本文主要是介绍秒杀超卖问题的解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.现象
(说明:来自《系统设计》一书)
在极短的时间内,有大量的购买请求,只有极少数能够购买成功,如何保证不超卖,是有很多技术难点的
瞬时高并发
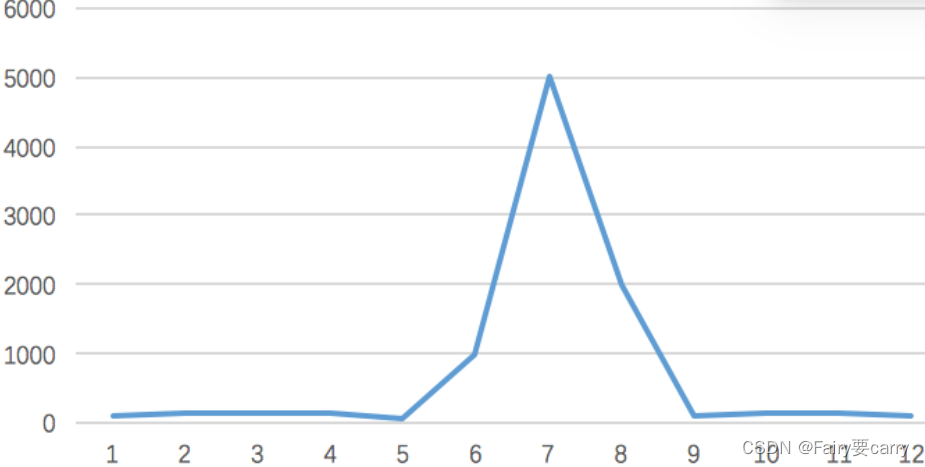
一般在秒杀时间点(比如:12点)前几分钟,用户并发量才真正突增,达到秒杀时间点时,并发量会达到顶峰。
但由于这类活动是大量用户抢少量商品的场景,必定会出现狼多肉少的情况,所以其实绝大部分用户秒杀会失败,只有极少部分用户能够成功。
正常情况下,大部分用户会收到商品已经抢完的提醒,收到该提醒后,他们大概率不会在那个活动页面停留了,如此一来,用户并发量又会急剧下降。所以这个峰值持续的时间其实是非常短的,这样就会出现瞬时高并发的情况,下面用一张图直观的感受一下流量的变化:
2.页面静态化
活动页面是用户流量的第一入口,所以是并发量最大的地方。
如果这些流量都能直接访问服务端,恐怕服务端会因为承受不住这么大的压力,而直接挂掉。
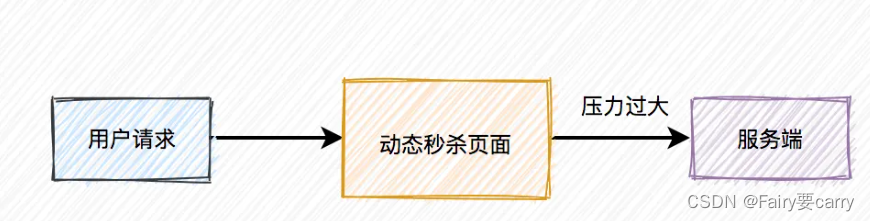
活动页面绝大多数内容是固定的,比如:商品名称、商品描述、图片等。为了减少不必要的服务端请求,通常情况下,会对活动页面做静态化处理。用户浏览商品等常规操作,并不会请求到服务端。只有到了秒杀时间点,并且用户主动点了秒杀按钮才允许访问服务端。
这样能过滤大部分无效请求。
但只做页面静态化还不够,因为用户分布在全国各地,有些人在北京,有些人在成都,有些人在深圳,地域相差很远,网速各不相同。
如何才能让用户最快访问到活动页面呢?
这就需要使用CDN,它的全称是Content Delivery Network,即内容分发网络;
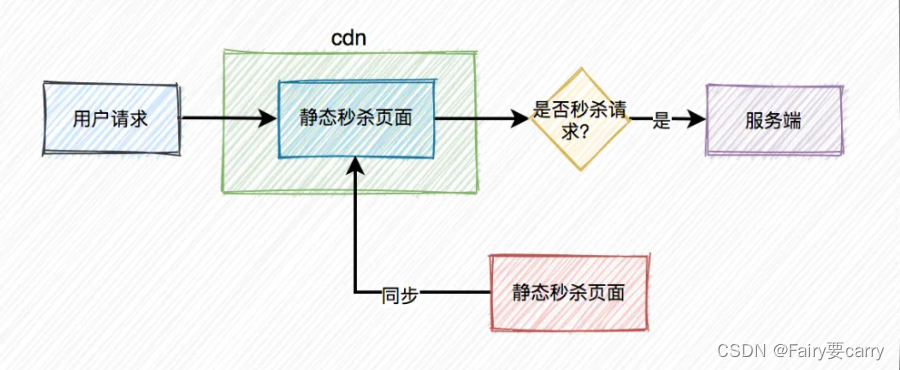
用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率
Js控制秒杀按钮
大部分用户怕错过秒杀时间点,一般会提前进入活动页面。
此时看到的秒杀按钮是置灰,不可点击的。只有到了秒杀时间点那一时刻,秒杀按钮才会自动点亮,变成可点击的。
但此时很多用户已经迫不及待了,通过不停刷新页面(CDN),争取在第一时间看到秒杀按钮的点亮。
从前面得知,该活动页面是静态的。那么我们在静态页面中如何控制秒杀按钮,只在秒杀时间点时才点亮呢?
使用js文件控制:
为了性能考虑,一般会将css、js和图片等静态资源文件提前缓存到CDN上,让用户能够就近访问秒杀页面。看到这里,有些聪明的小伙伴,可能会问:CDN上的js文件是如何更新的?——>秒杀开始之前,js标志为false,还有另外一个随机参数。
当秒杀开始的时候系统会生成一个新的js文件,此时标志为true,并且随机参数生成一个新值,然后同步给CDN。由于有了这个随机参数,CDN不会缓存数据,每次都能从CDN中获取最新的js代码。
本质:
使我们定义了一个全局变量version来表示当前的版本号,在加载JS文件时会将版本号作为参数添加到URL中。当需要更新文件时,调用updateScript函数,该函数会修改版本号并重新加载JS文件,从而触发客户端重新下载最新的文件。
通过这种方式,每次更新JS文件时只需修改版本号参数的值,就能确保客户端获取到最新的文件,实现了自动刷新的效果。需要注意的是,具体使用时还需要根据CDN提供的API接口和具体情况进行适配和调整。
// seckill.js// 定义一个全局变量,用于标识当前的版本号
var version = 'v1';// 获取当前版本号的函数,调用CDN提供的API接口
function getCurrentVersion() {// 假设CDN提供了一个名为getVersion的API接口,用于获取当前版本号// 这里使用setTimeout模拟异步请求setTimeout(function() {// 模拟从CDN API接口获取版本号var currentVersion = 'v1'; // 假设当前版本号为v1version = currentVersion;}, 1000);
}// 更新版本号的函数,调用CDN提供的API接口
function updateVersion(newVersion) {// 假设CDN提供了一个名为updateVersion的API接口,用于更新版本号// 这里使用setTimeout模拟异步请求setTimeout(function() {// 模拟向CDN API接口上传新的版本号version = newVersion; // 更新版本号为新的值// 调用加载JS文件的函数,重新加载更新后的JS文件loadScript();}, 1000);
}// 加载JS文件的函数
function loadScript() {// 构建JS文件的URL,包含版本号参数var scriptUrl = 'https://cdn.example.com/seckill.js?version=' + version;// 创建script元素并设置src属性为带有版本号参数的URLvar scriptElement = document.createElement('script');scriptElement.src = scriptUrl;// 将script元素添加到页面中document.head.appendChild(scriptElement);
}// 初始化时获取当前版本号
getCurrentVersion();// 模拟更新JS文件并触发重新加载
function updateScript(newVersion) {// 调用更新版本号的函数,将新的版本号上传到CDNupdateVersion(newVersion);
}// 初始加载JS文件
loadScript();定时器
此外,前端还可以加一个定时器,控制比如:10秒之内,只允许发起一次请求。如果用户点击了一次秒杀按钮,则在10秒之内置**灰,**不允许再次点击,等到过了时间限制,又允许重新点击该按钮。——>大大减少了QPS
3.读多写少
超卖问题的本质就是读多写少的问题,故我们可以加一层缓存,去减少数据库连接资源的消耗(毕竟大多数请求只是读操作)
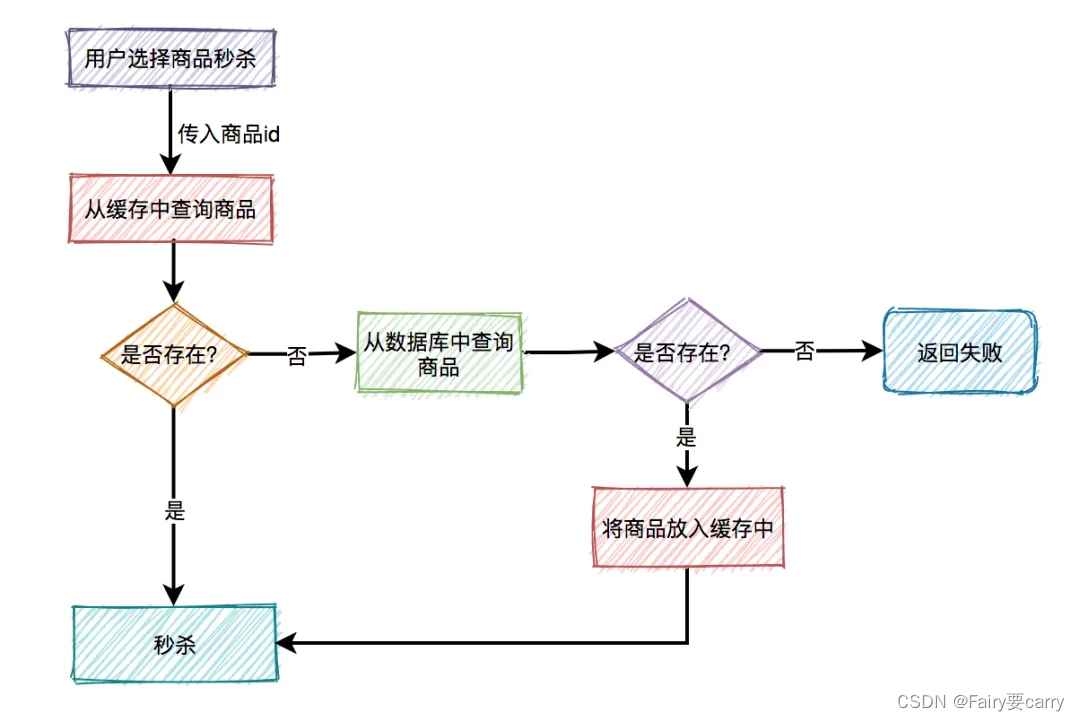
缓存中出现缓存击穿的问题的解决
比如商品A第一次秒杀时,缓存中是没有数据的,但数据库中有。虽说上面有如果从数据库中查到数据,则放入缓存的逻辑。然而,在高并发下,同一时刻会有大量的请求,都在秒杀同一件商品,这些请求同时去查缓存中没有数据,然后又同时访问数据库。结果悲剧了,数据库可能扛不住压力,直接挂掉。如何解决这个问题呢?
1.第一点缓存空值(避免大量请求落到数据库上)
2.第二点对商品数据进行预热
3.第三点用布隆过滤器
4.第四点,另外我们可以加分布式锁,减少请求量,避免大量请求一下落在数据库上
https://blog.csdn.net/weixin_57128596/article/details/123453702?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170869918216800226588478%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170869918216800226588478&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-123453702-null-null.nonecase&utm_term=%E7%BC%93%E5%AD%98%E5%87%BB%E7%A9%BF&spm=1018.2226.3001.4450
布隆过滤器
**1.前景:**像这种秒杀场景下,商品的更新频率肯定不高(商品id),所以我们可以使用布隆过滤器
2.过程:根据商品id,先从布隆过滤器中查询该id是否存在,如果存在则允许从缓存中查询数据,如果不存在,则直接返回失败。
3.缓存一致性的问题:
如果缓存中数据有更新,则要及时同步到布隆过滤器中。如果数据同步失败了,还需要增加重试机制,而且跨数据源,能保证数据的实时一致性吗
import java.util.concurrent.TimeUnit;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;public class CacheAndBloomFilterSync {private static final int RETRY_LIMIT = 3;private static final long RETRY_INTERVAL = 1000; // 1秒private static BloomFilter<String> bloomFilter;public static void main(String[] args) {// 初始化布隆过滤器bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 1000, 0.01);// 模拟缓存数据更新String key = "example_key";String newData = "example_data";updateCacheAndFilter(key, newData);}// 模拟从缓存中获取数据的方法private static String getFromCache(String key) {// 假设这是从缓存中获取数据的逻辑return null;}// 模拟将数据同步到缓存的方法private static void syncToCache(String key, String data) {// 假设这是将数据同步到缓存的逻辑}// 模拟将数据同步到布隆过滤器的方法private static void syncToBloomFilter(String data) {// 假设这是将数据同步到布隆过滤器的逻辑bloomFilter.put(data);}// 更新缓存数据并同步到布隆过滤器的方法,包括重试机制private static void updateCacheAndFilter(String key, String newData) {int retryCount = 0;boolean success = false;while (retryCount < RETRY_LIMIT && !success) {try {// 从缓存中获取数据String currentData = getFromCache(key);// 更新缓存中的数据String updatedData = currentData + " " + newData;syncToCache(key, updatedData);// 将更新后的数据同步到布隆过滤器syncToBloomFilter(updatedData);success = true; // 数据同步成功} catch (Exception e) {System.err.println("Data sync failed: " + e.getMessage());retryCount++;// 添加重试机制,等待一段时间后重试try {TimeUnit.MILLISECONDS.sleep(RETRY_INTERVAL);} catch (InterruptedException ex) {ex.printStackTrace();}}}if (!success) {System.err.println("Data sync to cache and Bloom filter failed after " + RETRY_LIMIT + " retries");}}
}**优点:**二进制组成的数组首先占空间较少(不是0就是1),并且查询速度较快(下标)
缺点:
1.元素可以添加到集合中,但不能被删除。
2.匹配结果只能是**“绝对不在集合中”**,并不能保证匹配成功的值已经在集合中。
3.当集合快满时,即接近预估最大容量时,误报的概率会变大。
4.数据占用空间放大。一般来说,对于1%的误报概率,每个元素少于10比特,与集合中的元素的大小或数量无关。查询过程变慢,hash函数增多,导致每次匹配过程,需要查找多个位(hash个数)来确认是否存在
https://blog.csdn.net/weixin_57128596/article/details/126734577?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170870431716800213025863%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170870431716800213025863&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-2-126734577-null-null.nonecase&utm_term=%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8&spm=1018.2226.3001.4450
4.库存问题
真正的秒杀商品的场景,不是说扣完库存,就完事了,如果用户在一段时间内,还没完成支付,扣减的库存是要加回去的。
所以,在这里引出了一个预扣库存的概念,预扣库存的主要流程如下:
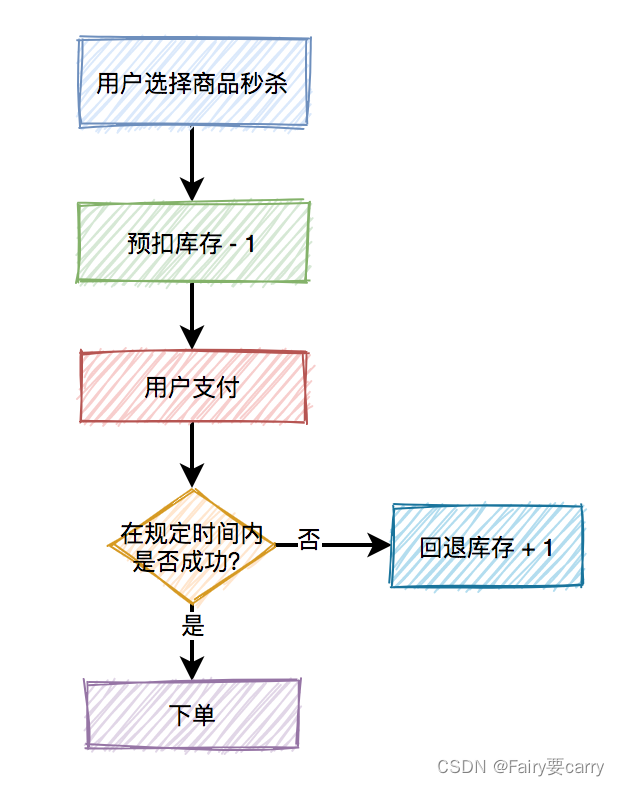
数据库扣减库存优雅方案:
1.一般是查询存储数量,然后判断库存是否足够,然后更新
以上操作对数据库进行了两次操作,效率较低;
2.基于数据库的乐观锁,这样会少一次数据库查询,而且能够天然的保证数据操作的原子性:
update product set stock=stock-1 where id=product and stock > 0;
在sql最后加上:stock > 0,就能保证不会出现超卖的情况。
但需要频繁访问数据库,我们都知道数据库连接是非常昂贵的资源。在高并发的场景下,可能会造成系统雪崩。而且,容易出现多个请求,同时竞争行锁的情况,造成相互等待,从而出现死锁的问题。
redis扣减库存:
https://blog.csdn.net/Maxiao1204/article/details/111040841?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166325895216782427456749%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166325895216782427456749&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-8-111040841-null-null.142%5Ev47%5Econtrol_1,201%5Ev3%5Econtrol_1&utm_term=redis%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%B0%9A%E7%A1%85%E8%B0%B7&spm=1018.2226.3001.4187
https://zhuanlan.zhihu.com/p/374306005
或者用我们自旋锁:
在规定的时间,比如500毫秒内,自旋不断尝试加锁,如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
try {Long start = System.currentTimeMillis();while(true) {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {return true;}long time = System.currentTimeMillis() - start;if (time>=timeout) {return false;}try {Thread.sleep(50);} catch (InterruptedException e) {e.printStackTrace();}}} finally{unlock(lockKey,requestId);
}
return false;5.MQ异步处理

而这三个核心流程中,真正并发量大的是秒杀功能,下单和支付功能实际并发量很小。所以,我们在设计秒杀系统时,有必要把下单和支付功能从秒杀的主流程中拆分出来,特别是下单功能要做成mq异步处理的。而支付功能,比如支付宝支付,是业务场景本身保证的异步。
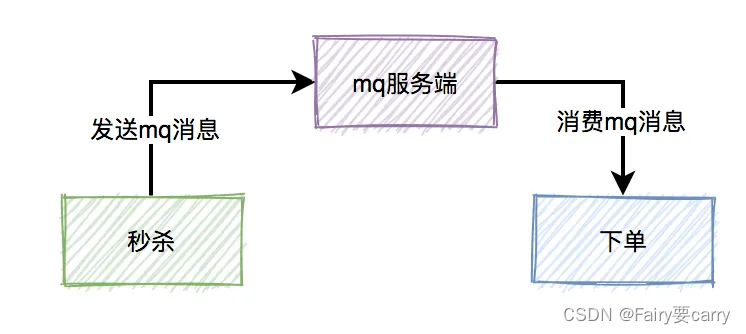
消息丢失问题
加一张消息发送表
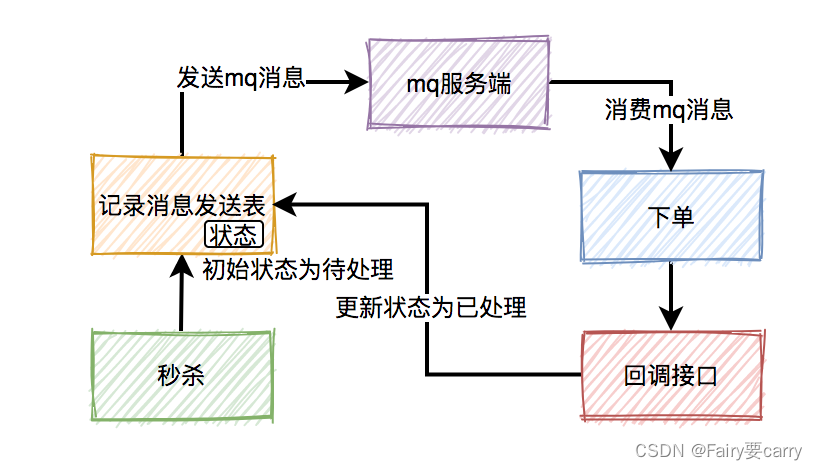
在生产者发送mq消息之前,先把该条消息写入消息发送表,初始状态是待处理,然后再发送mq消息。消费者消费消息时,处理完业务逻辑之后,再回调生产者的一个接口,修改消息状态为已处理。如果生产者把消息写入消息发送表之后,再发送mq消息到mq服务端的过程中失败了,造成了消息丢失。
-
消息队列的选型(
DirectExchange,TopicExchang,FanoutExchange) -
消息队列的几个高级特性(消息确认ACK以及回调确认方法ComfirmCallBack还有失败的ReturnCall
Back,消息持久化 setDiliveryMode) -
消息堆积的处理(死信交换机:对TTL过时消息或者retry耗尽的死信消息进行处理)
惰性队列处理消息堆积 -
延时队列处理延迟消费问题
1.问题背景:用户秒杀成功,下单之后,30分钟之内未进行支付,该订单会被自动取消,回退库存。
实现方法可以用job,但job有个问题,需要每隔一段时间处理一次,实时性不是很好我们还可以用延时队列,rocketMq自带了延时队列的功能
2.具体实现: 下单时消息生产者会生成一张订单,此时的状态为待支付,然后向延时队列中发送一条消息,当到达延时时间,消息消费者读取消息之后,会查询该订单的状态是否为待支付。如 果是待支付状态,则更新订单状态为取消状态。如果不是待支付,说明该订单已经支付过了,则直接返回;
3.注意点: 用户完成支付之后,会修改订单状态为已支付
-
消息重复消费问题
1.问题背景: 如果我们设置了ack机制,当出现网络问题时,ack应答超时,本身就有可能造成消息重复消费,而且我们还设置了job定时重新发送消息,这样使消息的重复消费的几率大大增加。
2.解决办法: 增加一张消息处理表
3.具体实现:消费者读到消息之后,先判断一下消息处理表,是否存在该消息,如果存在,表示重复消费,则直接返回。 如果不存在,则进行正常操作,接着将消息写入消息处理表中,再返回。
4.注意点: 进行正常业务逻辑操作和将消息写入消息处理表中,这个两个操作要放在一个事务当中,保证原子性。 -
消息丢失问题的处理
**1.问题背景:**上一步秒杀操作成功了,发送消息的时候出现网络问题或broker挂了等原因,导致消息发送失败,造成消息丢失
**2.解决办法:**增加一张消息发送表
**3.具体实现:**在生产者发送消息到mq之前,先把这条消息写入消息发送表,消息初始状态是待处理,后在发送mq消息,消费者消费消息时,处理完业务逻辑之后,再回调生产者这个接口,修改消息状态为已处理。
**4.遗留问题:**如果生产者已经把消息写入消息发送表了,再发送消息到mq服务端的过程失败了,造成了 消息的丢失,如何处理?
5.解决办法:使用job,增加重试机制
**6.具体实现:**用job,每隔一段时间去查询消息发送表中状态为待处理的数据,然后重新发送mq消息。
遗留问题:那这样是不是也有可能消息被重复消费?
这篇关于秒杀超卖问题的解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





