本文主要是介绍python xlrd xlwt pandas openxyl导入方法对比 N/A,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
操作目的:
通过对比两个EXCEL表格 对比数据 相同部分和不同部分区分开来 并生成新的EXCEL
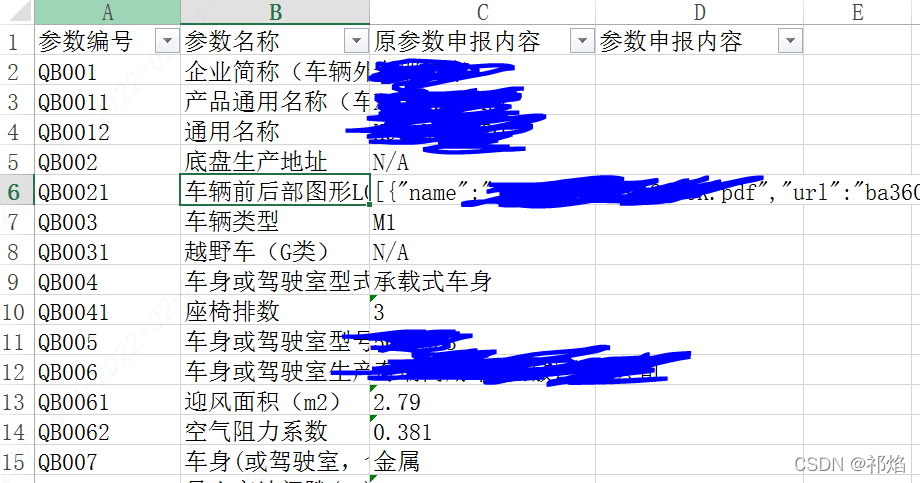
两者表格形式如下 原理是通过读取B表格的参数编号和申报内容作为字典,在A表格中对应的进行查询 是否相同并作出标识

先说第一版使用openxyl做的代码
一地板openxyl写的代码本身没有问题 也很快 定位也很简单
但是有个致命性的问题 他不支持XLS文件格式
然后尝试了第二版的pandas 做代码导入
我说下pandas遇到的问题
其中比较难理解的是out of range的问题
相对于openxyl pandas是在读取文件的时间预先选定好文件的范围,比如4*4 那么超过这个范围的第5行你就选择不到 就会报这个错误 但是openxyl则不会有这个问题 openxyl相当于在一个excel的副本上进行操作 没有范围限制
其中还有一个pandas目前无法解决的问题 如果文件中出现N/A这个字符串时 他会默认识别为Nan 不会当做字符串而是空进行识别 这个也是我为什么会尝试第三种方法的原因
但Pandas的读取范围确实比openxyl要大
再说下xlrd 和xlwt的问题
相对于前面两种方式 他们的操作性好在于他的操作模式 相当于是复制了一个副本进行操作,如果某一个值不满意直接变更掉就可以了
但是xlrd则不是这样
他是对于EXCEL的直接操作,我这里是想要输出一个副本,那么操作起来就麻烦了不少
需要先读 对比 然后循环输出
就不是更改完后一把输出的模式
但是好处是他不会将N/A读错,字符串之间的转换也没有问题
对于写入来说 是有限将需要写入的字段拼成一个字符组
循环写入那一行 然后通过FILE输出 得到的效果和前面是一样的
row=df.index.sized = dict()for i in range(0, row): # 最大行数lp = df.loc[i][1]np = df.loc[i][2]if not lp is None :d[df.loc[i][0]] = df.loc[i][2]# print(df.loc[i][0],df.loc[i][2])# for key in d:# print(key + ':' + str(d[key]))row2 = df2.index.size # 获取最大的 行数col_name = df2.columns.tolist()col_name.insert(6,'状态')df3=df2.reindex(columns=col_name)for i in range(0, row2): # 最大行数lp = df3.loc[i][1]if not lp is None:# d[df.loc[i][0]] = df.loc[i][2]# print(df3.loc[i][0], df3.loc[i][5])if d.get(df3.loc这篇关于python xlrd xlwt pandas openxyl导入方法对比 N/A的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




