本文主要是介绍MySQL 窗口函数温故知新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文用于复习数据库窗口函数,希望能够温故知新,也希望读到这篇文章的有所收获。
本文以:MySQL为例
参考文档: https://www.begtut.com/mysql/mysql-window-functions.html
使用的样例数据:https://www.begtut.com/mysql/mysql-sample-database.html
1. 概括的说明
| 函数 | 说明 |
|---|---|
| ROW_NUMBER | 为其分区中的每一行分配一个序号。 |
| RANK | 根据ORDER BY的字段,为每一行分配一个排名。 值相同的行分配相同的排名, 下一行排名不联系,会累加值相同的行数。 |
| DENSE_RANK | 与RANK()函数类似,只是当出现值相同的行时,排名是连续的,不是累加行数。 |
| PERCENT_RANK | 计算分区或结果集中行的百分位数。计算公式为:(当前从小到大排序序号-1 ) / (总序号数-1) 【就是(rank - 1) / (total_rows - 1) 】 |
| FIRST_VALUE | 返回指定表达式相对于窗口框架中第一行的值。 |
| LAST_VALUE | 返回指定表达式相对于窗口框架中最后一行的值。 |
| LEAD | 返回分区中当前行之后的第N行的值。 如果不存在后续行,则返回NULL。 |
| LAG | 返回分区中当前行之前的第N行的值。 如果不存在前一行,则返回NULL。 |
| NTILE | 将每个窗口分区的行分配到指定数量的已排名组中。 (把结果分成n个组) |
| CUME_DIST | 计算一组值中值的累积分布。 |
| NTH_VALUE | 返回窗口框架第N行的参数 |
2. 注意 rows between 的用法
- rows between …… and ……
- unbounded preceding 前面所有行 、n preceding 前面n行
- unbounded following 后面所有行 、n following 后面n行
- current row 当前行
SELECTorderNumber,productCode,quantityOrdered,SUM(quantityOrdered) OVER(PARTITION BY orderNumber ORDER BY productcode) AS quantity_amount,-- 前面一行和当前行的值累加SUM(quantityOrdered) OVER(PARTITION BY orderNumber ORDER BY productcode ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) quantity_add
FROMmysqldemo.orderdetails
WHEREorderNumber = 10103;
3. 注意 range between的用法
range between 按照排序字段的值限制窗口大小。主要将order by后面字段排序后,然后根据排序字段的值,框定一个范围,再对这个范围内的行进行汇总。样例如下:
sum(num) over(order by dateTime range between interval 6 day preceding and current row)
-- 必须是date类型的数据,这一天和前面6天(如果存在)的数据sum(close) over(order by salary range between 100 preceding and 200 following)
--通过 salary 字段差值来进行选择。如当前行的 salary 字段值是 200,那么这个窗口大小的定义就会选择分区中 salary 字段值落在 100 至 400 区间的记录(行),再求这些行的sum(close).需要注意的点:
- rows表示行,就是前n行,后n行。
- range表示的是具体的值,比这个值小n的行,比这个值大n的行。是以当前值为锚点进行计算。
- 同时 range 也可以使用 between unbounded preceding and unbounded following,效果和等同于rows一样,取上下限所有行,不指定值。
- range 窗口仅对数字和日期起作用,因为需要计算值的范围。
- 在range 的开窗中,order by 中只能有一列;rows 的开窗的order by 可以有多列。
SELECTorderNumber,productCode,quantityOrdered,SUM(quantityOrdered) OVER(PARTITION BY orderNumber ORDER BY quantityOrdered) AS quantity_amount,-- quantityOrdered 的值-1 和 +2的值区间范围内的行的累加SUM(quantityOrdered) OVER(PARTITION BY orderNumber ORDER BY quantityOrdered RANGE BETWEEN 1 PRECEDING AND 2 following) quantity_add
FROMmysqldemo.orderdetails;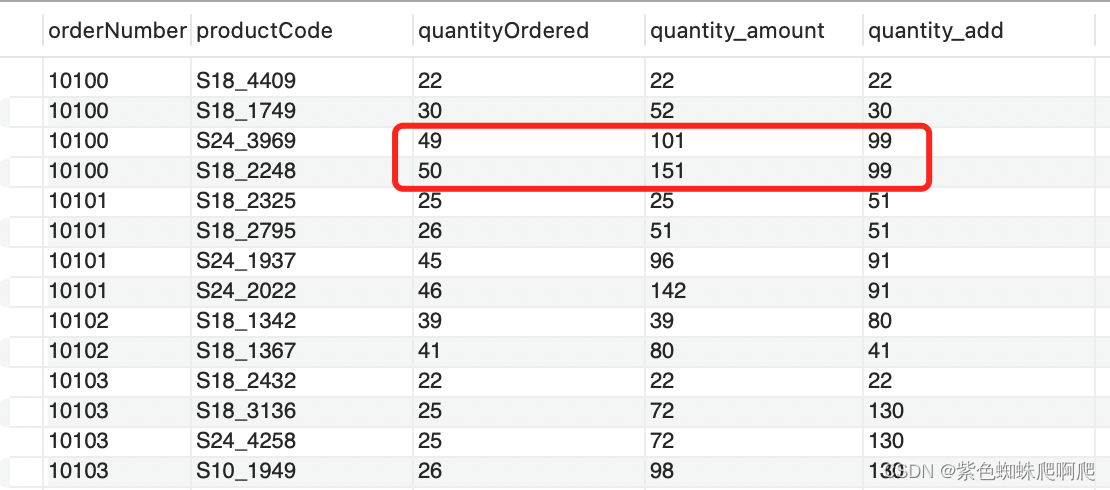
4. ROW_NUMBER & RANK & DENSE_RANK
比较常用,都很熟悉,基本用法就不用赘述了。
SELECTorderNumber,productCode,quantityOrdered,ROW_NUMBER() OVER (ORDER BY quantityOrdered) AS nb,RANK() OVER (PARTITION BY orderNumber ORDER BY quantityOrdered) AS rank_quantity,DENSE_RANK() OVER (PARTITION BY orderNumber ORDER BY quantityOrdered) AS dense_rank_quantity
FROMmysqldemo.orderdetails
WHEREorderNumber = 10103;rank和dense_rank 的区别,就是遇到有多行值相同时,那么下一行的序号,rank会加上重复的行数,那么rank对应的序号就不连续了;dense_rank 不会加上重复的行数,保持序号任然是连续的。
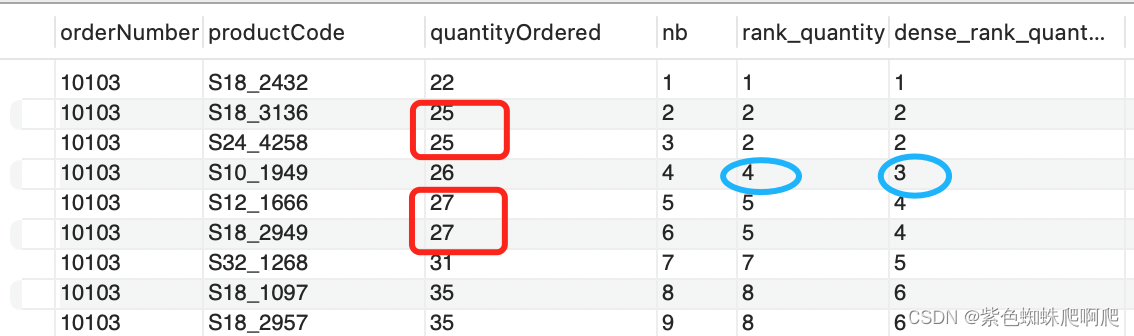
需要注意的点:
- ROW_NUMBER 不加partition的时候,对所有行加序号,加partition之后分组加序号。
- RANK 注意不加order by的时候,不排序,全是1,即使加partition也没用;一定要加order by才会排序。
- SUM 用法和 ROW_NUMBER 相同,汇总和分组汇总。
SELECT *, ROW_NUMBER() OVER () row_num0,ROW_NUMBER() OVER (PARTITION BY productline) row_num1,RANK() OVER() AS Rank00,RANK() OVER(PARTITION BY productline) AS Rank01,RANK() OVER(PARTITION BY productline,order_year) AS Rank02,RANK() OVER(order by amount) AS Rank1,RANK() OVER(PARTITION BY productline order by amount) AS Rank2,SUM(amount) OVER(PARTITION BY productline,order_year ) AS amount0,SUM(amount) OVER(PARTITION BY productline ) AS amount1,SUM(amount) OVER() AS amount2
FROM (SELECT productline, year(orderDate) order_year, sum(quantityOrdered) as amountFROM ordersINNER JOIN orderdetails USING (orderNumber)INNER JOIN products USING (productCode)GROUP BY productline,order_year) T;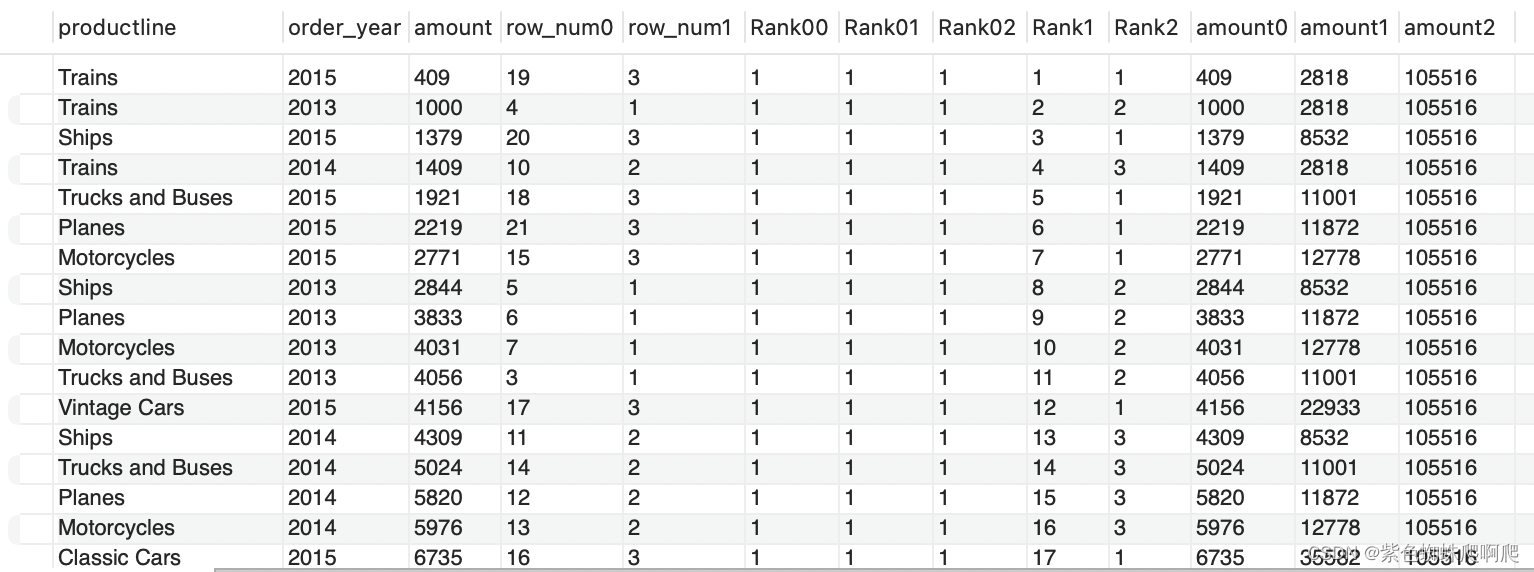
5. PERCENT_RANK()
函数返回一个从0到1的数字。 计算公式为:(rank - 1) / (total_rows - 1)。
rank是当前行的等级,total_rows是要计算的行数。 公式的意思就是计算当前行的等级减1,除以分区或结果集中的总行数减1。
- PERCENT_RANK()对于分区或结果集中的第一行,函数始终返回零。重复的列值将接收相同的PERCENT_RANK()值。
- PERCENT_RANK()是一个顺序敏感函数,因此,您应始终使用ORDER BY子句。
CREATE TABLE productLineSales -- 我们创建了一张表,后面还会重复用到它
SELECTproductLine,YEAR(orderDate) orderYear,SUM(quantityOrdered * priceEach) orderValue
FROM orderDetails
INNER JOIN orders USING (orderNumber)
INNER JOIN products USING (productCode)
GROUP BY productLine , YEAR(orderDate); WITH t AS (SELECT productLine, SUM(orderValue) orderValueFROM productLineSalesGROUP BY productLine
)
SELECTproductLine,orderValue,ROUND(PERCENT_RANK() OVER (ORDER BY orderValue),2) percentile_rank
FROM t; 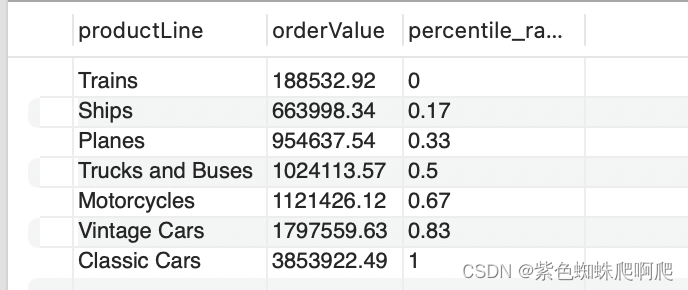
在这个例子中: 首先,我们使用表达式按产品线汇总订单值。 其次,我们用它PERCENT_RANK()来计算每种产品的订单价值的百分等级。
以下是输出中的一些分析:
- 订单价值Trains并不比任何其他产品线更好,后者用零表示。
- Vintage Cars 表现优于50%的其他产品。
- Classic Cars 表现优于任何其他产品系列,因此其百分比等级为1或100%
6. CUME_DIST
它表示值小于或等于当前行的值除以总行数。 公式为: ROW_NUMBER() / total_rows 。注意和 PERCENT_RANK 的区别。
- CUME_DIST()函数的返回值大于零且小于或等于1。
- 重复的列值接收相同的CUME_DIST()值。
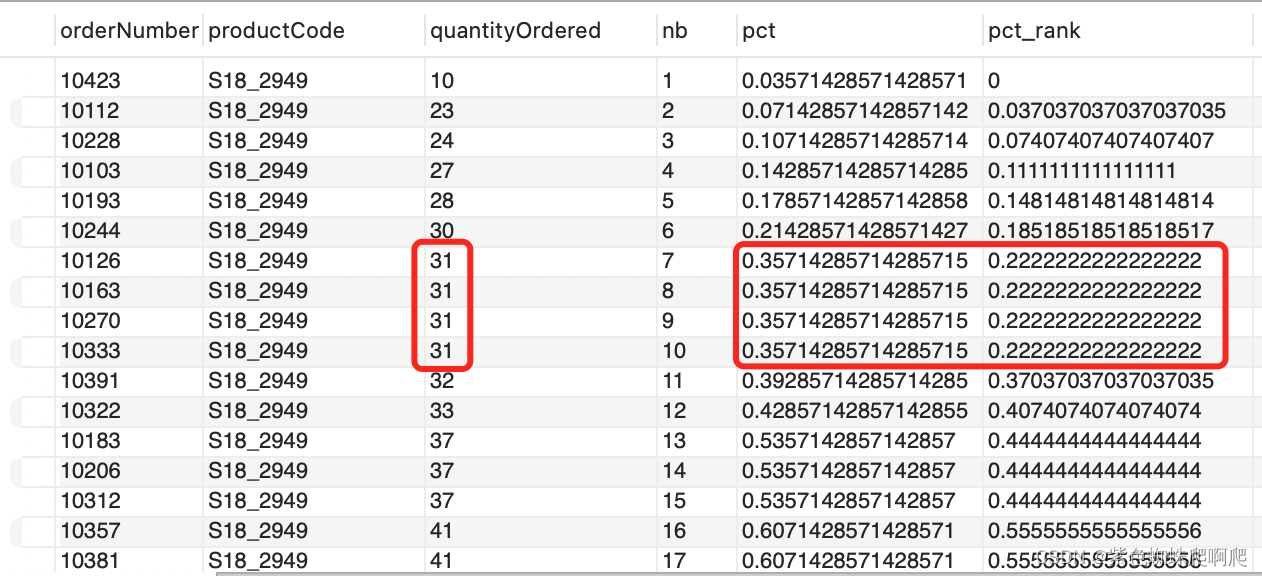
样例:计算某产品的订单订货量数量分布 (注意第7行开始有重复的值31,对应百分比也是相同的。表示数量小于等于31的一共10行,占总行数28的35.71%)
SELECT orderNumber, productCode, quantityOrdered, ROW_NUMBER() OVER(ORDER BY quantityordered) AS nb,CUME_DIST() OVER(ORDER BY quantityordered) AS pct,PERCENT_RANK() OVER(ORDER BY quantityordered) AS pct_rank
FROM mysqldemo.orderdetails
WHERE productcode = 'S18_2949';
7. FIRST_VALUE
样例:获取客户首单订单金额。
SELECT customernumber,amount,paymentDate,FIRST_VALUE (amount) OVER (PARTITION BY customernumber ORDER BY paymentDate) AS first_amount
FROM payments
ORDER BY customernumber;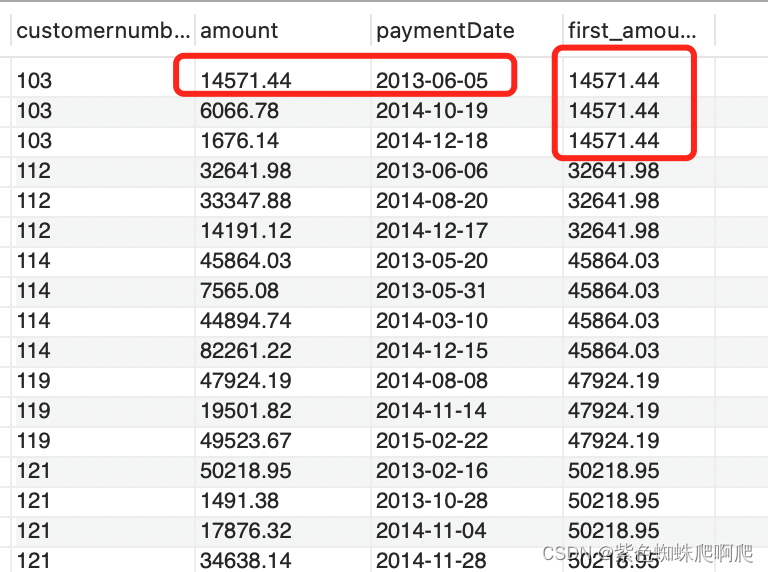
8. Last_Value
样例:获取客户最后一笔订单金额。
注意:Last_Value 和 First_Value 不同, 他认为每一行,是当前行中的最后一行。注意对比下面两个字段的不同。
SELECT customernumber, amount, paymentDate,last_value (amount) OVER (PARTITION BY customernumber ORDER BY paymentDate) AS last_amount,last_value (amount) OVER (PARTITION BY customernumber ORDER BY paymentDate RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_amount_umbounded
FROM payments
ORDER BY customernumber;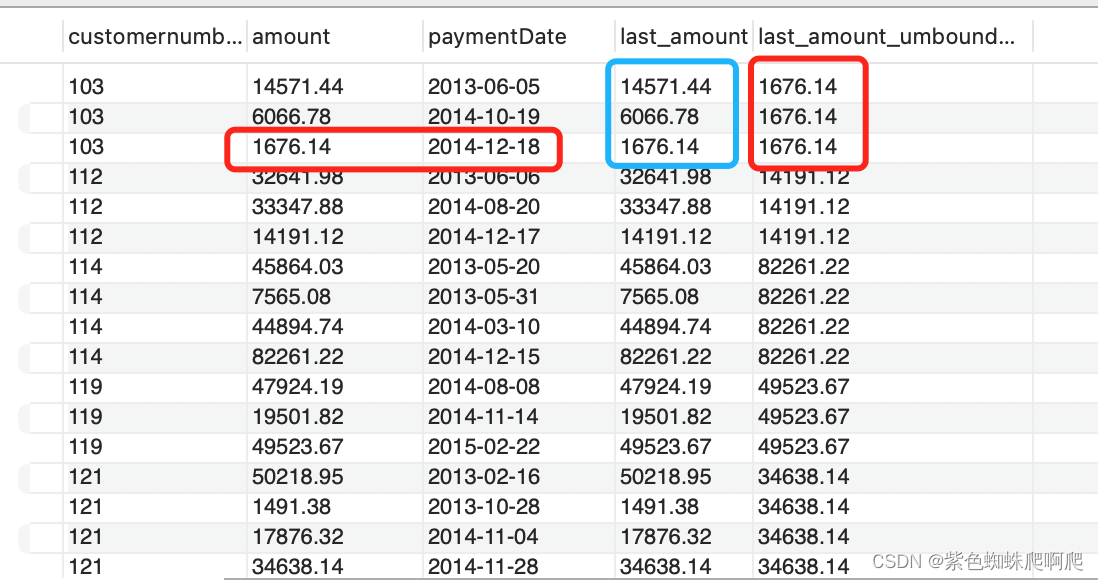
8. Lead和Lag
函数类似,是查询某一字段的从当前行往后找到第N行的数据(Lead)和往前找到第N行的数据(Lag)。在找到某一行的偏移n行的数据非常有用。
lead/lag(expression, offffset, default) over(partion by ......order by ......)
- expression 要取的是哪一个字段
- offset 是从当前行前进(lead)/后退(lag)的行数。 必须是一个非负整数,为零则取当前行。
- default 如果没有后续行,则函数返回default。例如,如果offset是1,则lead的最后一行,lag的第一行的返回值为default。 未指定default_value,则返回 NULL 。
样例: 查询出上一个订单,下一个订单的时间
SELECT customerName,orderDate,LEAD(orderDate,1) OVER (PARTITION BY customerNumber ORDER BY orderDate ) nextOrderDate,LAG(orderDate,1) OVER (PARTITION BY customerNumber ORDER BY orderDate ) PreviousOrderDate
FROM orders
INNER JOIN customers USING (customerNumber); 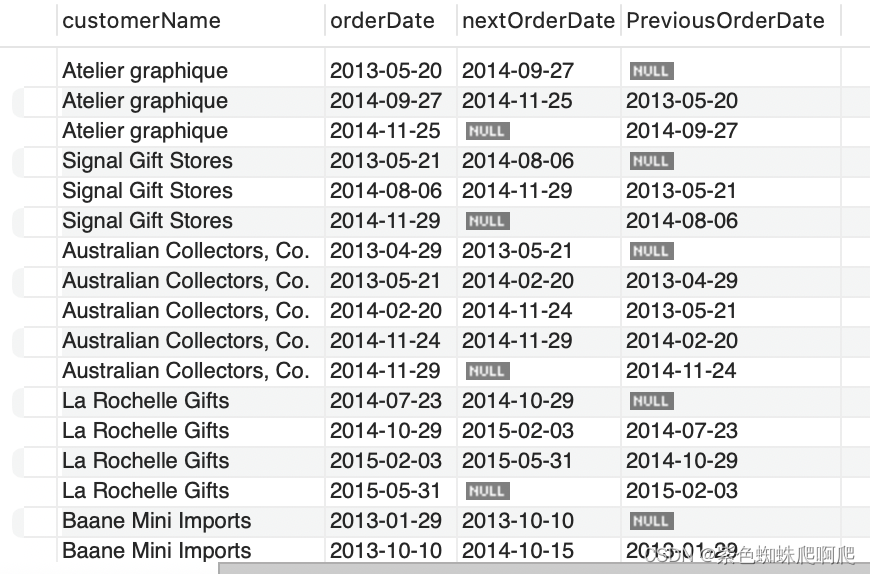
样例:查询出下单时间间隔最长的用户。
SELECT customerName, MAX(orderdate_interval) AS MAX_interval, RANK() OVER(ORDER BY MAX(orderdate_interval) DESC) AS data_rank
FROM(SELECT customerName,orderDate,LEAD(orderDate,1) OVER (PARTITION BY customerNumber ORDER BY orderDate ) nextOrderDate,datediff(LEAD(orderDate,1) OVER (PARTITION BY customerNumber ORDER BY orderDate), orderDate) orderdate_intervalFROM ordersINNER JOIN customers USING (customerNumber)) T1
WHERE nextOrderDate IS NOT NULL
GROUP BY customerName; 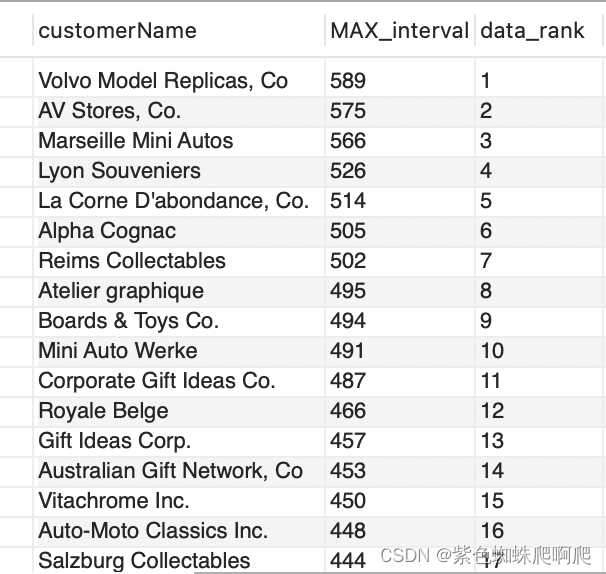
9. NTILE 平均分组
样例:将产品线按照年份,汇总订单金额,并且划分为三个组。
注意不能平均分配时,例如将9行数据分成4个组,他会把第1组分3个,剩余3个组每个组2个;
SELECTproductline, orderYear, orderValue,NTILE(3) OVER (PARTITION BY orderYear ORDER BY orderValue DESC) product_line_group
FROM productlineSales; 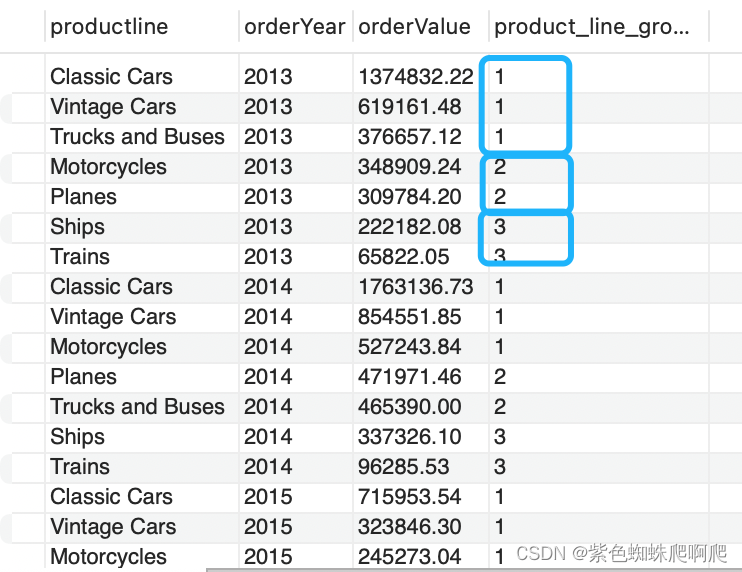
样例: 查询出2013支付金额排名前30%的所有用户
SELECT customerNumber, pay_amount, level
FROM (SELECT customerNumber, SUM(amount) AS pay_amount,NTILE(10) OVER(ORDER BY SUM(amount) DESC) AS levelFROM mysqldemo.paymentsWHERE Year(paymentDate) = 2013GROUP BY customerNumber)a
WHERE level in (1,2,3);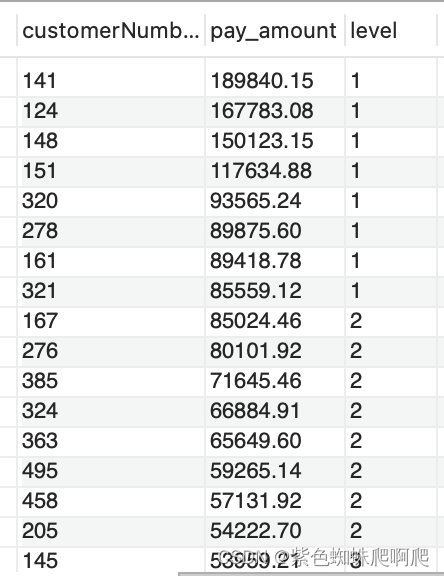
通过这种方法计算出来的百分比不准确,通过下面的SQL,会发现前3个组的人数超过了30%。
SELECT COUNT(customerNumber), level
FROM (SELECT customerNumber, SUM(amount) AS pay_amount,NTILE(10) OVER(ORDER BY SUM(amount) DESC) AS levelFROM mysqldemo.paymentsWHERE Year(paymentDate) = 2013GROUP BY customerNumber)a
GROUP BY level;
使用用 CUME_DIST 效果更好。
SELECT customerNumber, pay_amount, level, pct
FROM (SELECT customerNumber, SUM(amount) AS pay_amount,NTILE(10) OVER(ORDER BY SUM(amount) DESC) AS level,CUME_DIST() over(order by SUM(amount) desc) as pctFROM mysqldemo.paymentsWHERE Year(paymentDate) = 2013GROUP BY customerNumber)a 直接定位带排序小于等于30%的即可。从结果可以看出,和NTILE不一样,第三组的人没有全部都取。
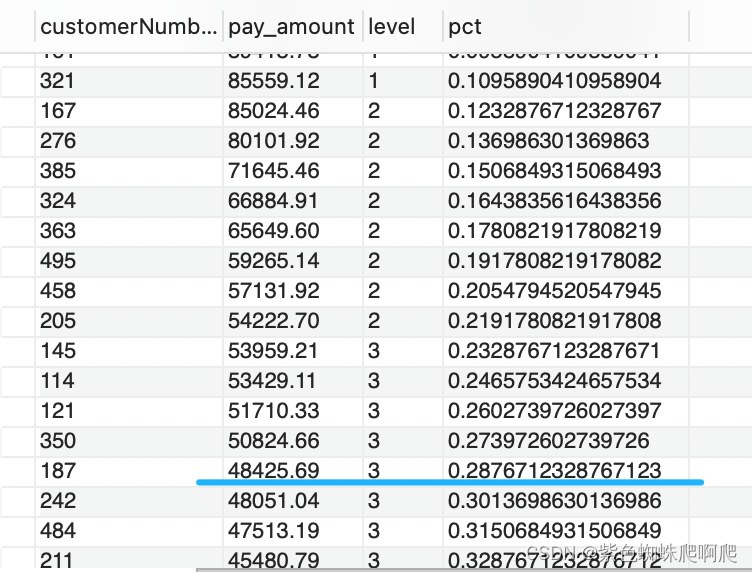
10. NTH_VALUE
函数格式为:
NTH_VALUE(expression, N)
OVER (partition_clauseorder_clauseframe_clause) 从有序行集中的第N行获取值;如果第N行不存在,则函数返回NULL;N必须是正整数。
注意:From First(标准SQL 支持 From Last, MySQL只支持From First。如果要模拟效果From Last,则可以使用其中ORDER BY倒叙排列)
样例:2015年每月购买金额第三的人
SELECT paymentmonth,customernumber, amount,
NTH_VALUE(customernumber, 3) OVER(PARTITION BY paymentmonth ORDER BY amount DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS NTH
FROM (SELECT MONTH(paymentDate) AS paymentmonth, customernumber, SUM(amount) amountFROM paymentsWHERE YEAR(paymentDate) = 2015GROUP BY customernumber, paymentmonth) T1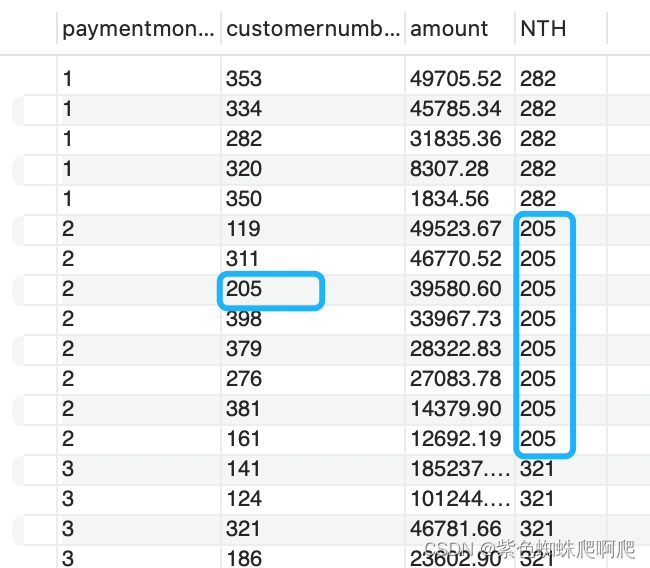
11. 测试:查询出每年连续下单的客户和连续的年份
方法1
使用 lag 取上一年的年份,计算差值是1的,就是这两年是连续的;然后对customerName进行group by。
SELECT customerName, max(orderYear), min(previousYear), SUM(gap)+1
FROM (SELECT customerName, orderYear, lag(orderYear) over(partition by customerName order by orderYear) AS previousYear,orderYear - lag(orderYear) over(partition by customerName order by orderYear) gapFROM (SELECT customerName,YEAR(orderDate) AS orderYearFROM ordersINNER JOIN customers USING (customerNumber)GROUP BY customerName, orderYear ) T1) T2
WHERE gap =1
GROUP BY customerName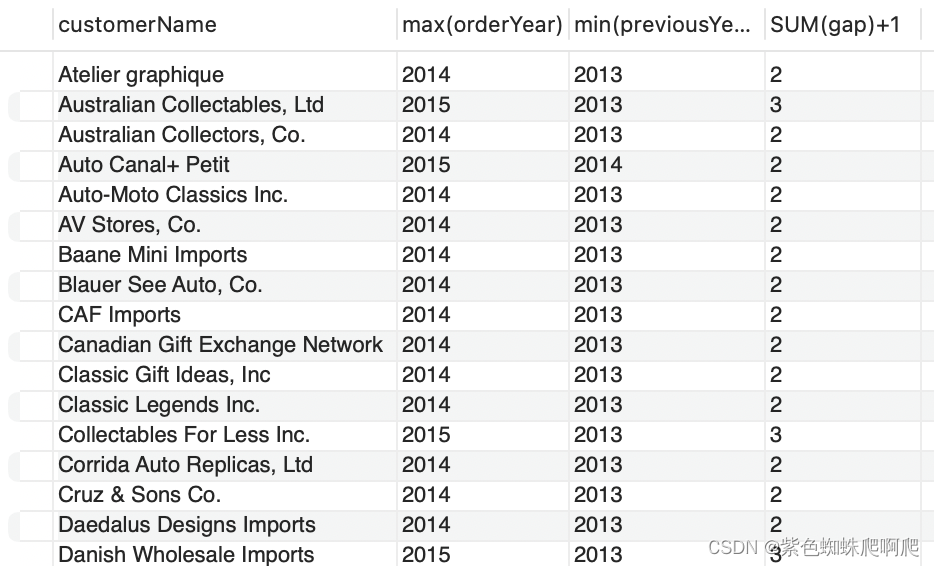
方法2
用Year 减去row_number, 取得gap,gap相同的,就是年份连续的。
SELECT customerName, minYear, maxYear, max(nb)
FROM (SELECT customerName,gap,orderYear, min(orderYear) OVER (partition by customerName,gap ORDER BY customerName,gap) minYear, max(orderYear)OVER (partition by customerName,gap ORDER BY customerName,gap) maxYear,ROW_NUMBER() OVER (partition by customerName,gap ORDER BY customerName,gap) nbFROM(SELECT customerName, orderYear, orderYear-nbbycustomer as gapFROM (SELECT customerName,YEAR(orderDate) AS orderYear,ROW_NUMBER() OVER (PARTITION BY customerName ORDER BY YEAR(orderDate)) nbbycustomerFROM ordersINNER JOIN customers USING (customerNumber)GROUP BY customerName,orderYear)T1) T2
) T3
WHERE minYear <> maxYear
GROUP BY customerName, minYear, maxYear;12. 其它有趣的函数
使用rand() 获取随机10行数据。
select * from customers order by rand() limit 10;这篇关于MySQL 窗口函数温故知新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





