本文主要是介绍[论文] SegFormer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
摘要:
我们介绍的 SegFormer 是一个简单、高效但功能强大的语义分割框架,它将 Transformers 与轻量级多层感知器 (MLP) 解码器结合在一起。SegFormer 有两个吸引人的特点:
1) SegFormer包含一个可以输出多尺度信息的transformer编码器(没有使用position embedding,避免了position插值);当测试分辨率与训练分辨率不同时,插值会导致性能下降。
2) SegFormer 避免了复杂的解码器。所提出的 MLP 解码器汇聚了来自不同层的信息,从而将局部注意力和全局注意力结合起来,呈现出强大的表征。
我们的研究表明,这种简单轻便的设计是在 Transformers 上实现高效分割的关键。我们通过扩展我们的方法,获得了从 SegFormer-B0 到 SegFormer-B5 的一系列模型,其性能和效率明显优于之前的同类产品。例如,SegFormer-B4 在 64M 参数的 ADE20K 上实现了 50.3% 的 mIoU,比之前的最佳方法小 5 倍,好 2.2%。我们的最佳模型 SegFormer-B5 在 Cityscapes 验证集上实现了 84.0% 的 mIoU,并在 Cityscapes-C 上显示了出色的零点稳健性。
1 引言
语义分割是计算机视觉中的一项基本任务,可用于许多下游应用。它与图像分类相关,因为它产生的是每个像素的类别预测,而不是图像级预测。在一项开创性工作[1]中,作者指出并系统地研究了这种关系,并将全卷积网络(FCN)用于语义分割任务。此后,FCN 激发了许多后续工作,并成为密集预测的主要设计选择。
“Since there is a strong relation between classification and semantic segmentation, many stateof-the-art semantic segmentation frameworks are variants of popular architectures for image classification on ImageNet.”
在计算机视觉领域,图像分类和语义分割任务之间有着密切的关系。许多最先进的语义分割框架都是基于在ImageNet上进行图像分类的流行架构的变体。
这样做的原因在于图像分类和语义分割任务都需要从图像中提取有意义的特征以进行预测。卷积神经网络(CNN)在从图像中捕获分层特征方面非常有效,因此适用于各种计算机视觉任务。
在语义分割任务中,关键挑战是为图像中的每个像素分配一个类别标签,表示该像素所属的对象或区域的类别。为了解决这个问题,语义分割框架修改现有的图像分类架构,以处理像素级别的密集预测。
例如,全卷积网络(FCN)是一种用于语义分割的流行架构。FCN基于用于图像分类的VGG16架构,但将VGG16的全连接层替换为1x1卷积层,以实现对每个像素的密集预测。
类似地,其他流行的架构,如U-Net、DeepLab和SegNet,都是基于知名的图像分类架构,并经过修改以适应语义分割任务的需求。
这种将图像分类架构的知识转移和调整应用于语义分割,已经成功地实现了计算机视觉领域的最先进结果。通过利用ImageNet上预训练的权重,这些分割框架可以从图像中学习有意义的特征,并且即使在语义分割的有限标注数据情况下,也能很好地泛化到新的数据集。
“Therefore, designing backbone architectures has remained an active area in semantic segmentation. Indeed, starting from early methods using VGGs [1, 2], to the latest methods with significantly deeper and more powerful backbones [3], the evolution of backbones has dramatically pushed the performance boundary of semantic segmentation.” (Xie 等, 2021, p. 2)
因此,设计骨干网络架构一直是语义分割领域中的一个活跃领域。事实上,从最早使用VGG网络[1, 2]的方法,到现在使用更深、更强大的骨干网络[3]的最新方法,骨干网络的演进极大地推动了语义分割性能的界限。在语义分割任务中,骨干网络负责从图像中提取高级特征,这些特征在后续的分割任务中发挥着关键作用。通过设计更强大的骨干网络,可以获得更丰富的图像特征,并且在语义分割任务中取得更好的性能。随着计算机视觉领域的不断发展,研究人员提出了许多不同的骨干网络架构,如ResNet、ResNeXt、Dilated ResNet、HRNet等。这些骨干网络在图像分类任务中已经得到验证,并且可以通过迁移学习应用于语义分割任务。使用更深、更复杂的骨干网络,可以提高模型的表示能力和感受野,使其能够更好地捕捉图像中的语义信息。这些进展使得语义分割方法在处理复杂场景和具有细粒度结构的图像时取得了显著的性能提升。因此,骨干网络的演进对于推动语义分割技术的发展具有重要意义。
“Besides backbone architectures, another line of work formulates semantic segmentation as a structured prediction problem, and focuses on designing modules and operators, which can effectively capture contextual information. A representative example in this area is dilated convolution [4, 5], which increases the receptive field by “inflating” the kernel with holes.” (Xie 等, 2021, p. 2)
除了骨干网络架构,另一种方法将语义分割看作是一种结构化预测问题,并专注于设计模块和运算符,以有效地捕捉上下文信息。在这个领域中,一个代表性的例子是空洞卷积(dilated convolution)[4, 5],通过在卷积核中添加“空洞”来增加感受野。在语义分割任务中,上下文信息对于准确地区分不同的语义类别非常重要。然而,标准的卷积操作在捕捉全局上下文信息时存在一定的限制,特别是对于大尺寸的感受野。为了解决这个问题,空洞卷积被引入。空洞卷积通过在卷积核中引入空洞或者称为膨胀率(dilation rate),使得卷积核的有效感受野变大。这种方式可以在保持参数量不变的情况下,增加卷积核对远处像素的感知范围,从而捕捉更广阔的上下文信息。通过使用空洞卷积,语义分割模型能够更好地理解图像中的全局结构和语义信息,从而提高分割结果的准确性。空洞卷积已经成为许多最先进的语义分割方法中的重要组件,为解决复杂场景下的分割问题提供了有效的解决方案。同时,还有其他一些设计模块和操作符的方法,用于捕捉上下文信息,进一步推动了语义分割技术的发展。
在语义分割中,低级特征和高级特征是指在神经网络中不同层次的特征表示。1. 低级特征(Low-level features):低级特征是指在神经网络较早的层次中提取的特征表示。这些特征通常包含局部的、细节性的信息,比如边缘、纹理和颜色等低级信息。在卷积神经网络(CNN)中,低级特征通常由浅层的卷积层提取,因为这些层主要负责对输入图像的局部信息进行特征提取。低级特征的感受野较小,只能感知图像的局部信息,而不具备全局的上下文理解能力。因此,低级特征更适合用于处理图像的细节信息。2. 高级特征(High-level features):高级特征是指在神经网络较深的层次中提取的特征表示。这些特征通常包含更加抽象和语义化的信息,比如物体的形状、类别和位置等高级语义信息。在卷积神经网络中,高级特征通常由深层的卷积层或全连接层提取,因为这些层具有更大的感受野和更强的表达能力,能够理解图像的全局结构和语义信息。高级特征适合用于对图像中的整体语义信息进行建模和分析。在语义分割任务中,通常会采用多尺度的特征融合策略,将低级特征和高级特征进行合并,以获得更加全面和丰富的特征表示。低级特征可以帮助提取图像的细节信息,而高级特征可以帮助理解图像的整体语义结构,从而在分割过程中获得更准确的结果。因此,在设计语义分割模型时,合理地利用低级特征和高级特征是非常重要的。
在语义分割和计算机视觉领域中,"上下文"(Context)是指图像中像素或区域的周围环境和背景信息。具体来说,上下文是指与特定像素或区域相关的邻近像素的信息,包括它们的值、位置和语义等。在图像中,每个像素的含义和类别通常受到其周围像素的影响,因为图像中的像素往往在语义上具有一定的连续性和相关性。 上下文信息在语义分割中具有重要作用,特别是对于像素级别的分类任务。通过考虑像素的上下文信息,可以更好地理解图像的语义结构,提高对像素的正确分类和分割准确性。例如,在一个物体的边界区域,单独考虑一个像素的信息可能无法确定其属于哪个类别,但通过分析周围像素的上下文信息,可以更准确地判断其所属类别。为了有效利用上下文信息,常用的方法包括使用卷积神经网络(CNN)的较大感受野、使用空洞卷积(Dilated Convolution)来扩展感受野,以及采用多尺度或金字塔结构来融合不同尺度的上下文信息。这些方法能够帮助模型更好地理解图像的语义信息,从而提高语义分割任务的性能。
Witnessing the great success in natural language processing (NLP), there has been a recent surge of interest to introduce Transformers to vision tasks. Dosovitskiy et al. [6] proposed vision Transformer (ViT) for image classification. Following the Transformer design in NLP, the authors split an image into multiple linearly embedded patches and feed them into a standard Transformer with positional embeddings (PE), leading to an impressive performance on ImageNet. In semantic segmentation, Zheng et al. [7] proposed SETR to demonstrate the feasibility of using Transformers in this task.
随着自然语言处理(NLP)领域中Transformer模型的巨大成功,近年来越来越多的研究开始将Transformer引入视觉任务中。Dosovitskiy等人在论文[6]中提出了视觉Transformer(ViT)用于图像分类任务。借鉴了NLP中的Transformer设计,作者将图像划分为多个线性嵌入的小块(patches),然后将它们输入到带有位置嵌入(PE)的标准Transformer中,从而在ImageNet图像分类任务上取得了令人印象深刻的性能。
在语义分割任务中,Zheng等人在论文[7]中提出了SETR模型,以证明在该任务中使用Transformer的可行性。SETR模型同样将图像分割成多个线性嵌入的小块,并利用Transformer来捕捉全局和局部的上下文信息,从而实现了对语义分割任务的处理。
这些研究表明,将Transformer应用于计算机视觉领域是可行的,并且在某些任务上能够取得出色的性能。Transformer模型的引入为图像处理任务带来了新的思路和方法,为视觉与语言之间的交叉研究提供了新的契机。随着不断的研究和发展,相信在更多的视觉任务中将看到Transformer的应用和进一步的创新。
SETR adopts ViT as a backbone and incorporates several CNN decoders to enlarge feature resolution. Despite the good performance, ViT has some limitations: 1) ViT outputs single-scale low-resolution features instead of multi-scale ones. 2) It has high computation cost on large images. To address these limitations, Wang et al. [8] proposed a pyramid vision Transformer (PVT), a natural extension of ViT with pyramid structures for dense prediction. PVT shows considerable improvements over the ResNet counterpart on object detection and semantic segmentation. However, together with other emerging methods such as Swin Transformer [9] and Twins [10], these methods mainly consider the design of the Transformer encoder, neglecting the contribution of the decoder for further improvements.
SETR采用了ViT作为骨干网络,并结合了多个CNN解码器以增加特征分辨率。尽管ViT表现良好,但它也存在一些局限性:1)ViT输出单尺度低分辨率特征,而不是多尺度特征。2)对于大尺寸的图像,ViT计算成本较高。为了解决这些限制,Wang等人在论文[8]中提出了金字塔视觉Transformer(PVT),它是ViT的自然延伸,引入了金字塔结构用于密集预测任务。PVT在目标检测和语义分割任务上相比ResNet等对应方法取得了显著的改进。
然而,与其他新兴方法(例如Swin Transformer [9]和Twins [10])一样,这些方法主要关注Transformer编码器的设计,而忽视了解码器在进一步改进中的作用。
在语义分割任务中,解码器在输出的特征图上进行上采样和融合,用于将低分辨率的特征恢复到原始图像大小并进行细节恢复。因此,设计有效的解码器对于实现高质量的语义分割至关重要。未来的研究可能会探索更多关于解码器的创新和优化,以进一步提高语义分割模型的性能。同时,继续挖掘Transformer的优势,将其应用于视觉任务中的更多方向,有望推动计算机视觉领域的进一步发展和突破。
This paper introduces SegFormer, a cutting-edge Transformer framework for semantic segmentation that jointly considers efficiency, accuracy, and robustness. In contrast to previous methods, our framework redesigns both the encoder and the decoder. The key novelties of our approach are:
• A novel positional-encoding-free and hierarchical Transformer encoder.
• A lightweight All-MLP decoder design that yields a powerful representation without complex and computationally demanding modules.
• As shown in Figure 1, SegFormer sets new a state-of-the-art in terms of efficiency, accuracy and robustness in three publicly available semantic segmentation datasets.
本论文介绍了SegFormer,这是一个在语义分割任务中同时考虑效率、准确性和鲁棒性的前沿Transformer框架。与之前的方法不同,该框架对编码器和解码器进行了重新设计。我们方法的关键创新点包括:
• 一种新颖的无位置编码和分层Transformer编码器。
• 一种轻量级的全连接层(All-MLP)解码器设计,可以在不使用复杂和计算量大的模块的情况下产生强大的表示。
• 如图1所示,SegFormer在三个公开可用的语义分割数据集中在效率、准确性和鲁棒性方面均刷新了现有的最新技术水平。
SegFormer的引入为语义分割任务带来了新的解决方案,使得在保持高效率的同时,能够获得更高的准确性和更强的鲁棒性。这对于实际应用和计算机视觉领域的研究都具有重要意义。

First, the proposed encoder avoids interpolating positional codes when performing inference on images with resolutions different from the training one. As a result, our encoder can easily adapt to arbitrary test resolutions without impacting the performance. In addition, the hierarchical part enables the encoder to generate both high-resolution fine features and low-resolution coarse features, this is in contrast to ViT that can only produce single low-resolution feature maps with fixed resolutions. Second, we propose a lightweight MLP decoder where the key idea is to take advantage of the Transformer-induced features where the attentions of lower layers tend to stay local, whereas the ones of the highest layers are highly non-local. By aggregating the information from different layers, the MLP decoder combines both local and global attention. As a result, we obtain a simple and straightforward decoder that renders powerful representations.
首先,我们提出的编码器在对分辨率与训练分辨率不同的图像进行推理时避免了插值位置编码。因此,我们的编码器可以轻松地适应任意测试分辨率,而不会影响性能。此外,分层部分使编码器能够生成高分辨率的精细特征和低分辨率的粗糙特征,这与ViT不同,后者只能产生具有固定分辨率的单一低分辨率特征图。
其次,我们提出了一种轻量级的MLP解码器,其关键思想是利用Transformer所引发的特征,其中较低层的注意力倾向于保持局部性,而最高层的注意力则高度非局部。通过聚合来自不同层的信息,MLP解码器结合了局部和全局的关注。因此,我们得到了一个简单直接的解码器,它能够产生强大的表示。
通过上述创新,SegFormer在编码器和解码器的设计上都具有优势。编码器的避免插值位置编码和分层结构,使得模型能够更好地适应不同分辨率的图像。而解码器的轻量级MLP设计使得模型在不牺牲性能的前提下更加高效。这些特点共同使得SegFormer在语义分割任务中取得了优异的效果,在效率、准确性和鲁棒性方面都表现出色。
We demonstrate the advantages of SegFormer in terms of model size, run-time, and accuracy on three publicly available datasets: ADE20K, Cityscapes, and COCO-Stuff. On Citysapces, our lightweight model, SegFormer-B0, without accelerated implementations such as TensorRT, yields 71.9% mIoU at 48 FPS, which, compared to ICNet [11], represents a relative improvement of 60% and 4.2% in latency and performance, respectively. Our largest model, SegFormer-B5, yields 84.0% mIoU, which represents a relative 1.8% mIoU improvement while being 5 × faster than SETR [7]. On ADE20K, this model sets a new state-of-the-art of 51.8% mIoU while being 4 × smaller than SETR. Moreover, our approach is significantly more robust to common corruptions and perturbations than existing methods, therefore being suitable for safety-critical applications. Code will be publicly available.
我们在三个公开数据集(ADE20K、Cityscapes和COCO-Stuff)上展示了SegFormer在模型大小、运行时间和准确性方面的优势。在Cityscapes数据集上,我们的轻量级模型SegFormer-B0,在没有使用TensorRT等加速实现的情况下,实现了71.9%的mIoU,并以48 FPS的速度运行。与ICNet相比,我们的模型在延迟和性能方面分别提高了60%和4.2%。
我们最大的模型SegFormer-B5实现了84.0%的mIoU,在比SETR快5倍的情况下,相对于SETR实现了1.8%的mIoU改进。在ADE20K数据集上,该模型实现了51.8%的mIoU,比SETR小4倍,并且创造了新的mIoU记录。
此外,与现有方法相比,我们的方法对常见的数据破坏和扰动具有更强的鲁棒性,因此适用于对安全性要求较高的应用。我们的代码将公开提供。
2 Related Work
Semantic Segmentation. Semantic segmentation can be seen as an extension of image classification from image level to pixel level. In the deep learning era [12–16], FCN [1] is the fundamental work of semantic segmentation, which is a fully convolution network that performs pixel-to-pixel classification in an end-to-end manner. After that, researchers focused on improving FCN from different aspects such as: enlarging the receptive field [17–19, 5, 2, 4, 20]; refining the contextual information [21–29]; introducing boundary information [30–37]; designing various attention modules [38–46]; or using AutoML technologies [47–51]. These methods significantly improve semantic segmentation performance at the expense of introducing many empirical modules, making the resulting framework computationally demanding and complicated. More recent methods have proved the effectiveness of Transformer-based architectures for semantic segmentation [7, 46]. However, these methods are still computationally demanding.
语义分割可以被看作是将图像分类从图像级别扩展到像素级别的一种任务。在深度学习时代[12-16],全卷积网络(FCN)[1]是语义分割的基础工作,它是一个完全卷积的网络,可以以端到端的方式对每个像素进行分类。随后的研究聚焦于从不同方面改进FCN,例如:扩大感受野[17-19, 5, 2, 4, 20]、优化上下文信息[21-29]、引入边界信息[30-37]、设计各种注意力模块[38-46]或使用AutoML技术[47-51]。这些方法显著提高了语义分割的性能,但也引入了许多经验性模块,使得生成的框架计算复杂且要求较高。
更近期的研究表明,在语义分割中基于Transformer架构的方法[7, 46]也非常有效。然而,这些方法仍然对计算资源要求较高。
Transformer backbones. ViT [6] is the first work to prove that a pure Transformer can achieve state-of-the-art performance in image classification. ViT treats each image as a sequence of tokens and then feeds them to multiple Transformer layers to make the classification. Subsequently, DeiT [52] further explores a data-efficient training strategy and a distillation approach for ViT. More recent methods such as T2T ViT [53], CPVT [54], TNT [55], CrossViT [56] and LocalViT [57] introduce tailored changes to ViT to further improve image classification performance. Beyond classification, PVT [8] is the first work to introduce a pyramid structure in Transformer, demonstrating the potential of a pure Transformer backbone compared to CNN counterparts in dense prediction tasks. After that, methods such as Swin [9], CvT [58], CoaT [59], LeViT [60] and Twins [10] enhance the local continuity of features and remove fixed size position embedding to improve the performance of Transformers in dense prediction tasks.
Transformer编码器的背骨网络。ViT [6] 是第一个证明纯Transformer可以在图像分类任务中达到最先进性能的工作。ViT将每个图像视为一系列标记(tokens),然后将它们输入多个Transformer层进行分类。随后,DeiT [52] 进一步探索了对ViT的数据高效训练策略和蒸馏方法。更近期的方法,如T2T ViT [53]、CPVT [54]、TNT [55]、CrossViT [56] 和 LocalViT [57] 对ViT进行了定制化的改进,以进一步提高图像分类性能。
除了分类任务,PVT [8] 是第一个在Transformer中引入金字塔结构的工作,展示了纯Transformer背骨相比CNN在密集预测任务中的潜力。之后,方法如Swin [9]、CvT [58]、CoaT [59]、LeViT [60] 和 Twins [10] 加强了特征的局部连续性,并去除了固定大小的位置嵌入,以提高Transformer在密集预测任务中的性能。这些方法在密集预测任务中对Transformer进行了改进,使得Transformer在语义分割等任务上表现得更加优越。
Transformers for specific tasks. DETR [52] is the first work using Transformers to build an end-toend object detection framework without non-maximum suppression (NMS). Other works have also used Transformers in a variety of tasks such as tracking [61, 62], super-resolution [63], ReID [64], Colorization [65], Retrieval [66] and multi-modal learning [67, 68]. For semantic segmentation, SETR [7] adopts ViT [6] as a backbone to extract features, achieving impressive performance. However, these Transformer-based methods have very low efficiency and, thus, difficult to deploy in real-time applications.
针对特定任务的Transformer应用。DETR [52] 是第一个使用Transformer构建端到端目标检测框架,并且不需要使用非最大抑制(NMS)。其他工作也将Transformer应用于各种任务,如跟踪 [61, 62]、超分辨率 [63]、ReID [64]、上色 [65]、检索 [66] 和多模态学习 [67, 68]。对于语义分割任务,SETR [7] 采用了ViT [6] 作为背骨网络来提取特征,并取得了令人印象深刻的性能。然而,这些基于Transformer的方法效率很低,因此在实时应用中很难部署。
非最大抑制(Non-Maximum Suppression,NMS)是一种用于目标检测和物体识别任务的后处理技术。在目标检测中,检测器通常会在输入图像中找到多个候选目标框(bounding boxes),这些候选框可能对同一物体的不同部分或重叠区域进行检测。为了避免重复检测和减少冗余信息,NMS算法被用于去除冗余的候选框。
NMS的原理是通过对候选框进行置信度(confidence)排序,并选择置信度最高的框作为最终检测结果,然后移除与该框高度重叠的其他框。具体而言,NMS从置信度最高的框开始,逐个检查其它候选框与该框的重叠程度(例如,重叠面积),如果重叠程度高于设定的阈值,则将该候选框移除。这样一步步地遍历所有候选框,直至没有重叠较高的框为止。
通过应用NMS算法,可以确保在目标检测结果中只保留最显著的候选框,避免了多余的重复信息,提高了目标检测的准确性和效率。
3 Method
This section introduces SegFormer, our efficient, robust, and powerful segmentation framework without hand-crafted and computationally demanding modules. As depicted in Figure 2, SegFormer consists of two main modules: (1) a hierarchical Transformer encoder to generate high-resolution coarse features and low-resolution fine features; and (2) a lightweight All-MLP decoder to fuse these multi-level features to produce the final semantic segmentation mask.
本节介绍SegFormer,我们的高效、鲁棒和强大的语义分割框架,该框架避免了使用手工设计的、计算开销较大的模块。如图2所示,SegFormer由两个主要模块组成:(1) 层级Transformer编码器,用于生成高分辨率的粗糙特征和低分辨率的细粒度特征;以及(2) 轻量级的全连接MLP(多层感知机)解码器,用于融合这些多级特征以生成最终的语义分割掩模。
1. 层级Transformer编码器:这个模块用于处理输入图像,并将其分解为多个线性嵌入的图像块(patches)。然后,这些图像块通过多个Transformer层进行处理,以生成高分辨率的粗糙特征和低分辨率的细粒度特征。与传统的Transformer编码器不同的是,SegFormer采用层级结构,使得编码器能够同时产生多个特征层,从而更好地捕捉图像中的语义信息。
2. 轻量级的全连接MLP解码器:这个模块用于将编码器产生的多级特征进行融合,从而生成最终的语义分割掩模。相比于复杂和计算开销较大的模块,SegFormer采用了全连接MLP,这使得解码器的设计更加简单和高效,同时仍能生成强大的特征表示。
SegFormer的这两个主要模块相互配合,使得该框架能够在语义分割任务中取得高效、准确和鲁棒的性能,而无需手工设计的复杂模块和高计算开销。
这一部分介绍了SegFormer,我们高效、稳健和强大的分割框架,它不需要手工设计的、计算复杂的模块。如图2所示,SegFormer由两个主要模块组成:(1) 一个层次化的Transformer编码器,用于生成高分辨率的粗糙特征和低分辨率的细粒度特征;以及(2) 一个轻量级的全连接MLP解码器,用于融合这些多级特征以生成最终的语义分割掩码。
1. 层次化Transformer编码器:这个模块用于处理输入图像,将其分成多个线性嵌入的图像块(patches)。然后,通过多个Transformer层对这些图像块进行处理,生成高分辨率的粗糙特征和低分辨率的细粒度特征。与传统的Transformer编码器不同,SegFormer使用层次结构,使编码器能够同时生成多个特征层,从而更好地捕捉图像的语义信息。
2. 轻量级全连接MLP解码器:这个模块用于将编码器生成的多级特征进行融合,从而生成最终的语义分割掩码。与复杂且计算密集的模块相比,SegFormer采用轻量级的全连接MLP,使得解码器设计更简单高效,同时仍能生成强大的特征表示。
SegFormer的这两个主要模块相互配合,使其能够在语义分割任务中实现高效、稳健和强大的性能,而无需手工设计的复杂模块和高计算开销。

在给定尺寸为 H × W × 3 的图像上,我们首先将其分割成大小为 4 × 4 的块(或称为“patches”)。与ViT使用大小为 16 × 16 的块不同,使用较小的块有利于密集预测任务。接下来,我们将这些块作为输入传递给分层Transformer编码器,以获得在原始图像分辨率的 {1/4, 1/8, 1/16, 1/32} 处的多级特征。然后,我们将这些多级特征传递给全连接多层感知机(All-MLP)解码器,以预测分割掩模,其分辨率为 ,其中
是类别的数量。在本节的其余部分,我们详细介绍了提出的编码器和解码器设计,并总结了我们的方法与SETR之间的主要区别。
3.1 Hierarchical Transformer Encoder 分层Transformer编码器
我们设计了一系列的Mix Transformer编码器(MiT),从MiT-B0到MiT-B5,它们具有相同的架构但不同的尺寸。MiT-B0是我们的轻量级模型,适用于快速推理,而MiT-B5则是性能最佳的最大模型。我们对MiT的设计在某种程度上受到了ViT的启发,但经过了针对语义分割的定制和优化。
MiT编码器的设计充分考虑了语义分割任务的特点,通过使用Mix Transformer结构,我们能够更好地捕捉到图像中的语义信息。这种结构在保留了Transformer的优势的同时,还针对语义分割任务进行了改进,使得模型能够更好地理解图像中不同物体的分布和关系。
总之,Mix Transformer编码器是SegFormer的关键组件之一,通过不同尺寸的设计,我们能够在性能和推理速度之间进行权衡,为不同应用场景提供了更多的选择。
Mix Transformer编码器的核心思想是将输入图像分成不同的局部区域,然后在每个区域内应用Transformer的机制来提取局部特征。这些局部特征随后会通过跨区域的注意力机制进行整合,从而捕捉图像中的全局语义信息。这种设计使得编码器能够更好地捕捉不同尺度和不同位置的特征,有助于提高语义分割的准确性和鲁棒性。
Hierarchical Feature Representation模块的目标是在给定输入图像的情况下,生成类似卷积神经网络的多级特征。这些特征提供高分辨率的粗特征和低分辨率的细粒度特征,通常能够提升语义分割的性能。具体而言,对于一个分辨率为H × W × 3的输入图像,我们进行补丁合并以获得一个分辨率为H 2i+1 × W 2i+1 × Ci的层次特征图Fi,其中i ∈ {1, 2, 3, 4},而Ci+1大于Ci。
在这个过程中,输入图像被分割成不同的分辨率的补丁,然后通过合并这些补丁来生成层次特征图。这种层次结构的设计使得模型能够捕捉不同尺度的特征,从而在语义分割任务中更好地理解图像的语义信息。这些层次特征图可以提供更全面的视觉信息,有助于改善分割的准确性和鲁棒性。
重叠补丁合并。在给定图像补丁的情况下,ViT中使用的补丁合并过程将一个N × N × 3的补丁统一为一个1 × 1 × C的向量。我们可以将这个过程扩展为将一个2 × 2 × Ci的特征补丁统一为一个1 × 1 × Ci+1的向量,从而获得层次特征图。利用这一过程,我们可以从F1(H 4 × W 4 × C1)缩小到F2(H 8 × W 8 × C2),然后迭代到层次结构中的其他特征图。这个过程最初是设计用来合并非重叠的图像或特征补丁的。因此,它无法保留这些补丁周围的局部连续性。相反,我们使用了重叠的补丁合并过程。为此,我们定义了K、S和P,其中K是补丁大小,S是相邻两个补丁之间的步长,P是填充大小。在我们的实验中,我们设置K = 7,S = 4,P = 3和K = 3,S = 2,P = 1,以执行重叠补丁合并,从而生成与非重叠过程相同大小的特征。
ViT的Patch Embedding是无重叠的(non-overlapping),但是non-overlapping对语义分割任务来说,会导致patch边缘不连续。MiT使用overlapped patch embedding,保证patch边缘连续。
Efficient Self-Attention Transformer的主要计算瓶颈在Attention层,设Q/K/V的维度为[N, C](N=H*W),注意力计算公式如下:

它的计算复杂度是O(),当对大分辨率的图片,计算量过大,segformer引入一个衰减比率R,利用全连接层减少Attention计算量。K的维度为[N, C],先将其reshape为[N/R, C*R],通过全连接层将维度变为[N/R, C],那么计算复杂度变为O(
/R),从stage1到stage4,R分别设置为[64, 16, 4, 1]。
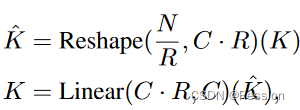
Mix-FFN。ViT使用位置编码(PE)引入位置信息。然而,PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,需要插值位置代码,这通常会导致准确性下降。为了缓解这个问题,CPVT [54] 使用3 × 3卷积与PE一起实现了数据驱动的PE。我们认为,在语义分割中实际上不需要位置编码。相反,我们引入了Mix-FFN,它通过直接在前馈网络(FFN)中使用3 × 3卷积来考虑零填充对泄漏位置信息的影响[69]。Mix-FFN可以表示为:
![]()
其中,xin是来自自注意模块的特征。Mix-FFN将一个3 × 3卷积和一个MLP混合到每个FFN中。在我们的实验中,我们将展示一个3 × 3卷积足以为Transformer提供位置信息。特别地,我们使用深度可分离卷积来减少参数数量并提高效率。
3.2 Lightweight All-MLP Decoder 轻量级全连接多层感知机
SegFormer采用了一个轻量级的解码器,仅由MLP层组成,从而避免了其他方法中常用的手工设计和计算密集的组件。能够实现如此简单的解码器的关键在于,我们的层次化Transformer编码器具有比传统CNN编码器更大的有效感受野(ERF)。
在SegFormer中,我们通过层次化的Transformer编码器生成具有不同分辨率的特征。这些特征被输入到轻量级的All-MLP解码器中,其中的MLP层用于将不同分辨率的特征进行融合。由于编码器的ERF更大,解码器能够捕捉到更广泛的上下文信息,从而无需使用复杂的组件即可生成强大的表示。
这种设计使得SegFormer在保持高性能的同时,避免了复杂的操作和高计算成本,从而使得模型更加高效。
所提出的All-MLP解码器包括四个主要步骤。首先,来自MiT编码器的多级特征Fi经过一个MLP层,以统一通道维度。然后,在第二步中,特征被上采样至1/4大小,并连接在一起。第三步,采用MLP层将连接的特征F进行融合。最后,另一个MLP层将融合后的特征用于预测具有分辨率的分割掩模M,其中Ncls是类别数量。这使得我们可以将解码器形式化为:
其中,表示上采样操作,Concatenate 表示连接操作,
和
分别是用于融合和预测的MLP层,
到
是来自不同分辨率的特征。这种解码器设计简单而高效,能够有效地融合不同分辨率的特征,生成最终的分割掩模。
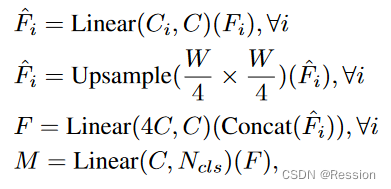
其中, 表示预测的掩模,
表示具有输入维度
和输出维度
的线性层。这个线性层将输入的特征进行线性变换,产生与输出维度相匹配的预测结果。在SegFormer的解码器中,这些线性层用于特征融合和最终分割掩模的预测。
有效感受野分析。在语义分割中,保持大的感受野以包含上下文信息一直是一个核心问题[5, 19, 20]。在这里,我们使用有效感受野(Effective Receptive Field,ERF)[70]作为工具来可视化和解释为什么我们的MLP解码器设计对于Transformers如此有效。在图3中,我们可视化了DeepLabv3+和SegFormer的四个编码器阶段和解码器头部的ERF。我们可以得出以下观察结论:
- DeepLabv3+的ERF相对较小,即使在最深的第4阶段(Stage-4)。
- SegFormer的编码器自然产生类似于较低阶段卷积的局部注意力,同时能够在第4阶段输出高度非局部的注意力,有效捕获上下文信息。
- 如图3中的放大区域所示,MLP头部(蓝色框)的ERF与第4阶段(红色框)不同,除了非局部注意力外,还具有更强的局部注意力。CNN中有限的感受野需要使用诸如ASPP [18]之类的上下文模块来扩大感受野,但不可避免地会变得复杂。我们的解码器设计受益于Transformers中的非局部注意力,可以在不增加复杂性的情况下获得更大的感受野。然而,同样的解码器设计在CNN骨干网络上效果不好,因为总体感受野的上限由第4阶段的有限感受野决定,我们将在表1d中进行验证。更重要的是,我们的解码器设计基本上利用了Transformer产生的特征,同时产生高度局部和非局部的注意力。通过将它们统一起来,我们的MLP解码器通过添加少量参数产生互补和强大的表示。这是我们设计的另一个关键原因。仅仅使用第4阶段的非局部注意力是不足以产生好的结果的,这将在表1d中进行验证。

3.3 与SETR的关系。
SegFormer相对于SETR [7]包含了更多高效和强大的设计:
- 我们只使用ImageNet-1K进行预训练。SETR中的ViT是在更大的ImageNet-22K上进行预训练的。
- SegFormer的编码器具有分层架构,比ViT更小,可以捕获高分辨率的粗特征和低分辨率的细粒度特征。相比之下,SETR的ViT编码器只能生成单一的低分辨率特征图。
- 我们在编码器中去除了位置嵌入,而SETR使用了固定形状的位置嵌入,这会在推断时的分辨率与训练时不同时降低准确性。
- 我们的MLP解码器比SETR中的解码器更紧凑,计算成本更低。这导致几乎没有计算开销。相比之下,SETR需要使用多个3×3卷积的复杂解码器。
这篇关于[论文] SegFormer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


