本文主要是介绍来看看投资界最关心的 Sora 几大问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:苍何,前大厂高级 Java 工程师,阿里云专家博主,CSDN 2023 年 实力新星,土木转码,现任部门技术 leader,专注于互联网技术分享,职场经验分享。
🔥热门文章推荐:
- (1)对程序员来说,技术能力和业务逻辑哪个更重要?
- (2)搭建GitHub免费个人网站(详细教程)
- (3)itchat实现微信聊天机器人
- (4)嗖嗖移动业务大厅(源码下载+注释全 值得收藏)

大家好,我是苍何。因为 Sora 的大火,最近一直在研究 Sora 的技术报告,也翻阅了不少论文和技术文稿,结合最近接受的咨询公司的付费采访,给大家做一些分享。
首先,要告诉大家的是,虽说 Sora 火的一塌糊涂,但这玩意现在能用的人屈指可数,大部分的视频都来自官方及个别内测人员,所以,要小心那些假借 Sora 之名割韭菜的卖课程的人。其次,现在对例如 DIT 和 LDM 技术深入了解的很少,要想深入学习,还是要自己多去翻翻论文和技术报告。
下面分享投资界最关心的 Sora 的几大问题,以下仅为个人观点,不构成任何投资建议。
Sora 是否可以理解成就是Latent Diffusion Model (LDM) 加上 Diffusion Transformer (DiT)?
Sora 确实可以被理解为Latent Diffusion Model (LDM)与Diffusion Transformer (DiT)的结合。DiT是一种新型的扩散模型,通过替换常用的U-Net背骨网络为在潜在补丁上操作的变压器(Transformer),从而训练潜在扩散模型。这种模型的关键特点是它们通过增加变压器的深度/宽度或输入令牌的数量来提高Gflops,这通常会导致更低的FID(Frechet Inception Distance),从而在图像生成的质量上取得了显著的进步。DiT模型在ImageNet的类条件基准上超越了以往所有的扩散模型,实现了前所未有的图像质量。
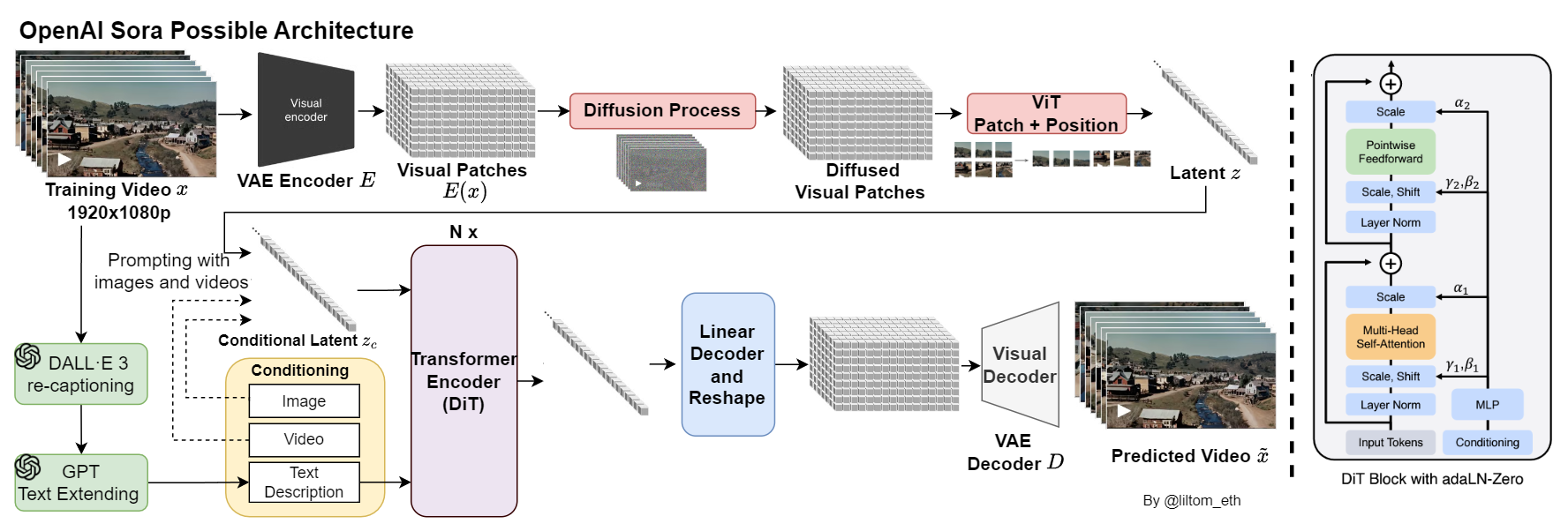
Sora作为一个文本到视频的模型,采用了类似的技术,但进一步扩展到视频生成领域。Sora利用了扩散模型和变压器架构的组合,通过统一表示、基于补丁的表示、视频压缩网络和扩散变压器等方法,使用户能够将文本描述转换为高清视频片段。Sora 的能力不仅限于图像和视频提示,还包括DALL·E图像动画、视频扩展、编辑、图像生成等。尽管Sora在模拟复杂空间和理解因果关系方面存在一些局限性,但它在安全措施方面强调了红队测试、内容检测和与利益相关者的互动。
因此,虽然Sora并没有采用全新的技术,但它在现有技术基础上进行了创新和优化,特别是将LDM和DiT结合到视频生成领域,实现了文本到视频的高质量转换。这表明Sora是在现有技术的基础上,通过结合和优化这些技术,来达到在视频生成方面的突破。
可扩展性是DiT(diffusion transformer)论文的核心主题, 能否简单帮我们理解它的原理及优势?
DiT(Diffusion Transformer)的核心优势在于其可扩展性,它通过利用Transformer架构来训练潜在扩散模型(Latent Diffusion Models, LDMs),替换了传统的U-Net骨架。这种方法的关键在于它能够根据前向传递的复杂度(以Gflops衡量)分析模型的可扩展性,发现那些具有更高Gflops的DiT模型——通过增加Transformer的深度/宽度或输入令牌的数量——能够一致地实现更低的FID(Frechet Inception Distance),这意味着它们能够生成更高质量的图像和视频。
它在图像和视频生成中引入了变压器(Transformer)的概念,这种变化让DiT在处理复杂数据时更加高效和灵活。与传统的U-Net架构不同,Transformer不依赖于数据的顺序,这意味着它可以更自由地处理和生成图像和视频内容。
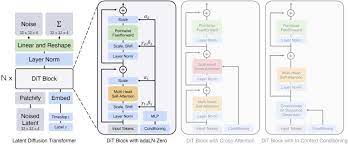
想象一下,我们有一个乱涂乱画的草稿本,这个草稿本就像是一段充满噪声的视频或图像。我们的目标是根据一段描述,比如“一只猫坐在窗台上看日落”,将这个乱涂乱画的草稿本变成一幅精美的画作或一段生动的视频。DiT技术就像是一个有魔法的画笔,它能够逐步清除噪声,最终根据给定的描述生成我们想要的内容。

Sora则是在DiT的基础上进一步发展,专门用于生成视频内容。它不仅继承了DiT处理图像的能力,还能处理时间维度,使得生成的视频不仅画面质量高,而且动作流畅自然。Sora通过视频的3D位置生成位置编码,这一创新打破了传统二维图像生成的限制,让Sora能够理解和生成具有时间维度的视频内容。
这个生成过程并非一步到位,而是通过数百个渐进式的步骤完成的,每一步都让视频内容更加接近最终目标。这种方法不仅增加了生成内容的灵活性和创造性,而且还能确保最终生成的视频与文本提示高度一致,无论是再现真实场景还是创造幻想世界,Sora都能依据文本提示“涂改”出令人惊叹的视觉作品。
总的来说,DiT和Sora代表了AI在图像和视频生成领域的一大步进。通过将Transformer技术应用于扩散模型,它们不仅提高了生成内容的质量,还拓宽了AI创作的可能性,让我们能够将抽象的文字描述转化为具体且生动的视觉内容。
视频压缩网络的工作逻辑?
想象你在整理一间乱糟糟的房间,目标是让一切井井有条,而且日后想找什么东西都能手到擒来。你会怎么做呢?可能会把小东西放进小盒子里,再把这些小盒子统统放进一个大箱子里。这样,用更少的空间,更有条理地存放了同样多的东西。视频压缩就是用类似的办法工作的。它把视频内容“清理和整理”得更紧凑、更高效,就像把一间乱室变成了一个整洁的储物间。这样做的好处是,Sora处理视频时会更快,但同时还能保留重建原始视频所需的所有关键信息。

工作逻辑
- 预处理:视频首先被分割成帧,每帧可以进一步被分割成较小的块或patches。这有助于处理视频的局部特征,并减少处理整帧所需的计算资源。
- 转换和量化:通过转换(如离散余弦变换DCT)将这些块的像素值转换成频率领域,然后通过量化过程减少这些频率值的精度,以减少所需的数据位数。
- 编码:利用视频内容的时间和空间冗余,通过编码算法(如H.264, H.265)压缩这些量化后的数据。编码过程可能包括预测编码、变换编码和熵编码等步骤。
- 解码:压缩后的视频在播放前需要被解码,解码过程是编码过程的逆过程,它将压缩的数据转换回视频帧。
有效将其分块(patches)的核心难点在于算法还是?
将视频有效地分块的核心难点主要在于算法和计算资源的平衡:
- 算法难点:需要智能地确定如何分块以最大化压缩效率,同时保留视频的重要特征。这包括决定块的大小、形状和如何处理帧间的相关性。
- 计算资源:视频分块和压缩过程需要大量计算资源,特别是对于高分辨率和高帧率的视频。优化算法以减少计算需求,同时保持高压缩率和视频质量是一个挑战。
碎片Patch已经被证明是一个有效的视觉数据表征模型,且高度可扩展表征不同类型的视频和图像。将视频压缩到一个低维的潜变量空间,然后将其拆解为时空碎片Spacetime Latent Patches
被用于从高维的时空碎片张成的空间中,观察并提取丰富的时空碎片之间的关联与演化的动态过程。如果把前者对应人类读书,后者就是人类的视觉观察。
四维时空模型(x,y,z,t),关键是如何提取出关键信息,
想象你在拼图,每一块都是一幕幕小故事的片段,既有画面也有随时间变化的动作。这就像Sora处理视频的方式。首先,它把视频不只是看成一连串的画面,而是把这些画面分成了很多小块,我们叫它“空间时间补丁”。这些小块就像是视频故事的微缩版,既展示了某个瞬间的景象,又记录了时间的流逝,比如一个苹果从桌子上滚落的整个过程。

这个方法起源于处理静态图片的技巧——将图片切成小片来更高效地分析和理解。当我们把这种做法应用到视频上时,就意味着我们不仅仅关注每一帧图像的细节,还要关注这些细节随着时间如何变化。就好比你正在看一本连环画,每翻一页都是故事的一个瞬间,连起来就讲述了一个完整的故事。
通过把视频拆解成这样的“空间时间补丁”,Sora就能够更精细地理解和处理视频中的每一个动作和变化,就像是用放大镜观察每一块拼图片,既看到了片段的细节,也把握了整体故事的流动。这种方式让Sora在创造或编辑视频时,能够更准确地捕捉和再现复杂的视觉内容和动态变化。
针对不同的输入, 压缩率的调节难度在于?(视频压缩网络类比与latent diffusion model中的VAE,但是压缩率是多少,如何保证视频特征被更好的保留,还需要进一步的研究)?
关于视频压缩网络,Sora可能采用的就是VAE架构,区别就是经过原始视频数据训练。
而由于VAE是一个ConvNet,所以DiT从技术上来说是一个混合模型。
压缩率的调节难度在于平衡压缩率和视频质量的关系:
- 视频质量保留:如何在高压缩率的同时保留视频的关键特征和质量是一个挑战。这涉及到复杂的算法,如运动估计和补偿、高效的量化策略,以及智能的编码决策。
- 针对不同输入的适应性:不同视频内容(如静态场景vs.快速运动)和不同视频类型(如电影vs.直播)可能需要不同的压缩策略。自动调整压缩参数以适应不同内容的能力是提高压缩效率的关键。
- 类比于VAE:在latent diffusion model中使用的VAE(变分自编码器)可以通过调整潜在空间的维度来控制压缩率。视频压缩网络面临的挑战是找到一种方法来调节压缩率,同时确保重要的视频特征被有效保留,这可能需要通过训练数据学习特定于视频的表示。
长视频(60秒) VS 短视频(5-6秒)生成对模型要求的差距? (可能是通过允许自回归采样的联合帧预测来实现的,但一个主要挑战是如何解决误差积累并保持质量/一致性)
长视频与短视频生成在技术实现和模型要求上存在显著差异,这些差异主要涉及到模型的设计、训练过程、以及如何在生成过程中管理和减少误差积累。以下是几个关键方面,用来解释这些差距:
时间依赖性和一致性
- 短视频:对于短视频生成,模型需要捕捉较短时间序列内的动态和变化,这意味着时间依赖性相对较小。因此,保持视频开始到结束的一致性相对容易。
- 长视频:长视频生成涉及到更长时间序列的处理,需要模型具有更强的时间依赖性捕捉能力。随着视频长度的增加,如何保持场景、风格和叙事的一致性,同时避免误差积累成为一个更大的挑战。
模型复杂性和计算需求
- 短视频:生成短视频的模型可能不需要处理极其复杂的场景变化,因此模型复杂性和计算需求可以相对较低。
- 长视频:长视频生成需要模型能够处理和记住更长时间内的信息,这通常意味着更高的模型复杂性和更大的计算需求。长视频中的每一帧都必须考虑到前文的上下文,以保持叙事和视觉的连贯性。
误差积累和质量控制
- 短视频:在短视频生成中,即使存在一定的误差,其对整体视频质量的影响也相对较小。因此,简单的质量控制措施可能就足够了。
- 长视频:长视频生成中,误差可能会随着时间的推移而积累,导致视频的后半部分出现显著的质量下降或内容偏差。因此,需要采用更先进的技术来监控和纠正这些误差,例如通过增强模型的自回归能力、使用条件限制或引入额外的一致性损失函数。
训练数据和过拟合问题
- 短视频:短视频生成模型的训练可能需要相对较少的数据,且模型较容易在有限的数据上学习到有效的表示。
- 长视频:长视频生成模型需要大量的、多样化的训练数据来学习如何在较长时间序列上保持内容的连贯性和一致性。此外,长视频生成模型更容易遇到过拟合问题,因为模型需要在更复杂的数据分布上泛化。
解决方案
针对长视频生成中的误差积累问题,研究者们探索了多种技术,如:
- 条件生成:使用先前帧的信息作为条件输入,帮助模型生成一致的后续帧。
- 注意力机制:利用注意力模型捕捉长期依赖,帮助减少误差积累。
- 一致性损失:引入额外的损失函数,以确保视频在视觉和内容上的连贯性和一致性。
- 自回归模型:通过自回归采样生成视频帧,逐步提高生成内容的质量和一致性。
对模型多模态的要求极高是否理解是一直以来其它软件商无法突破时长的核心?
对模型多模态的高要求确实是许多组织面临的一个挑战,原因如下:
- 复杂性增加:多模态学习涉及到不同类型数据的处理和融合,这增加了模型的复杂性。模型需要能够理解和利用不同模态之间的关系,这在技术上更加困难。
- 数据和标注挑战:获取大规模、高质量且跨多模态的训练数据集是一个挑战。此外,这些数据集需要准确的标注,这在多模态场景下尤为复杂和成本高昂。
- 计算资源要求:扩展的Transformer模型需要巨大的计算资源进行训练,这对于很多组织来说是一个限制因素。
- 研发投入:成功开发和训练大规模多模态Transformer模型需要前沿的研究和大量的研发投入,这可能超出了许多软件商的能力范围。
Sora与UE5的差异理解? (UE5是手工制作和精确的,而Sora则是通过数据和“直观”完全学习的)
了解到Sora是一种先进的视频生成技术,其工作原理类似于扩散模型,这为我们提供了更清晰的对比视角。Sora和UE5在设计理念、技术实现以及目标应用场景上存在显著差异。
Sora(基于扩散过程的视频生成技术)
- 基于扩散的生成过程:Sora从看似随机噪声的状态开始,通过多个迭代步骤逐渐去除噪声,最终生成清晰的视频内容。这种方法依赖于对视频数据的深入学习,通过逆向模拟噪声添加过程来重建视频。
- 数据驱动和学习为本:Sora利用大量数据来训练其生成模型,依赖于机器学习(尤其是深度学习)技术来“理解”视频内容的结构和动态。这种方法更注重于从数据中自动学习和提取特征,而不是依赖于人工设计的规则。
- 创新和自动生成:Sora的强项在于能够自动生成视频内容,这对于需要大量视频数据但资源有限的场景(如虚拟现实、游戏测试场景生成等)尤其有价值。
UE5(Unreal Engine 5)
- 手工制作和精确控制:UE5提供了丰富的工具和功能,让艺术家和开发者能够精确地手工制作游戏和虚拟环境中的每一个细节。从精细的模型到复杂的光照效果,UE5旨在提供尽可能真实的视觉体验。
- 实时渲染技术:UE5搭载了Nanite虚拟化几何技术和Lumen全局光照技术,使得在游戏和实时渲染应用中能够实现高度真实的视觉效果,同时优化性能。
- 广泛的应用领域:UE5不仅适用于游戏开发,也被广泛用于电影制作、建筑可视化、模拟训练等领域,支持高度定制化的创作和开发流程。
差异总结
- 生成方法:Sora基于数据和机器学习算法自动生成视频内容,而UE5侧重于提供工具和环境,供开发者和艺术家手工制作和精确控制内容。
- 技术依赖:Sora依赖于深度学习和扩散模型技术,UE5则依赖于传统的游戏和渲染技术,结合最新的图形和渲染改进。
- 目标应用:Sora更适合于自动生成和探索新内容的场景,UE5则更适合于需要高度定制和实时交互的高质量视觉表现领域。
- 用户角色:Sora的用户可能更多关注于模型训练和数据准备,UE5的用户则更专注于艺术创作和技术实现的细节。
对于长视频生成推理,一定是需要更大的VRAM或者带宽,因此需求推理的算力并行也就是网络通信能力要求会更高,您怎么看这个观点,可以通俗易懂的为我们讲解一下么?
想象一下,Sora把视频和图片切成了一堆小方块,就像拼图一样。这些小方块被叫做时空碎片,它们像变形金刚一样可以组合成各种形状和大小的视频,不管视频是长是短,是方是圆。在Sora的世界里,这些小方块就像乐高积木一样,可以自由组合,让Sora学习和生成各种不同的视频和图片。
当Sora要创建一个视频时,就像你在玩拼图游戏,随机拿出几块来摆在一起,试图拼出想要的画面。这里的挑战是让这些小方块能够顺畅地"交流",就好比确保所有玩具列车的轨道都连接好,火车能顺畅运行一样。这就是为什么网络的“通信”非常重要,特别是在让这些碎片并行工作,即同时进行多项任务时。

那么,为什么Sora对网络带宽的需求比对计算能力的需求还要大呢?这涉及到几个方面:
- 处理海量数据:Sora需要分析和处理大量数据,尤其是在学习阶段。想象一下你在网上看视频,如果网速慢,视频就会卡顿。同样地,Sora在处理数据时,如果没有足够快的带宽来支持数据的快速流动,它的学习和生成过程也会变慢。
- 实时生成:如果Sora被用来即时创造视频,比如直播时加入特效,那么它生成内容的速度就必须跟得上实时播放的速度。这不仅仅需要强大的计算能力,还需要高速的网络来确保视频内容能够迅速传达给观众。
- 分布式工作:Sora可能会在多台机器上同时工作来处理复杂的任务,这就好比一个团队同时在不同地方工作,需要通过网络紧密协作。如果网络带宽不够,就好比团队沟通不畅,会影响整个项目的进展。
- 内容分发:制作出来的视频需要发送给世界各地的用户。随着视频质量的提高和用户对观看体验要求的提升,快速有效地分发视频内容也越来越依赖高速网络。
简单来说,Sora就像是一个需要快速传输大量数据的超级工厂,不仅自己要快速高效地工作,还要确保制作出的产品能够迅速送达消费者手中。这就是为什么它对网络带宽的需求往往超过了对计算能力的需求。
您怎麽看Sora 参数规模 (DiT算力消耗可能并不像大家想的那么高,DiT XL/2 需要的算力是 B/2 模型的 5 倍 GFLOPs,因此最终的 16X 计算模型可能是 DiT-XL 模型的 3 倍,这意味着 Sora的参数量可能在大约3B)? 想请您就这个推论帮我们展开白话理解一下
通过视频压缩网络和时空切片技术,将算力消耗进行分布化,算力并行,利用多个计算节点共同完成工作。这种方法提高了算力利用率,但同时也大幅增加了节点间数据同步和交换的需求,进一步提升了对高带宽的依赖。 所以DiT算力消耗可能并不像大家想的那么高,Sora可能还真并不需要人们想象中的那么多GPU来训练
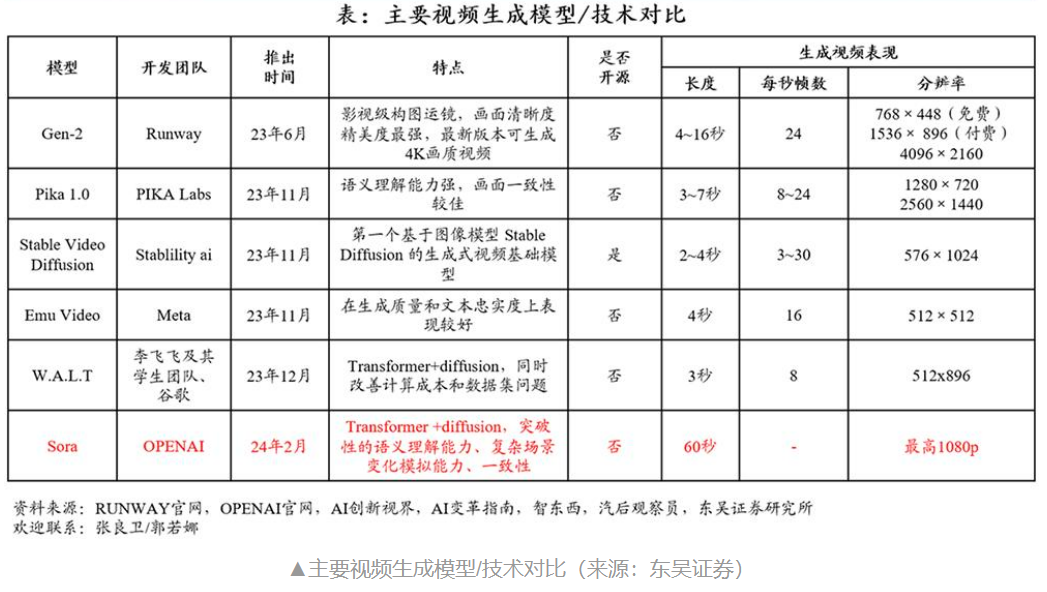
为什么Runway跟sora是一个技术路线,但没有办法做到sora这么好?
首先,Sora能够生成相对较长的视频片段,这些片段不仅长度更长,而且在视觉质量和遵循用户提示方面表现得更好。这得益于Sora背后的高级深度学习模型和算法,它们优化了从文本到视频的生成过程,使得Sora能够更好地捕捉和实现复杂的视觉故事。
相比之下,Runway作为一个提供多种AI创意工具的平台,虽然也能从文本或图像生成视频,但它生成的视频通常更短,可能没有Sora那么高的视觉质量或丰富的细节。这可能是因为Runway在多功能性和用户友好性方面做了平衡,以适应更广泛的创意需求,而可能没有像Sora那样深入优化特定的文本到视频生成过程。
此外,Sora在处理和生成视频时采用了更先进的 DIT 技术,,这些都是专门为了提高视频生成的质量和效率。而Runway更侧重于提供一个灵活的平台,让用户能够探索和使用多种AI工具,包括视频生成,但可能没有对任何单一功能进行深度的技术优化。
您怎麽看待未来短视频模型竞争格局?
Sora为什么这么厉害?主要有三大秘密。首先,Sora懂得在时间上做文章,意味着它可以压缩和处理时间信息,所以能制作出长达一分钟的视频。其次,Sora用了一种叫做DiT的技巧,这个技术不仅打破了视频长度和尺寸的界限,还发挥了Transformer技术的强大能力,让制作一个大型视频生成模型成为可能。
最后但同样重要的,是Sora背后的视频标注能力。就像之前的Stable Diffusion模型因为有CLIP这样一个能链接图片和文字的模型,加上大量有标注的图片而大放异彩一样,视频生成也面临着类似的挑战:视频数据不仅少,有标注的视频更是难得一见。但如果有个标注工具能够深刻理解视频内容,并能生成详细的视频标注,那么它就能帮助视频生成模型更好地理解复杂的文本描述,这正是Sora成功的关键之一。简单说,Sora就像是个懂电影的聪明制片人,不仅知道怎么拍好电影,还懂得如何让电影讲好故事。
短视频模型竞争一定会围绕着 3D 一致性,长视频连贯性,与世界的交互、模拟数字世界等方向发展,将会有更多的厂商学习新颖的 DiT 用法用到自己的模型中。

未来已来,Sora 掀起的是一轮新的技术浪潮,而我们普通人,更需要好好的学习这些新的 AI 工具,否则等到哪天,被 AI 取代了,我们还一脸懵逼。
如果你也对 AI 感兴趣,欢迎你关注苍何,加入我的免费星球,一同通过 AI 提效让我们成长的更快:https://t.zsxq.com/1771Yxf33

创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

这篇关于来看看投资界最关心的 Sora 几大问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







