本文主要是介绍软件著作书 60页代码轻松搞定!(附exe和代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近做了一个软件,准备去申请软件著作书,看着那60页的文档,确实难搞,不过幸好会用一点点python,就自己用python写了一个读取所有文件代码的程序,使用起来也很简单,过来分享一下
链接:https://pan.baidu.com/s/1rosw7H2-vMNmtmr7gMXxHw?pwd=m5tt
提取码:m5tt
展示
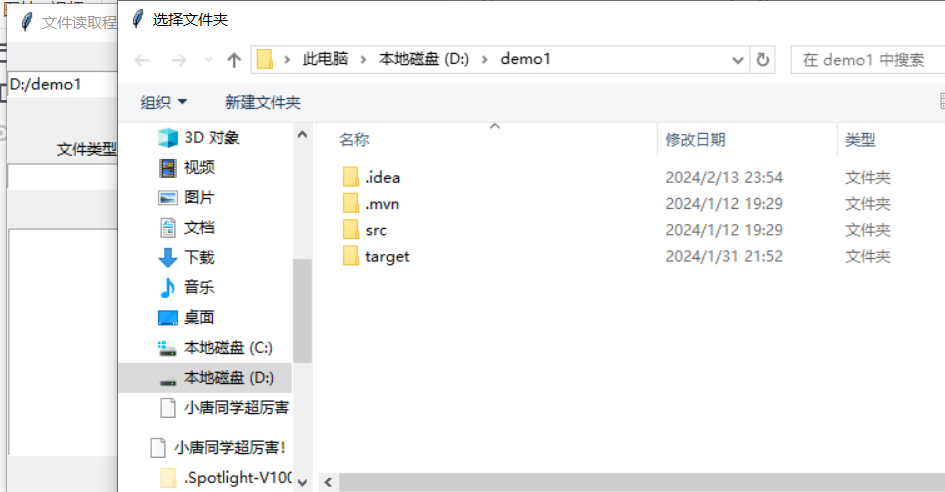
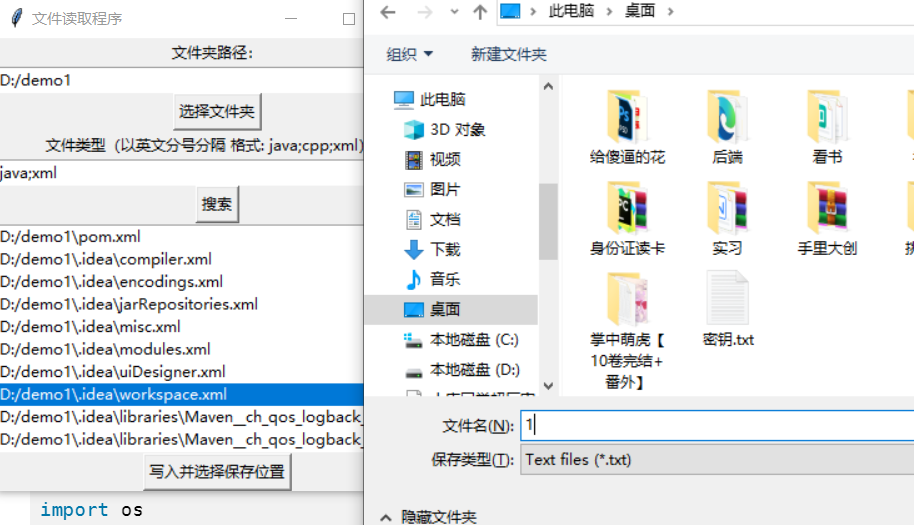
可以对于文件夹进行选择
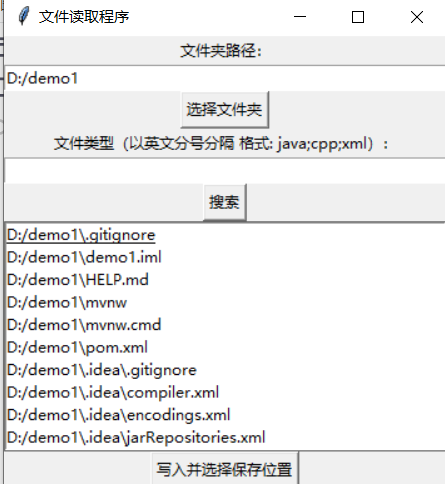
中间不写就是读取全部文件,写了就可以读取指定格式文件,点击搜索
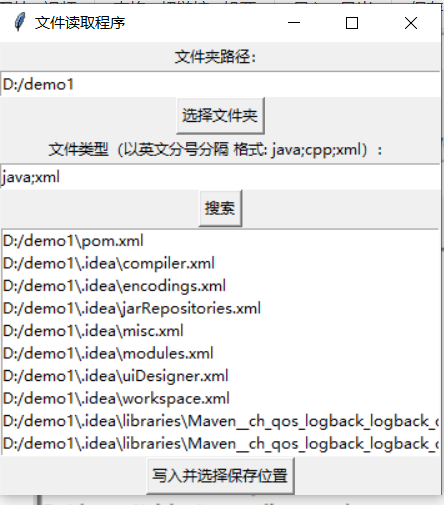
然后选择最下面的按钮
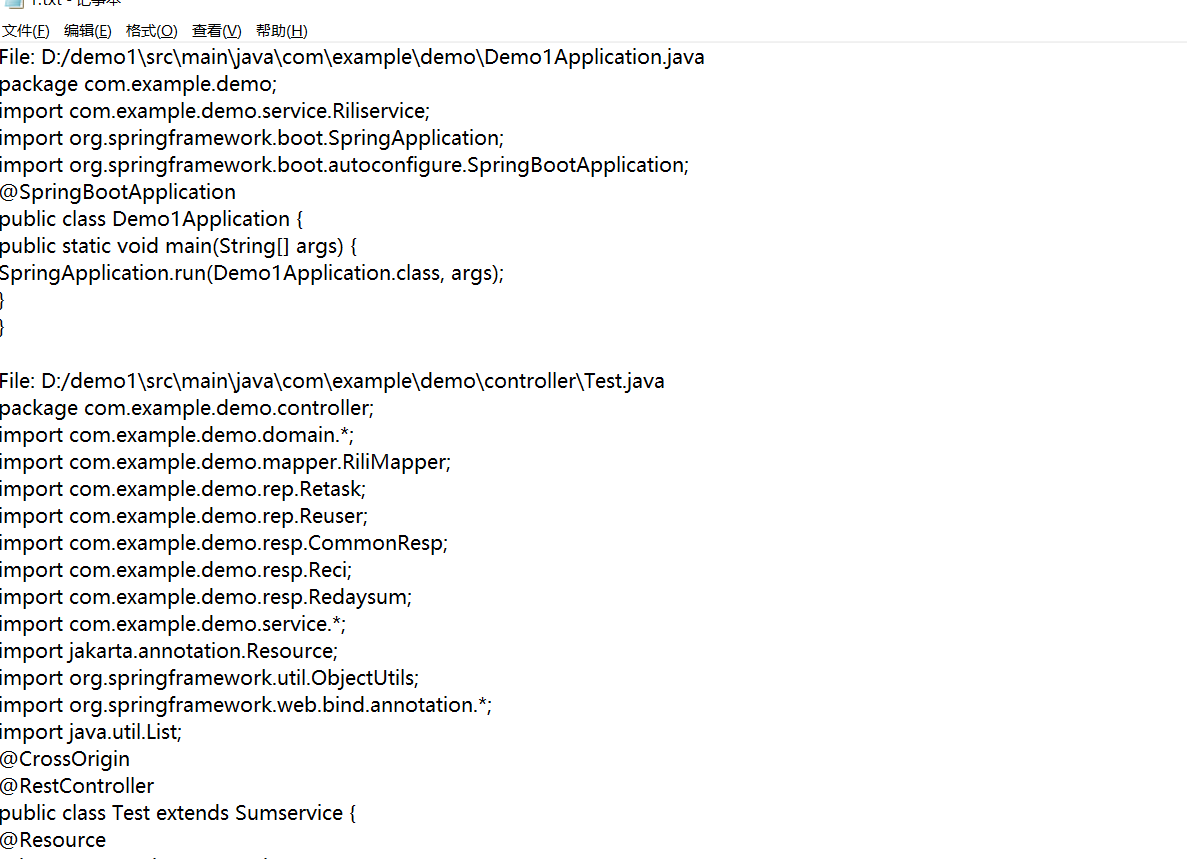
轻松完成代码编写,会自动去除空行
主要代码
def select_directory():global directory_pathdirectory_path = filedialog.askdirectory()directory_entry.delete(0, tk.END)directory_entry.insert(0, directory_path)def search_files():files_listbox.delete(0, tk.END)if not directory_path:returnfile_types = file_type_entry.get().split(';')if len(file_types) == 1 and file_types[0] == '':file_types = Nonefor root, dirs, files in os.walk(directory_path):for file in files:if file_types is None or file.lower().endswith(tuple(file_types)):files_listbox.insert(tk.END, os.path.join(root, file))def write_to_txt():directory = directory_entry.get()save_path = filedialog.asksaveasfilename(defaultextension=".txt", filetypes=[("Text files", "*.txt")])if not directory or not save_path:returnwith open(save_path, 'w', encoding='utf-8') as output_file:for i in range(files_listbox.size()):file_path = files_listbox.get(i)with open(file_path, 'r', encoding='utf-8') as f:content = f.readlines() # 按行读取文件内容content = [line.strip() for line in content if line.strip()] # 去除空行if content:output_file.write(f'File: {file_path}\n')output_file.write('\n'.join(content) + '\n\n')这篇关于软件著作书 60页代码轻松搞定!(附exe和代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



