本文主要是介绍linux ext3/ext4文件系统(part2 jbd2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
jbd2(journal block device 2)是为块存储设计的 wal 机制,它为要写设备的buffer绑定了一个journal_head,这个journal_head与一个transaction绑定,随着事务状态的转移(运行,生成日志,日志块刷盘,数据块刷盘),journal_head会转移到事务相应的journal队列中(t_buffers、t_shadow_list、t_forget、t_checkpoint_list),其中前三个状态,journal_head与事务是绑定的,第四个状态下,journal_head。当系统crash时,可从superblock记录的最后一次完整刷盘的位置(checkpoint)开始,通过三遍扫描日志块(检查checksum、收集不必恢复的数据块信息、执行数据块恢复),来恢复块设备到最后一个完整commit的事务状态。
事务与日志handle
同一个时段内可以有多个线程同时做一些修改,每个线程持有一个journal 的 handle,这个handle可以同时修改几个块的内容,作为一个原子操作,在 handle 修改结束时,触发事务的提交。等所有开启handle的线程的事务均触发提交后,这些事务打包为一个事务提交至日志系统。
事务是per filesystem的,同一时间最多存在两种类型的事务,running,committing,两个事务不能同时修改日志内容,如果committing事务正在修改,则将它的journal_head的next_transaction置为当前running的事务,在commit结束后,主动转移到 running 事务的队列上。
事务状态转移
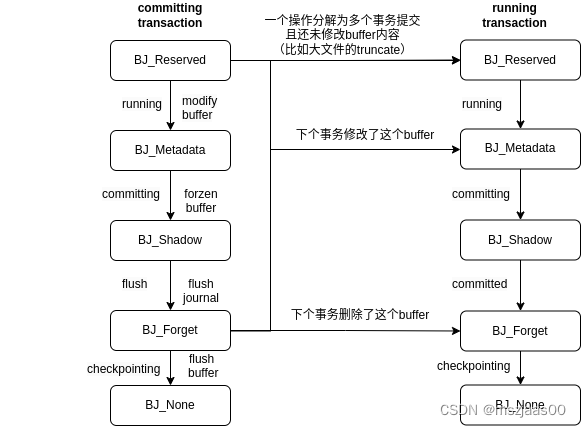
事务状态逻辑上可以分为:运行、生成日志、日志块刷盘、数据块刷盘四种类型(实际状态划分更细,见commit阶段描述)journal_head转移到事务的相应队列为:t_buffers、t_shadow_list、t_forget、t_checkpoint_list
其中前事务三个状态下,journal_head与事务是绑定的,第四个状态下,journal_head虽然还在事务的t_checkpoint_list上,但已与事务解绑定了。
running阶段(运行)
一个元数据块的buffer在修改前,首先为它生成一个journal_head,获取write权限(do_journal_get_write_access),这时它还没有修改过,将它转移至当前事务的 BJ_Reserve 队列(t_reserved_list),如果全局事务切换后还没开启过新的(j_running_transaction为空)就先要new 一个(jbd2_journal_start)。
接下来该线程从jbd2_journal_start到jbd2_journal_stop之间的所有块修改是一个原子操作,在修改块内容后,将buffer用jbddirty来代替dirty(表示由journal子系统接管,被journal子系统接管的buffer块不能直接刷盘,要等日志commit之后,它才可能进入事务的checkpoint列表,由回写子系统接管),并将journal_head转移至当前事务的BJ_Metadata 队列(t_buffers),如果上一个事务正在提交它,则只是把buffer的j_next_transaction标为当前事务,在上个事务的日志刷盘后,发现j_next_transaction为当前事务,会主动将buffer置于当前事务的BJ_Metadata列表(t_buffers)中。(jbd2_journal_dirty_metadata)。
所谓获取write权限与copy on write过程刚好相反:如果buffer正被committing事务用于生成日志,则需要将此时的数据拷贝一份到journal_head->b_frozen_data上,committing事务生成日志时用的是frozen_data的数据,而非buffer最新的数据(jbd2_journal_write_metadata_buffer)。
committing阶段(生成日志)
一个事务运行一段时间(JBD2_DEFAULT_MAX_COMMIT_AGE,5秒)后,会切换事务(jbd2_journal_commit_transaction),当然也可以在必要时手工切事务
T_LOCKED:commit首先要将当前running的事务转为committing状态,当然这需要等running事务的所有线程handle都不再运行(jbd2_journal_stop->stop_this_handle)后才会开始提交(jbd2_journal_wait_updates或其它调用jbd2_journal_lock_updates的地方),等待期间新的handle不能start(由j_state_lock保证),这被称为barrier。(与用户设置的JBD2_BARRIER不同,JBD2_BARRIER指在更新checkpoint时需要将设备的缓存刷下去)
commit阶段生成的日志块顺序为:revoke块,normal journal块,commit块,对于异步提交场景,允许commit块与其它块并发刷盘,对于同步提交场景,只有当revoke块与normal journal 块均提交后,才可以提交 commit块。
生成日志的过程可以描述为几步:
1、T_SWITCH:将本事务删除的块号记录为多个revoke块
2、T_FLUSH:ordered 模式下需要等待数据块提交
3、T_COMMIT:生成一个descriptor 块
4、T_COMMIT:从BJ_Metadata 队列(t_buffers)上取一个journal_head,做frozen,并将frozen的数据块内容作为日志块内容刷盘(jbd2_journal_write_metadata_buffer)
5、T_COMMIT:计算这个frozen 块的checksum,作为tag放在descriptor块上
6、T_COMMIT:将journal_head从BJ_Metadata 队列(t_buffers)转移至BJ_Shadow队列(t_shadow_list),这期间下一个事务是拿不到buffer的写权限的,需要等待日志刷盘。
7、T_COMMIT:重复456过程,如果tag把descriptor块写满了,就计算descriptor块的checksum放在descriptor的tail上。然后重新开一个descriptor块(即3456过程)
8、T_COMMIT_DFLUSH:异步提交场景允许提交commit块,它保存了整体的checksum和事务号
flush阶段(日志块刷盘)
在日志刷盘后,新的事务的handle就可以接管这个事务的journal_head了,具体如下:
1、T_COMMIT_DFLUSH:将日志刷盘后的journal_head从BJ_Metadata 队列(t_buffers)转移至BJ_Forget队列(t_forget)
2、T_COMMIT_DFLUSH:对于同步提交场景,要在所有日志刷盘后才可以提交commit块,它保存了整体的checksum和事务号
3、T_COMMIT_DFLUSH:将BJ_Forget队列(t_forget)的journal_head插入当前事务的t_checkpoint_list队列
4、T_COMMIT_DFLUSH:如果下个事务要修改或删除这个块,则转移至下个事务的BJ_Metadata 队列(t_buffers)或BJ_Forget队列(t_forget)上;如果下个事务要用这个块,但还没做修改,则转移至BJ_Reserve 队列(t_reserved_list)
5、T_COMMIT_DFLUSH:如果下个事务不用这个块了,则将buffer的jbddirty标记清除,改为dirty标记,表示它开始由回写子系统接管;如果下个事务用它,则 jbddirty 标记不会删除,虽然它在当前事务 checkpoint buffer 列表上,但不会将它刷盘,因为它还在被 jbd2 接管,后面还可能会更新或删除(__jbd2_journal_refile_buffer)。
这之后是一些收尾工作:
1、T_COMMIT_JFLUSH:更新统计信息,比如commit用时等
2、T_COMMIT_CALLBACK:ext4会在这个阶段才真正在bitmap里标记free的块真free了,可被下个事务重新分配。
3、T_FINISHED:更新journal相关的全局统计信息
checkpoint阶段(数据块刷盘)
checkpoint的作用是将已经写日志的buffer块回写到磁盘。checkpoint的触发点主要有2个(jbd2_log_do_checkpoint):
1、journal 文件的磁盘空间不足,或内存buffer不够用
2、手工调用jbd2_journal_flush时,比如修改了重要的inode或superblock内容时。
也就是说,commit 事务涉及的 buffer 不是马上刷盘的,checkpoint 事务列表中可以包含多个事务。
do checkpoint的过程只会将标记为dirty(由回写子系统接管)的buffer内容刷盘(write_dirty_buffer),如果buffer还标记为jbddirty,表示它还在被journal子系统接管(后面的事务还在修改或删除它),这时直接将它从事务上删除(__jbd2_journal_remove_checkpoint),并更新 checkpoint 的进度(jbd2_cleanup_journal_tail)。这里不用担心掉电的问题,因为重启时recovery机制会从checkpoint进度点开始,根据日志内容将数据块恢复到最后一次提交事务的状态。
abort阶段
如果journal运行期间出现错误(尤其是io错误时),可能调用jbd2_journal_abort,这时要将所有未checkpoint的数据刷盘,然后restart journal,根据日志内容将系统恢复到最后一个成功事务的状态。
日志模式与实现
一个线程的journal handle运行期间,它会根据日志模式来决定将哪些数据块按什么顺序写入日志。jbd2有三种模式:journal(数据块与元数据块一同记日志),ordered(数据块刷盘后写元数据块日志),writeback(只写元数据块日志,不用等数据块刷盘)
journal 模式实现
journal 模式表示将数据块和元数据块均记录在日志中,提交日志后均由checkpoint 机制去将数据块刷盘,其实现可以搜ext4_should_journal_data相关分支:
在对数据块修改时(pagecache_write、ext4_page_mkwrite),writeback 模式与ordered模式不会记录日志,而journal模式会为这个范围的块的buffer绑定一个journal_head,类型标记为BJ_Metadata,并用jbddirty代替dirty,表示这个buffer由journal 接管(ext4_journal_folio_buffers)。
ordered/writeback 模式实现
可以搜索ext4_jbd2_inode_add_write相关调用:
当修改数据块时,ordered模式下会在修改文件的inode上标记修改数据块的范围(ext4_jbd2_inode_add_write),writeback则忽略。
在commit 阶段,ordered模式下会先扫描inode被标记的数据块范围,等这些数据块内容都刷盘后才开始写日志(journal_submit_data_buffers),writeback模式下由于不记录数据块范围,因而日志刷盘时也不会等待数据块写完。
日志块的内容
提交过程会等构造事务日志,它包含三部分:revoke块(删除块),normal块(running状态构造的BJ_Metadata队列上的buffer块),commit块(checksum等信息)。
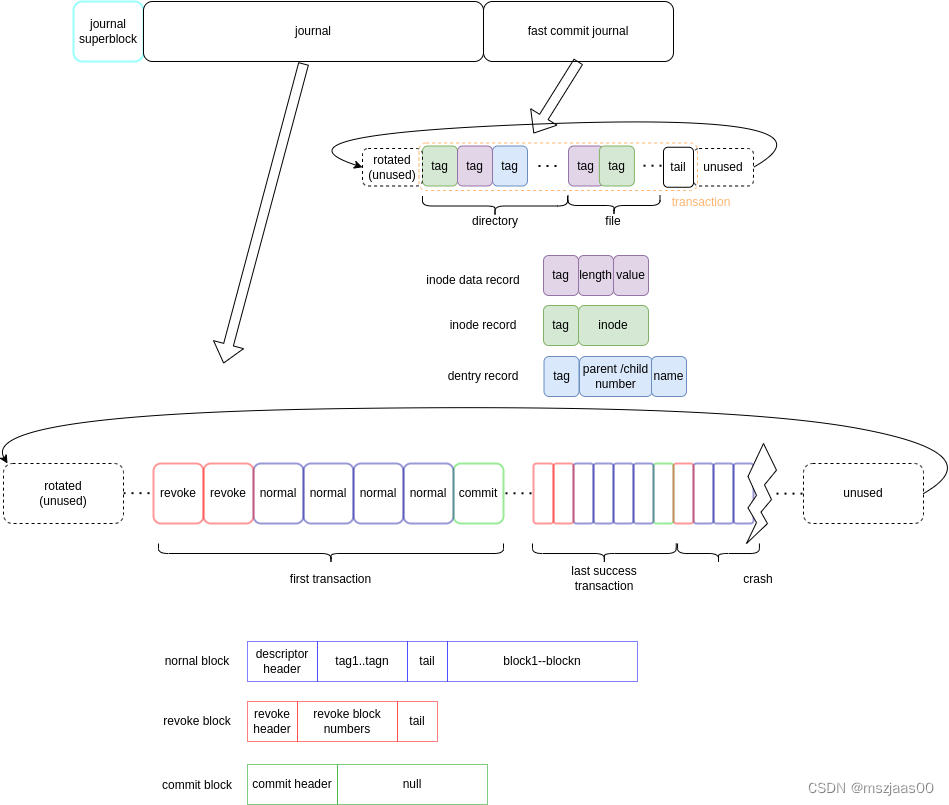
normal块
normal块由一个descriptor块 + 多个数据/元数据块组成。
descriptor块上有header, tags, tail:
第0个tag是jbd2的uuid,它是makefs时就确定的,只有tune2fs系统会用到它,ext4会忽略。后面的tag表示由对应数据块的内容与事务号计算的 checksum,如果发现哪个数据块计算的checksum与tag不一致,则不恢复这个数据块。
tail是用来校验这个descriptor块的checksum的。
revoke块
revoke块的信息是删掉的块号,表示在当前事务会将这块的内容删掉并且不再更新,在恢复时没必要恢复这之前事务的日志中这块的内容。
考虑这个场景:
1、T1,block1写元数据,提交
2、T2,block1被删除,提交
3、T3,block1写数据,掉电。
重启恢复时,发现提交的T2的revoke记录,不会再为block1写入T1的内容,因为它此时已经属于T3的数据块了。数据块在writeback与ordered模式下不记录在日志中,因而不能用日志恢复,需要保留至断电前的样子,即T3时的样子。
commit块
它的内容只有32字节,但要占用一整块,表示本事务的提交成功。
在恢复阶段,如果用descriptor计算的checksum不一致,有四种可能的场景:
1、对于async commit 的场景,有可能先写出了commit 块再写出了之前的数据块,因而可能发现commit 块checksum 与数据块对不上,遇到这种情况就说明已经读到了journal崩溃时的正在提交的事务日志。
2、checksum 不一致还有一种可能,就是日志回卷了,比如读完了下面的t6的事务日志,接着读到t3的descriptor块,发现checksum不一致,这之后正确读到commit块发现原来是读到了回卷的旧日志,这时说明journal是正常退出的,且读到了journal最后的成功日志。
![]()
3、如果用descriptor计算的checksum不一致,但后面不存在commit块,说明与第一种情况一样,找到了journal崩溃时的正在提交的事务日志。
4、如果commit块存在且不是回卷的旧块,且是sync commit的,则说明日志本身写坏了,或者可能是日志所在块的硬件坏了,这种场景不能正常恢复,会直接报错。
重启recovery
重启恢复有三个过程:
第一遍scan阶段,检查checksum,确认日志文件没问题,且找到最后一个成功的事务
第二遍revoke阶段,检查revoke块,构建revoke块号的hash表
第三遍replay阶段,跳过revoke块,对每个数据块做检查,只恢复数据块checksum与tag能对应上的数据块。
场景举例
块分配bitmap重利用问题
考虑一个场景(这个场景与上面描述revoke块内容时相同):在事务T1中,从bitmap块中分配了一个块a,在T2中释放掉了,那么当T2处于committing阶段的时候,当前事务T3能不能重新分配这个块a呢?不可以,因为不能保证上T2事务commit成功,如果T2事务提交失败了,块a还是已经被分配了的状态,但此时又在T3中分配了它并修改,那么块a的数据将会不一致。
ext3的解决方法是:在buffer的journal_head加一个b_committed_data字段,当分配块时利用b_committed_data记录的块内容来决定是否可以分配,即T1事务中bitmap块的状态(这块a已分配)。
ext4的解决方法是:在T2释放块时,不是马上修改bitmap,而是将free的块先记录在super_block_info->s_freed_data_list中,当T2事务commit成功时,通过ext4_journal_commit_callback->ext4_process_freed_data->ext4_free_data_in_buddy->mb_free_blocks回调来真正修改bitmap(ext4_mb_clear_bb),因而没有依赖b_committed_data字段。不过这个解决方法只用于ordered与journal模式,在writeback模式的语义下,还是会发生上面的问题
块的删除
删除一个块:除了可能记录revoke记录外,还要做额外操作:(jbd2_journal_forget)
有三种场景要考虑:
第一,如果没有事务绑定它,它是否在早期的 checkpoint 列表上,如果在,它是否已经刷盘了?可以通过jbd2_journal_try_remove_checkpoint失败尝试移除checkpoint,如果已经刷盘了,则移除成功,可以直接释放,如果失败,说明没有刷盘,那就要加在当前事务的forget列表上,在本事务commit之后如果还没刷盘,就将其从checkpoint移除,不再刷盘了(__jbd2_journal_refile_buffer)。这里不用担心突然掉电后删除的块被日志回写为旧的状态,因为revoke记录会保证他不被之前日志中内容覆盖。
第二,如果绑定在正在提交的事务上,将buffer标记为free,且b_next_transaction标为当前事务,这样在写完日志后会移至当前事务的forget列表上,然后由当前事务提交成功与否决定后面还要不要刷盘(与第一种情况的原理一样)。
第三,如果绑定在当前事务上,又没有早期的事务checkpoint引用,则可以直接释放。
由BJ_Reserve转下个事务的BJ_Reserve场景
比如truncate一个文件,调用ext4_free_branches时发现credit不够用了,这时会调用 ext4_ind_truncate_ensure_credits来将前一段修改的块先提交,然后开启新的事务(ext4_journal_restart),这个场景下提交事务时可能有块还没来得急修改,还在事务的BJ_Reserve列表中,就需要平移至新事务的BJ_Reserve列表
这篇关于linux ext3/ext4文件系统(part2 jbd2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







