本文主要是介绍Redis第一关之常规用法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
Redis不用多说,已经火了很多年了,也用了很多年了。现在做一些归纳总结。
这篇文章主要介绍Redis的常规知识及用法,包括数据结构、使用场景、特性、过期机制、持久化机制。
Redis与Mysql
Mysql是一款基于磁盘的关系型SQL数据库。
Redis是一款基于内存的、非关系型、Nosql数据库,
Mysql的基本构成结构是二维表,由行和列组成。
Redis的数据存储形式是Key-Value结构,由键和值组成。
相较于传统的RDBMS数据库,NOSQL数据库更满足Web2.0时代数据爆炸式需求。不需要固定的格式,严格的关系,提供高并发性能等等。单NOSQL并不能完全取代传统数据库,因此,RDBMS+NOSQL是最好的方式。
下面具体来分析Redis的数据结构
Redis数据结构
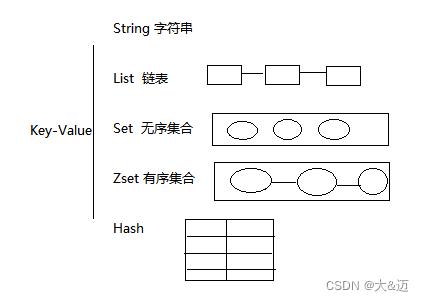
Redis是Key-Value结构,Key值都是单字符串,Value也是字符串,但却有9种数据类型,分别如下:
- String(字符串)
- List(链表)
- Set(无序集合)
- ZSet(有序集合)
- Hash(哈希)
- Geo 地理位置
- Bitmaps 位图
- HyperLogLog 基数统计
除了最后三种特殊数据结构外,常用的5种数据结构可以按类型分类。
1. 按单、多个字符串分类:
String为单个字符串结构
List、Set、Zset、Hash为多字符串结构2. 在多字符串结构中,再按有序、无序分类
List、ZSet为有序数据结构,其中List底层为链表结构,以插入顺序排序。ZSet通过分数Score来排序。
Set、Hash为无序数据结构,其中Set为无序唯一性集合,会自动去重。
Hash数据结构是以field-value形式,非常适合存储对象结构。同时支持对对象属性的增删。
Redis应用场景
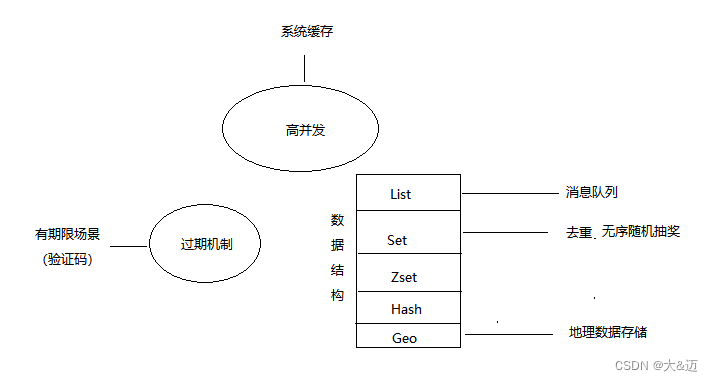
Redis作为Web2.0时代受欢迎的产物,其基于内存的高性能、过期机制、特殊的数据结构都分别决定了它的用途广泛。
缓存应用的三大问题
缓存击穿
概念: 缓存将某个或小面积热Key击穿,
造成原因:误操作、缓存过期
解决办法:暂时设置永不过期、增加热点监控
缓存穿透
概念: 请求穿过了缓存,直达缓存后的数据库层,大并发下容易造成数据库宕机,从而影响全局。
造成原因:大并发请求,缓存层未命中,黑客攻击等
解决办法:增加数据有效性校验,对不存在的数据进行Null值缓存,使用布隆过滤器。
缓存雪崩
概念:大面积缓存的key值在同一时间段都未命中
造成原因:key值过期时间过于集中,或者Redis宕机。
解决办法:分散key值得过期时间,通过随机数加权计算。增加Redis高可用性。
过期时间
在Redis中,很多场景可以通过过期机制来实现。比如短信验证码、七天免登录等。
但是Redis中允许key不设置过期时间,这会让key值永不过期,占用内存。如果不是特殊设计不建议这样使用。
关于Redis的设计缺陷及补丁措施思考
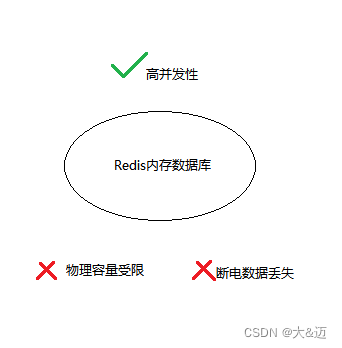
Redis是一款基于内存的数据库,其目的是为了满足快速处理的高并发特性。
但是内存是有物理局限的,它无法像硬盘一样容量可以扩充到很大,也容易受到断电丢失数据影响。
因此,Redis作者又做了几个补丁。
补丁一:过期机制
如果Redis没有过期机制?
那么意味着,所有存入到内存的数据都是永不过期的,使用完了就得删除,这像是 C++语言开发,而过期机制相当于Java的内存回收机制,操作起来更柔性。
过期机制的底层原理?
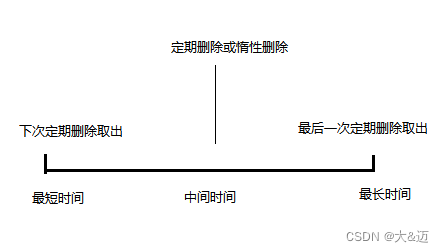
Redis内部采用的是定期删除+惰性删除,两种机制相配合保证了最终一定被删除。
定期删除
设置了定时器,每次会取出一部分过期的key进行删除。
为什么不是轮询全部过期的key值?
因为如果内存较大,过期的key值较多,轮询比较耗时,会消耗大量的CPU在轮询上。
那么,未被取出的过期key值如何删除?
惰性删除
惰性删除,类似于java中的类的懒加载,Spring IOC对象的懒加载。
未被定期删除策略命中的过期key,只有当这个key再次被访问时来判断是否要删除。
因此,定期删除+惰性删除策略,一定会删除所有过期的key,但是有一个时间差问题。
某个key值过期了,它的最快删除时间是定期任务第一次扫描就被取出来并删除。它的最慢删除时间是…很久,这取决于定期删除是怎么取出数据的了。
虽然这些过期的key最终会被删除,但Redis内存容量总是动态变化的,不断的有增量Key,也有不断的删除Key。
如果:
增量速度 > 删除速度,删除速度>=0(等于0时所有的key都未过期)
Redis内存就会膨胀,逐渐趋于饱和。这时候,那些未被及时删除的过期Key就亟需被找到并删除掉了,作者怎么做的呢?
内存淘汰策略
当出现上述情况时,作者设计了一种内存淘汰机制,使用者可以不同的策略来清理内存,保证Redis能否正常使用。
1. volatile-lru(least recently used) 从设置了过期时间的数据中(server.db[i].expires) 淘汰最近最少被使用的数据。
2. volatile-random 从设置了过期时间的数据中 随机淘汰数据。
3. volatile-lfu 从设置了过期时间的数据中 淘汰最不频繁被使用的数据。4. allkeys-lru 从所有的数据中(server.db[i].dict) 淘汰最近最少被使用的数据。- 常用
5. allkeys-random 从所有的数据中(server.db[i].dict)随机淘汰数据。
6. allkeys-lfu 从所有的数据中(server.db[i].dict)淘汰最不频繁被使用的数据。7. volatile-ttl 从设置了过期时间的数据中(server.db[i].expires)淘汰将要过期的数据。
8. no-eviction 禁止淘汰数据。
补丁二: 持久化机制
Redis毕竟是基于内存的数据库,如果断电了肯定会导致数据丢失。所以设计持久化机制是必然的。
作者设计了两种持久化机制:AOF、RDB
AOF持久化
AOF是一种以记录实时日志的方式,将Redis的每个操作命令持久化,其优点是实时性比较强,可以每秒钟记录一次,其缺点是产生的日志量较大,重启恢复时的耗时较长。
RDB持久化
RDB是一种全量备份模式,将Redis中的所有数据全部备份下来,可以实现备份和迁移。
其优点是产生的数据量较小,重启时可以快速的恢复,其缺点是实时性较弱,容易产生数据丢失。
RDB持久化时,如果发生在Redis运行中,由于数据是动态变化的,因此常见的备份方式是将Redis其他操作阻塞,直到全量备份完成在放行,另一种方式是Redis作者提供的异步备份。
1. 同步备份 save
2. 异步备份 bgsave
异步备份是bgsave命令,其原理是在主进程中fork一个子进程异步执行,不会阻塞主进程操作。
Redis高可用设计
Redis提供了高可用设计,分别是主从模式、哨兵模式、集群模式。
主从模式
Redis数据库的主从模式和Mysql数据库的主从模式类似,都是以容灾备份为目的设计的,因此当Redis主结点发生故障时,可手动切换为从结点提供服务。
主从模式需要两个Redis结点。
哨兵模式
虽然主从模式可以提供容灾备份的功能,但是当发生故障时,需要手动切换,并不智能。 于是,哨兵模式解决了这个问题。
哨兵模式通过哨兵集群监控所有Redis结点,让主结点发生故障时,自动将主节点踢出,然后重新选择一个从节点作为主节点提供服务,保证了高可用性。
哨兵模式最大的优点是故障自动转移,但至少需要3个Redis结点。
群集模式
群集模式提供了Redis分布式数据存储功能,由于单机内存上限的限制,群集模式解决了这个问题,通过数据分片的形式将Redis数据分散到多个结点,实现容量的横向扩展,每个主结点都需要配置一个从结点作为数据容灾备份,以便故障自动转移。
Redis群集模式一般需要3主3从,共6个Redis结点。
这篇关于Redis第一关之常规用法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





