本文主要是介绍袋鼠云产品功能更新报告09期|更全面,更多样,更高效,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎阅读袋鼠云09期产品功能更新报告。在此期报告中,我们秉持创新与优化并重的理念,对产品进行了深度打磨与全面升级。每一处细节的改进,都是我们对卓越品质的不懈追求,期待这些新功能能助力您的业务运营与发展,让数字化转型之路更加畅通无阻。
以下为袋鼠云产品功能更新报告09期内容,更多探索,请继续阅读。
离线开发平台
新增功能更新
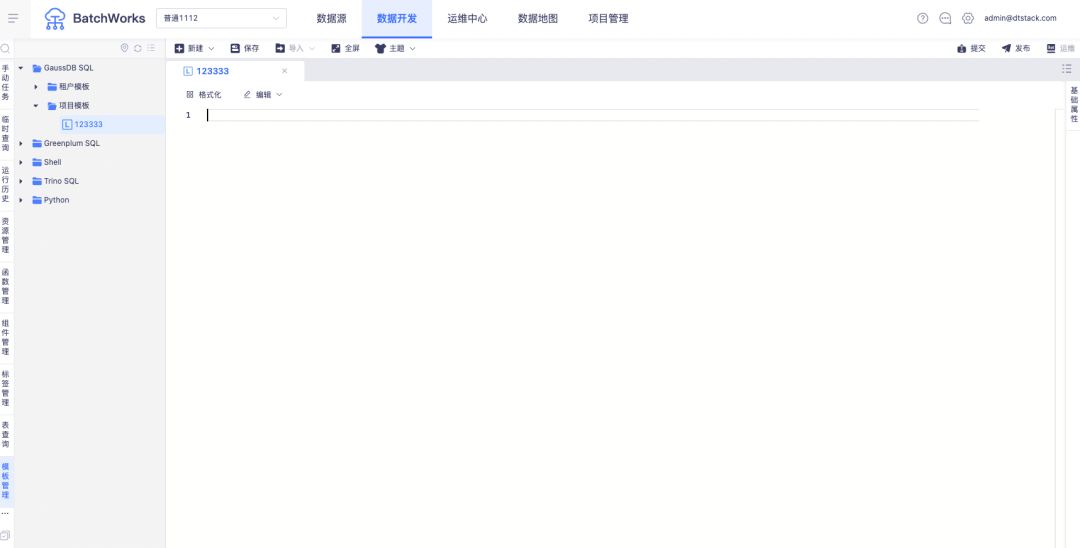
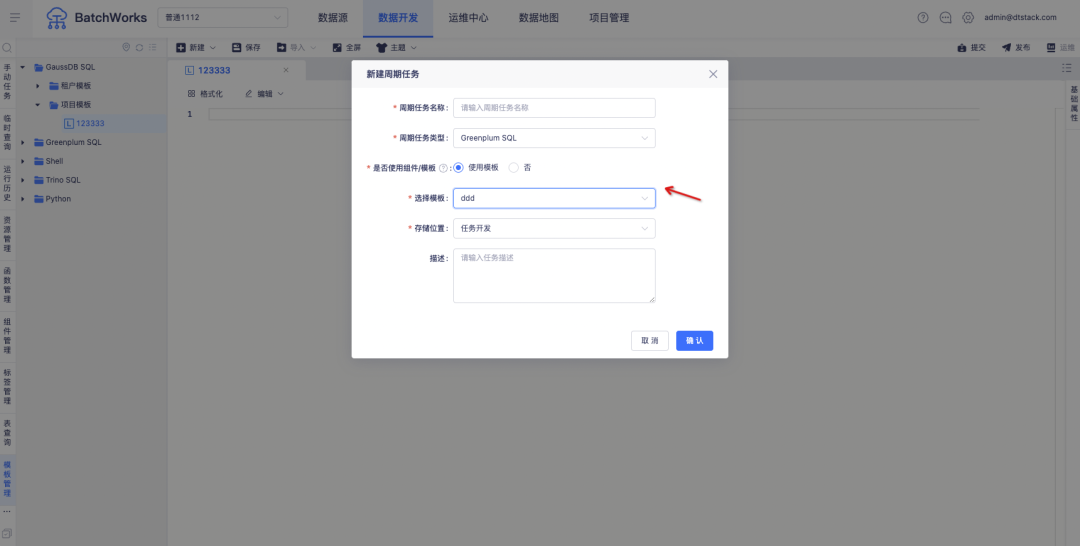
1.任务模版
背景:客户希望将日常通用的代码模板在离线中进行维护,在进行数据开发时可以直接引用。
模板与组件的差异:
1、模板代码引用后支持编辑,组件引用后不支持编辑
2、模板变更后不影响引用的任务,组件变更后会影响引用的任务
新增功能说明:支持各任务类型的项目代码模版、租户代码模版,在创建任务时支持引用代码模版。
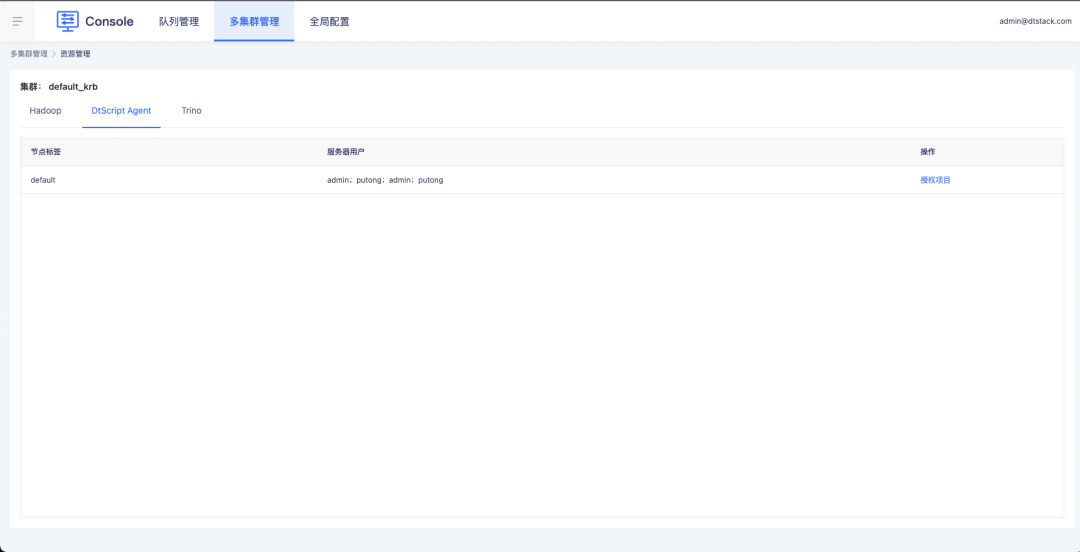
2.shell on agent/python on agent 新增项目维度管控
背景:
Shell on agent 是离线平台特殊的一种任务类型。
Shell 任务运行并不直接在集群部署的机器上,而是将 Shell 运行在独立部署的服务器节点上。因为离线一个任务需要占用两个核,如果客户场景存在较多 Shell 任务,很容易将集群资源打满。因此将 Shell、Python 等任务运行在独立部署的节点上,可以有效降低集群的压力。
目前存在一个问题,只要客户在 EM 和控制台上配置的节点和服务器用户,集群下所有项目都可以使用配置的节点和服务器用户,这样存在安全性的问题。例如 root 等高权限的用户,客户比较看重安全性问题,不希望所有项目都能去使用这个账号,因此需要设计一个能够管控配置服务器节点和服务器用户的方案,来解决这个问题。
新增功能说明:
1、控制台通过项目授权进行节点和服务器用户权限管控
2、离线项目中任务支持选到被授权对服务器节点和用户
功能优化
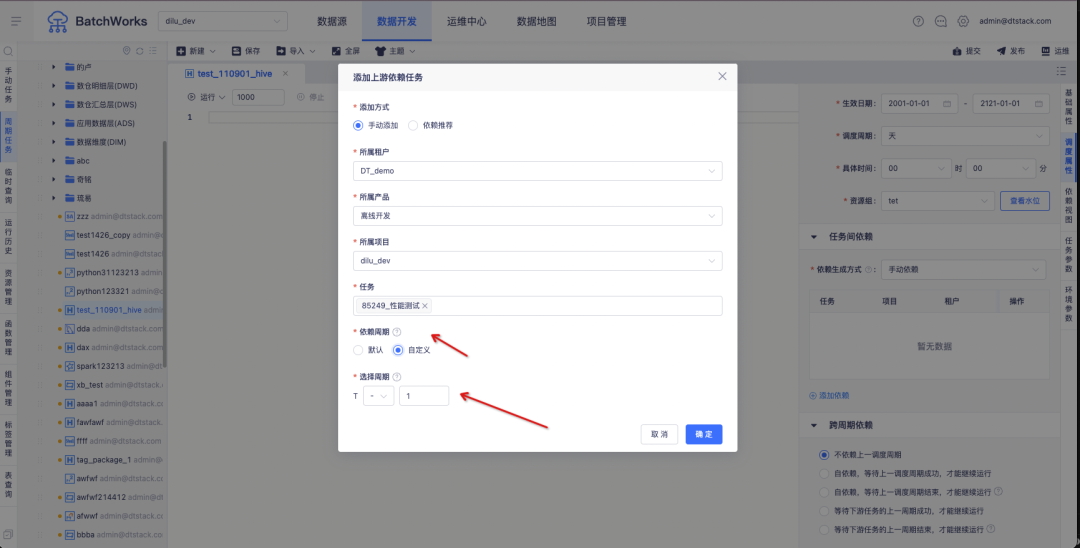
1.调度配置优化,可以调控依赖上游任务的任一周期实例
背景:
目前调度中天任务默认只能依赖当前周期的上游实例,客户可能存在以下场景:
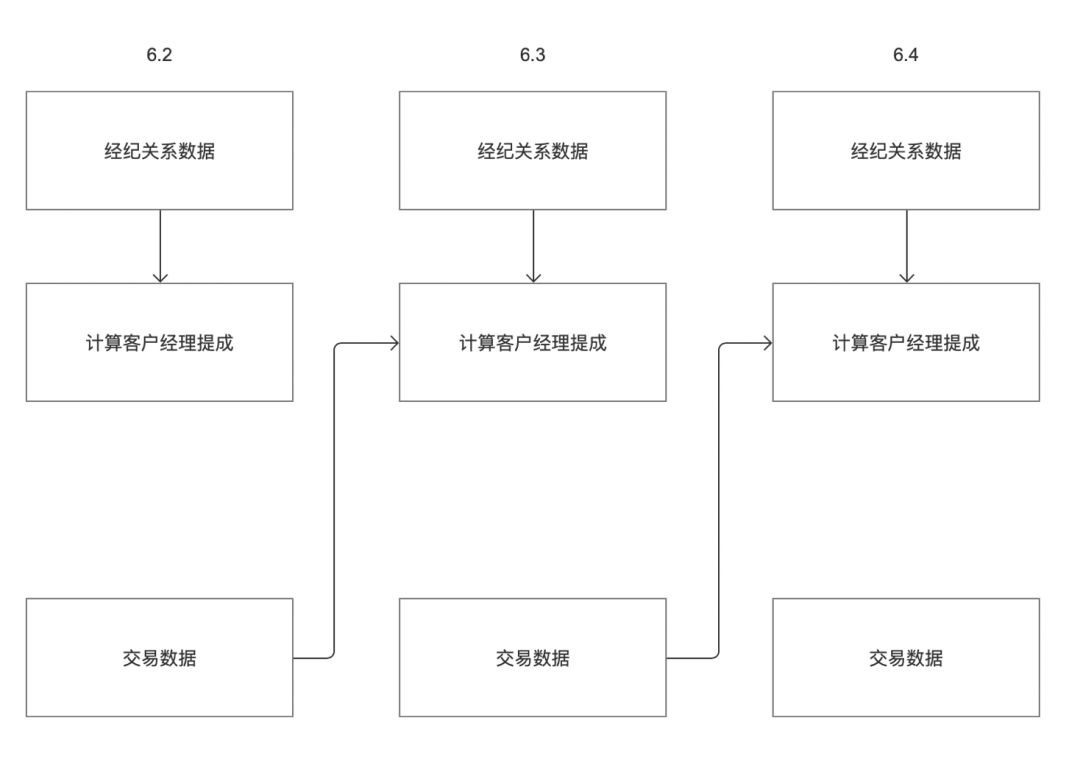
例如客户存在两个业务系统「经纪关系数据」和「交易数据」,客户6月3日的提成需要分别依赖于「经纪关系数据」和「交易数据」计算得出。如上图所示,6月2日的「经纪关系数据」业务系统数据产出时间是6月3日;6月2日的「交易数据」业务系统数据产出时间是6月2日晚。
按照目前离线的上下游依赖逻辑,「计算客户经理提成」任务只能取到6月3日的任务,无法获取到6月2日的任务,因此需要进行改造,支持任务实例依赖设置可以选择自定义周期。
体验优化说明:
支持自定义依赖上游任务的调度周期。
T代表当前任务(下游任务)的计划时间,“+ -”代表偏移方向,“+”代表时间向未来偏移,“-”代表时间向过去偏移,默认选择“-”。
偏移量为数字输入框,最大值10,最小值1,代表偏移上游任务周期数。
实时开发平台
新增功能更新
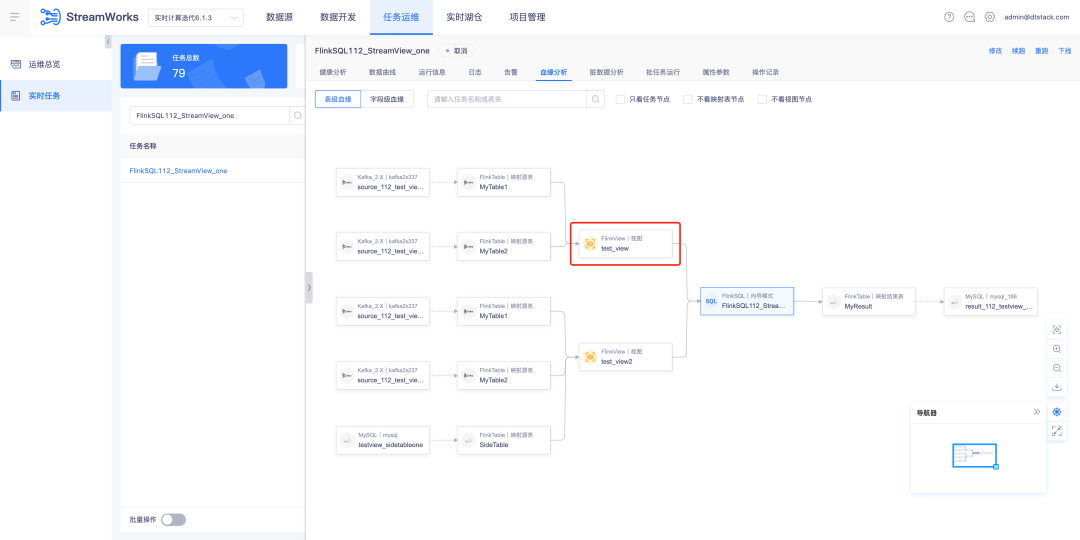
1.视图血缘解析
背景: 目前 SQLParser 不支持 FlinkSQL 的视图血缘解析,但在一般开发场景下,任务如果涉及三张以上表,很多数开会选择 IDE 里建视图,方便阅读 SQL 逻辑。
功能:
1、SQLParser 支持 FlinkSQL 视图表展示血缘解析
2、任务运维-实时任务-FlinkSQL 任务详情-血缘解析展示功能
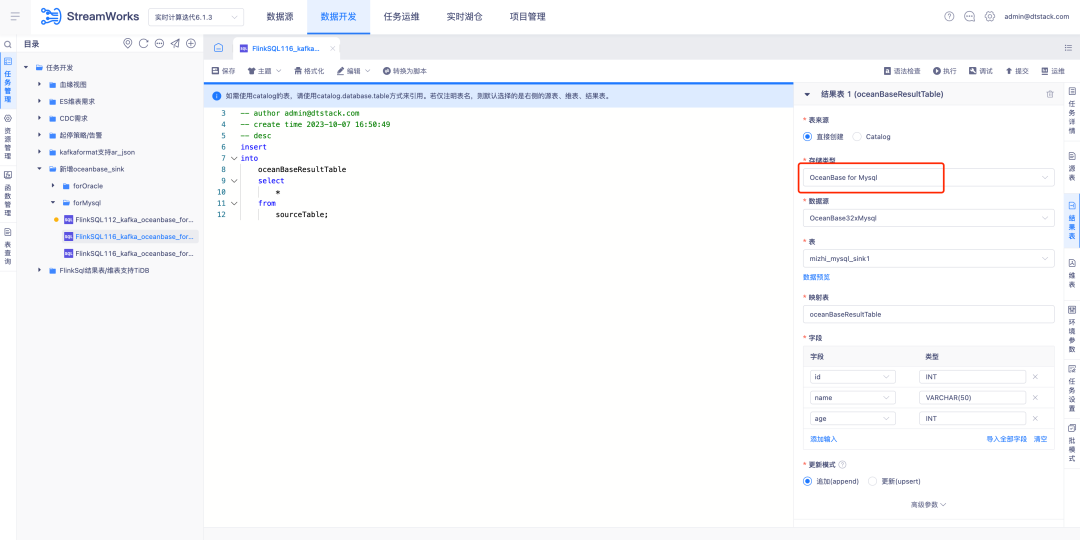
2.FlinkSQL 支持 Oceanbase Sink
FlinkSQL1.16版本对 OceanBase 结果表的支持,同时兼容 OceanBase 4.2.0 版本的 MySQL 和 Oracle 两种模式,为用户提供了更加灵活和高效的数据处理能力。
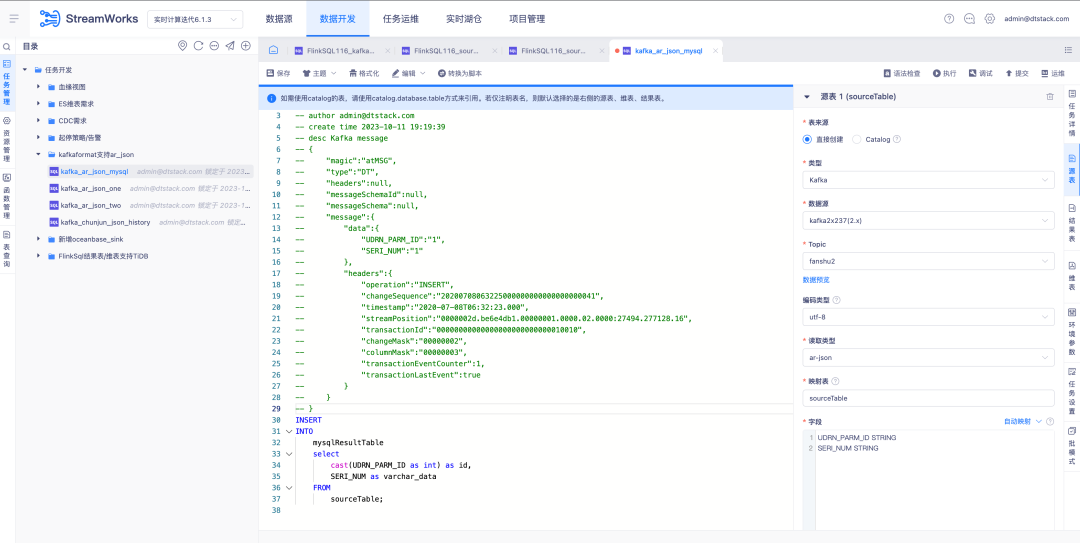
3.源表 Kafka 读取类型支持 AR Json
背景:在国外,OGG 和 Attunity Replicate 是两个广泛使用的商业产品,为了更好地满足客户需求,我们需要确保 Kafka 的 JSON 格式兼容 AR Json 的读取类型。
新增功能说明:FlinkSQL1.16 版本源表 Kafka 读取类型支持 AR Json 类型并且支持自动映射相关功能解析 Json。
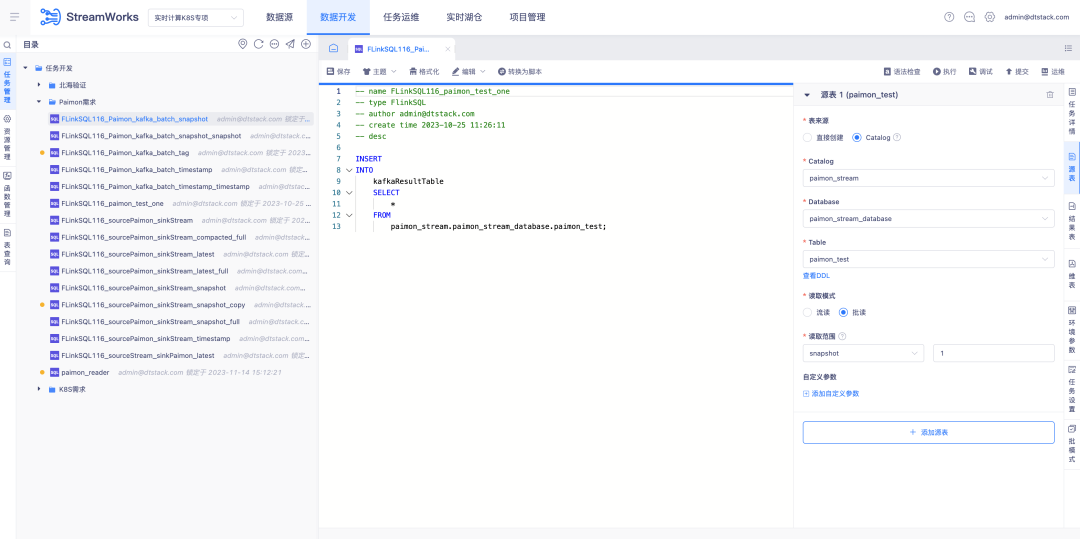
4.实时湖仓 Paimon 支持
背景:借助 Paimon 的开发,本次需要迭代一种新的 FlinkSQL 开发模式,使用该模式,可以全链路串起湖仓管理模块。
新增功能说明:
1、湖仓管理新增 Paimon 表增删改查能力
2、数据开发平台端增加 Paimon 表的可视化配置功能
3、数据开发平台端通过 IDE 方式完成 Paimon 表的读写功能
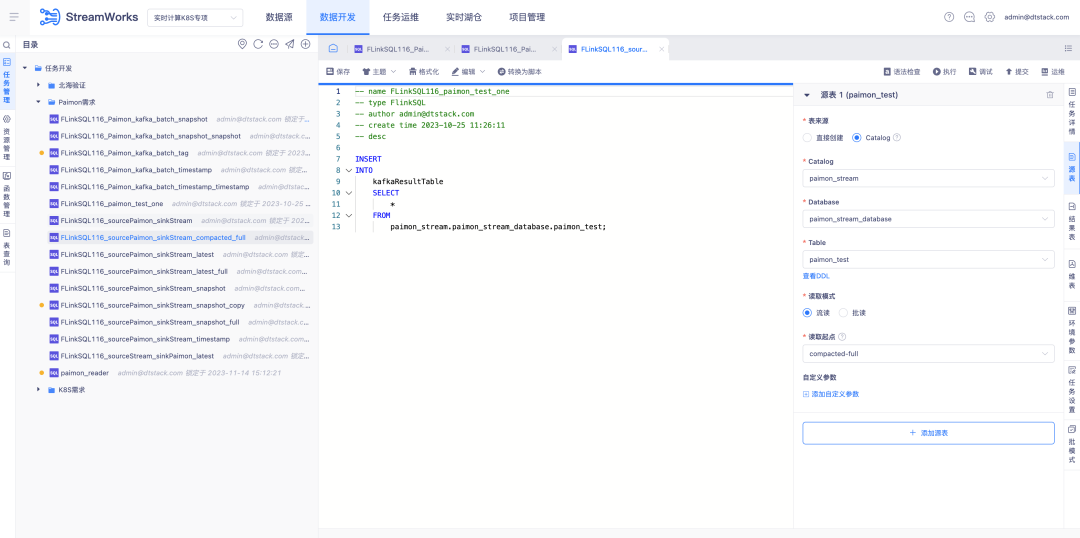
5.FlinkSQL 内置 FlinkCDC
背景:FlinkCDC 是一款开源的实时采集组件,其迭代速度非常快,底层依赖的 Flink 框架也与我们使用的 ChunJun 框架相同。因此,我们考虑将其作为实时平台部署的默认组件,并将其打包进我们的系统中。
新增功能说明:
1、实时默认部署包,带上 FlinkCDC 实时采集组建
2、平台脚本模式,需要验证下 FlinkCDC 自带的采集能力和已经支持的 Connector
3、平台向导模式,会根据项目情况,将 FlinkCDC 支持的 Connector 采集配置化掉
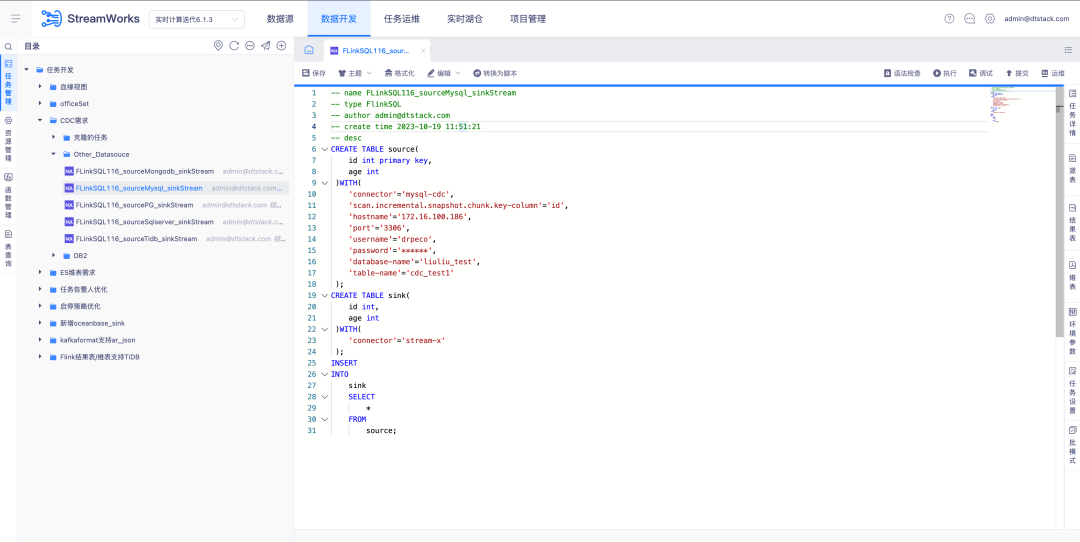
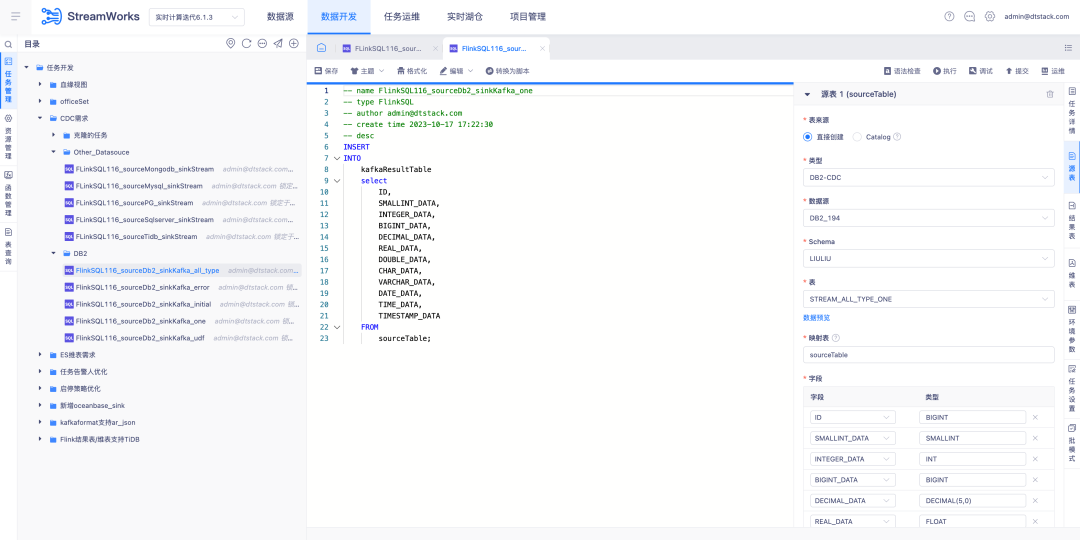
6.FlinkSQL 支持 FlinkCDC DB2 数据源
背景:客户需要支持 DB2 的实时采集,考虑到 CDC Connector 开发难度又较大,FinkCDC 刚好支持,所以底层借用 FlinkCDC 的能力。
新增功能说明:实时平台端支持向导模式配置源表为 DB2-CDC 数据源。
功能优化
1.续跑逻辑优化
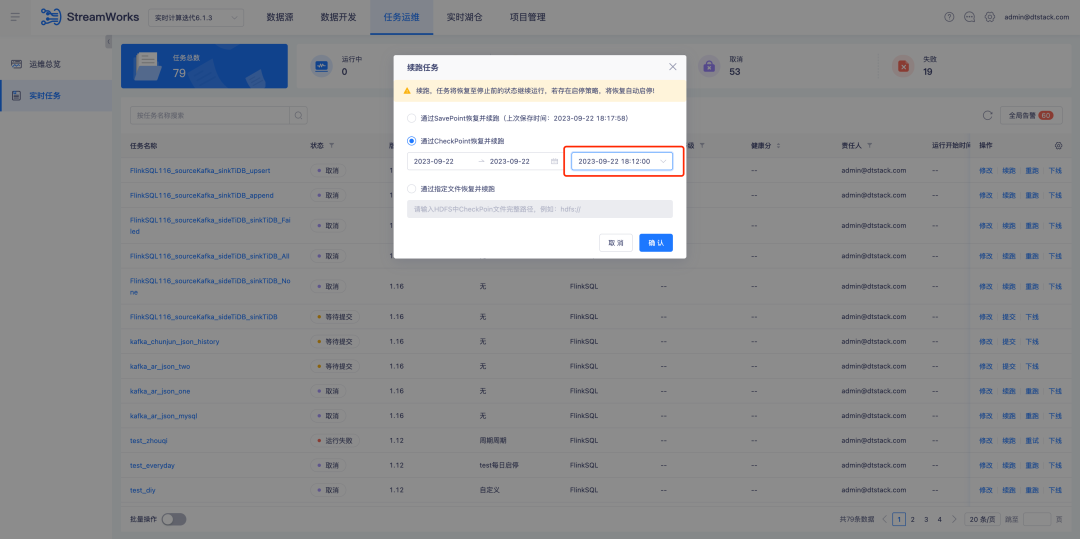
背景:实时任务通过 CheckPoint 恢复并续跑时,需要手动选择一个时间点,但实际上大部分续跑场景都是选择最近一个 CheckPoint。
体验优化说明:优化选择通过 CheckPoint 恢复并续跑时,自动选择日期内最近的 CheckPoint。
2.启停策略/Offsite 优化
背景:在客户的深入使用过程中,我们发现启停策略、提交和重跑等方面可以进行优化,以实现更高效的工作流程和更好的用户体验。
目前我们的数据开发源表中的 Offsite 时间戳配置都是固定的。然而,有些客户在实时任务计算场景中,只关注当天的数据计算,因此他们会配置一个启停策略,以便每天重新运行任务。他们希望能够从每天的零点开始重新运行任务,而不是使用固定的时间戳。虽然理论上 Latest 也能满足这一需求,但由于实时任务启动时间的消耗可能会导致实际运行时间偏离零点,从而产生数据误差。
体验优化说明:
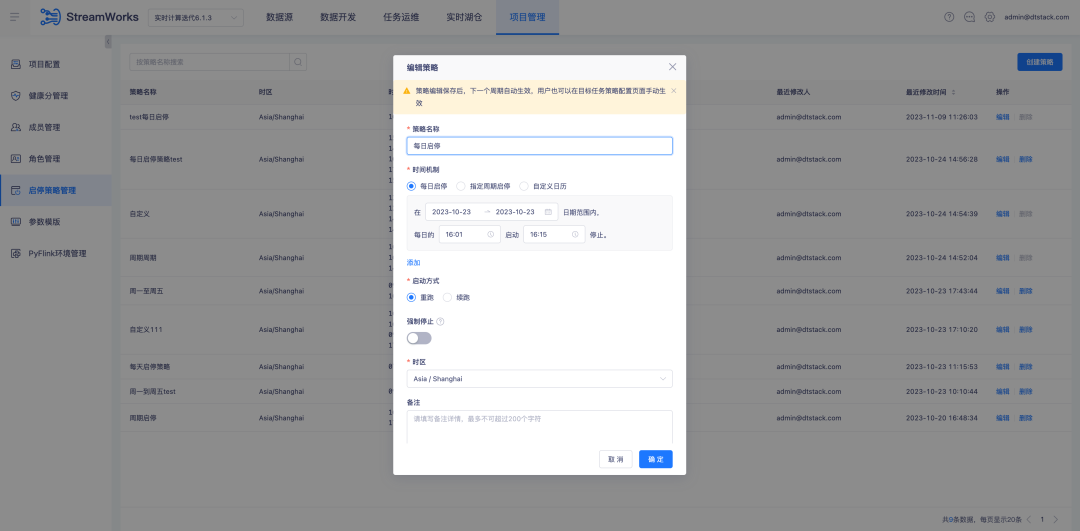
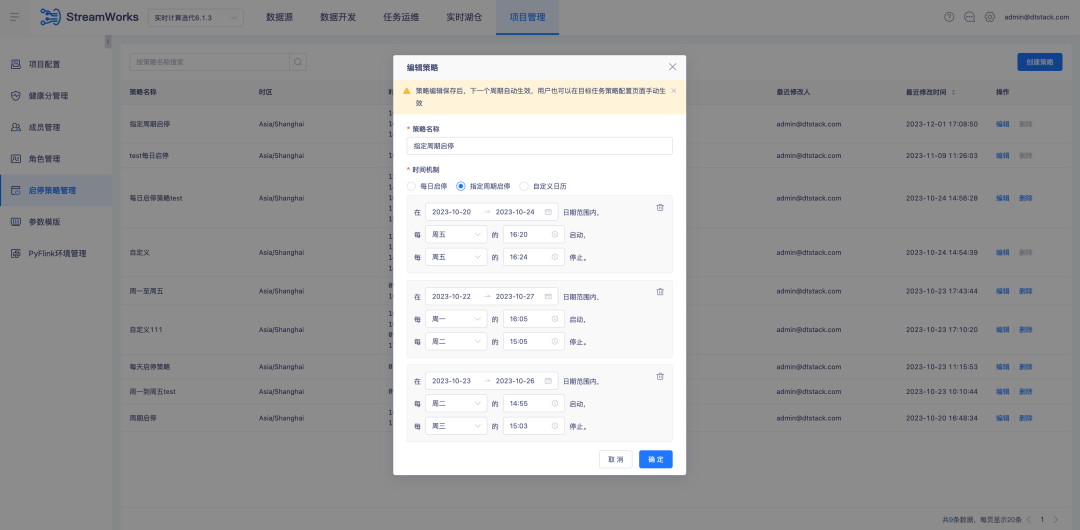
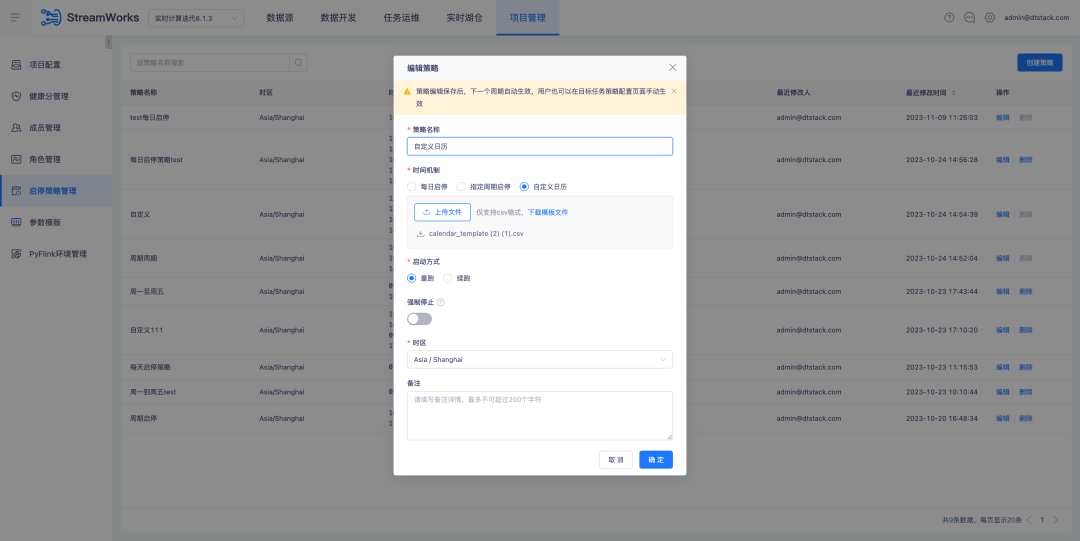
1、对启停策略配置进行优化,现在支持跨天的启停策略,并且对当前的启停策略页面交互进行了改进,以提供更高效、更便捷的操作体验
2、数据开发-源表,支持参数化配置 Offsite 位点
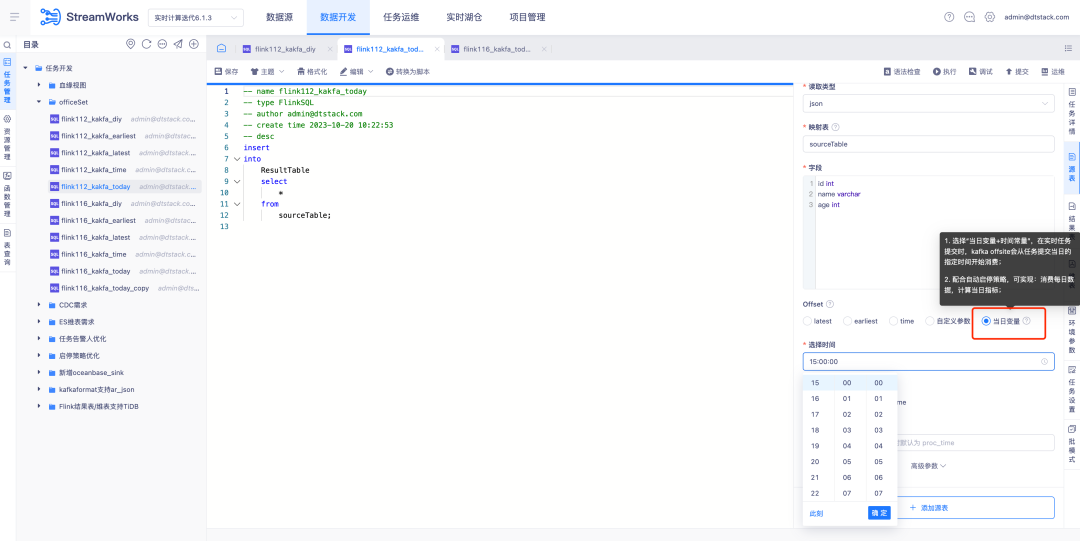
3.FlinkSQL1.16 版本 ES7.x 插件优化
背景: FlinkSQL1.10 版本的 ES 插件支持配置维表超时时间和超时数据次数限制,这一功能在当前的 FlinkSQL 1.16 版本中暂时无法实现,正积极进行优化。
体验优化说明:
FlinkSQL1.16 版本 ES7.x 插件维表配置 table.exec.async-lookup.timeout 或使用 hints 语法设置超时时间,任务运行中维表 LRU 模式,异步查询超时生效。
4.告警配置优化
背景:在任务告警规则中,告警接收配置需要手动选择,无法实现根据任务责任人自动匹配发送告警信息,同时在全局告警配置中,也无法根据任务责任人自动进行对应发送。
体验优化说明:
1、单任务告警规则配置接收人调整默认勾选任务责任人、其他接收人通过选择框进行选择,支持多选
2、全局告警规则配置勾选任务责任人时实际发送给每个任务的责任人,当选择其他接收人时,选择的任务异常时会发送给选择的接收人

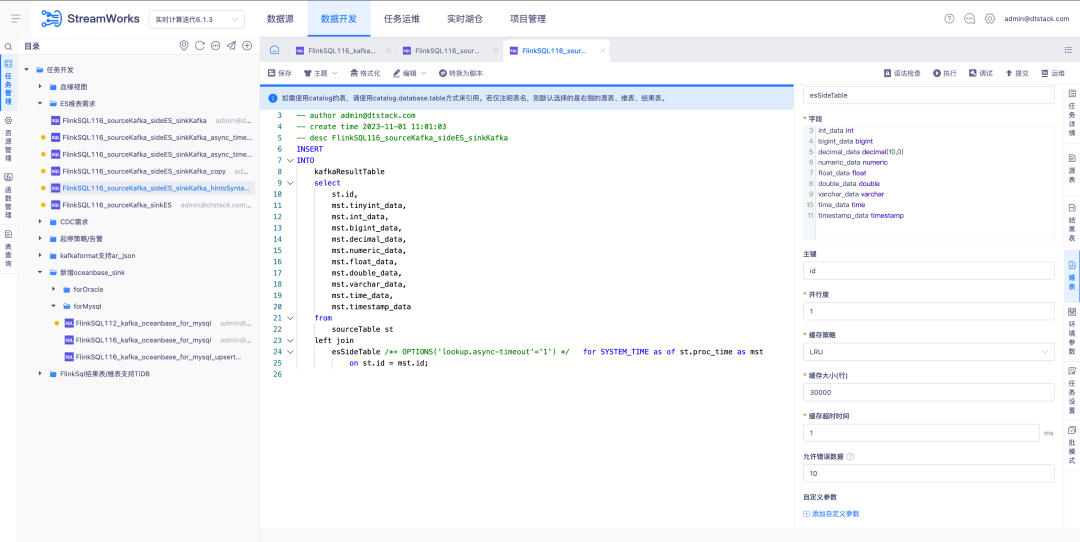
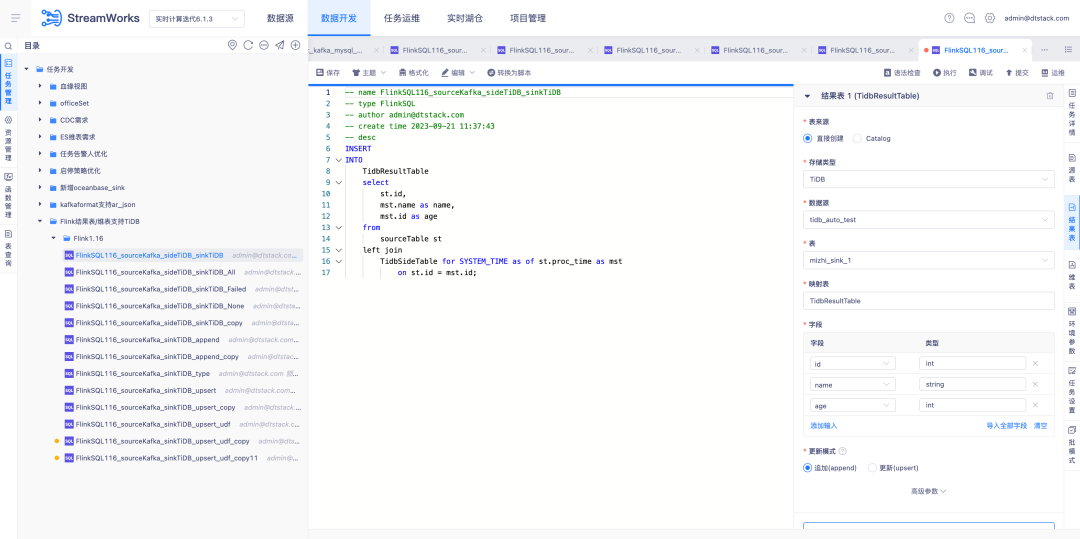
5.FlinkSQL1.12&1.16 版本 Tidb 插件平台兼容
背景: FlinkSQL 的1.12和1.16版本已经完成了与 Tidb 的适配,然而平台层仅在1.10版本时进行了适配,因此1.12和1.16版本不支持使用。
体验优化说明:
实时平台端兼容 Tidb 插件1.12&1.16版本,需要同时支持维表、结果表。
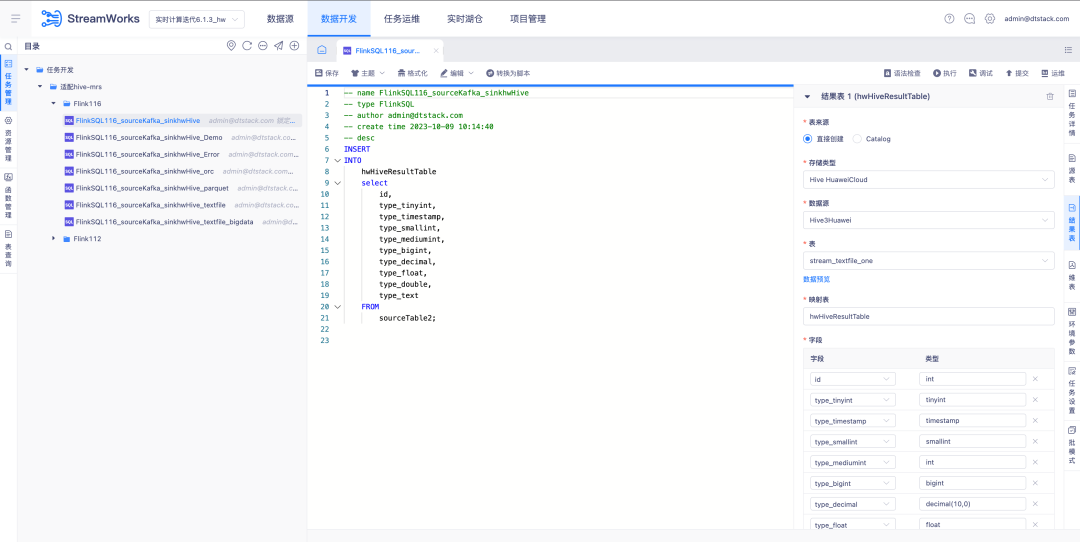
6.FlinkSQL1.12&1.16 版本 Hive huaweiCloud 适配
背景:实时备份 Kafka 数据打入 MRS Hive,当实时计算数据有问题时,可以对 Hive 里的备份消息做分析。
体验优化说明:
FlinkSQL1.12&1.16 版本 Hive huaweiCloud 适配,数据源中心、引擎、平台同步开发支持 Hive huaweiCloud 结果表,需要关注开启 Kerberos 场景。
数据服务平台
新增功能更新
1.支持 HBase TBDS 版本创建 API
新增 HBase TBDS 版本创建API,所包括范围:向导模式生成 API、导入导出、发布至目标项目。

功能优化
1.Oracle 数据源支持 DML
对 DML 所支持的数据源做完善。
2.自定义 SQL 模式注释解析不再覆盖说明
背景:对于历史逻辑,自定义 SQL 模式对于数据库重新解析后,数据库所自带的注释会覆盖所修改后的说明。
体验优化说明:对历史逻辑进行修改,对于修改后的说明,数据库的注释在重新解析后不再做覆盖处理。
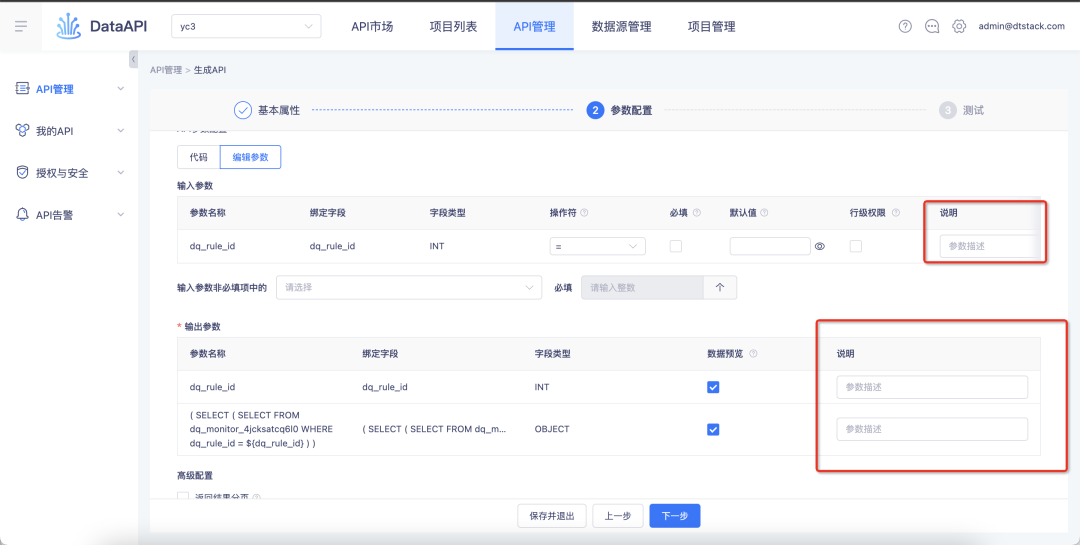
3.行级权限开启后默认不必填
背景:对于历史行级权限,会从表的字段去开启行级权限,开启后字段会默认为必填且不支持用户取消。
体验优化说明:本次迭代对历史逻辑做调整,行级权限会从 API 级别去开启行级权限,开启后该 API 使用该表时,就会受到行级权限的的限制。
4.框架版本、组件升级
Spring Cloud(Boot)框架版本升级,Nacos 组件升级,降低漏洞出现概率,加强 API 本身的稳定性。
客户数据洞察平台
新增功能更新
1.支持自定义 UDF 函数
背景:客户加工的数据中涉及到的手机号、身份证号等数据是加密数据,从审计角度来说,这种数据是不可以明文展示的,但上层业务上会有展示明文内容的场景,如:基于手机号进行短信营销。
客户需要将解密流程尽量后置,放到标签平台完成,通过 UDF 函数自定义的方式添加自定义标签完成加工。
新增功能说明:标签中心新增函数管理模块,在该模块下可创建、查看、删除 UDF 函数(仅 Trino385 以上版本支持创建函数)
上传的函数可点击函数名称查看函数详情。
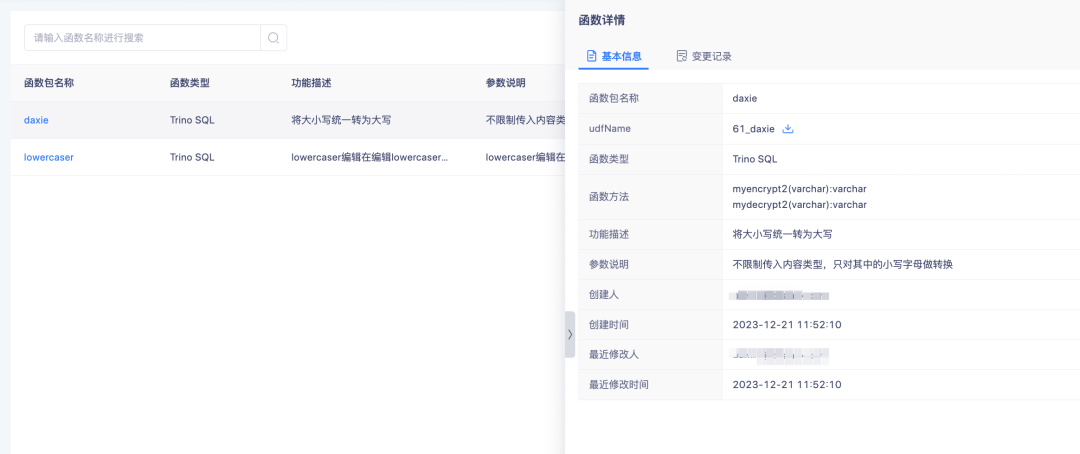
上传的函数主要作用于衍生 SQL 标签的加工。
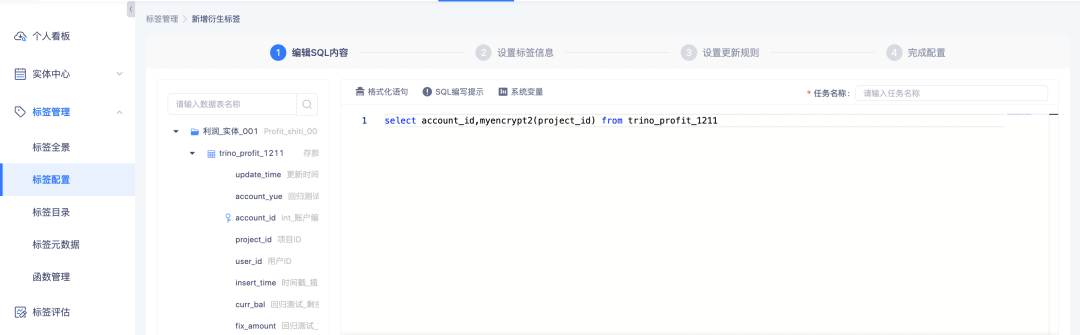
2.支持加工多值标签
背景:目前衍生标签、组合标签加工规则是当一个实例先命中了某一规则条件,则为该实例打上对应标签值,其他标签值不再做匹配,最终数据库里存的是单值标签结果。
但在实际应用中,条件之间不一定是互斥的,如:根据用户购买特定类型的商品次数给用户打上商品偏好标签,一个用户可以既喜欢家具,又喜欢服装,此时需要支持多值标签的设置。
新增功能说明:
衍生规则标签、衍生 SQL 标签、组合标签、自定义标签加工支持配置为多值标签,系统根据设置的标签值类型计算。
• 单值标签:按规则配置顺序依次匹配,命中某一个标签值时停止继续匹配,数据结果中最多有一个标签值
• 多值标签:按规则配置顺序依次匹配,每一个规则均会匹配一遍,数据结果中最多有配置的n个标签值
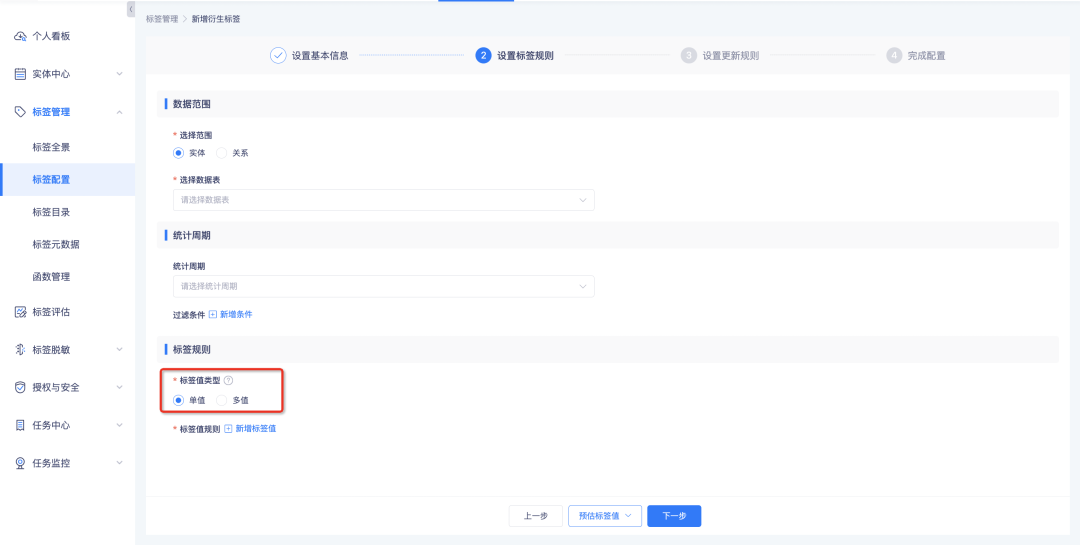
针对计算结果,标签详情中将针对每一个单独的标签做实例数统计,即,单值标签的每个标签值覆盖实例数之和为标签覆盖实例数,多值标签的每个标签值覆盖实例数之和大于等于标签覆盖实例数。
3.自定义角色对接业务中心
背景:之前角色为系统内置角色,且不可新增/修改/删除角色,不可自定义角色权限,功能过于固定,无法根据客户实际业务场景做灵活调整,在6.0版本中,业务中心新增自定义角色功能,标签产品对接业务中心的该功能,实现如下效果:
1、支持新增角色
2、支持自定义角色权限
新增功能说明:在业务中心配置角色及其指标权限,标签平台将自动引入权限配置结果做查询。
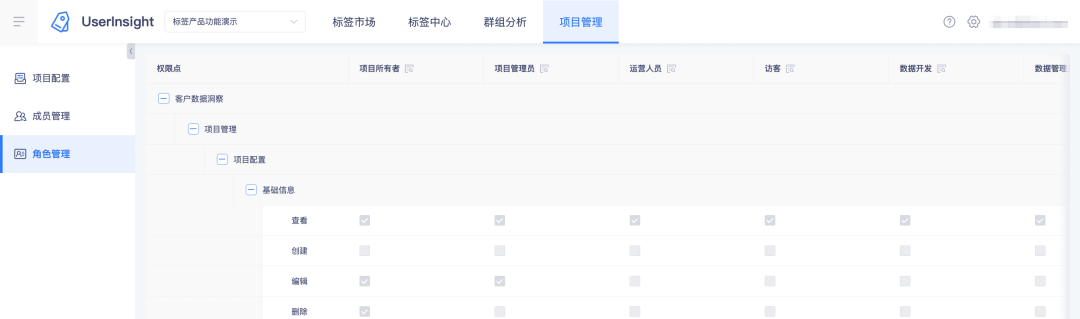
1、业务中心新增角色及配置角色权限点:
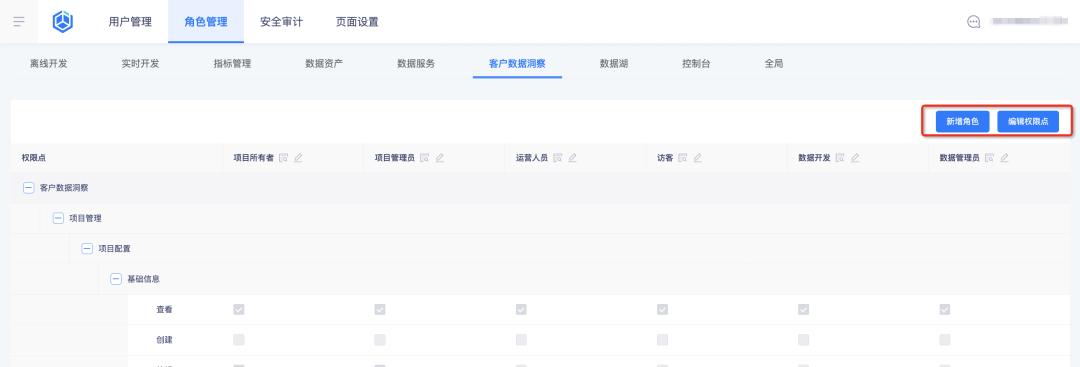
2、标签平台查看角色及其权限点:
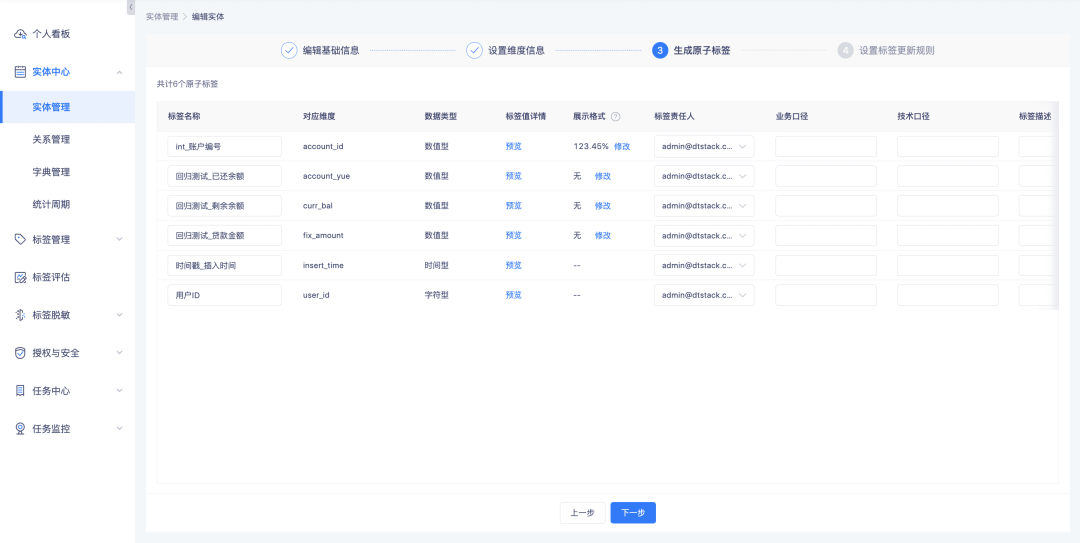
4、数据展示格式支持自定义
背景:对于数值型标签,目前不支持设置展示精度,导致页面展示不规范,有些显示的是1这种整数,有些显示的是1.234这种小数,整体阅读体验不高,为提升使用体验,需要增加数据展示规则的设置。
新增功能说明:
1、实体创建/编辑时、原子标签编辑时、衍生SQL标签创建/编辑时,支持对数值型的标签设置展示规则
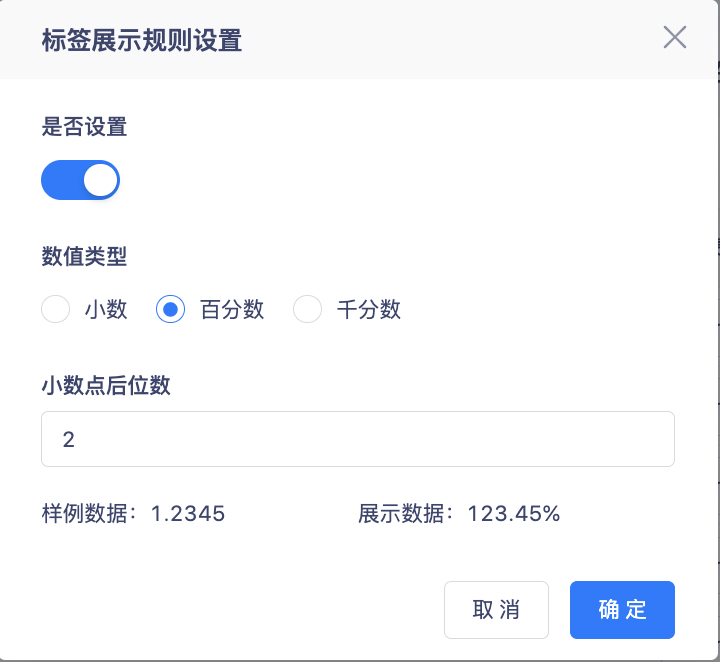
2、支持展示成小数、百分数、千分数,并支持设置小数点后位数
3、群组相关页面展示的标签数据,根据设置的展示规则展示
5、标签/群组文件上传支持查看上传进度
背景:文件导入功能目前上传无进度提示,当文件过大时等待时间较久,会让用户产生页面卡住了的误解,需增加进度提示已让用户明晰当前进展。
新增功能说明:
1、标签、群组文件上传、离线查询任务运行过程中增加进度提示
2、群组文件上传调整为支持最多上传500M大小文件
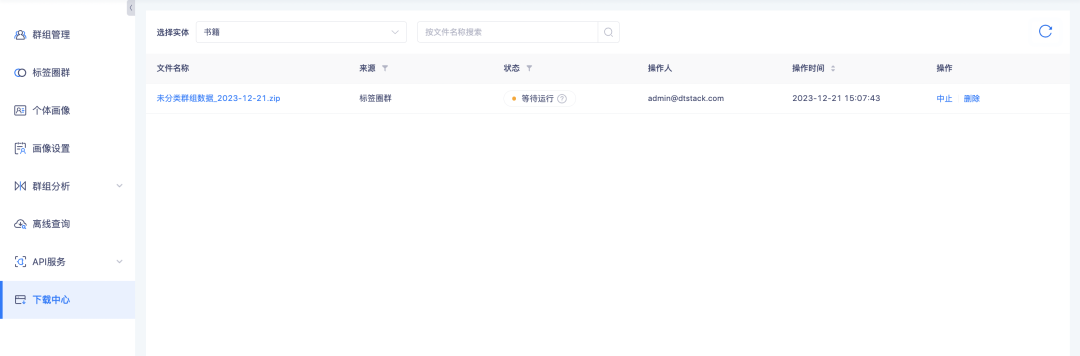
6、下载中心支持查询下载进度
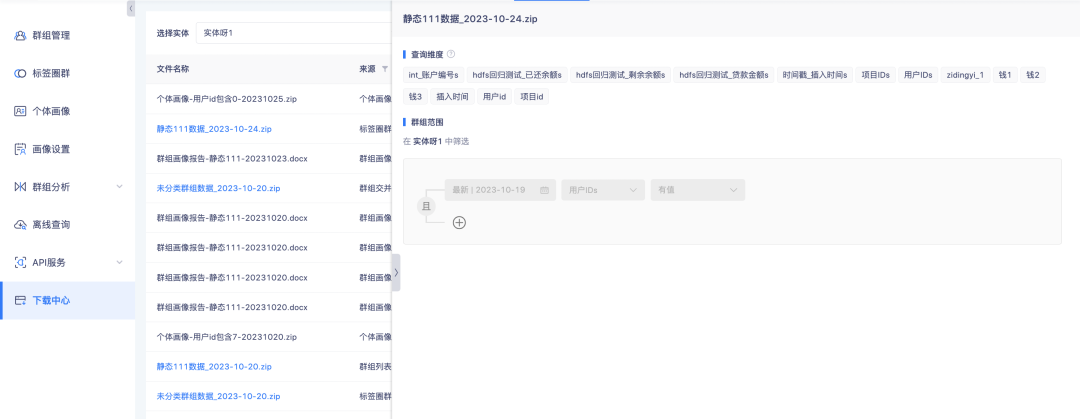
背景:数据下载过程中,因数据量大导致数据准备时间很久才能下载,用户使用时没有预期,需要频繁刷新以确定是否可以执行下载。需要增加下载进度提示,以指导用户确定等待时长。
新增功能说明:下载中心任务状态增加等待运行、已中止状态。其中,标签圈群-群组列表、群组详情-群体列表、上传本地群组-实例列表、离线查询-群组详情-实例列表、群组交并差-实例列表的下载因群组列表数据量较大,采用串行下载方式执行,群组列表相关任务依次排队执行,未排到的状态是等待运行,其他下载数据量小,将直接执行任务。任务运行过程中,可针对不再需要的任务执行中止操作。
功能优化
1.数据导出调整为通过下载中心下载文件
背景:部分页面的文件下载,是直接进行下载,导致按钮始终处于运行状态不变,使用者无法感知到下载进度。
体验优化说明:数据导出相关按钮点击后,文件进行异步下载,下载完成后,可进入「下载中心」模块下载数据详情,涉及到的页面按钮如下:标签圈群-数据导出、群组详情-群体列表-数据导出、上传本地群组-实例列表-数据导出、离线查询-上传本地群组/群组交并差详情-数据导出、群组交并差-数据导出。
若数据量过大, 系统将根据用户设置的记录数上限做分文件导出。
2.下载中心来自标签圈群、群组详情的列表数据支持查看配置详情
背景:目前下载中心的文件来源较多,只针对文件名称不便于做内容区分,需要增加文件数据来源,以提升数据可用性。
体验优化说明:来自标签圈群、群组详情的列表数据支持点击,点击侧边栏打开配置详情。
3.标签市场上新标签功能优化
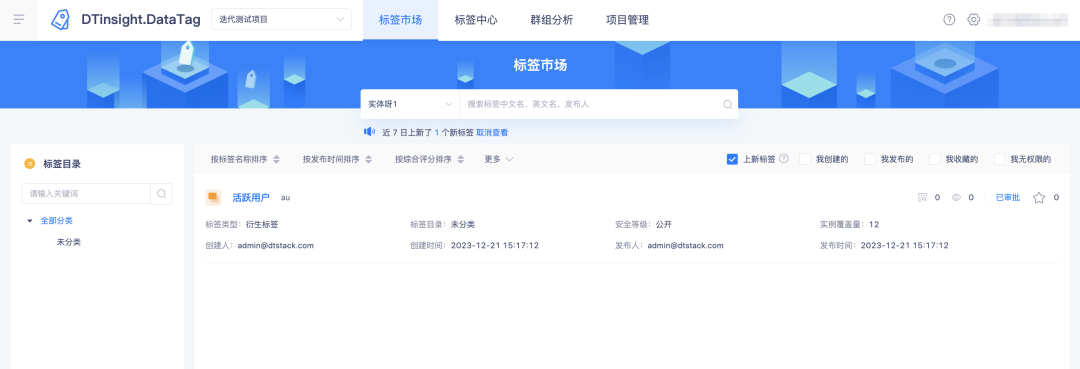
背景:目前平台对于上新标签的定义未做说明,需要增加说明。
体验优化说明:平台上新标签定义为近24小时,但实际使用中,周末一般大家不会关注,到了周一来再关注的时候会存在周五至周日早上更新的标签无法通知到位的情况,将定义调整为近7天。
4.跨子产品切换权限适配优化
标签产品进行跨子产品切换时,会存在页面tab内容缺失情况,是由于权限问题导致,本次优化保证跨产品切换页面时功能正常可用。
5、支持列宽调整自定义
群组列表、群组详情-群体列表、标签圈群-用户列表、群组交并差-实例列表、标签列表列宽支持自定义。
自定义列宽后,基于当前浏览器、当前登陆用户的后续使用均生效,当用户使用新浏览器登录操作或是当前浏览器清空缓存,或重新登陆,展示默认设置。
指标管理平台
新增功能更新
1.自定义角色对接业务中心
背景:之前角色为系统内置角色,且不可新增/修改/删除角色,不可自定义角色权限,功能过于固定,无法根据客户实际业务场景做灵活调整。
新增功能说明:
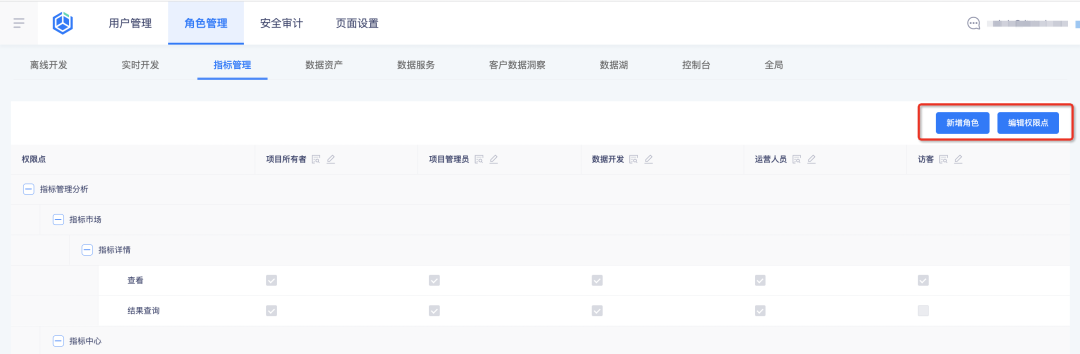
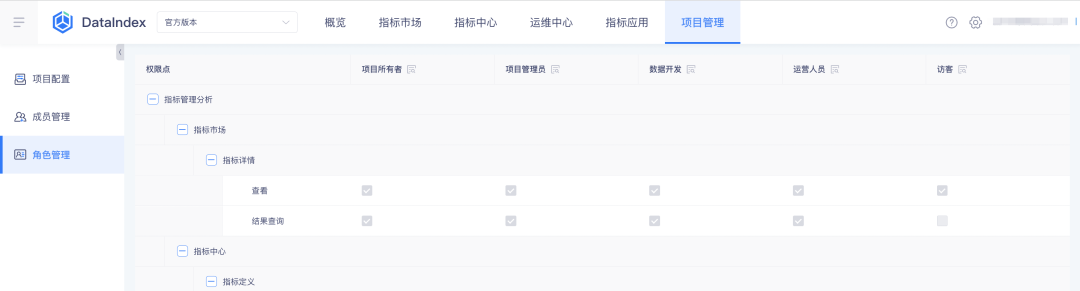
在业务中心配置角色及其指标权限,指标平台将自动引入权限配置结果做查询:
1、业务中心新增角色及配置角色权限点
2、指标平台查看角色及其权限点
2.Spark、数据同步任务支持自定义参数配置
背景:针对 Spark 任务、数据同步任务,目前只能通过控制台做参数调整,调整结果将在全局生效,但指标任务之间的数据量级差异性较大,配置相同的参数将造成资源浪费,因此针对 Spark、数据同步任务支持设置任务级参数,以方便对任务做灵活调控。
新增功能说明:
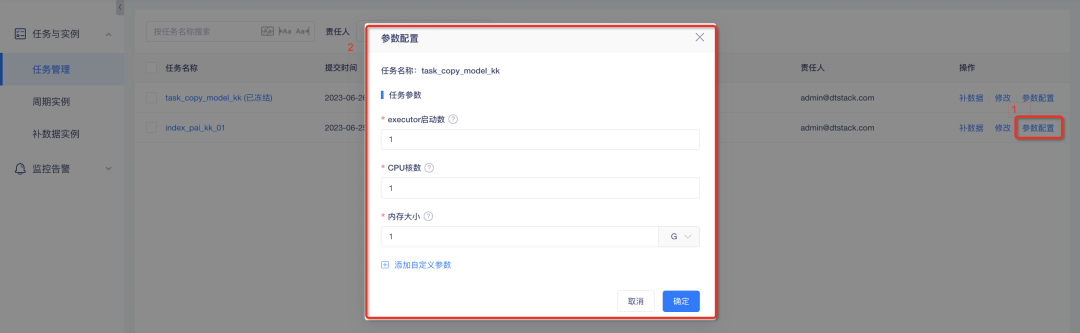
1、Spark任务自定义参数配置:其中,executor 启动数、CPU 核数、内存大小必填;可设置自定义参数
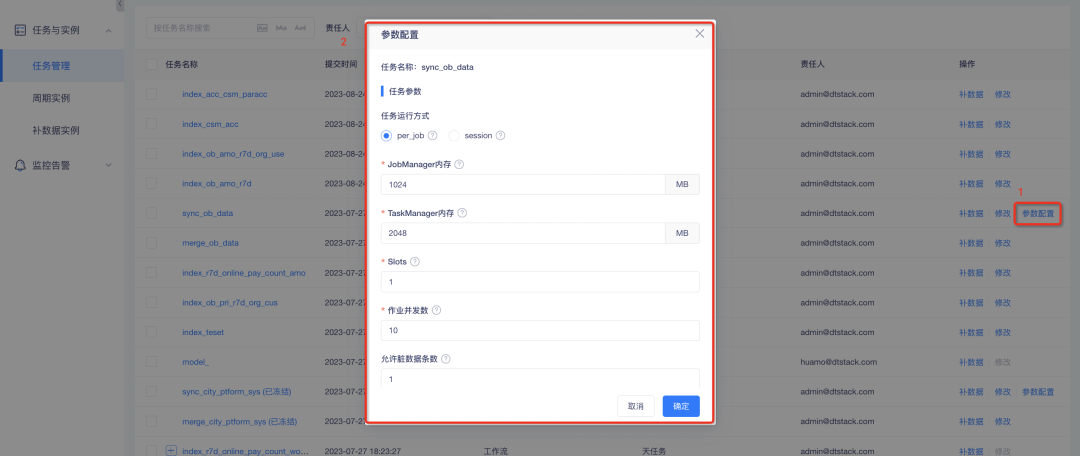
2、数据同步任务自定义参数配置:其中,per-job 模式下,jobmanager 内存、taskmanager 内存、slots必填;作业并发数、HBase 的 WriteBufferSize 必填;可设置自定义参数
功能优化
1.浏览器支持同时打开多个项目
背景:历史功能中,cookie 未存储项目参数,导致当数栈打开一个新项目窗口时,历史窗口中的内容将被刷新,回到项目列表页进行项目选择,影响客户使用。
体验优化说明:本次优化支持浏览器同时打开多个项目做查询、操作等,以提高产品使用效率。
2.edge 浏览器兼容
兼容 egde 浏览器,对功能做相应的适配调整,以提高产品在主流浏览器上的可用性。
3.行更新补充表更新时间
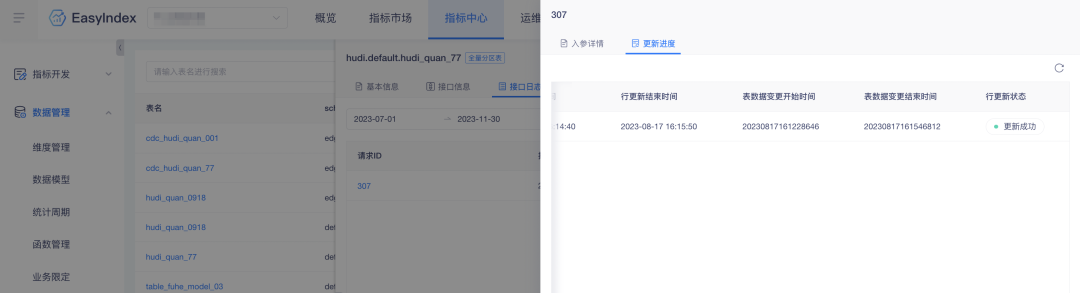
背景:行更新数据记录中缺少表数据变更时间段,导致做数据检索的时候不方便,为提高数据检索效率,平台中增加相关数据。
体验优化说明:指标行更新增加表数据变更开始时间、结束时间。
4.行更新状态增加手动刷新功能
行更新过程中,为方便及时跟进更新进度,在页面增加刷新按钮,以提高刷新效率。

5、模型填充的维度对象、维度属性功能优化
编辑模型时,设置维度信息步骤中,系统会默认回填主维表字段绑定的维度信息,若历史版本中用户已修改关联维度,编辑过程中若未注意调整,将会保存错误数据,为避免数据错误率,调整为回显上一版本保存信息。
6、API gateway支持自定义前缀
指标当前是 API 的前缀信息是写到配置项中,同时 API 目前有一个自定义前缀功能以提高 API 配置灵活性。此时,当指标的 API 配置项与 API 自定义前缀不一致时无法正常调用数据,需要调整为对接 API 的配置设置,保证全局配置唯一。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn
这篇关于袋鼠云产品功能更新报告09期|更全面,更多样,更高效的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




