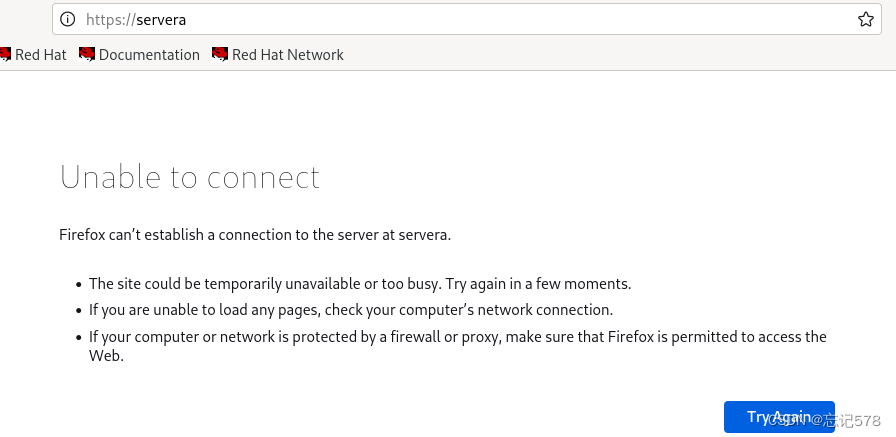
curl命令只会获取网页的源代码),得到如下界面。因为我们没有有把防火墙关闭,不能访问到80端口的界面
我们把防火墙暂时关闭一下(systemctl stop firewalld),再查看
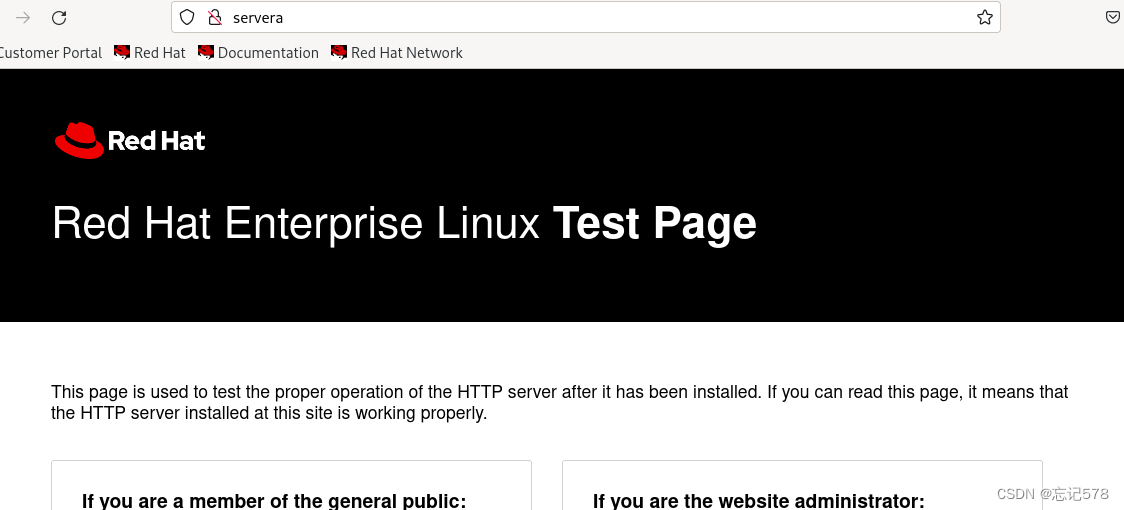
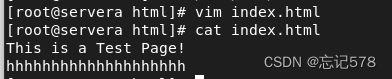
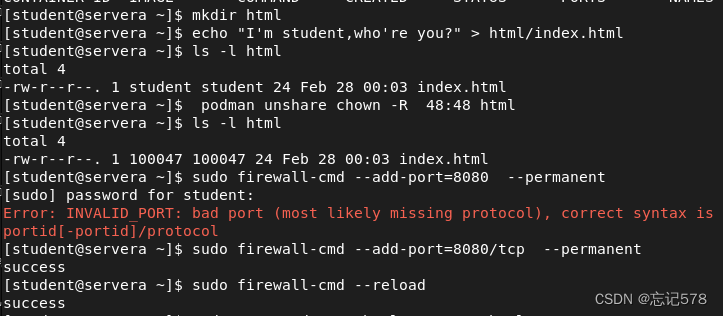
这个界面即是之前查看到的源代码界面,我们也可以自己去写一个静态测试页,只要在/var/www/html下创建一个html文件即可(记得以html为后缀)
如上编辑了一个测试界面index.html,内容是两行文字,我们用curl命令本地访问来验证一下
发现可以成功访问,如下在浏览器上也可以成功访问
(
curl http://servera:80是用来请求在服务器servera的端口 80 上运行的服务。而/var/www/html是许多 web 服务器的默认文档根目录,如果在这个目录下有可访问的 HTML 文件,那么这些文件就可能被访问)针对前面说的当我们说的关闭防火墙后才可以访问80端口(80是http默认访问端口)的问题,我们可以用命令实现即使不关闭也可以正常访问,如下注意是service=http,不是httpd,因为httpd是守护进程,服务名叫http
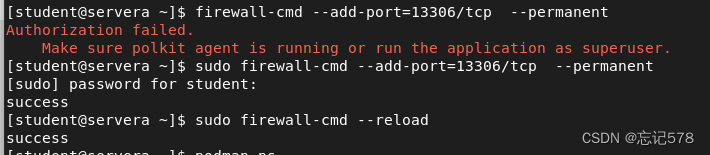
同时也可以设置放行的端口
但是如上方法设置放行这个服务(即可以访问默认的80端口),只是暂时的效果,如果重新启动防火墙(firewall-cmd --reload)则设置失效。
永久放行只要在后面加个选项--permanent即可(不管是放行服务还是端口都可这样加),并重启一下防火墙的服务。






















管理基本存储
关于硬盘
硬盘的命名
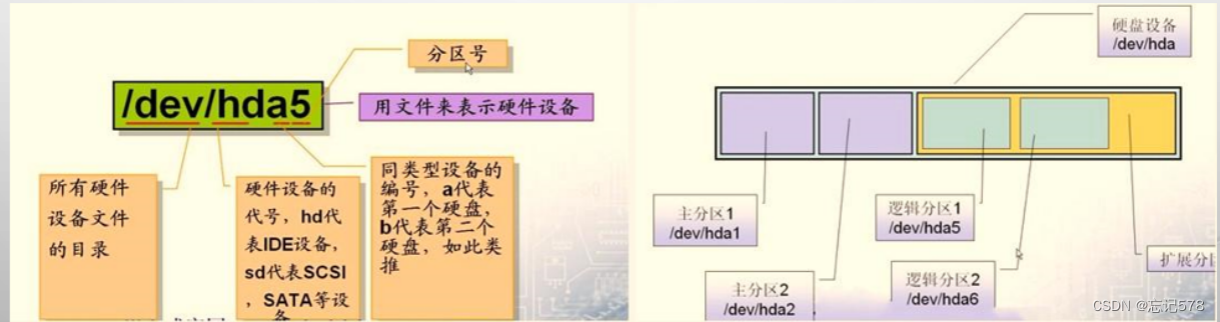
红帽系统支持两种主要的分区表格式:MBR(主引导记录)和GPT(GUID分区表)。
硬盘小于等于2T用MBR格式进行分区(有4个主分区),大于则用GPT格式进行分区(总共可以分128个分区)
一般利用MBR格式进行分区时,先创建三个主分区(primary),最后一个主分区制作成扩展的形式,将剩余的所有容量添加进去,也叫扩展分区。第三个默认为扩展分区(extended),扩展分区可以继续进行逻辑层面的划分,划分的区域称为逻辑分区,逻辑分区最多可以划分15个逻辑分区。所以最多可以划分15+3=18个分区。注意:如果直接创建四个主分区,如果还有剩余的空间则剩下的空间不能再使用。
主分区的编号为为1到4,可以指定,但一般都按顺序来(即1234,而不是1432)
在红帽系统中,有两个主要的硬盘管理工具:
fdisk和parted。
制作磁盘的过程,创建分区(可选,如果不想创建,全部空间一整块拿来使用也是可以的),格式化,挂载
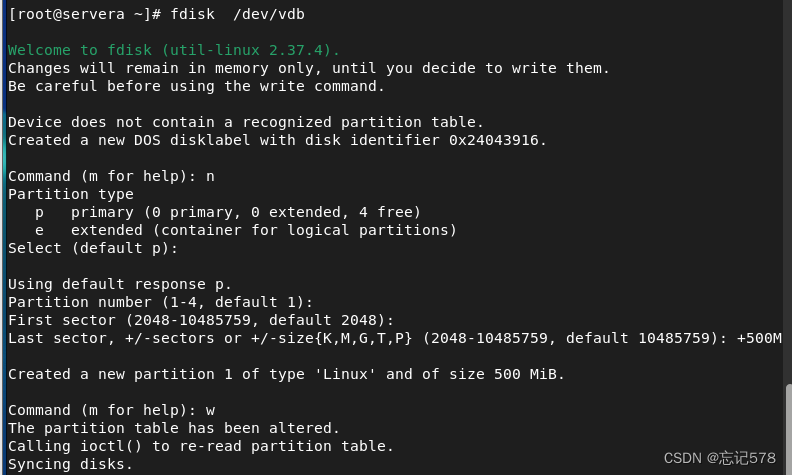
1、下面使用fdisk来创建分区
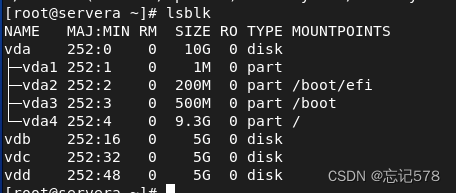
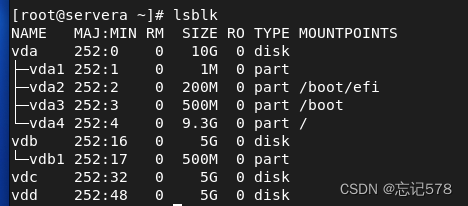
如上查看磁盘分配情况,接下来我们将vdb进行分区,fdisk /dev/vdb (要写绝对路径)
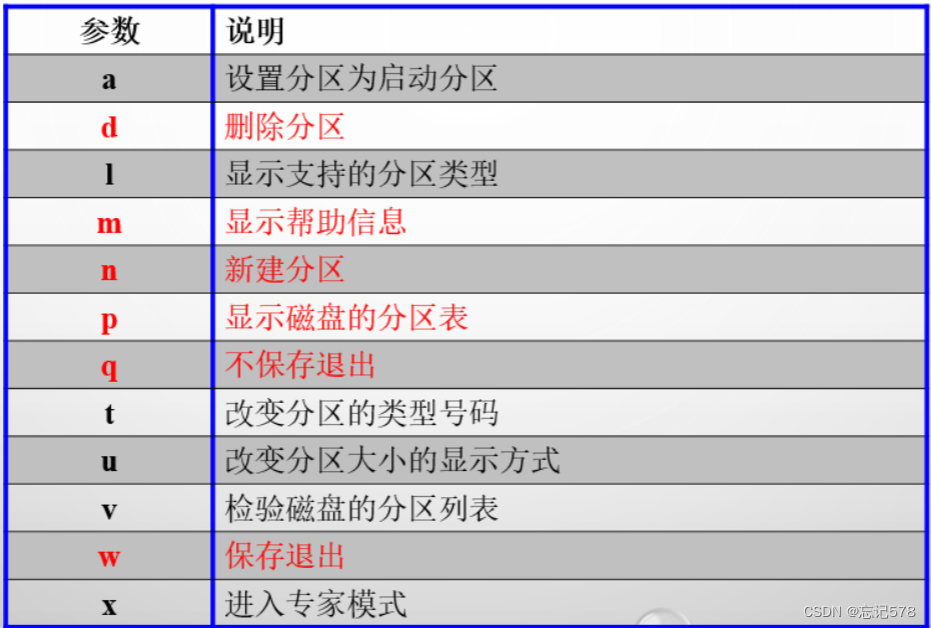
如上当不知道怎么进行,输入m后得到如上提示,只要输入字母即可
一些常用的字母:
n:(new)新建一个分区。d:delete 删除(如果要删除要使用后的分区,则要将内容删除,且卸载后才能删除)。p:print 打印分区信息。w:操作后要刷新分区表,保存该分区信息。q:不保存,直接退出。
(再创建完一个分区后,可以继续创建,然后再保存退出,即可以连续操作)
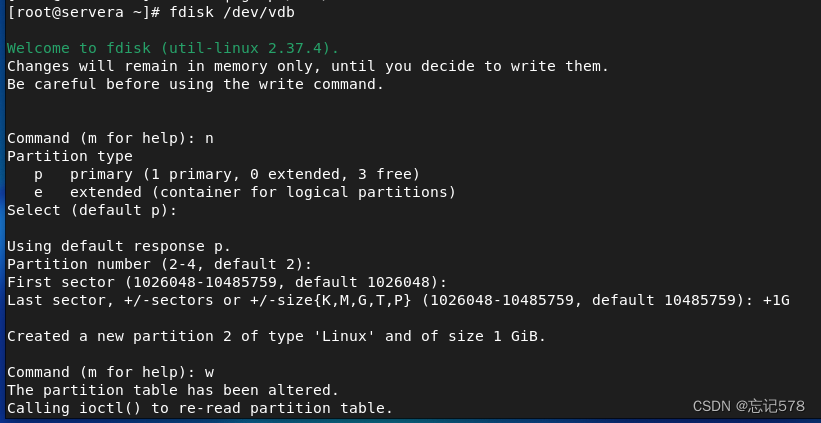
如上分别根据提示输入字母,n创建一个分区(给出提示p代表创建主分区,e创建扩展分区),输入p创建主分区(如上我直接回车,默认创建主分区),输入1-4中的数字作为主分区编号(如上直接回车,默认为1,因为这是第一个创建的主分区,默认按顺序编号),选择2048-10485759的扇区范围,默认第一个分区从2048块扇区开始(如上回车,则选择默认,为什么是2048而不是从第0块扇区开始,因为2048扇区之前预留给EFI启动引导,大小为1M),空间大小划分从第一块扇区开始,最后一块的扇区可以先择直接输入扇区或者用大小表示(如上+500M,即从指定扇区开始500M大小的空间作为分区大小)。
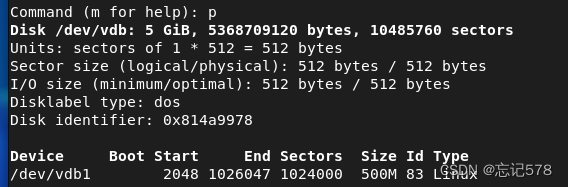
分区成功后,如下查看到vdb1
最后输入w保存这些分区的设置,如果没有保存则相当于没有分区成功,如下用p打印我们分区情况,
但是如果没有保存且设退出设置分区的界面后,好像没有办法恢复(之前再ubantu中可以使用
partprobe命令来使内核重新读取分区表,从而应用之前的分区设置)当我们创建扩展分区时,一边拿会默认将剩余空间分配给扩展分区,且如果要使用该分区则要在对磁盘进行分区进行划分,即fdisk /dev/vdb ,这时输入n,则会自动帮我们创建逻辑分区(即当我们按顺序划分完三个主分区后,划分第四个分区为扩展分区,其依旧是有名字的,即vdb4(其不能被直接使用,不能进行格式化或者存储数据,要划分逻辑分区后使用,其大小显示的是记录分区引导的大小,例如1K),而在进行划分则是对vdb4进行划分逻辑分区,从5开始)
实际也可以直接创建扩展分区,但建议先划分完主分区,再划分扩展分区。
2、格式化(制作文件系统)
分区创建或调整后,你需要对分区进行格式化、创建文件系统才能正常使用。
注意:不能对扩展分区格式化
如下常见文件系统
在windows系统中的文件系统格式NTFS、FAT32。NTFS存储单个文件大于等于4G,FAT32存储单个文件小于4G。linux系统默认不支持NTFS格式,如果想要使用这个系统格式,则要下载相关软件包。
如下图可以设置的文件系统格式,其中fat和vfat和windows中的FAT32是通用的。
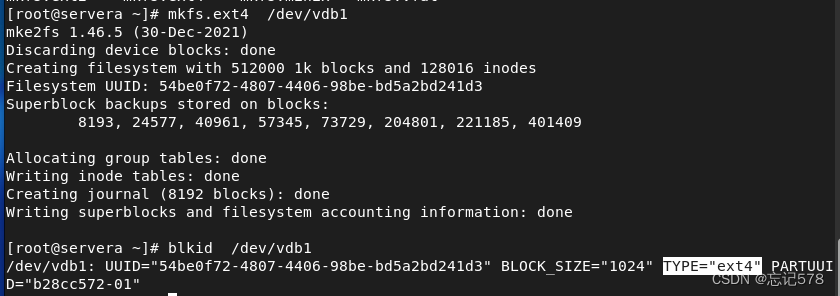
上面分区完成得到/dev/vdb1,对其进行格式化,如下图用mkfs.文件系统格式 设备名,发现这个命令也可以(mkfs -t 文件系统格式 设备名(绝对路径))
如上使用blkid可以看到其文件系统类型为ext4,当然使用lsblk也可看出。
注意:不同格式的返回结果不同,如上设置ext4格式化后出现的信息,如果设置成别的格式例如vfat则会不同,如下图
如果想要修改文件系统格式,如下图再格式化一次
(补充:
3、挂载(分为临时挂载(需要手动挂载)和永久挂载(会自动挂载))
在windows系统中给磁盘格式化完就可以直接使用了,但在linux中则要挂载完才可以使用,因为不能直接使用磁盘,需要手动指定一个挂载点(一个空目录),并将该分区挂载到这个目录下。这样就可以通过访问这个挂载点来访问该分区上的文件和文件夹。
用mount进行临时挂载,当系统重启后则挂载设置会失效。
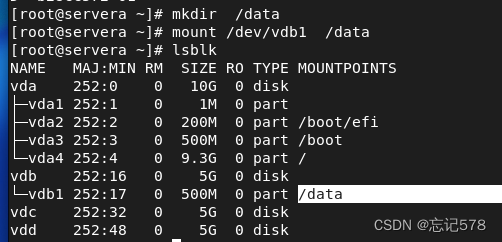
mount 设备名 目录(挂载点)
如上我创建一个目录,并将其作为/dev/vdb1的挂载点,之后对该目录进行操作就相当于对该磁盘进行存储使用。而当挂载到某个空目录后,存储了某些文件,则用umout卸载后,再在对该分区进行挂载则也会有之前存储的文件,由此可以知道文件是存储磁盘里的
卸载可用umount命令,umount /dev/vdb1(设备名) 和umount /data(挂载点)的效果相同。
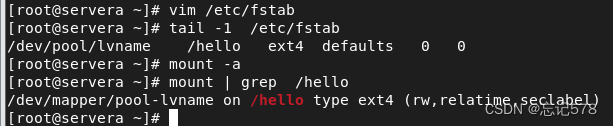
永久挂载,编辑配置文件/etc/fstab
在该文件中每列内容的字段含义
1、设备的uuid(可以通过blkid命令查看,如下图所示,当然也可以直接用blkid),可以用设备名代替。
2、挂载点。
3、文件系统类型。
4、挂载选项,一般用defaults就够了。defaults则系统会寻找最合适的挂载选项,到那时如果还不足以满足需求,可以后面再添一些选项,用逗号隔开。再defaults设置并挂载完后想要查看系统给自己设置的挂载选项,可以用mount命令查看自己的分区,如下括号内的字段
5、dump备份的优先级(通常设置为0,表示不备份)
6、fsck检查的顺序(根文件系统应该是1,其他文件系统可以是2或更大)。0表示忽略开机的自动检查(只有启动引导在开机的时候需要自动检查一下),一般都是0。
补充第5和6列意思:
编辑并保存配置文件后,要重启reboot后才能生效
但是不要直接重启让其生效,最好再检查一下编辑是否有误,用mount -a 刷新一下配置文件内容,如果有误则会提示,当没有报错时再去重启,到那时也可以不用重启,因为mount -a命令执行后如果无误则已经生效。
如果有误,再重启开机时,很可能因为编辑错误而导致开机时找不到挂载信息而开不了机,一般可以通过通过grub2救援模式去修改配置文件来解决这个问题。
如果想要卸载,则和上面临时挂载一样用umount命令去卸载,然后删除在/etc/fstab上对应的挂载信息,(然后使用mount -a或者重启,但是其实使用umount卸载完后再去查看已经卸载成功)。
在挂载完后想要删除这个分区时,不能直接用fdisk 设备名,这一命令去删除,要先卸载,然后再删除,且如果删除后,用lsblk查看还是有该分区信息,则可以用partprobe去刷新一下,或者直接重启。
管理交换空间
交换空间(Swap Space)是磁盘上的一块区域,用于在物理内存(RAM)不足时存储不常访问的数据。当系统需要更多的内存资源,但物理内存已满时,操作系统会将部分内存中的数据移至交换空间,以释放物理内存供其他应用程序使用。虽然交换空间可以帮助缓解内存压力,但访问交换空间的速度通常比访问物理内存慢得多,因此它被视为物理内存的补充而非替代。
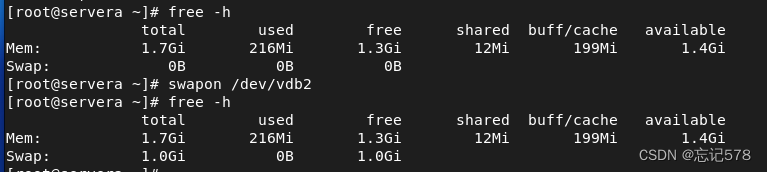
如下可以通过者三个命令查看当前交换空间信息,可以发现当前没有给交换空间分配大小。
接下来创建一个分区用来给后面设置交换空间使用,如下新建过程就是普通的新建一个分区
设置该分区作为交换空间,使用mkswap命令
激活并启用交换空间,使用swapon命令
如上图对比启用前后交换空间的大小,如果要停用则用swapoff 设备名这一命令即可
综上配置为交换空间的操作是临时有效。持久化配置同样要编辑配置文件/etc/fstab.
如上在配置文件的各列情况,因为没有物理挂载点所以直接写swap即可,文件系统格式也写swap,其它没有什么不同。记得用swapon -a命令去刷新一下才会生效
(当我删除对应交换空间的配置配置信息,再用swapon -a去刷新时,发现没有生效,交换空间仍然在使用,所以还是记得用swapoff停用一下,即先停用再删除,刷新🙄















管理逻辑卷
1、创建物理分区:首先,需要在硬盘上创建物理分区,并将分区类型设置为Linux LVM。
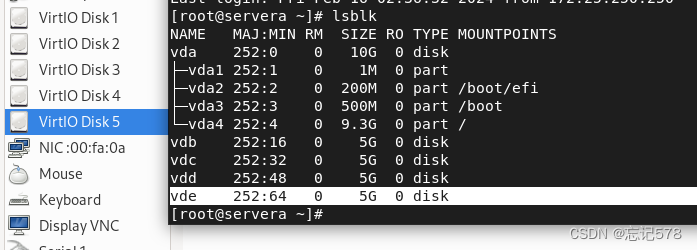
当有足够的物理设备可以制作时,就可以了,如下查看我们还有vdb、vdc、vdd三块磁盘没有使用,接下来让我们会在vdb磁盘创建3个分区来使用(其实直接三块磁盘用都行,不用分区),模拟多个物理设备制作物理卷
注意:一个硬盘分区或整个硬盘都可以被创建为物理卷
如下用fdisk为vdb磁盘创建三个分区
补充:
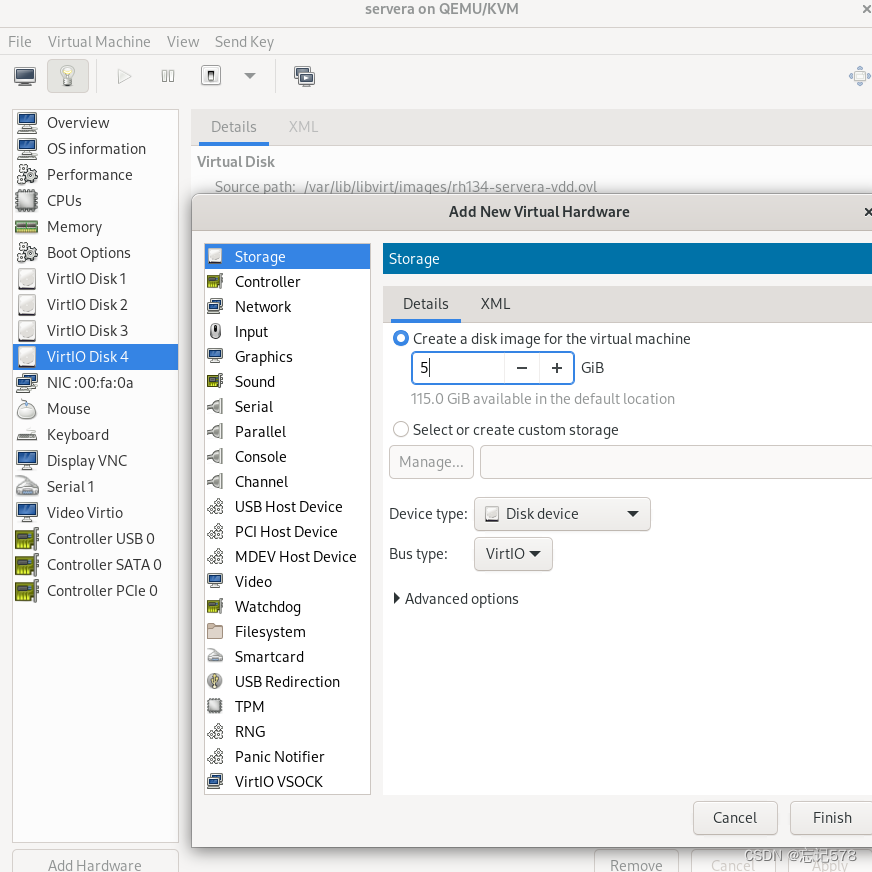
在虚拟机上可以如下添加虚拟磁盘
如上vde即是我们添加的磁盘。
2、创建物理卷(PV):使用
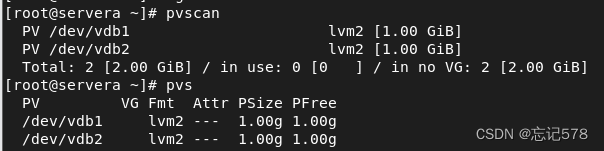
pvcreate命令将物理分区转化为物理卷(Physical Volume)。将/dev/vdb1、/dev/vdb2、/dev/vdb3都创建成物理卷
实际上物理设备或分区在创建成物理卷时,会被划分为多个物理块(物理范围),创建成物理卷后,它们三个名称没有什么变化,
查看物理卷情况,如下pvs和pvdisplay、pvscan命令都可以查看
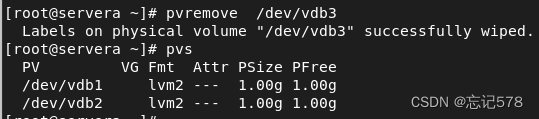
如果已经创建成物理卷,想要删除,则用pvremove命令,如下删除物理卷/dev/vdb3将其还原到普通的物理设备。
3、创建卷组(VG):使用
vgcreate命令将一个或多个物理卷组合成一个卷组(Volume Group)卷组可以看作是一个资源池,其中包含了多个物理卷。
如上用vgcreate将两个物理卷制作成卷组pool,这里取名自定义,我是将其命名为pool,上面我们是将两个物理卷同时创建成卷组,那如果当我们用一个创建完,另一个也想加入相同的卷组是用命令vgextend 卷组名 物理卷
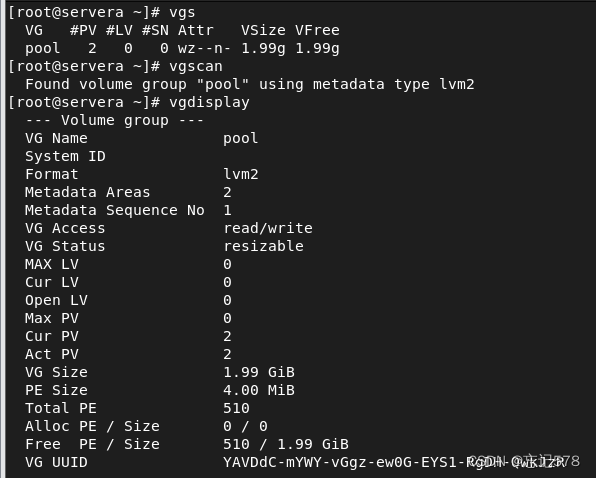
查看卷组信息,如下用vgs或是vgdisplay、vgscan都可
删除卷组用vgremove,如下删除卷组pool
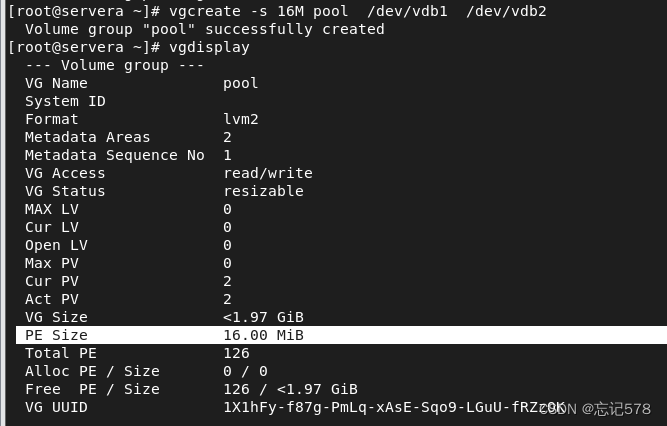
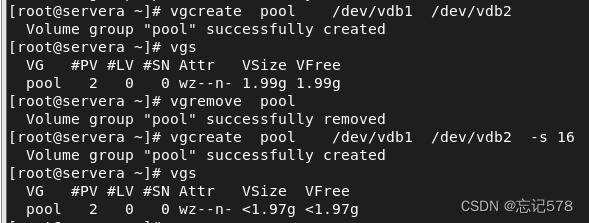
补充:vgcreate -s PEsize 物理卷 命令可指定物理卷PE的大小(PE取值为2的整数次幂,默认为4M),如下图指定为16M(不用带单位,直接数字也可),也可将-s选项放在后面写,即vgcreate pool /dev/vdb1 -s 16
当您创建一个新的卷组时,可以使用
-s选项来指定物理扩展大小,这个设置将应用于该卷组中的所有逻辑卷。物理块的大小决定了逻辑卷的最小可分配空间大小,并影响着存储管理的性能和效率。在创建物理卷时,需要根据实际情况选择合适的物理块大小(必须是2的整数次幂,通常在4KB到1GB之间),以满足系统的存储需求。但是默认的物理块大小可能已经足够,无需进行特别设置。如下可以发现不同的PE大小,最后创建的卷组的大小也不同,一个1.99.一个1.97。这是因为卷组的总容量是基于物理块大小来计算的,而不是基于底层分区的原始大小。
可能因为物理块大小、对齐空间浪费、卷组容量计算等多种原因导致实际大小的差异,如果希望减少由于对齐造成的空间浪费,可以考虑使用更小的物理扩展大小,但这可能会降低性能并增加管理复杂性。通常,建议根据工作负载的需求选择合适的物理扩展大小(即物理块PE大小)。
4、创建逻辑卷(LV):使用
lvcreate命令在卷组内部创建逻辑卷。逻辑卷的大小可以动态调整,且可以跨多个物理卷。上面我们创建了大小为2G(实际是为1.99,可能存在一些内部调整问题)的卷组,现在从这个池子里拿出小于等于总数量的卷组创建成逻辑卷。有两种写法:
用空间大小来计算的写法:(如果不指定单位,则默认时M)
lvcreate -n 逻辑卷名(自定义) 使用的卷组名 -L 1.5G(空间大小)用物理块(PE)大小来计算的写法:(用vgdisplay查看每块物理块的大小,然后自己想要的空间大小除以每块物理块大小得到想要的物理块数量)
lvcreate -n 逻辑卷名(自定义) 使用的卷组名 -l 60(物理块数量)如下我从卷组(上面创建了名为pool的卷组)中分配1.5G的空间来创建名为lvname,大小为1.5G的逻辑卷。(名字和大小的顺序不要求,即-n也可在后面指定逻辑卷名)
注意:如果没有用-n选项指定逻辑卷名,则会自动生成一个名字
查看逻辑卷信息,如下lvs和lvdisplay、lvscan命令
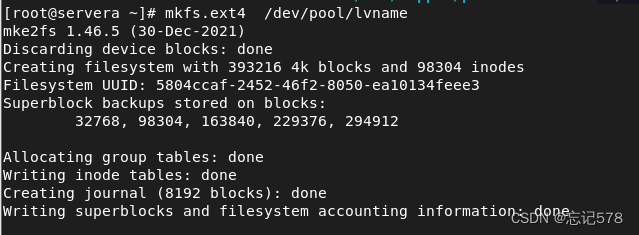
5、创建文件系统(格式化):在逻辑卷上创建文件系统,如ext4等。
创建完逻辑卷后,我们就可以将逻辑卷当磁盘一样去格式化,然后挂载来使用。
这个逻辑卷的路径有两个且都是软链接(指向的源文件是一样的),
/dev/卷组名/逻辑卷名和/dev/mapper/卷组名-逻辑卷名,如下
使用软链接路径是为了提供一个更加稳定和统一的接口。由于LVM允许动态地添加、删除和修改逻辑卷,直接使用源文件路径(如果存在的话)可能会导致混淆和错误。设备映射机制通过
/dev/mapper/目录提供了一个抽象层,使得无论底层逻辑卷如何变化,用户空间程序都可以通过一致的路径来访问这些逻辑卷。知道路径后将其格式化,和之前对分区进行格式化一样。(如下使用的是/dev/卷组名/逻辑卷名的路径,实际用哪个都可以)
6、挂载:使用
mount命令将逻辑卷挂载到文件系统的某个目录上,使其可以被系统访问和使用。挂载操作和之前对分区进行挂载的操作相同
如果想永久挂载,也是需要编辑配置文件,如下图
到那时上面挂载成功后可以发现,当我们去查看挂载信息时,显示的是另一个路径/dev/mapper/pool-lvname的挂载而不是我们使用的那个路径/dev/pool/lvname,因为在LVM中,逻辑卷是通过设备映射(Device Mapper)来实现的,因此它们的实际路径是
/dev/mapper/pool-lvname。扩展逻辑卷
注意:ext4和xfs是常见的支持逻辑卷扩容的文件系统格式,但其他文件系统也可能支持类似的操作
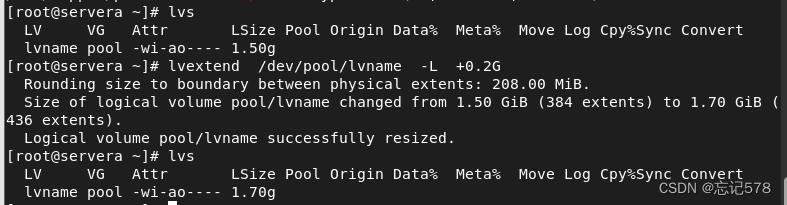
如果逻辑卷空间不足,则用lvextend命令对逻辑卷进行扩容,和创建逻辑卷的命令相同,也可以用空间大小或是物理块数量两种方式对命令进行书写。
lvextend 逻辑卷名 -L 空间大小 或者是lvextend 逻辑卷名 -l 物理块数量
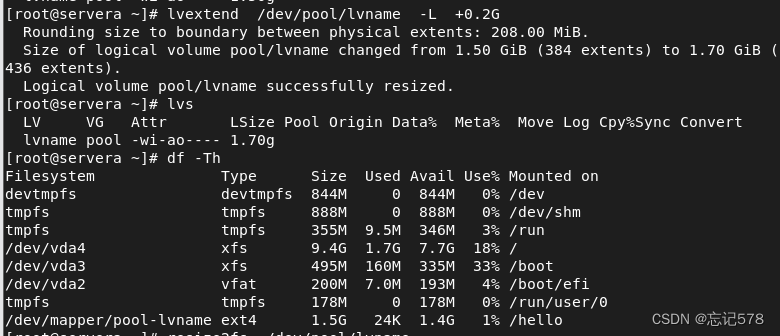
但是使用extend命令扩容了对应空间后,并不能马上让逻辑卷大小增加才对,因为为新扩容的空间没有进行格式化,应该要拉伸文件系统(即形象的让原来的空间拉伸一样扩容,文件系统相同),但是如上图用lvs去查看,居然直接就扩容成功,容量增加,但是如下用df -Th
(-T可以看到文件系统类型,-h表示以人类可读的方式程显)查看则可以看出并未真正成功
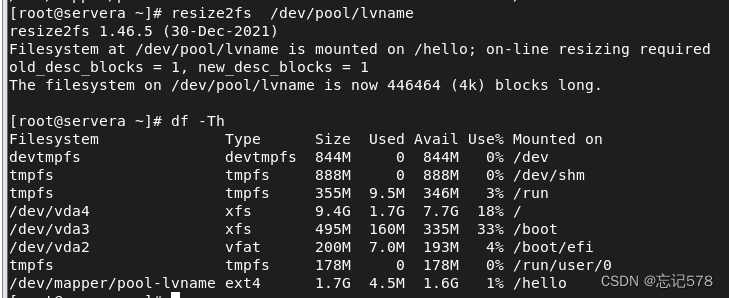
根据卷的逻辑文件系统类型选择对应的命令去拉伸文件系统,让新扩容的空间和使用的空间一致,比如ext4类型则用命令resize2fs,将新扩容的空间也变成ext4的类型。即如上执行完lvextend后再执行命令resize2fs 逻辑卷名即可
如果是xfs格式则用命令xfs-growfs 逻辑卷名
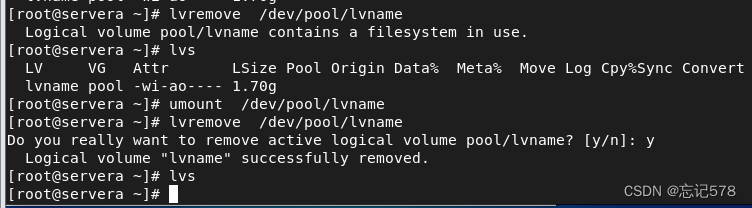
用lvremove卸载逻辑卷时,记得要用逻辑卷的绝对路径,当然两种路径写法都是可以的。记得如下图如果逻辑卷已经挂载,则要去删除要先卸载
还有就是当我们新建逻辑卷时出现如下警告,询问是否要清除签名,只有输入y才可以继续创建。如果不清除签名并尝试继续创建新的逻辑卷,系统通常会拒绝执行这个操作,并给出错误信息。这是为了防止不小心破坏现有的文件系统并导致数据丢失。
出现“ext4 signature detected”这个提示很可能是因为之前删除逻辑卷时没有删除干净,而且明明我们设置的是1.5M的大小,但是实际查看却是4.00m,因为物理卷(PV)的物理扩展大小默认配置为4.00MiB,因为逻辑卷是在卷组的基础上创建的,它们会继承卷组设定的PE大小,如果我们没有在创建卷组时没有指定物理块大小,则默认是4M,因为物理块PE决定逻辑卷(Logical Volume)上的最小可分配空间大小,那么任何小于4.00MiB的逻辑卷大小请求都会被向上取整到4.00MiB。如果是以M为单位(不写单位也默认是M),但不是2的整数次幂,也会向上取整为2的整数次幂。
高级存储功能
VDO(Virtual Data Optimize)是一种存储优化技术,全称是虚拟数据优化。VDO通过在块设备之上创建一个逻辑层,对写入的数据进行压缩和去重处理。使用VDO压缩存储和删除重复数据,VDO包括两个内核模块:kvdo模块用于以透明的方式控制数据压缩,uds则可用于重复数据删除。
用VDO创建的逻辑设备叫VDO卷,与磁盘分区类似,可以将VDO卷格式化为所需的文件系统类型,并像常规文件系统那样进行挂载。而且也可以将VDO卷用作LVM逻辑卷。
注意:VDO卷的逻辑大小(可指定)可以大于实际块设备的物理大小,如果在创建卷时未指定逻辑大小,则VDO会将实际物理大小视为卷的逻辑大小。(设置逻辑大小是为了提高存储功能的使用效率)
如下实现和使用VDO:
1、安装VDO软件包:使用
yum install vdo kmod-kvdo命令来安装这些软件包。
(上图显示默认之前安装好了,安装好VDO软件包后,就可以开始使用VDO来优化存储配置了。无需手动启动任何服务,VDO会在需要时自动处理数据的压缩和去重。)
2、创建VDO卷:使用
vdo create命令来创建一个VDO卷。需要指定VDO卷的名称(使用选项--name)、使用的块设备(--device)以及VDO卷的逻辑大小(--vdoLogicalSize)。(逻辑卷大小是可选的,如果不指定即是1:1的实际物理大小,而最大可以设置的比例是1:10),再选择磁盘创建称VDO卷时,一般使用完整的磁盘(未分区)
上图创建一个名为
vdo1的VDO卷,使用/dev/vdd作为块设备,并指定逻辑大小为50G。
上图查看vdo1的一些状态信息
3、格式化VDO卷并挂载文件系统:一旦VDO卷创建成功,你可以使用
mkfs命令在VDO卷上创建一个文件系统,例如XFS或ext4。然后,使用mount命令将文件系统挂载到适当的挂载点。
如上把VDO卷格式化为xfs文件系统。该绝对路径在成功创建VDO卷后会给出。
上图将VDO卷挂载到目录/mnt/dvo1
4、配置自动挂载:如果希望在系统启动时自动挂载VDO卷,可以在
/etc/fstab文件中添加相应的条目。
挂载选项 x-systemd.requires=vdo.service 意思为可延迟挂在文件系统,直到vdo.service启动为止。这些选项必须要添加,因为只要先启动vdo服务成功后,才能使用vdo卷去挂载,但机器关机后服务也已经关闭,且机器开机时是先去挂载相对应的磁盘,然后才会启动服务,所以对于vdo卷来说,要加上这些挂载选项延迟vdo挂载,先读取fstab的挂载其它磁盘,然后再启动开机所需服务,开启vdo.service服务,挂载vdo卷。(不然则开不了机)
5、使用和管理VDO卷:一旦VDO卷挂载成功,就可以像使用普通文件系统一样使用它。VDO将自动对写入的数据进行压缩和去重处理。你可以使用
vdostats命令来查看VDO卷的状态和性能统计信息。注意:在红帽9(RHEL 9)版本中,VDO(Virtual Data Optimize)卷功能已被移除,所以上面说的关于VDO的操作是在8版本中的实践。
可以参考Redhat8.0 Stratis和Vdo高级存储以及初级实战演练-CSDN博客













访问网络附加存储
NFS(Network File System)是一种网络文件系统协议,它允许客户端通过网络访问服务器上的文件和目录。当使用NFS共享文件系统时,客户端实际上是通过网络来访问服务器上的文件和目录,而不是直接访问块设备。其允许远程主机通过网络挂载文件系统,并像它们是本地挂载的文件系统一样与它们进行交互。这使系统管理员能够将资源整合到网络上的集中式服务器上。
(补充:NFS是典型的C/S结构(客户端和服务器端)。即将服务器内容共享给客户。nfs服务的网络共享是linux与linux之间共享传输的。(linux与windows之间实现共享是sanba)
如下利用nfs实现网络附加共享:
首先要开启nfs服务(没有安装则先安装nfs软件包(通常需要先安装NFS客户端和服务器软件包),并开启服务)
可以先查看有没有下载
(上图是系统默认安装好的,也就是如下两个安装后的效果)使用 yum install rpcbind nfs-utils 安装
我也实验了直接用yum install nfs* 去安装的效果,如下
感觉差别不大,说明主要就是上面说的那两个安装包
安装好后开启rpcbind、nfs-server这两个服务
如上开启并设置nfs-server服务为开机自启动(因为rpcbind服务默认是开机自启动的,可以查看一下是否开启,并启动)
实现共享,如下我创建共享的文件夹,
编辑nfs的配置文件/etc/exports(默认是一个空文件,只需要按照格式将要共享的文件路径、文件对象、文件权限写入即可),
共享目录是指定要共享给其它主机的目录,需要绝对路径。主机则可以是
权限用( )括住,多个权限在括号内用逗号隔开,括号里填的权限参数有
如下我编辑内容为将/root/share 目录下的内容共享给serverb(172.25.250.11),权限为可读可写并同步内容
编辑完后我们要编辑防火墙,放行我们的服务才可以被访问,一种方法是关闭防火墙,不采取,第二种方法就是用命令放行如下三种服务,
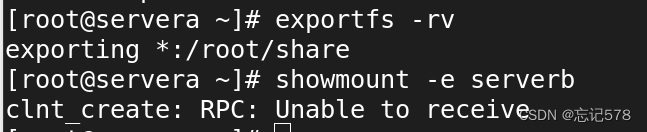
然后重新启动防火墙,重启nfs-server,rpcbind这两个服务
并用exportfs -rv使配置文件生效,下面用showmount -e 命令来查看对serverb的共享的文件,没有查看到,原来是要在客户端上查看
(补充:网上说
exportfs -rv和exportfs -ra都是用来使/etc/exports文件中的更改生效的命令,但前者会显示详细的输出信息,而后者不会。如果不执行这些命令,对/etc/exports文件所做的更改将不会生效,NFS客户端也就无法访问新配置的共享目录。但是这个命令在服务端和客户端的配置都正确,并且客户端在需要时能够访问到这些配置时可以省略,如果修改了/etc/exports文件并希望这些更改立即生效,那么需要运行exportfs -rv命令。)如下查看,要搞清是谁共享谁访问,在访问的主机上用showmount -e 共享的主机名查看
接下来就是将servera主机上共享的/root/share目录挂载到自己的目录下(需要是空目录,因为发现挂载在由文件内容的目录下则挂载成功后会覆盖原有文件,但在卸载后,原来的文件会恢复就是),在这个例子中访问的主机就是自己,即serverb
挂载完成后,就可以访问被共享的文件,但是如下发现当我们
于是我们知道其实共享的文件也要设置访问权限才可以,即使是在配置文件设置了可读可写,但是也要满足实际的共享目录也是允许被可读可写的,这是要用chmod o+rw 文件路径才可。添加权限后再执行,修改内容且同步成功,如下
注意:在共享的主机上把共享的目录删除后,再去访问就出现如下报错
这是即使再共享的主机上重新创建一样的共享的目录,再去访问还是这样报错,但是即使共享主机把共性目录删除,还是可以用mount命令查看到挂载信息。尝试后发现可以在访问的主机上用umount /haha(挂载点)的方法去卸载,在重新挂载就可以解决这个问题。
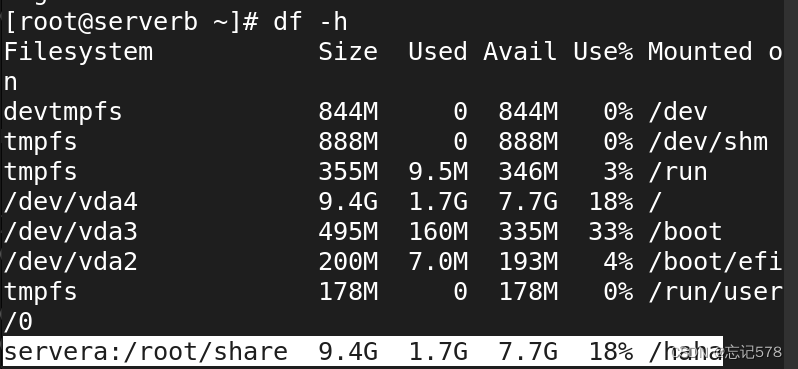
用df -h命令查看到如下挂载情况
(补充:可以使用
df命令来查看已挂载的文件系统的磁盘空间使用情况,包括NFS共享后挂载的信息。而lsblk命令主要用于列出块设备的信息,可能无法直接查看到NFS共享后挂载的信息。)但是上面这种用命令行在访问主机上挂载的方式是临时挂载,如果要永久挂载是不是要和之前磁盘分区挂载一样编辑/etc/fstab文件呢,如果编辑则是按照格式如下编写
但是这样不行,因为机器开启时会先去挂载对应的磁盘,当我们如上编写后,开机遇到servera主机没有开启或断电等情况时,则找不到这个共享目录,则开机会卡住。
可以用自动挂载解决这个问题
注意:自动挂载是在访问的主机上进行操作,但是要实现自动挂载,载服务器上还是和上面一样要安装好软件包开启nfs服务,编辑/etc/exports文件等操作。下面则是在访问的客户机上做的挂载操作。
一般建议,在开始配置前可以使用mount挂载映射(即上面说的临时挂载先实验一下)来测试NFS服务器和共享。(提示:mount -t nfs servera:/share /hh)
下面是自动挂载
如下实现自动挂载网络附加存储
按照上图所说操作
实现自动挂载,首先要安装autofs软件包(注意在访问的主机上安装,如下是serverb访问servera,所以serverb需要下载autofs软件包,实现自动挂载)
autofs自动挂载需要编辑两个配置文件
(例如我们要将servera主机上/root/share挂载到 当前主机serverb上的/haha目录下)
直接挂载点文件/etc/auto.master,编辑该文件内容如下
格式为挂载点的一级目录 间接挂载点文件的路径
间接挂载点文件/etc/auto.misc,编辑该文件内容如下
注意:
a、因为我的挂载点为/haha,他没有二级目录,所以在直接挂载文件里用/-表示,如果挂载点为/qq/ww,则在直接挂载点文件上编辑为/qq,在间接上为ww。
注意:如果父目录中是
/-模版中才可以有/开头的详细目录。b、间接挂载点文件可以自定义文件,但是建议使用默认的,因为会有格式参照,但是也可以复制一份文件来编辑。
c、在间接挂载点文件后面的权限中,可以直接写-rw,sync,省略-fstype=nfs,因为autofs默认支持nfs使用。
注意上面编辑完配置文件后,需要重启autofs服务!
如果挂载点是多级的目录,则没有进入最里面的挂载目录则不会自动挂载,只要真正访问时才会挂载!!!!所以当查看到前面的目录没有内容时,一定要载进入最后的目录!
下面是我将servera:/root/share挂载到/haha/we,且自定义了间接挂载点文件为/etc/auto.nfs的示例,可以发现挂载完成后去查看,得到的挂载信息是是/etc/auto.nfs on /haha,当时一直以为自己挂载错了。
如下图确实当我们进入第一级目录haha时ls查看不到任何文件,只有当进入要访问的文件时,才会自动挂载显现出来
在退出挂载目录没有进行操作后的300秒(即5min)后会自动卸载,下次进入再自动挂载
该默认时长可以通过编辑配置文件/etc/autofs.conf进行修改,记得修改后再重新启动服务才会生效。
watch -n 1 ls 实时监控ls动态,并且每秒进行监控。
关于设置挂载点的配置文件:
/etc/auto.master和/etc/auto.master.d/和/etc/auto.misc在
autofs的配置中,/etc/auto.master和/etc/auto.master.d/目录下的文件都用于定义挂载映射的规则,但它们的作用和用途有所不同。/etc/auto.master是autofs的主配置文件,用于定义挂载点的目录和映射文件位置;/etc/auto.master.d/是一个目录,用于存放额外的映射文件,以组织和管理不同的挂载点,可以在这个目录下创建新的配置文件,每个文件都遵循/etc/auto.master的格式,定义了一组挂载点及其映射文件。然后,在/etc/auto.master文件中,通过一行引用这个目录(如+auto.master.d)来包含这些额外的配置文件。而
/etc/auto.misc是一个传统的映射文件,用于定义一些通用的挂载规则。可以根据自己的需要选择直接编辑这些文件或在/etc/auto.master.d/目录下创建自定义的配置文件。关于利用autofs实现自动挂载的补充:
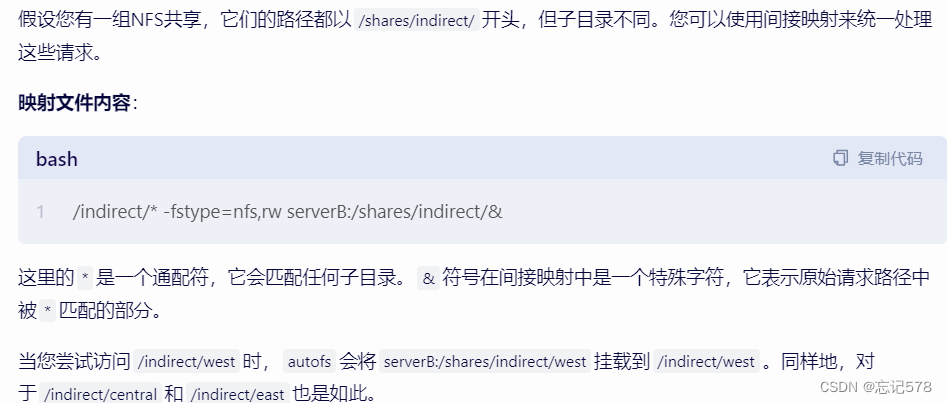
autofs服务中用于定义文件系统自动挂载方式分为直接映射和间接通配符映射,而描述文件系统如何被挂载到系统上分为直接挂载和间接挂载。间接通配符映射:
使用通配符来匹配多个路径,并将它们映射到同一个或不同的文件系统。这种方式更加灵活,因为它可以根据路径的一部分来决定挂载哪个文件系统。
(记得如果映射的挂载点没有事先创建,
autofs服务在需要时会自动创建它们。这是autofs的一个主要特点,允许动态地挂载和卸载文件系统,而无需手动创建和管理挂载点。)关于报错补充:
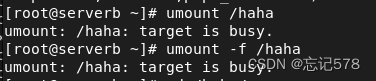
在尝试卸载文件系统或设备时,如果收到“目标正忙”(target is busy)的错误消息,这通常意味着仍有进程正在使用该文件系统或设备。为了成功卸载,需要首先确定哪些进程正在访问该目标,并终止这些进程。
lsof(list open files)是一个用于显示Linux系统上当前打开文件的实用程序。可以使用它来查找正在使用特定挂载点或设备的进程。
然后用kill命令杀死进程,如果有多个进程可以在
kill命令后面列出多个PID,用空格分隔。(要分情况使用,如果是要删除已经挂载的目录,提示目标在忙的话,则要先用umount卸载,然后再删除目录即可,不用杀死进程)





















控制启动过程
重置root密码
当我项设置一台虚拟机的密码,在开机时打算进入引导菜单界面去修改时,发现只有如下图一值在加载,后面直接就进入了界面没有看到菜单引导。后面发现是默认的开机动态倒计时的时间设置为0了。所以我们要修改引导时间。我是参照这个博客操作的,Linux 修改 GRUB 引导菜单等待时间_grub.cfg 设置 停顿时间-CSDN博客
vim /etc/default/grub 编辑如下的GRUB_TIMEOUT参数,这里因为默认为0,所以我们要延长器菜单停留时间,
上图是没有修改的数据,我的修改为GRUB_TIMEOUT=10,保存退出后进行如下操作。
如下图所示,我们可以看到这个引导菜单的界面,之前因为GRUB_TIMEOUT=0,停留时间过短,所以没有看到。
现在我们执行到如下图所示的第一步,第二接着我们要按任意键中断倒计时(即我们设置的时间,上面设置中我的修改为延长到10s),注意第二步要执行成功的前提是要点击界面,进入虚拟机,即鼠标看不到时,按任意键才有效)
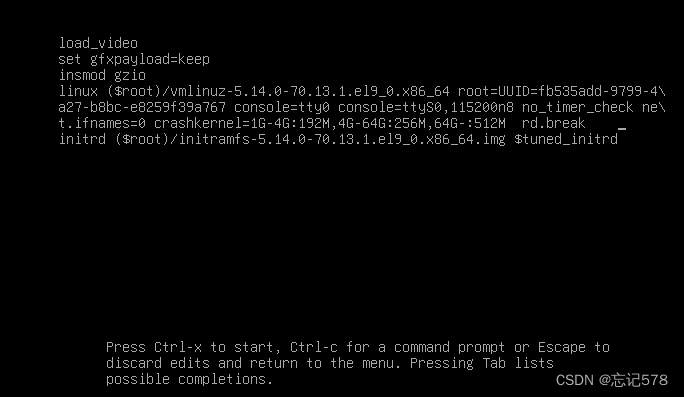
根据上图操作提示,按e进行编辑,进入到如下图所示界面,第5步,如下linux开头为下图的第4行,ctrl+e可以直接到这行的末尾,如下图所示,添加rd.break(至于后面有个白色的_,那是我的光标所在,不要误解了),
(还有一种是修改是多了一步修改出现的ro为rw,然后和上面一样在linux开头的行尾添加rd.break ,这样操作可以省略后面以命令方式设置以可读方式重新挂载)
(注意,按esc键即可返回上一步的菜单界面)
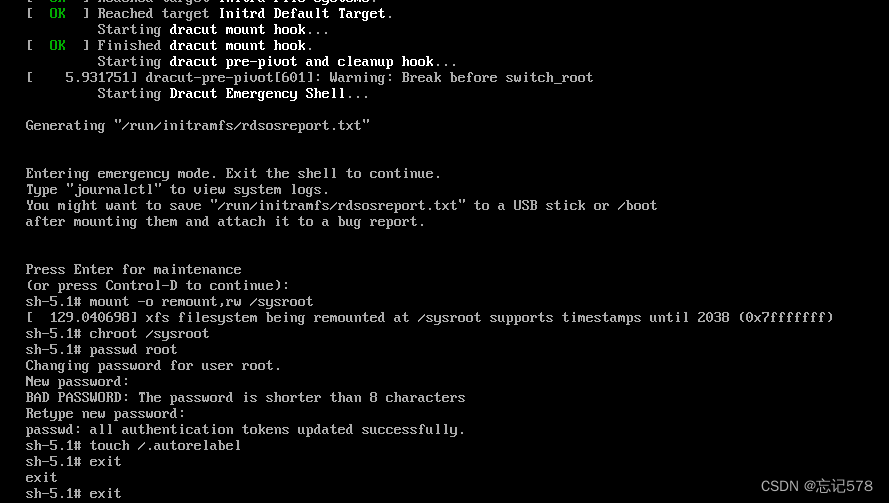
编辑好后根据上图提示,按ctrl+x进行启动。启动好后发现进入如下界面,有个提示说ctrl+d继续,不用管他,直接enter,进行下面的操作
如上图实际操作,对应下图步骤
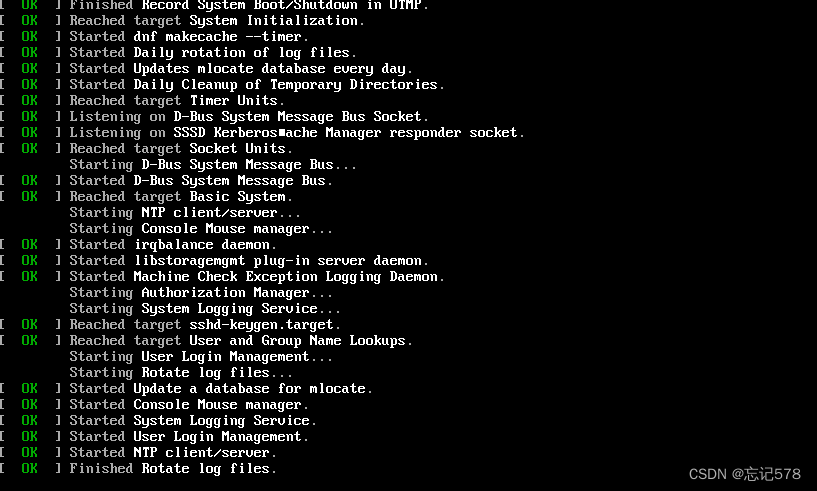
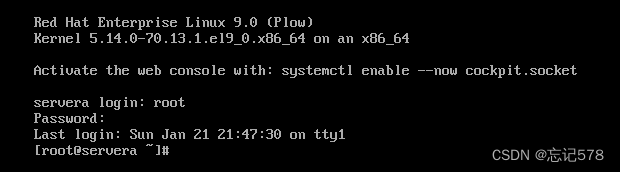
执行完后,我们需要等待一会才会有反应。如下进入登录界面,输入我们刚重新设置的密码即可成功登录,说明我们修改成功.。





运行容器
虚拟化是将存储设备、cpu、网络等设备池化,为提升资源利用率。
而容器技术是虚拟化技术的一种形式,它将应用程序及其依赖项打包到一个独立的容器中,并在操作系统级别进行隔离。与传统虚拟机相比,容器具有更快的启动时间、更小的资源消耗。
补充:容器和虚拟机对比
虚拟机通常需要模拟整个硬件环境,并运行一个完整的操作系统。因此,虚拟机通常受限于宿主机操作系统对虚拟化技术的支持。(以Windows主机为例,要在Windows上运行虚拟机,通常需要安装虚拟化软件,如VMware Workstation、VirtualBox或Hyper-V(Windows 10和专业版以上内置的虚拟化技术)。这些虚拟化软件允许在Windows主机上创建和管理虚拟机,并在其中安装和运行其其他操作系统,如Linux、Windows Server等。)
而容器则比较轻量,不完全依赖于特定的宿主机操作系统,不需要虚拟化软件的支持,可以直接跑在linux或windows系统中,而且容器不需要单独安装自己的操作系统,(容器镜像通常包含应用程序及其所有依赖项,以及一个轻量级的操作系统层。)只要有支持容器运行的文件(工具等如Docker或Podman),容器就可以在该操作系统上运行(共享主机的操作系统,可以自适应,所以也不用单独安装一个操作系统,比较轻量),而无需对容器本身进行任何修改。这使得容器具有出色的跨平台兼容性。
关于镜像、容器、仓库和注册表
镜像是只读的模板,它包含了运行特定应用所需的所有文件和配置。可以把镜像理解为一个应用的快照,它包括代码、运行时环境、依赖项等。镜像不包含动态数据,其内容在构建之后不会被改变。
容器是由镜像创建的运行实例,可以把它看作是正在运行的应用。容器包括一个完整的运行环境,例如操作系统、应用程序和依赖项。容器之间相互隔离,保证每个容器的安全性和稳定性(一个镜像可以创建多个容器。镜像是创建容器的基础,而容器则是从这个模板中实例化出来的、正在运行的应用程序。)
仓库是用来存放和分发镜像的地方,每个仓库可以包含多个镜像。可以把仓库理解为一个存储镜像的目录或集合。仓库可以包含多个镜像,每个镜像对应一个特定的应用或服务。
注册表是包含多个仓库的服务器(提供下载容器的那些镜像网站,如docker.io),每个仓库都存放在注册表中。可以把注册表理解为一个存储和管理多个仓库的平台。注册表可以是公共的(比如 Docker Hub),也可以是私有的(比如企业自建的容器注册表)。
综上:运行容器前我们要下载镜像,既要先知道从存储容器镜像的仓库的容器注册表去找到对应仓库下载需要的镜像。
Docker和Podman都是容器化技术的实现工具,它们允许开发者将应用程序及其依赖项打包到一个容器中,并在不同的环境中进行一致的部署和运行。(docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖项到一个可移植的镜像中,然后部署到Linux或者Windows系统,也可以实现虚拟化。)
Podman是Red Hat开发的一个无守护进程的容器引擎,它与Docker兼容,但不需要运行一个持久的守护进程来管理容器。Podman的目标是实现与Docker相同的功能,但提供更好的安全性和性能。接下来我们会使用podman来运行和管理容器(podman是docker的升级,命令都差不多)
1、首先我们需要下载软件包,安装podman工具,如下
yum会下载并安装container-tools模块及其依赖项。安装完成后,就可以使用podman和其他包含在container-tools模块中的工具来管理容器了。
在我们的教学环境中的注册表是一台虚拟机classroom的域名(registry.lab.example.com),需要注意的是在我们教学环境默认的配置文件里没有添加安全可靠的信任域,所以需要我们手动把信任添加到配置文件中,如下系统提供了完整的配置文件registries.conf,我们去下载即可(可用Firefox输入materials.example.com搜索即可得到如下界面)
如果是想让所有用户都可以直接访问registry网站,那么我们用wget命令将配置文件下载到/etc/containers目录下,则之后所有用户都可登录该镜像仓库的地址。当然如果是想当前登录的用户生效,则把该文件下载到当前用户的家目录下的.config目录下(.config这个隐藏目录需要自己创建),这样的话只有该用户能使用
如上下载到目录下(如果该目录下本来就有同名文件,记得可以重命名,而不是直接覆盖,说不定还有用呢。还有就是只有下载了软件包后才会有containers这个目录)
(红帽建议使用普通用户来管理容器,因此在$HOME/.config/containers目录中为容器注册表创建register.conf文件,以覆盖/etc/containers/registries.conf文件中的设置)
2、登录注册表
网站登录和命令行登录是两个独立的过程,服务于不同的目的。
命令行登录:允许从命令行界面与注册表进行交互,执行如拉取和推送镜像等操作。
网站登录:允许通过Web界面查看和管理您的注册表资源,例如查看镜像、管理用户权限等。
在命令行中登录注册表
如下时在图形化界面登录注册表
密码是redhat321
进去后点击用户可以进去看到
点击左边的标签一样的图案(即竖着的第二个图形),我们可以看到版本情况,选择自己需要的版本
容器命名的约定
容器镜像基于以下完全限定镜像名称语法命名
registry_name/user_name/image_name:tag
registry_name:是存储镜像的注册表名称,通常是注册表的完全限定域名(要完整)
user_name:表示镜像所属的用户或组织
image_name:在用户命名空间中必须唯一(是上传用户上传的名字)
tag:表示镜像版本(如果不设定则默认是latest,即最新版,则会下载最新版)
注意:下载时不能省略完整的注册表地址,尽管已经登录到该网站。
3、下载镜像到本地。
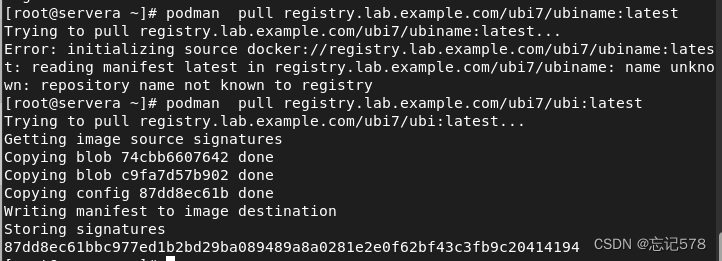
如下用podman pull 从注册表中提取镜像
可用podman images 查看本地镜像
podman ps命令列出系统上正在运行的容器。加上-a选项则是查看计算机中所有容器(创建、已停止、已暂停或正在运行)
4、运行容器
如下通过镜像部署容器
使用podmna create命令来创建容器但不运行(创建好后可用podman start 来启动),可使用--name设置容器名称
(如上后面的数字是镜像的id,每次下载好镜像后自动生成的唯一的编号,在创建容器时需要使用,且只要输入到可唯一识别就好,比如只有一个镜像的话,直接输入该镜像的一两个数字即可,当然也可以输入镜像的全名即registry_name/user_name/image_name:tag),如上容器创建时自己取的容器名为haha,要符合具有唯一性,且当容器创建好后也会生成一个容器id,也是唯一的。)
上面时使用create创建容器,一般不推荐,推荐使用podmman run命令将首先从镜像仓库中提取镜像,然后运行容器,一步到位(pull镜像,create容器,start容器)。
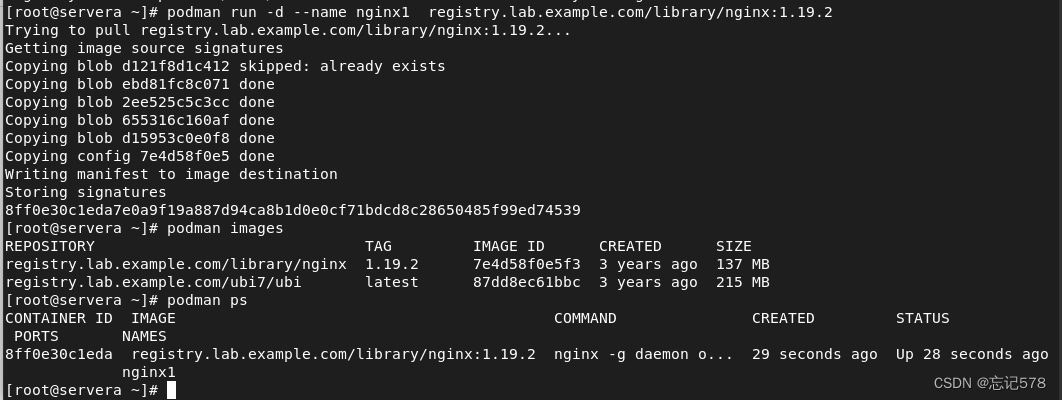
podman run -d image_name (把容器放在后台运行,这样创建完成后不是容器的界面)
(如上图实现了先拉去镜像,创建容器并放到后台运行)
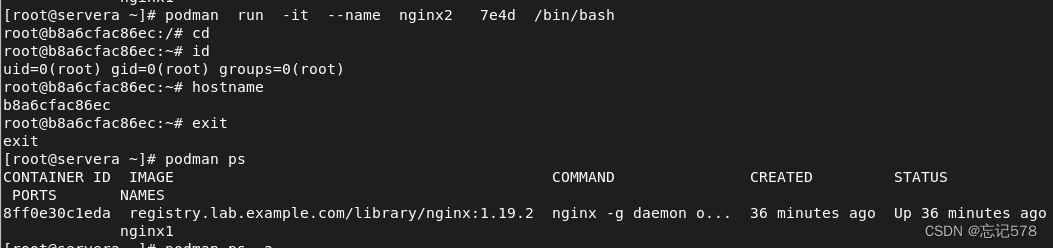
podman run -it image_name /bin/bash (将以交互即以伪终端的方式运行容器,-i表示接受标准输入,-t表示tty终端,登录的形式的/bin/bash),这样就可以以命令的方式取运行我们的容器
如上仍然是使用之前拉取的镜像创建镜像,并以交互方式运行容器,看到命令提示符是root@b8a6c....,因为我们是在root用户上创建并运行的容器,所以容器上也是root用户,且后面的数字是容器的id。但是如上可以发现当我们退出容器的界面后容器就不在运行,用podman ps去查看没有发现nginx2。
如下在没有关闭容器界面的同时,再创建一个窗口去查看容器运行情况,可以看到新创建的ngnix3在没有退出容器界面时,可以查看到正在运行。
但如下可以发现,即使是退出容器后再开启没有进入终端界面,系统不会再重新给它分配一个终端,只是放到后台去执行。
之前是分配了一个tty伪终端,所以可以直接在里面运行命令,现在如果想执行命令或者说在容器里去直接做一些配置,而不进入容器的伪终端,在容器中执行命令可以用podman exec
如下:podman exec 容器id或容器名 要执行的命令
如果还想进入环境里,则用podman exec -it 容器id或容器名 /bin/bash
如果从环境退出来后则不会像之前那样直接停止容器,而是依然处于up状态,运行在后台。如下退出后,仍然在运行着。
如果想要关闭则可以手动关闭(podman stop 容器名或容器id)
删除容器,如果是运行着的容器则要先关闭容器再删除,如下一开始删除不了,关闭后则可
(如果是删除了容器,则用podman ps -a 去查看也不会有相关运行记录)
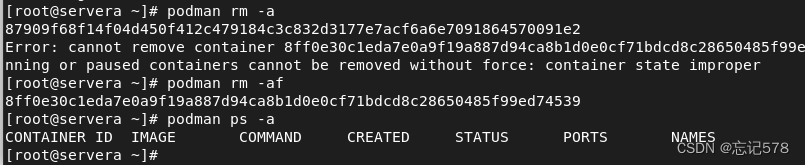
一般来说正常运行的容器不可以直接删除,如果想直接删除则需要加上-f选项表示强制删除
如果想要将全部容器删除,不管是不是再运行着的容器,则可以用-a选项,并用-f表示强制删除。
运行rootless容器(rootless 容器是指在不使用 root 用户的情况下运行的容器),在容器主机上,可以用root用户或普通非特权用户身份运行容器,分特权用户运行的容器称为rootless容器,rootless容器更安全,但是会有一些限制(比如发布服务需要端口号,无根的容器没有办法发布1024以下的端口)。如果是使用docker来运行容器的话,即使是普通用户在运行容器则都是root用户在运行容器(相当于变相的提权),比较不安全。传统的容器通常需要 root 权限来执行某些操作,但 rootless 容器的目的是增强安全性,因为容器内的进程不会拥有真正的 root 权限。
补充:podman cp命令再主机和容器文件系统之间复制文件和文件夹。如下
删除镜像命令podman rmi
关于容器的环境变量参数,对于一些容器来说,当我们将镜像下载下来,创建并运行容器后并不能直接使用,开发者在创建容器时在配置里面添加了许多的环境变量参数,在容器启动时则需要这些环境变量参数。如果直接像之前一样podman run 命令创建成功后,会发现容器并没有在后台按预期一样去运行,却是处于exit的状态,这就是因为我们缺少了环境变量。如下则是示例,我们下载镜像,创建并让容器去后台运行,结构却发现在后台没有运行,且其状态时exit
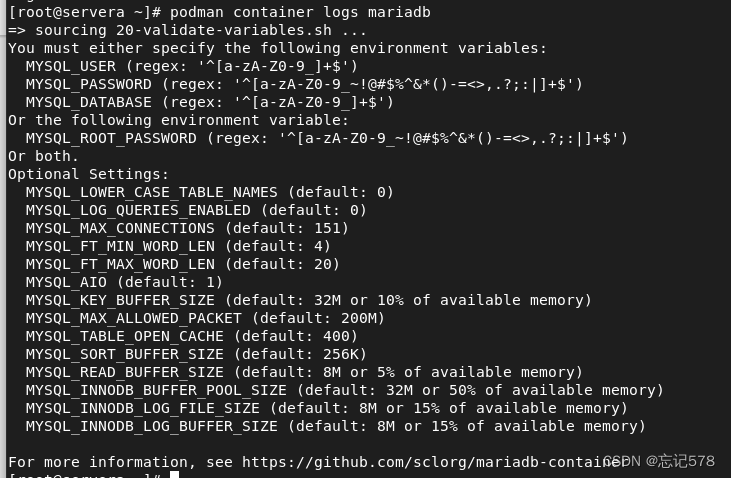
如下用podman container logs 容器名 去查看容器的状态日志,
如上日志提示是我们没有设置环境变量,如下我们用-e选项去添加环境变量(运行数据库容器一般要添加4个参数,如下需要前3个就可,管理员的密码(MYSQL_ROOT_PASSWORD)是可选的,下面我没有设置。
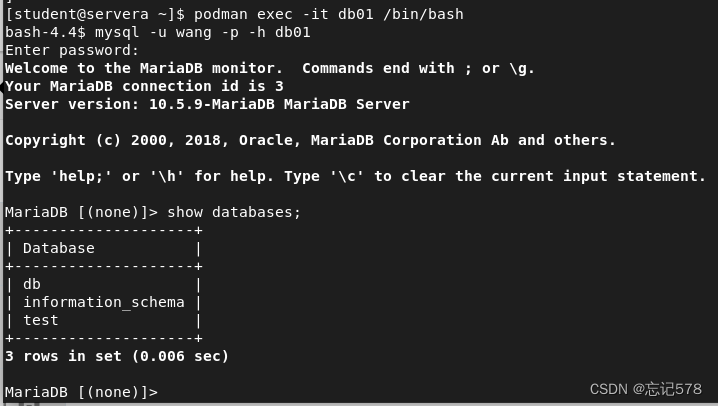
如上我们添加好了环境变量(上面则是创建了一个用户wang,密码为123,创建了一个数据库db),但是因为没有添加端口映射,所以在运行时还是会出现一点问题(主机想要访问则要进容器里,不能直接访问)
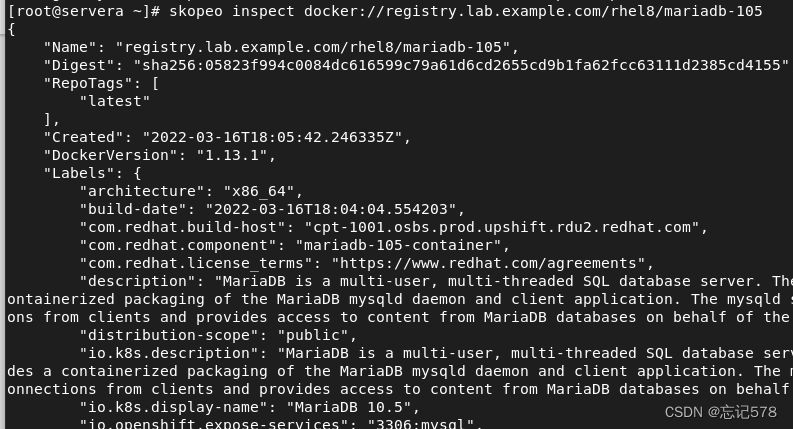
补充:skopeo inspect命令可以检索镜像运行容器时所需的信息写在usage的标签里了
如上已经说明需要使用-e选项去添加环境变量,且环境变量的名字也已经告诉。
管理容器资源
1、当配置一个容器运行某种服务时,如果想要给容器添加更多的资源,如持久存储,但是单个容器的小型部署不能满足我们的一些需求,这时需要借助本地的主机来存储容器的资源,实现永久存储文件,即将本地目录挂载到容器上
即使容器是临时的,产生的数据也是临时的,但是可以通过挂载的方式将其永久保存到主机,即使当容器删除或是重新创建,只要将本地目录挂载到容器中即可实现接手原来的容器继续存储新的文件,只要每次挂到同一个目录即可。
但是要注意权限的问题,如果挂载后没有写入功能则不能实现文件的储存。
关于权限:容器通常使用用户命名空间来隔离进程的用户身份。这意味着在容器内部运行的进程可能具有与宿主机上相同UID(用户ID)和GID(组ID)的不同用户身份。因此,对于相同的UID和GID,容器内部和宿主机上的权限解释可能会有所不同(就像本地和容器都有一个用户叫做mysql,但是即使将挂载目录的拥有人和拥有组都改成mysql,容器的mysql用户也不是同一个)
当我们将本地文件挂载到容器后要实现挂载目录能被容器内对应的用户实现读写,我们想要让系统用户都能对容器内被挂载到的目录都能够读写(如httpd服务对应apeache用户.mysqld服务对应用户mysql系统用户等),
在rootless容器中,普通用户具有容器内的root访问权限,因为podman在用户的namespace内启动,使用podman unshare命令在用户的namespace内运行命令,要获取用户namespace的UID映射,使用podman unshare cat命令(助于理解容器内的用户和宿主机上的用户之间的映射关系),将podman容器当中的用户映射到主机中,例如在容器中mysql用户的id是27,则我们可以在容器主机上分配一个没有被使用id作为容器用户的映射idxxx,这样就相当于是两个id都代表同一个用户,即容器上的用户mysql是主机上id为xxx的用户。这样久实现了主机将挂载的目录的所有人所有组中id为xxx的用户,则对应容器中被挂载的目录则可以被容器中的mysql用户读写。
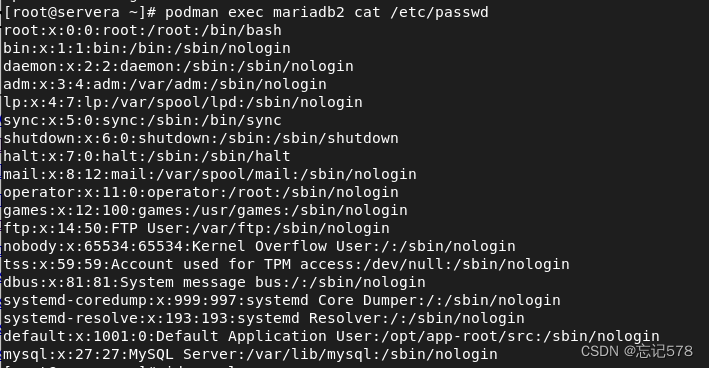
首先我们要判断一下我们运行容器的系统用户的id号是多少,如下查看到我们运行的数据库a、查看容器的系统用户id。如下服务的容器的系统用户mysql的id为27
b、做id映射。
接着用podman unshare命令做id映射(如下报错知道不能在root用户下进行,而且时chown不是chmod)
接下来我在student这个普通用户进行操作
如上图将主机的adirectory目录的所有人所有组的权限改成了id为100026的用户,其实容器上id为27的mysql用户在主机上映射的id。(27+99999=100000+27-1=100026),这个不需要自己计算成对应id是多少,直接用命令设置后自动会转换。
c、挂载
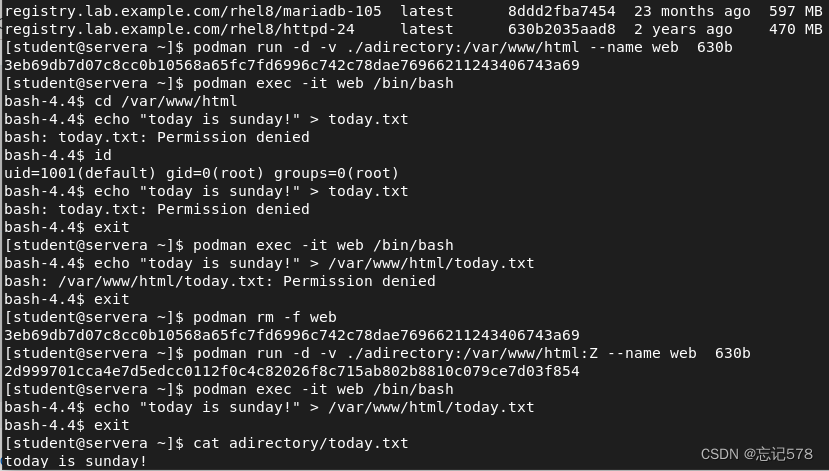
使用-v选项本地主机目录:容器目录(中间用:隔开),如下我和创建一个web容器,因为web容器的数据内容都放在/var/www/html下,所以我将本地的目录挂载到这个目录下。(如果说为什么不用上面的容器,因为上面我只是创建出来兰兰系统用户的id)
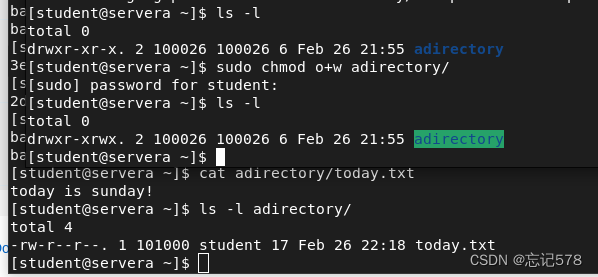
如上挂载好后,打算去新建文件输入内容,但是没有权限,如下可以发现一开始就是其它用户不可写,上面在容器中用id的命令查看发现当前使用的是id为1001的用户default,所以我们要修改其它用户的权限添加可读,如下修改后为rwx,然后再如上图去写入我呢见发现还是被拒绝,因为没有加安全上下文,所以如上图删除容器重新创建后,则可以成功写入,而如下图所示,写入后查看文件信息可以知道文件所有人的用户id为101000(即容器中用户id为1001的default用户,映射到主机的id为1001+99999=1001+100000-1=101000)
(注意:这个图我开了两个窗口,为作对比而截在一起,而且上面的示例是在创建容器时就进行挂载操作。一旦容器被创建并启动,其文件系统就被固定了,因此不能直接在运行中的容器上添加或修改挂载点。这是出于安全和隔离的考虑,确保容器在创建后的行为是可预测和一致的。所以好像是只能在创建容器时挂载🙃)
综上记得要考虑本地目录的权限是否时可以被容器上的目录可读可写的,即在容器上用id命令查看当前用户,如果本地目录拥有人和拥有组的用户(通过映射规律来判断,容器用户的id+99999=主机本地用户的id,则二者即为同一个用户),则要对其它用户的权限设置可读可写,还有记得添加安全上下文。
如果后面要删除这个容器,创建新的容器,则在创建时再次挂载到相同目录下就可以了。
注意需要设置适当的安全上下文。这包括确保挂载的文件或目录具有正确的访问权限、所有权和身份验证要求。
关于命名空间:
Linux 用户命名空间是 Linux 内核的一个功能,它允许用户创建自己的用户 ID(UID)和组 ID(GID)空间。使用 Podman 运行一个容器时,容器内的进程看到的是一个与宿主机系统隔离的用户空间。容器内的 root 用户实际上只是宿主机上的一个普通用户。这意味着一个进程可以在其自己的用户命名空间中拥有 root 权限,而实际上在宿主机系统中并不是真正的 root 用户。
2、默认podman容器无法解析彼此的主机名,因为默认网络上没有启用DNS的网络、,如果想实现网络互通,配置ip地址,让容器与容器之间通过网络去访问添加网卡,则可用podman network create命令创建一个支持DNS的网络。(podman v4.0支持两种容器网络后端,Netavark和CNI,自RHEL9起,系统默认使用Netavark(如下查看),之前安装的container-tools软件包的meta-package内含netavark和aardvark-dns软件包)
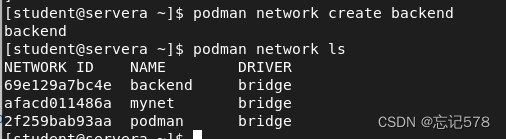
用podman network ls列出所有已创建的 Podman 网络。Podman 支持用户创建自定义网络,这些网络可以用来连接容器,以实现容器间的通信和隔离。当查看系统中已经创建了哪些网络,或者想要确认某个特定的网络是否存在时,可以使用这个命令。(默认情况下,Podman 提供了一个桥接网络)
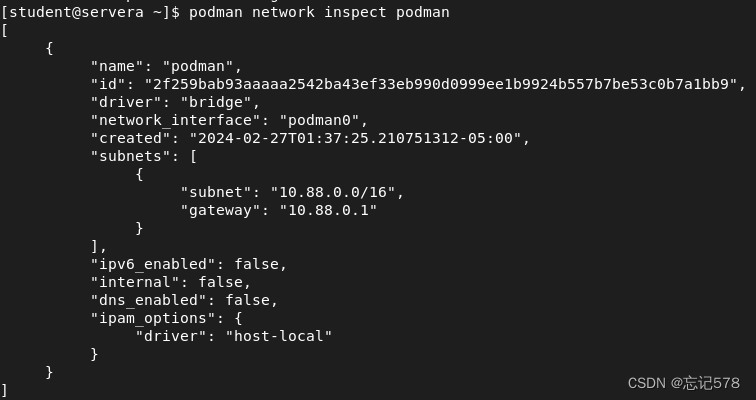
用podman network inspect podman这个命令用于查看指定网络的详细信息。获取网络的配置、连接的容器以及其他相关信息。确认某个容器是否已正确连接到某个网络,查看网络的 IP 地址范围、网关等信息。
a、创建网络
如下用podman network create命令创建一个支持DNS访问的网络连接,这样我们可以通过添加地址信息去直接访问对端ip。(从 Podman 4.0 开始,如果使用 podman network create 命令创建一个新的外部网络,则默认启用 DNS 插件。默认情况下,Podman 创建一个外部网络。可以使用 podman network create -- internal 命令创建内部网络。内部网络中的容器可以和主机上的其他容器通信,但无法连 接主机之外的网络,也无法从主机访问。)
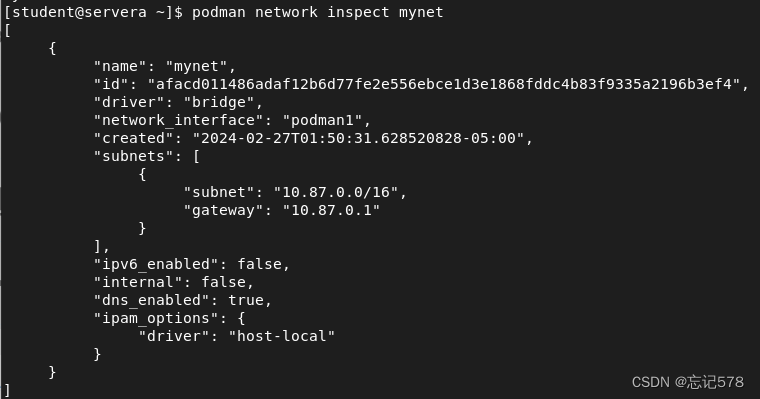
首先设置网络的话,要为其分配网段和网关,因为将网卡放到容器里会自动分配ip,所以我们只要把对应的网段和网关设置好(--gateway设置网关IP,--subnet设置子网),如上设置网关为10.87.0.1,子网为10.87.0.0/16的网段mynet
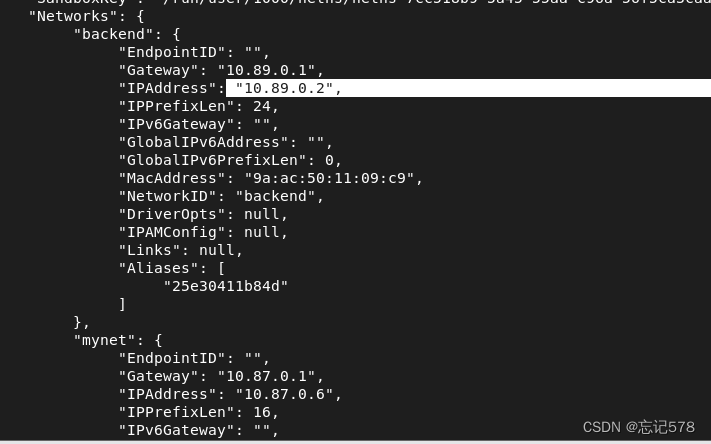
如下使用podman network inspect命令验证网关和子网的设置是否正确
b、将容器连接到网络
注意要在新建容器时将新建的网络添加到容器中,可以使用podman run --network 选项启用DNS的新建网络添加到新容器
如上两个新建的容器都添加了mynet网卡(二者实现网络互通),所以web1和web2都会有mynet会自动分配ip地址,
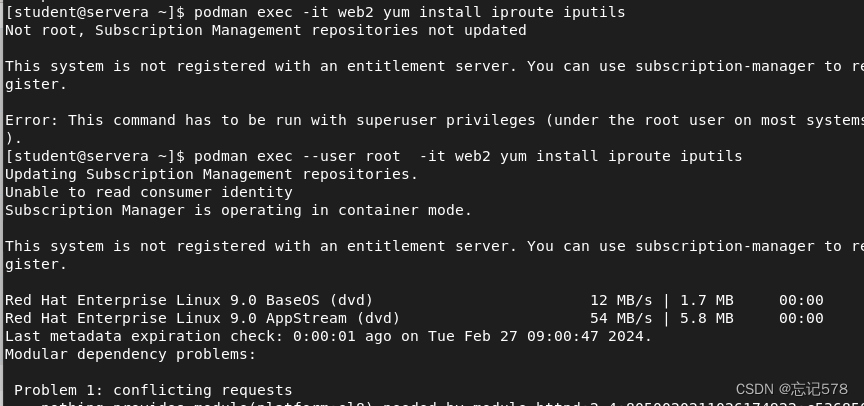
由于容器设计为仅预装最小的软件包,可能不具有测试网络的程序,如ping和ip命令,可使用podman exec 命令安装这些程序,同时也可能没有安装的yum源,我们可以将本地主机的yum源的所在目录挂载到容器中(如下),这样容器就有yum仓库,就可以安装了.如上,我们将本地的仓库/etc/yum.repos.d挂载到容器的相同目录下,注意,这里没有用安全上下文,因为我们不用实现储存。
当我们挂载好后就可以下载iproute和iputils,但是如下我们可以发现一开始被安装报错提示需要root用户,所以记得要加--user root,这样才是在容器中用root用户运行容器
(
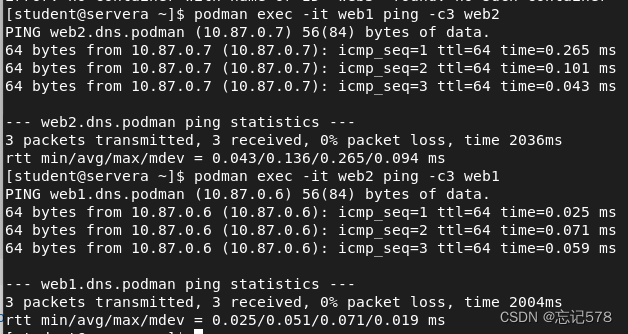
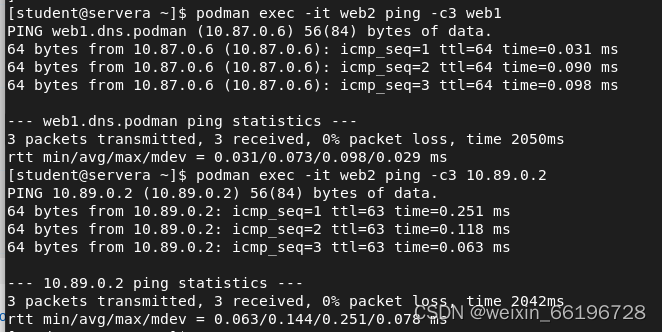
iproute和iputils是 Linux 系统上用于网络配置和诊断的工具集。iproute提供了ip命令,用于配置和查看路由表、网络接口等,而iputils提供了像ping这样的基本网络工具。)如下容器可以通过容器名称相互ping(说明两个容器都下载了相关工具,如果只有一个容器下载了iputils等,则其可以ping)
可以使用podman exec命令来测试DNS解析。名称解析到为mynet网络手动设置的子网内的ip,如上web2的ip为10.87.0.7,而web1的ip为10.87.0.6。
为多个网络连接到单个容器
容器运行时,可使用podman network connect 命令将其它网络连接到容器,多个网络可以同时连接到一个容器,以帮助分隔不同类型的流量,如下用podman network create创建backend网络,然后使用podman network ls 查看所有podman 网络
用podman network inspect 查看该网络的情况,我们在创建网络时没有给它分配网关,子网,如下会以自己默认的地址去分配,本来是需要自己手动分配的,以免不是自己想要的网络连接。
用podman network connect 将新建的backend网络连接到容器web1
如下可以用podman inspect web1查看到关于web1容器的详细信息,其中在Networks标签就有关于自己的网络地址分配情况,即上面将backend网卡添加后,自动分配了一个ip为10.89.0.2
我们可以发现即使容器之前可以相互ping通,到那时要知道在添加多个网卡,有多个ip后,DNS只会解析第一个网卡分配的ip,如下用容器名去ping时,可以发现 DNS解析的是第一个网卡分配的地址10.87.0.6,但是我们可以通过pingIP地址的方式检测网络连接状态,如下可以知道ping10.89.0.2时是互通的,
补充:
在Podman中,容器运行时可以连接到不同的网络。这些网络可以是默认网络,也可以是用户自定义的网络。使用podman run命令创建容器没有指定特定的网络时,容器将自动连接到默认网络。这个默认网络在Podman中通常使用
slirp4netns网络模式。slirp4netns是一个用户空间网络堆栈,它为容器提供了一个私有的网络命名空间,并且能够与宿主机进行网络通信。这种模式下,容器会通过一个虚拟的网络接口与宿主机进行通信。podman network create命令创建的网络则使用网桥网络模式。这些网络可以使用不同的网络驱动,比如桥接模式(bridge)。在桥接模式下,容器会被分配一个独立的IP地址,并且可以通过这个IP地址与同一网络中的其他容器或宿主机进行通信。
3、当再容器部署某种服务,如数据库服务器后,用户时不能直接访问到容器的(我们再主机里运行一个容器,用户能访问我们的主机,但是不能够直接访问容器),那我们去给容器配置端口映射,使得用户和容器可以建立连接,就可以访问到容器,和用户id映射一样,将本地没有被使用的端口分配给容器,对容器的端口进行一个映射,这样当我们访问主机那个映射的端口时则访问的是容器的服务
注意:当我们作端口映射式要让防火墙放行我们映射的那个端口,还有rootless容器无法映射主机上面的特权端口(即1024以下的端口不能做映射)
通常在创建容器时设置端口映射。这是因为端口映射是容器网络配置的一部分,而容器的网络配置在容器创建时确定。一旦容器启动并运行,其网络配置(包括端口映射)通常是不能直接修改的。所以如下我们在创建容器时用-p选项做端口映射,-p 主机端口:容器端口
(如上我挂载了容器主机的yum仓库,因为后面再容器内登录数据库需要数据库的管理工具需要下载,如下进行下载)
映射端口注意要放行防火墙,如下注意在普通用户下放行,需要加sudo,如下放行容器3306端口映射到主机的13306端口
podman port -a命令列出容器主机上定义的所有端口映射
以系统服务方式管理容器
容器运行起来后当我们重启系统或是命令的删除会导致容器的关闭,所要保存的运行的程序服务就直接断掉了,如果下一次想要再去调用服务则必须要用手动的方式重新启动容器不易管理,以系统服务方式管理容器意味着将容器作为操作系统的一个服务来运行(将运行的容器制作成服务),并设置开就自启动,则在系统关闭时自动停止,开启时自动启动。
关于systemd:
服务(或称为守护进程、daemons)的启动、停止、重启等管理操作通常是通过
systemd来进行的。systemd是一个初始化系统,也是一个系统和服务管理器,在systemd中,每个服务都被视为一个“单元”(unit)。这些单元可以是服务、挂载点、设备、目标(target,类似于运行级别)等。服务单元的配置文件通常放在/etc/systemd/system/或/lib/systemd/system/目录下,并以.service作为文件扩展名。每个服务单元都有一个对应的配置文件,该文件描述了如何启动该服务、服务的依赖关系、启动用户等信息。例如,sshd服务的配置文件可能是sshd.service,而mysqld服务的配置文件可能是mysqld.service。所以总的来说
systemd是Linux系统中用于管理服务的一个工具。每个服务都被视为一个单元,并有一个对应的配置文件来描述如何管理服务。制作成单元文件后就可以被systemd进行管理,用systemctl命令进行操作。systemctl命令只要管理员才能进行管理,当我们把容器做成服务后要让普通用户也能使用systemctl命令来启用服务,则需要另外的选项--user来指定以下自己的用户,如果不加则是普通用户,加了则是以管理员身份运行。
a、如果想让用户来管理服务,则要将单元文件放到自己的家目录下
b、普通用户在使用systemctl命令启用服务时,默认情况下,服务在打开会话时启动,在关闭会话时停止(打开会话时指用ssh或图形化界面去登录用户,不是sudo或su去切换用户,因为该命令只在第一次登录用户界面时生效),但对于系统服务不同,系统服务是系统启动时启动,并在系统关机时停止。这种默认方式可以通过一些配置命令去实现普通用户所设置的服务也可以像系统服务一样
将容器制作成我们服务
1、首先,创建并运行容器,容器要取名(后面的服务名被扩展成container-容器名.service)
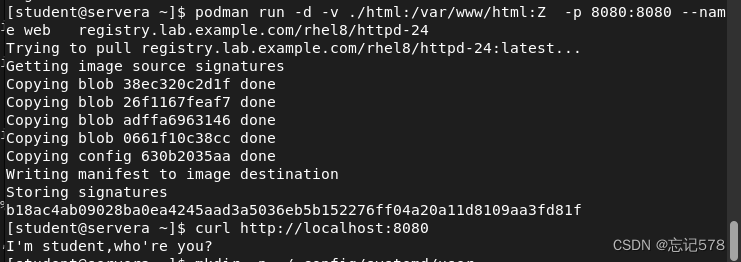
如上创建需要被挂载到容器的目录和文件,如上我做了id映射并修改拥有人和拥有组,因为我们知道web服务容器的系统用户时apache的id为48,所以没有新建容器再去查看,因为挂载的目录下还有文件,所以用-R选项递归修改拥有人和拥有组还有id映射,还有就是这里也可以不用修改其它用户的权限,因为我们只是访问不需要储存等。然后用curl去访问该端口,发现成功访问到了我们创建的的文件内容,说明我们挂载成功,且端口映射成功(通过访问主机的8080端口指定容器的8080端口),
2、在对应家目录路径下,创建单元文件指向容器。
单元文件的存放路径~/.config/systemd/user/存放(systemd目录没有的话自己创建)用podman generate systemd --name 容器名 --new --files 为现有容器创建单元文件。服务名被扩展成container-容器名.service
--new选项效果是在后面如果运行着的容器执行podman stop后,该容器则会被移除,相当于执行了podman rm 操作,没有加这个选项则当我们关闭容器后,该容器不会被删除,所以加了--new的效果是保证每一次运行的容器都是重新创建的,关机了就删除,开机就重新创建。
--files这个选项指示podman在当前目录中生成 systemd unit 文件(单元配置文件)。如果没有这个选项,podman 将在标准输出中显示 unit 文件的内容,而不是将其写入文件。
3、系统重新加载单元配置文件,注意在加载之前需要关闭和删除容器,否则服务在读取配置文件时会出现冲突,(删除一般时先停止在删除,不建议直接强制删除)
systemctl --user daemon-reload
如上查看到正在运行的容器,将其停止并删除,并用命令加载文件,注意daemon前面没有--,然后用systemctl --user start 服务名时开启该服务,如上当我们用systemctl --user stop 服务名去关闭时,可以看到容器也被删除(这就时加了--new选项的效果)。
4、使用systemctl管理服务
注意如果是用普通用户去管理服务,需要用loginctl enable-linger将我们的登录会话启动功能给它关闭,然后再使用systemmctlctl --user enable 服务名命令(不要忘了服务名)。如果是管理员用户则不需要这个命令。
随后我们重启servera然后在别的机器上访问servera的8080端口,发现即使我们没有登录servera上配置服务的用户也可以访问到到容器那8080端口的界面,说明我们成功将容器制作成服务,且可以和系统服务一样开机自启动,如下所示
补充:如果是以root用户身份使用systemd管理容器则和上面不同是
当使用podman generate systemd创建unit文件时,在/etc/systemd/system中运行而不是在~/.config/systemd/user中,当用systemctl配置容器的服务时,不需要使用--user选项(即用systemctl daemon-reload,且启动和关闭服务也不用--user选项),且不需要以root身份运行loginctl enable-linger(即不用运行loginctl --user enable-linger)























这篇关于rhcsa(rh134)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




