本文主要是介绍链表之“无头单向非循环链表”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
编辑
1.顺序表的问题及思考
2.链表
2.1链表的概念及结构
2.2无头单向非循环链表的实现
1.创建结构体
2.单链表打印
3.动态申请一个节点
3.单链表尾插
4.单链表头插
5.单链表尾删
6.单链表头删
7.单链表查找
8.单链表在pos位置之前插入x
9.单链表删除pos位置的值
10.单链表在pos位置之后插入x
11.单链表删除pos位置之后的值
12.单链表销毁
3.源码
1.顺序表的问题及思考
🌻问题:
- 顺序表在尾部插入删除效率还不错,但是在头部或者中间位置插入删除,就需要挪动数据,时间复杂度为O(N),效率低下。
- 空间满了以后只能增容,增容需要申请新的空间,拷贝数据,释放旧空间,会有一定的消耗。
- 增容一般是呈2倍的增长,势必会有一定的空间浪费。假设当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。也就是说,一次增的越多,可能浪费越多;一次增的少了,那么就会频繁增容。
🌻思考:
- 如何解决以上问题呢?下面让我们一起来看看链表的结构:
2.链表

2.1链表的概念及结构
🌴概念:
- 链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
- 简单来说,就是链表中的每一个数据元素都是单独存储的,我们把这个数据元素又叫做节点。当需要存储下一个数据元素的时候就申请一块新的内存用来存储数据,每一个节点又通过地址链接起来,当前节点存放的是下一个节点的地址。所以,一个节点里边就包含数据元素和下一个节点的地址这两部分。

🌴结构:
注意:
- 从上图可以看出,链式结构在逻辑上是连续的,但是在物理上不一定连续。
- 现实中的节点一般都是从堆上申请出来的。
- 从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续。
假设在32位系统上,节点中值域为int类型,则一个节点的大小为8个字节,则也可能有下述链表:



2.2无头单向非循环链表的实现
1.创建结构体
typedef int SLTDataType;typedef struct SListNode
{SLTDataType val; //数据域struct SListNode* next; //指针域
}SLNode;2.单链表打印
- phead是一个指针变量,占4个字节,它指向第一个节点,即存的是第一个节点的地址。而在其它节点中,每个节点里边分别又有两个数据域,其中一个保存val,另一个保存下一个节点的地址,在32位环境下,一个节点占8个字节。
- 遍历链表时,担心phead会发生意外,所以我们先将phead的值赋给cur,看cur等不等于NULL,如果不等于NULL,就进入循环,打印第一个节点的值,然后将第二个节点的地址再赋给cur,看它等不等于NULL,如果不等于NULL,再打印第二个节点的值,再将第三个节点的地址赋给cur,以此循环,直到cur等于NULL,就跳出循环。

//单链表打印
void SLTPrint(SLNode* phead)
{//不要动phead,否则会找不到头SLNode* cur = phead;while (cur != NULL){printf("%d->", cur->val);cur = cur->next;}printf("NULL\n");
}3.动态申请一个节点
如果直接在其它函数内部申请节点的话,它的作用域就只能在那个函数内部,出了函数作用域就会销毁,所以得单独写一个函数来申请节点,让其它函数来调用它。
//动态申请一个节点
SLNode* CreateNode(SLTDataType x)
{SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));if (newnode == NULL){perror("malloc");exit(-1);}newnode->val = x;newnode->next = NULL;return newnode;
}3.单链表尾插
单链表尾插分为有节点和无节点两种情况:
- 假设现在链表里边有节点,那我们要尾插一个数据,第一步肯定是要先找到尾。先定义一个tail,让它指向头节点,然后看tail->next等不等于NULL,如果不为NULL,让tail等于tail->next,依次循环,直到tail->next等于NULL的时候,tail刚好就是尾节点。找到尾节点后,再动态申请一个节点,让新申请的节点指向NULL,再让尾节点指向新申请的这个节点。
- 如果链表里边没有节点,即链表为空,那我们直接让*pphead指向新节点的地址就行了。因为在主函数里边我们定义的是*plist的指针,所以要想改变外面结构体指针SLNode*,就要用二级指针SLNode**。
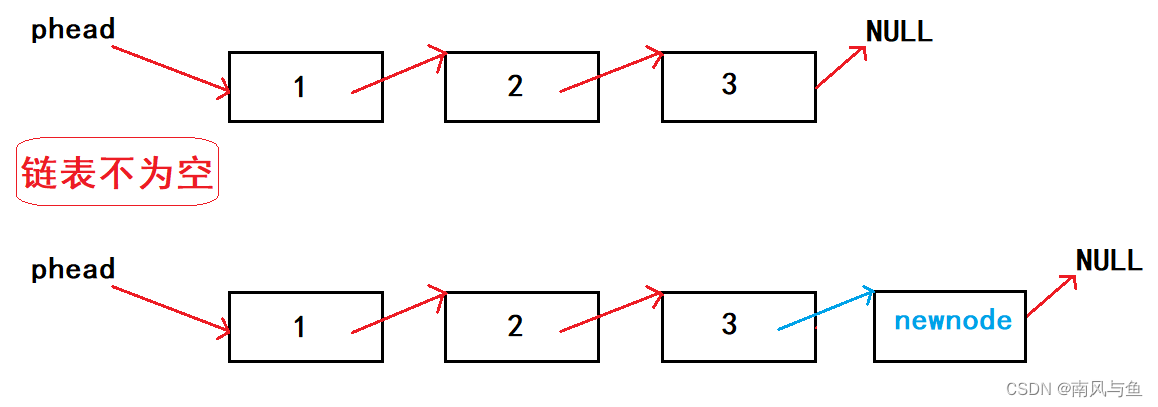
//单链表尾插
void SLTPushBack(SLNode** pphead, SLTDataType x)
{assert(pphead);SLNode* newnode = CreateNode(x);if (*pphead == NULL){*pphead = newnode;}else{//找尾SLNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newnode;}
}
4.单链表头插
头插时比较简单,我们让新申请出来的节点newnode指向第一个节点的地址,而第一个节点的地址保存在plist里边,我们又把plist的地址赋给了pphead,所以让newnode->next指向*pphead,再将*pphead指向newnode就可以了。
//单链表头插
void SLTPushFront(SLNode** pphead, SLTDataType x)
{assert(pphead);SLNode* newnode = CreateNode(x);newnode->next = *pphead;*pphead = newnode;
}
5.单链表尾删
单链表的尾删也分为两种情况:
- 第一种是当链表里边只有一个节点的时候,我们只需要free掉这个节点,然后让plist指向空就行了。
- 第二种是当链表里边有多个节点的时候,我们可以定义两个指针,让第一个指针prev指向NULL,第二个指针保存头节点的地址,然后通过循环找尾,当找到尾的时候,跳出循环,此时prev刚好指向了尾的前一个节点,我们再free掉尾,让前一个节点指向空就可以了。
//单链表尾删
void SLTPopBack(SLNode** pphead)
{assert(pphead);assert(*pphead);//1.一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}//2.多个节点else{/*SLNode* prev = NULL;SLNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);tail = NULL;prev->next = NULL;*/SLNode* tail = *pphead;while (tail->next->next != NULL){tail = tail->next;}free(tail->next);tail->next = NULL;}
}6.单链表头删
因为空链表无法删除,所以需要先断言。头删只需要将第一个节点free掉就可以了,但是free之前得先保存下一个节点的地址。
//单链表头删
void SLTPopFront(SLNode** pphead)
{assert(pphead);//空assert(*pphead);//一个或多个以上节点都可以处理SLNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}7.单链表查找
单链表的查找只需要遍历一遍就可以了,定义一个cur让它指向第一个节点的地址,通过循环如果cur不为空,就进入循环,进入循环后,如果cur->val等于x,则返回cur,否则,让cur指向下一个节点的地址。遍历完一遍如果没有找到,则返回NULL。可以说查找函数是为了配合修改单链表中的值而写的。
//单链表查找
SLNode* SLTFind(SLNode* phead, SLTDataType x)
{SLNode* cur = phead;while (cur){if (cur->val == x){return cur;}else{cur = cur->next;}}return NULL;
}8.单链表在pos位置之前插入x
如果此时链表为空,那么就相当于头插;如果不为空,则只需找到pos位置的前一个节点,让前一个节点的地址指向新节点,新节点指向pos位置即可。
//单链表在pos位置之前插入x
void SLTInsert(SLNode** pphead, SLNode* pos, SLTDataType x)
{assert(pphead);//要么都为空,要么都不为空assert((!pos && !(*pphead)) || (pos && *pphead));if (*pphead == pos){//头插SLTPushFront(pphead, x);}else{SLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLNode* newnode = CreateNode(x);prev->next = newnode;newnode->next = pos;}
}
9.单链表删除pos位置的值
如果链表只有一个节点,则相当于头删;如果有多个节点,则需要找到pos位置的前一个节点,然后让前一个节点指向pos位置的后一个节点,接着free掉pos即可。
//单链表删除pos位置的值
void SLTErase(SLNode** pphead, SLNode* pos)
{assert(pphead);assert(*pphead);assert(pos);if (*pphead == pos){//头删SLTPopFront(pphead);}else{SLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}}10.单链表在pos位置之后插入x
创建一个新节点,先让新节点的指针域存pos后一个节点的地址,然后让pos的指针域存新节点的地址。
//单链表在pos位置之后插入x
void SLTInsertAfter(SLNode* pos, SLTDataType x)
{assert(pos);SLNode* newnode = CreateNode(x);newnode->next = pos->next;pos->next = newnode;
}
11.单链表删除pos位置之后的值
这个操作必须保证链表中有两个以上的数据,如果只有一个数据的话,那它后面为空,没法执行删除操作,所以得先断言一下。
//单链表删除pos位置之后的值
void SLTEraseAfter(SLNode* pos)
{assert(pos);assert(pos->next);SLNode* tmp = pos->next;pos->next = pos->next->next;free(tmp);tmp = NULL;
}12.单链表销毁
//单链表销毁
void SLTDestroy(SLNode** pphead)
{assert(pphead);SLNode* cur = *pphead;while (cur){SLNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}3.源码
🌻SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int SLTDataType;typedef struct SListNode
{SLTDataType val;struct SListNode* next;
}SLNode;//单链表打印
void SLTPrint(SLNode* phead);//单链表尾插
void SLTPushBack(SLNode** pphead, SLTDataType x);
//单链表头插
void SLTPushFront(SLNode** pphead, SLTDataType x);
//单链表尾删
void SLTPopBack(SLNode** pphead);
//单链表头删
void SLTPopFront(SLNode** pphead);//单链表查找
SLNode* SLTFind(SLNode* phead, SLTDataType x);//单链表在pos位置之前插入x
void SLTInsert(SLNode** pphead, SLNode* pos, SLTDataType x);
//单链表删除pos位置的值
void SLTErase(SLNode** pphead, SLNode* pos);//单链表在pos位置之后插入x
void SLTInsertAfter(SLNode* pos, SLTDataType x);
//单链表删除pos位置之后的值
void SLTEraseAfter(SLNode* pos);//单链表销毁
void SLTDestroy(SLNode** pphead);
🌻SList.c
#include "SList.h"//单链表打印
void SLTPrint(SLNode* phead)
{//不要动phead,否则会找不到头SLNode* cur = phead;while (cur != NULL){printf("%d->", cur->val);cur = cur->next;}printf("NULL\n");
}//动态申请一个节点
SLNode* CreateNode(SLTDataType x)
{SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));if (newnode == NULL){perror("malloc");exit(-1);}newnode->val = x;newnode->next = NULL;return newnode;
}//单链表尾插
void SLTPushBack(SLNode** pphead, SLTDataType x)
{assert(pphead);SLNode* newnode = CreateNode(x);if (*pphead == NULL){*pphead = newnode;}else{//找尾SLNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newnode;}
}//单链表头插
void SLTPushFront(SLNode** pphead, SLTDataType x)
{assert(pphead);SLNode* newnode = CreateNode(x);newnode->next = *pphead;*pphead = newnode;
}//单链表尾删
void SLTPopBack(SLNode** pphead)
{assert(pphead);assert(*pphead);//1.一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}//2.多个节点else{/*SLNode* prev = NULL;SLNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);tail = NULL;prev->next = NULL;*/SLNode* tail = *pphead;while (tail->next->next != NULL){tail = tail->next;}free(tail->next);tail->next = NULL;}
}//单链表头删
void SLTPopFront(SLNode** pphead)
{assert(pphead);//空assert(*pphead);//一个或多个以上节点都可以处理SLNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}//单链表查找
SLNode* SLTFind(SLNode* phead, SLTDataType x)
{SLNode* cur = phead;while (cur){if (cur->val == x){return cur;}else{cur = cur->next;}}return NULL;
}//单链表在pos位置之前插入x
void SLTInsert(SLNode** pphead, SLNode* pos, SLTDataType x)
{assert(pphead);//要么都为空,要么都不为空assert((!pos && !(*pphead)) || (pos && *pphead));if (*pphead == pos){//头插SLTPushFront(pphead, x);}else{SLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLNode* newnode = CreateNode(x);prev->next = newnode;newnode->next = pos;}
}//单链表删除pos位置的值
void SLTErase(SLNode** pphead, SLNode* pos)
{assert(pphead);assert(*pphead);assert(pos);if (*pphead == pos){//头删SLTPopFront(pphead);}else{SLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}//单链表在pos位置之后插入x
void SLTInsertAfter(SLNode* pos, SLTDataType x)
{assert(pos);SLNode* newnode = CreateNode(x);newnode->next = pos->next;pos->next = newnode;
}//单链表删除pos位置之后的值
void SLTEraseAfter(SLNode* pos)
{assert(pos);assert(pos->next);SLNode* tmp = pos->next;pos->next = pos->next->next;free(tmp);tmp = NULL;
}//单链表销毁
void SLTDestroy(SLNode** pphead)
{assert(pphead);SLNode* cur = *pphead;while (cur){SLNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}这篇关于链表之“无头单向非循环链表”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




