本文主要是介绍啊丢的刷题记录手册(洛谷提单排序篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.洛谷题P1923 求第k小的数
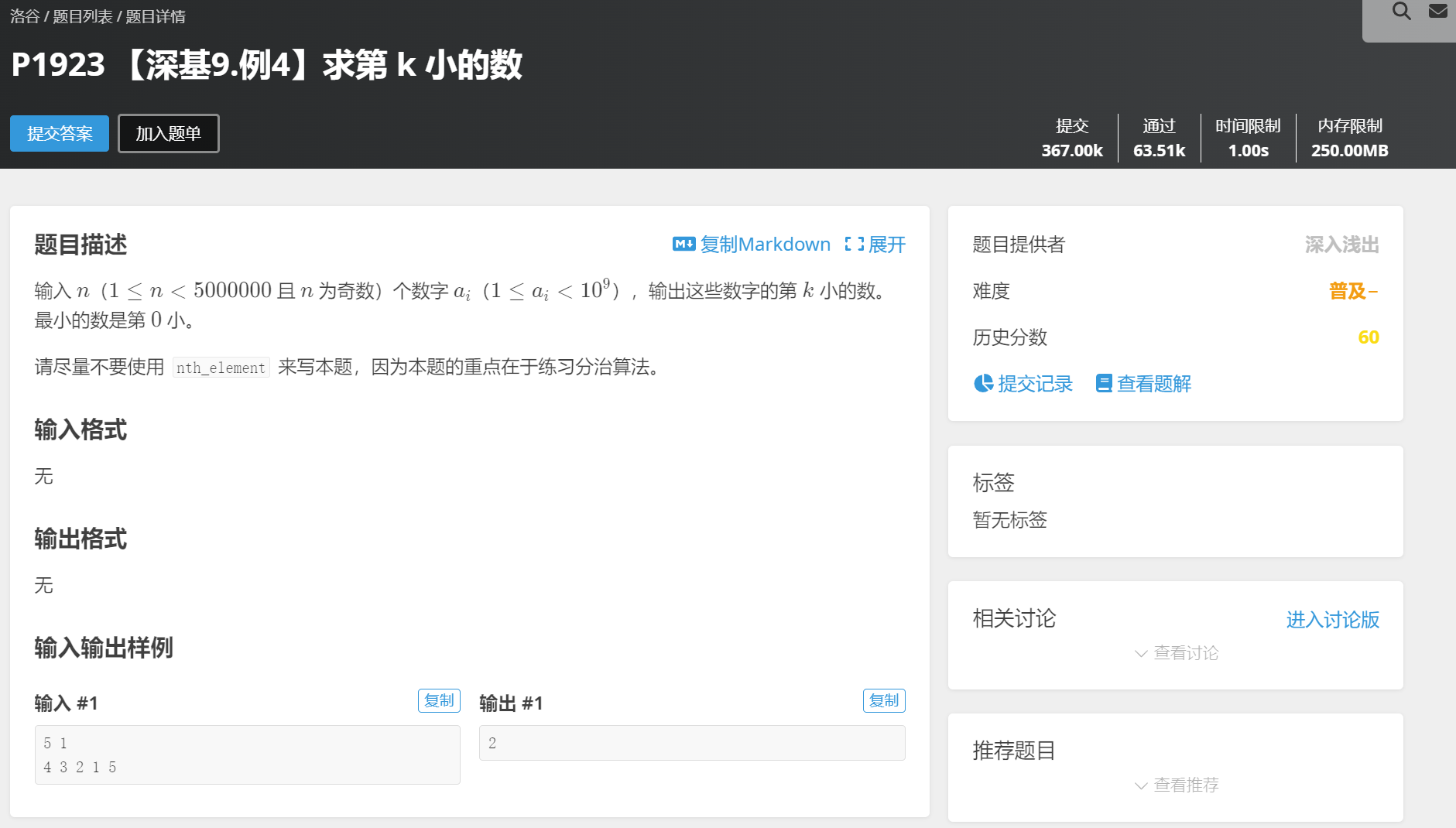
题目描述
输入 n(1≤n<5000000 且 n 为奇数)个数字ai(1≤ai<109),输出这些数字的第 k 小的数。最小的数是第 0 小。
请尽量不要使用 nth_element 来写本题,因为本题的重点在于练习分治算法。
输入格式
无
输出格式
无
输入输出样例
输入 :
5 1
4 3 2 1 5输出 :
2题目解析:
这道题一开始以为是很简单的sort直接乱杀,没想到写出来… 就对了60%的样例
第一版代码如下:
#include<bits/stdc++.h>
using namespace std;
const long long N=5e7+1;
int q[N];
int main(){int n,k;cin>>n>>k;for(int i=0;i<n;i++){cin>>q[i];}sort(q,q+n);cout<<q[k]<<" ";return 0;
} 测试样例结果如下:
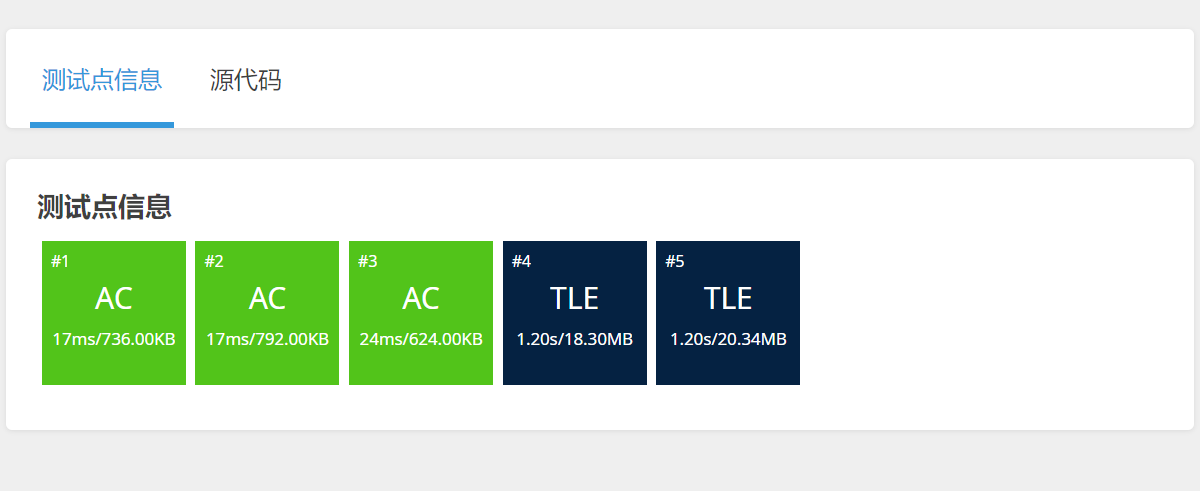
发现有些样例仍然不能通过显示超时了,因此我们在算法上对它进行优化一下,改变了一下这个排序算法和搜索第k个数的算法
第二版代码如下:(这次可以AC啦!!!)
#include<bits/stdc++.h>
using namespace std;
int x[5000005],k;
void qsort(int l,int r)
{int i=l,j=r,mid=x[(l+r)/2];do{while(x[j]>mid)j--;while(x[i]<mid)i++;if(i<=j){swap(x[i],x[j]);i++;j--;}}while(i<=j);//快排后数组被划分为三块: l<=j<=i<=rif(k<=j) qsort(l,j);//在左区间只需要搜左区间else if(i<=k) qsort(i,r);//在右区间只需要搜右区间else //如果在中间区间直接输出{printf("%d",x[j+1]);exit(0);}
}
int main()
{int n;scanf("%d%d",&n,&k);for(int i=0;i<n;i++)scanf("%d",&x[i]);qsort(0,n-1);
}测试样例结果如下:
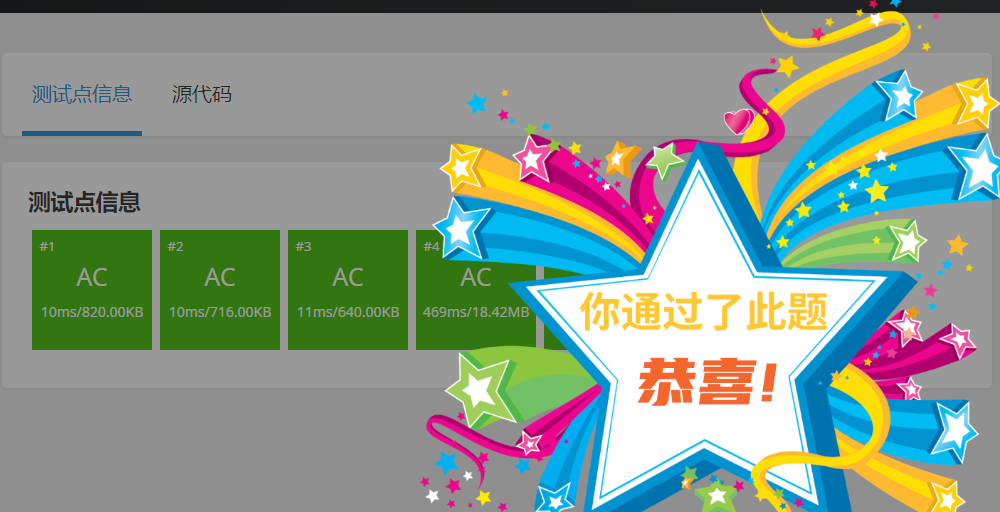
这次可以通过啦!
但是我发现题目中提到了一个
nth_element没见过,于是我又去了解了一下nth_element的用法和写法,所以有了第三版代码😘
第三版代码:(O(n))
在 STL 里有一个神奇的函数 nth_element。
它的用法是 nth_element(a+x,a+x+y,a+x+len)。
执行之后数组 a 下标 x 到x+y-1 的元素都小于 a[x+y],下标 x+y+1 到 x+len−1 的元素 都大于 a[x+y],但不保证数组有序。此时 a[x+y] 就是数组区间 x 到 x+len−1 中第 y 小的数,当然也可以自己定义 cmp 函数。
nth_element 的时间复杂度是O(n) 的,不过 STL 常数普遍较大……但还是能过此题。
#include<bits/stdc++.h>
using namespace std;
int x[5000005],k;
int main()
{int n;scanf("%d%d",&n,&k);for(int i=0;i<n;i++)scanf("%d",&x[i]);nth_element(x,x+k,x+n);//简短又高效printf("%d",x[k]);
}2. 明明的随机数

题目描述
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了 N 个 1到 1000 之间的随机整数 (N≤100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作。
输入格式
输入有两行,第 1 行为 1 个正整数,表示所生成的随机数的个数 N。
第 2 行有 N 个用空格隔开的正整数,为所产生的随机数。
输出格式
输出也是两行,第 1 行为 1 个正整数 M,表示不相同的随机数的个数。
第 22 行为 M 个用空格隔开的正整数,为从小到大排好序的不相同的随机数。
输入输出样例
输入
10
20 40 32 67 40 20 89 300 400 15输出
8
15 20 32 40 67 89 300 400这道题我们读题发现需要对数组进行去重然后排序,鉴于每个数字在1000以内,所以我想到用桶排序的思想来解决这道题,最后的测试结果也是可以AC的
代码参考:
#include<bits/stdc++.h>
using namespace std;
int q[1001];
int main(){int n;cin>>n;while(n--){int m;cin>>m;q[m]++;//将对应的数字放进对应的桶内 }int sum=0; //统计去重后的数字 for(int i=0;i<1000;i++){if(q[i]!=0){sum++;}}cout<<sum<<endl;for(int i=0;i<1000;i++){if(q[i]!=0){cout<<i<<" ";}}return 0;
} 
这篇关于啊丢的刷题记录手册(洛谷提单排序篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








