本文主要是介绍Leetcoder Day26| 回溯part06:总结+三道hard题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
332.重新安排行程
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。
提示:
- 如果存在多种有效的行程,请你按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前
- 所有的机场都用三个大写字母表示(机场代码)。
- 假定所有机票至少存在一种合理的行程。
- 所有的机票必须都用一次 且 只能用一次。
示例 1:
- 输入:[["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]]
- 输出:["JFK", "MUC", "LHR", "SFO", "SJC"]
示例 2:
- 输入:[["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
- 输出:["JFK","ATL","JFK","SFO","ATL","SFO"]
- 解释:另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"]。但是它自然排序更大更靠后。
这道题目有几个难点:
- 一个行程中,如果航班处理不好容易变成一个圈,成为死循环
- 有多种解法,字母序靠前排在前面,让很多同学望而退步,如何该记录映射关系呢 ?
- 使用回溯法(也可以说深搜) 的话,那么终止条件是什么呢?
- 搜索的过程中,如何遍历一个机场所对应的所有机场。
下面是一个有重复机场的例子 出发机场和到达机场也会重复的,如果在解题的过程中没有对集合元素处理好,就会死循环。
出发机场和到达机场也会重复的,如果在解题的过程中没有对集合元素处理好,就会死循环。
对于记录映射关系,可以用哈希集合。在这个过程中,需要可以增删元素。因为出发机场和到达机场是会重复的,搜索的过程没及时删除目的机场就会死循环。

按照回溯三部曲:
- 递归函数参数:要有机票数ticketNum,还要判断机票是否使用过,所以加一个bool数组used,注意,这里函数的返回值用的是bool,因为我们只需要找到一个行程,就是在树形结构中唯一的一条通向叶子节点的路线。之前在二叉树部分有总结过:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值。
- 递归终止条件:本题的终止条件可以这样考虑,如[["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]],有四张机票,5个机场,那么行程里的机场个数是5就可以了,也就是path里机场个数等于ticketNum+1
- 单层搜索的逻辑:如果这张机票没有被使用过,且当前机票的第一个机场,等于path里的最后一个机场,就可以将其添加进path。
class Solution {LinkedList<String> res;LinkedList<String> path=new LinkedList<>();public boolean backTracking(List<List<String>> tickets, boolean[] used){if(path.size()==tickets.size()+1){res=new LinkedList(path);return true;}for(int i=0;i<tickets.size();i++){if(!used[i] && tickets.get(i).get(0).equals(path.getLast())){used[i]=true;path.add(tickets.get(i).get(1));if(backTracking(tickets, used)){return true;}used[i]=false;path.removeLast();}}return false;}public List<String> findItinerary(List<List<String>> tickets) {Collections.sort(tickets, (a,b)->a.get(1).compareTo(b.get(1)));boolean[] used=new boolean[tickets.size()];path.add("JFK");backTracking(tickets, used);return res;}
}现在leetcode里这个方法已经超时了。
51. N皇后
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:
输入:n = 4 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]] 解释:如图所示,4 皇后问题存在两个不同的解法。
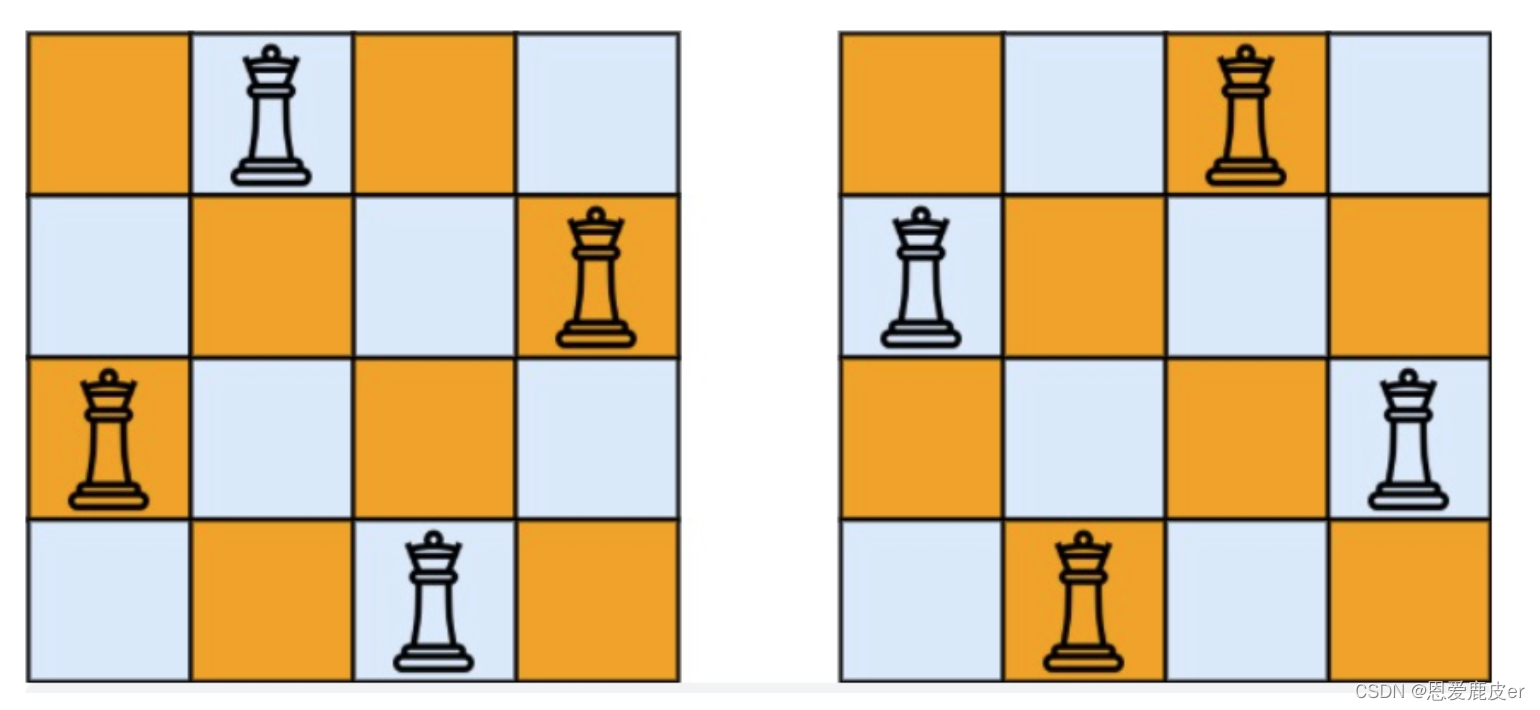
n皇后问题是回溯算法解决的经典问题,首先来看一下皇后们的约束条件:
- 不能同行
- 不能同列
- 不能同斜线
确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。
下面用一个 3 * 3 的棋盘,将搜索过程抽象为一棵树,如图:

从图中,可以看出,二维矩阵中矩阵的高就是这棵树的高度,矩阵的宽就是树形结构中每一个节点的宽度。用皇后们的约束条件,来回溯搜索这棵树,只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
- 递归函数参数:依然定义全局变量二维数组result来记录最终结果。参数n是棋盘的大小,然后用row来记录当前遍历到棋盘的第几层。
- 终止条件:递归到棋盘最底层(也就是叶子节点)的时候,就可以收集结果并返回
- 单层搜索的逻辑:递归深度就是row控制棋盘的行,每一层里for循环的col控制棋盘的列,一行一列,确定了放置皇后的位置。每次都是要从新的一行的起始位置开始搜,所以都是从0开始。这里面还涉及验证当前位置是否合法的方法,需要按照约束条件进行去重。这里不需要检查行是否重复,因为在单层搜索的过程中,每一层递归,只会选同一行里的一个元素,所以不用去重了。
在N皇后问题中,我们通常只考虑两个对角线方向:从左上角到右下角的45度对角线和从右上角到左下角的135度对角线。
这里还要注意⚠️,在将当前度棋盘结果添加到res中时,要将chessboard转换为List:res.add(Array2List(chessboard)); 因为原先的chessboard为二维数组:
public List Array2List(char[][] chessboard) {List<String> list = new ArrayList<>();for (char[] c : chessboard) {list.add(String.copyValueOf(c));}return list;}class Solution {List<List<String>> res =new ArrayList<>();public List ArraytoList(char[][] chessboard){List<String> list = new ArrayList<>();for(char[] c:chessboard){list.add(String.copyValueOf(c));}return list;}public boolean isValid(int row, int col, int n, char[][] chessboard){//检查列for(int i=0;i<row;i++){if(chessboard[i][col]=='Q'){return false;}}//检查45度斜线for(int i=row-1, j=col-1;i>=0 && j>=0; i--, j--){if(chessboard[i][j]=='Q'){return false;}}//检查135度斜线for(int i=row-1, j=col+1; i>=0 && j<n;i--,j++){if(chessboard[i][j]=='Q'){return false;}}return true;}public void backTracking(int n, int row, char[][] chessboard){if(row==n){res.add(ArraytoList(chessboard));return;}for(int col=0;col<n;col++){if(isValid(row, col, n, chessboard)){chessboard[row][col]='Q';backTracking(n, row+1, chessboard);chessboard[row][col]='.';}}}public List<List<String>> solveNQueens(int n) {char[][] chessboard=new char[n][n];for(char[]c:chessboard){Arrays.fill(c,'.');}backTracking(n,0,chessboard);return res;}
}总结
回溯部分涉及到的题型比较多,而且在二叉树环节也用到了回溯。回溯的问题都可以抽象为树结构,并且其本质是递归,也就是,只要有递归就会有回溯!这次刷题从代码随想录里学到了很有用的回溯模板,但是也不能只依赖于套模板,要具体问题具体分析。
回溯算法能解决如下问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等
回溯的模板:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}组合问题
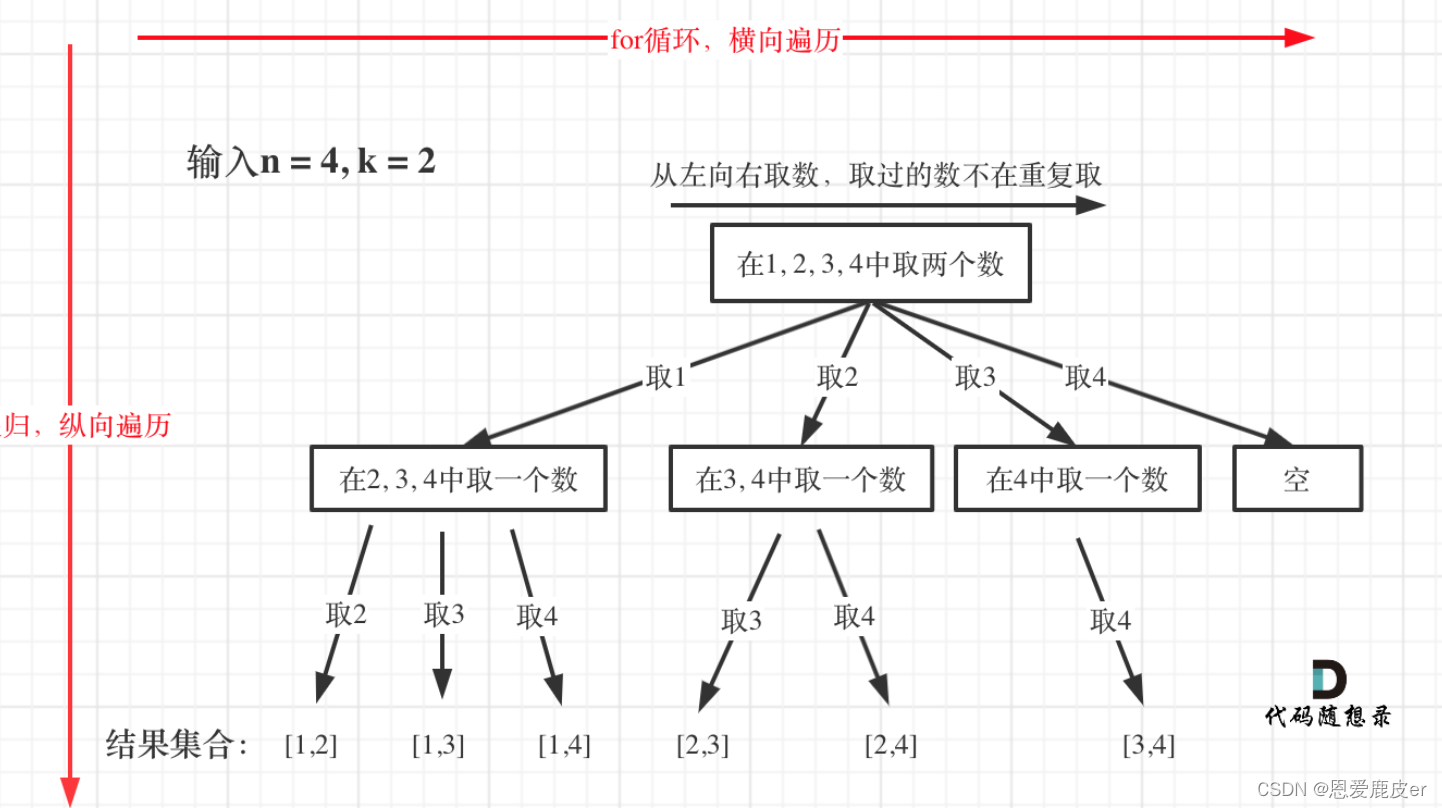
for循环横向遍历,递归纵向遍历,回溯不断调整结果集,因为取过的元素不再重复取,所以需要startIdx。如果是一个集合来求组合的话,就需要startIndex,如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,比如电话号码组合问题。
优化回溯算法只有剪枝一种方法,思路就是如果剩下的元素个数已经不满足需要的元素,就停止搜索。
(1)如果有元素总和的限制,剪枝的思路就是已选元素总和如果已经大于n(题中要求的和)了,那么往后遍历就没有意义了,直接剪掉
(2)如果包含重复数值的元素,那么使用过的就不能再次使用,carl哥用树枝重复和树层重复来进行细分。可以通过创建一个used数组来记录,也可以使用startIdx来进行去重,先对数组进行排序,如果candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
(3)多个集合来求组合,就不需要startIdx,而是从0开始遍历。
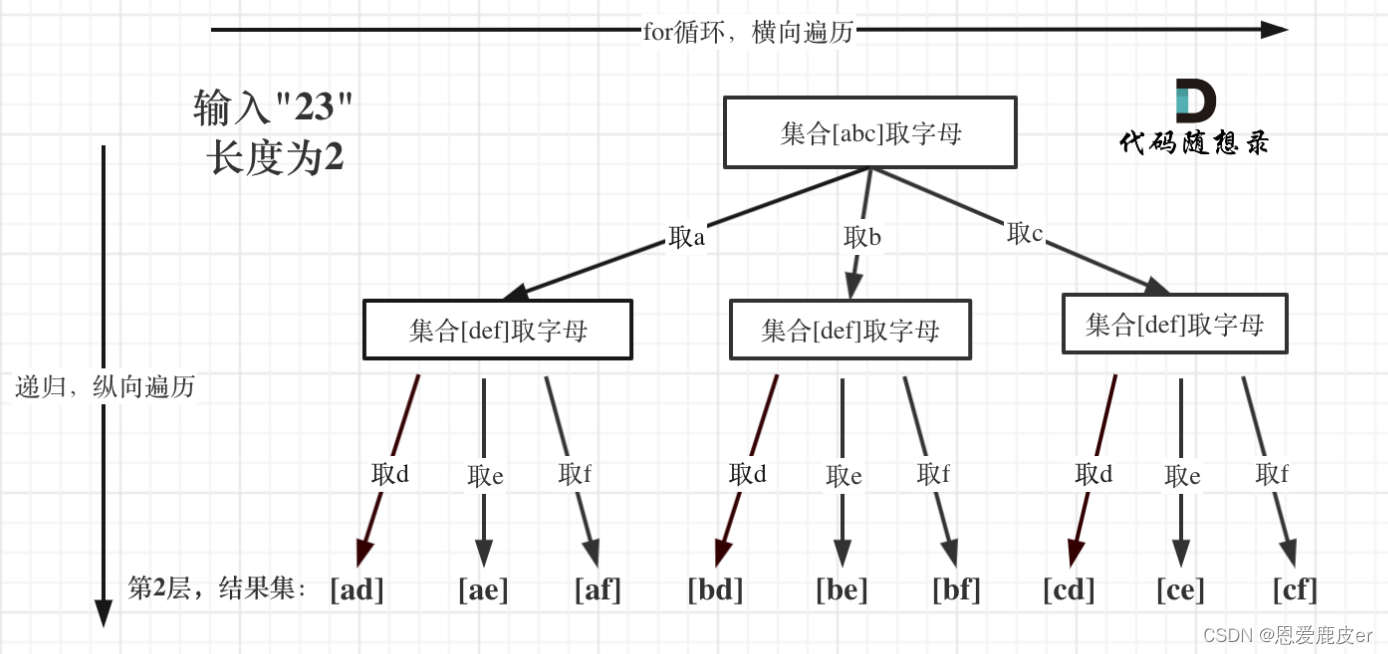
切割问题
切割问题有如下几个难点:
- 切割问题其实类似组合问题
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
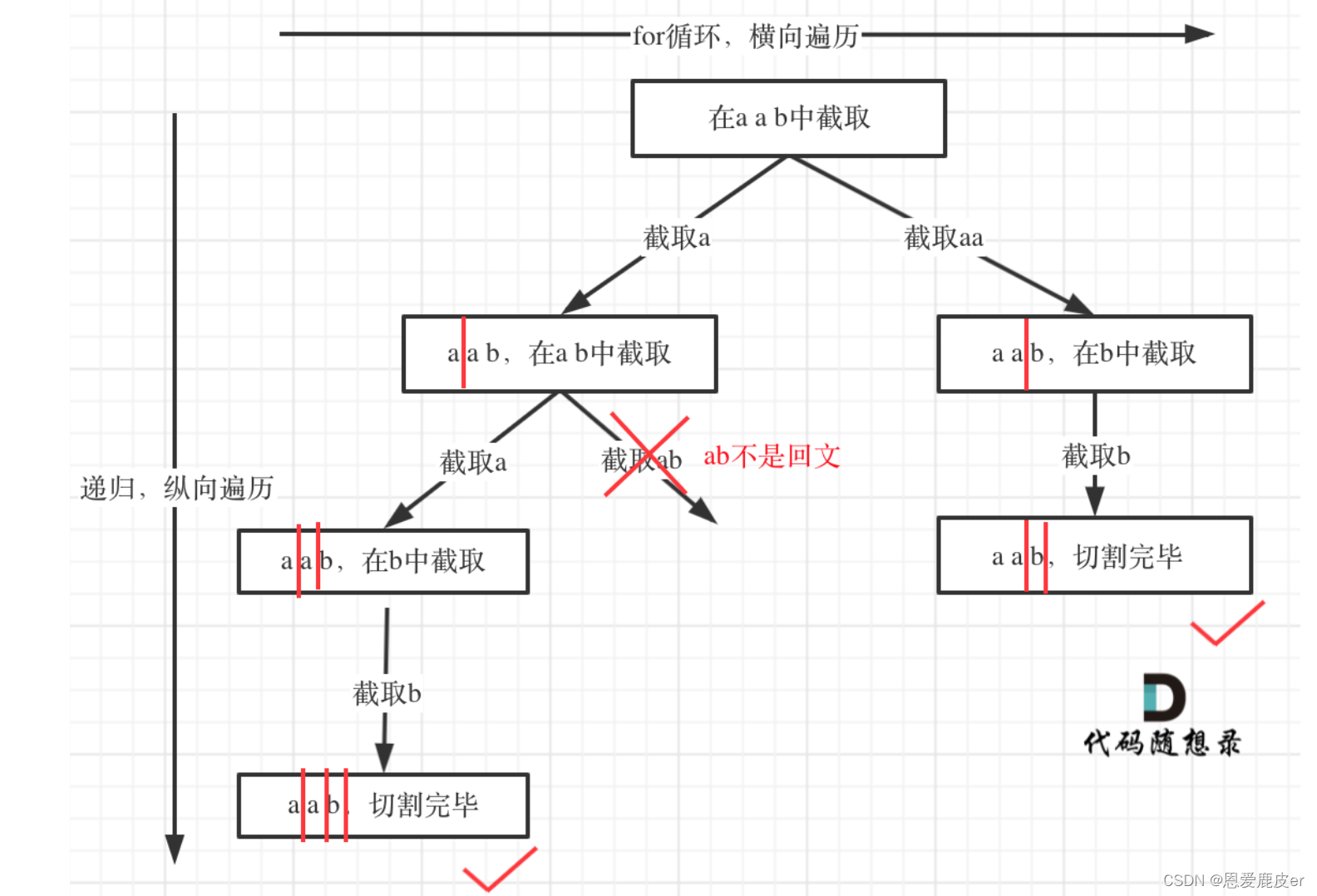
如果想到了用求解组合问题的思路来解决 切割问题本题就成功一大半了,接下来就可以对着模板照葫芦画瓢。但后序如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了。
所以本题应该是一个道hard题目了。除了这些难点,本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1。
树形结构如下:
子集问题
要记住,在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果。
子集问题一般都会先进行排序,注意:result.push_back(path);要放在终止条件的上面,如下:
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉结果
if (startIndex >= nums.size()) { // 终止条件可以不加return;
}在求递增子序列的时候一定注意,不可以进行排序。所以可以借助哈希集合,记录当前元素是否被使用过。
排列问题
排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素
这篇关于Leetcoder Day26| 回溯part06:总结+三道hard题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





