本文主要是介绍阿里云-系统盘-磁盘扩容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阿里云系统磁盘扩容
之前是测试环境磁盘用的默认的有 40G,后面升级到正式的 磁盘怕不够用打算升级到 100G,
系统镜像: Alibaba Cloud Linux 3.2104 LTS 64 位 磁盘 ESSD 40G
升级步骤:
扩容与创建快照
-
在阿里云后台首先去扩容下磁盘容量。
-
进入存储与快照-云盘

建议扩容前 为云盘创建快照,防止误操作数据丢失,也就是点下上面创建快照的按钮的事情,然后定义名称即可。
注意快照是收费的如果用完后记得删除快照,虽然不多,但是时间长了也是钱啊~~。
扩容分区和文件系统
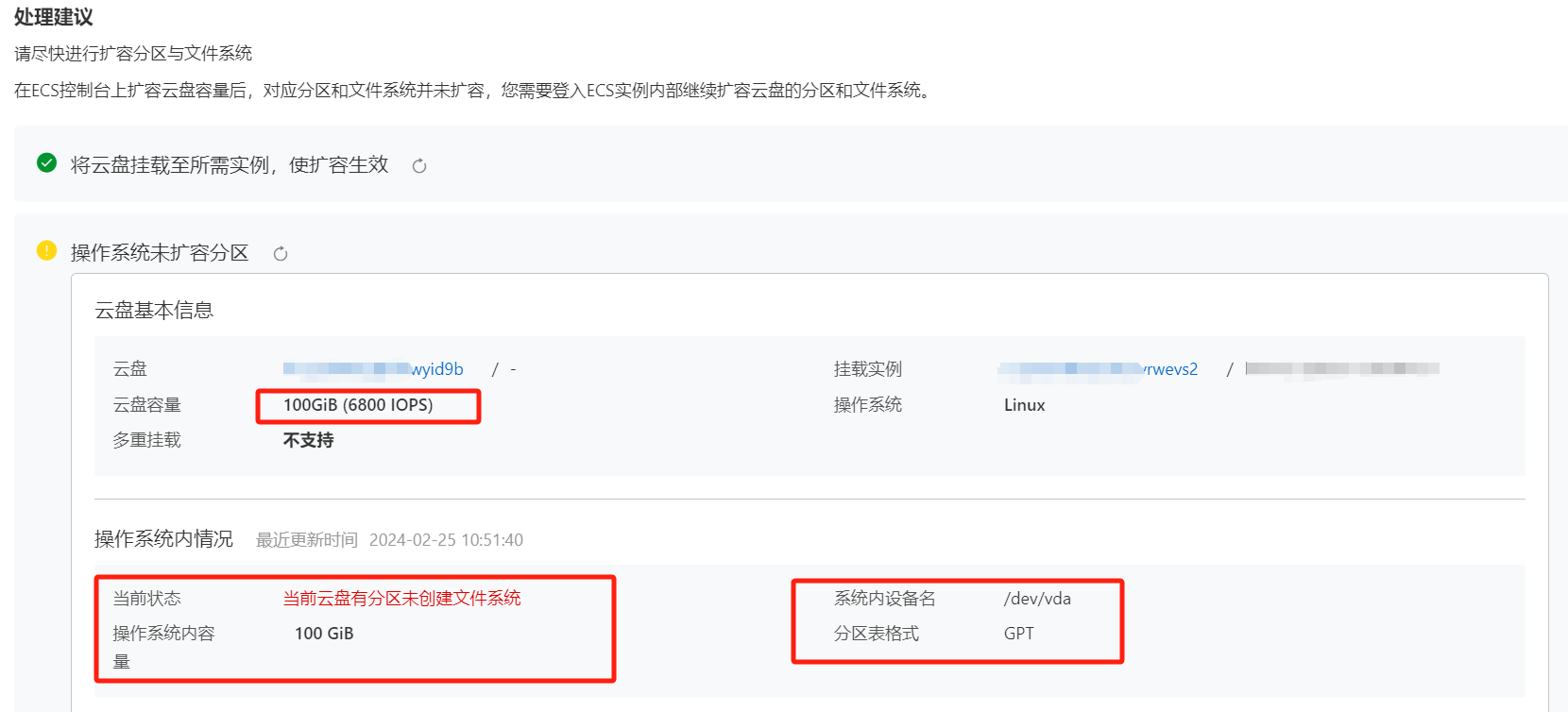
我上面扩容到 100G ,后面根据提示填写即可 。一般上面创建好后,阿里云后台容量就会变成 100G

在 块存储 EBS/工具集 有个工具可以检测云盘状态

通过云助手
在阿里云后台首先去扩容下磁盘容量。
-
查看 ECS 实例的云助手 Agent 信息
-
登录 ECS 管理控制台。
-
在左侧导航栏,选择运维与监控 > 云助手。
-
在页面左侧顶部,选择目标资源所在的资源组和地域。
正常按照文档,通过上面的检测工具可以生成扩容命令,我这里应该是升级了系统规格导致不能使用这种方式

通过文档自动敲命令
自己动手,丰衣足食~~
-
运行以下命令,确认待扩容云盘及其分区信息。
sudo fdisk -lu
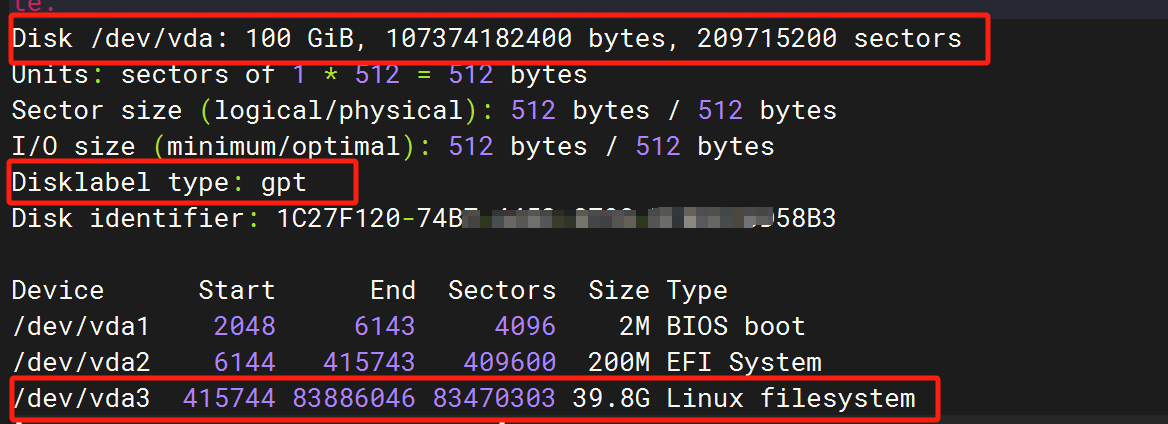
注意 我这里扩容的是系统盘 标识就是 vda 文档是数据盘 是 vdb 或者通过 lsblk 命令查看哪个分区待扩容。

vda3 这里我是扩容过的原来是 40G
扩容分区
GPT 分区(需安装 gdisk 工具)
sudo apt-get update type growpart || sudo apt-get install -y cloud-guest-utilstype sgdisk || sudo apt-get install -y gdisk安装好上面的工具则开始执行扩容分区命令
sudo LC_ALL=en_US.UTF-8 growpart /dev/vda 3
注意根据自己的磁盘信息修改命令
输出 CHANGED 字样时,表示分区扩容成功。

扩容文件系统
获取需要扩容的文件系统的类型和挂载目录。
df -Th

Type 值为文件系统类型,Mounted on 值为分区的挂载目录。如下图表示/dev/vda3 分区的文件系统类型为 ext4,挂载目录为/。
执行如下命令扩容文件 (ext4 文件系统类型)
resize2fs /dev/vda3

再次运行如下命令确认结果
df -Th
这篇关于阿里云-系统盘-磁盘扩容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







