本文主要是介绍[MySQL]可重复读下的幻读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、幻读的定义
根据MySQL官网的描述,幻读是“相同的查询在不同时间返回了不同的结果”
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times.
同时官网还举例说明了,如:两次查询中,后一次多出来的行就是所谓的“幻影行”
For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
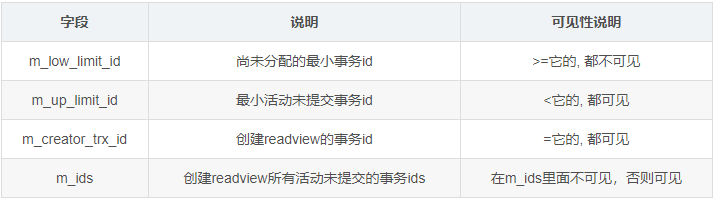
了解Innodb的同学应该十分眼熟下面这张图,图里介绍了各个隔离级别下的一致性问题。

得益于MVCC机制,可重复读级别(RR)下依赖一份不更新的Read View使之后提交事务的修改对当前事务不可见,解决了脏读和不可重复读问题。
不知你是否会和我有一样的疑问:
“既然RR实现了可重复读,按理已经屏蔽了其他事务的修改。但为什么还是会受其他事务影响产生幻读的问题?”
“RR下幻读是否真实存在?”
“幻读到底长什么样?”
如果你也和我一样有上述疑问,很好!接下来我们将一起探寻幻读的真相。
二、寻找幻读
秉持着“先问是不是,再问为什么”的理念,我们得先证明幻读在RR下是存在的。
为了制造幻读,先简单准备了一张'test_lock'表:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for test_lock
-- ----------------------------
DROP TABLE IF EXISTS `test_lock`;
CREATE TABLE `test_lock` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) NOT NULL,`b` int(11) NOT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `a`(`a`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 26 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of test_lock
-- ----------------------------
INSERT INTO `test_lock` VALUES (1, 1, 1);
INSERT INTO `test_lock` VALUES (5, 5, 5);
INSERT INTO `test_lock` VALUES (10, 10, 10);
INSERT INTO `test_lock` VALUES (15, 15, 15);SET FOREIGN_KEY_CHECKS = 1;
确认RR隔离级别后,开始编写事务, 着手制造幻读:
| 事务A | 事务B | |
|---|---|---|
| 1 | begin; | |
| 2 | SELECT * FROM `test_lock` WHERE a<10; | |
| 3 | begin; | |
| 4 | INSERT INTO test_lock VALUES(6,6,6); | |
| 5 | commit; | |
| 6 | (待输入) |
在“待输入”处应该要执行什么语句才能复现幻读呢?尝试执行select for update:
SELECT * FROM `test_lock` WHERE a<10 for UPDATE;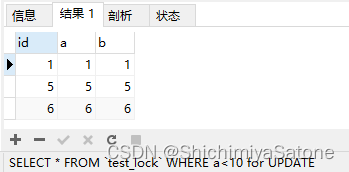
使用当前读(Locking Read)确实看到了刚刚插入的 (6, 6, 6) ,但这是幻读吗?
根据官方的定义,幻读发生在相同的查询,返回不同的结果。
实验中 select 和 select for update ,一个是快照读(Consistent Nonlocking Reads),一个是当前读(Locking Read),明显不符合“same query”的要求。
那既然select for update已经能看到插入了,在后面再执行一遍原来的快照读,是否就能符合要求了呢?
| 事务A | 事务B | |
|---|---|---|
| 1 | begin; | |
| 2 | SELECT * FROM `test_lock` WHERE a<10; | |
| 3 | begin; | |
| 4 | INSERT INTO test_lock VALUES(6,6,6); | |
| 5 | commit; | |
| 6 | SELECT * FROM `test_lock` WHERE a<10 for UPDATE; | |
| 7 | SELECT * FROM `test_lock` WHERE a<10; |


神奇的现象发生了,在select for update中可见的 (6, 6, 6) 又不见了。
这样一来,虽然满足了“same query”的要求,但又不满足“different sets of rows”了。
要想理解刚刚这种现象,需要回到RR的本质————“不更新的Read View”
-
前后两次快照读,因为Read View没有更新,所以没有任何差别
-
当前读使用了最新的Read View,看见了插入,但并没有更新事务里的read view副本。
至此,这种忽隐忽现的“伪幻读”已经解释清楚了。
三、发现幻读
既然RR下的Read View是不更新的,那事务A要如何看到事务B的插入呢?
进行两次当前读?很明显不行,由于间隙锁(Gap Lock)的存在,事务B无法在事务A锁定的区间进行插入。插入都被阻塞了,还谈什么返回结果不同。
那还有别的办法吗?有!

这次我们成功地看到了幻读的发生,同时符合相同查询和相同结果两个定义。
根据MySQL执行修改的流程,事务A在执行修改时,先使用当前读将数据读入缓冲池(Buffer Pool),再将修改应用到内存。

正是这样的先加载后更新的操作,让事务A看到自身更新的同时,也看到了事务B的插入,导致幻读发生。
四、解决幻读
幻读发生的条件较为苛刻,多数情况下是触发不了的。
但如果发生,我们可以使用当前读对区间上间隙锁,阻塞插入的发生,从而规避幻读。
还记得刚刚讨论方案时说的吗,用的就是这种方法:
既然RR下的Read View是不更新的,那事务A要如何看到事务B的插入呢?
进行两次当前读?很明显不行,由于间隙锁(Gap Lock)的存在,事务B无法在事务A锁定的区间进行插入。插入都被阻塞了,还谈什么返回结果不同。
具体上锁的方式分为两种:
- SELECT ... FOR SHARE
- SELECT ... FOR UPDATE
根据检索条件和具体行数据的不同,间隙锁可能与行锁(Record Lock)结合,生成临键锁(Next Key Lock)。与间隙锁一样,生成的临键锁也可阻塞其他事务的修改。三者的关系为:
- 行锁:对唯一索引进行等值查询且命中
- 间隙锁:进行等值查询未命中
- 临键锁:(剩余查询条件)
需要注意的是,间隙锁是种特殊的锁,相同的间隙锁是共享的,并不是互斥的。
这种共享将可能导致死锁的发生,如:
| 事务A | 事务B | |
|---|---|---|
| 1 | begin; | |
| 2 | SELECT * FROM `test_lock` WHERE a=3 FOR UPDATE; | |
| 3 | # 锁定区间(1, 5) | |
| 4 | begin; | |
| 5 | SELECT * FROM `test_lock` WHERE a=4 FOR UPDATE; | |
| 6 | # 锁定区间(1, 5) | |
| 7 | INSERT INTO test_lock VALUES(3, 3, 3); | |
| 8 | # 发生阻塞,等待事务B释放间隙锁 | |
| 9 | INSERT INTO test_lock VALUES(4, 4, 4); | |
| 10 | # 发生死锁 |

五、总结
至此,我们给出了幻读的定义、重现了幻读、提供了解决方案、讨论了死锁的条件。
RR下存在幻读,可以使用间隙锁避免。
参考:
MySQL 8.0 Reference Manual
Innodb MVCC源码实现—— xpchild
这篇关于[MySQL]可重复读下的幻读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






