本文主要是介绍Retrieve, Discriminate and Rewrite: A Simple and Effective Framework翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
获得有情感的响应是建立具有同理心对话系统的关键步骤。这项任务已经在基于生成的聊天机器人中进行了很多研究,但是在基于检索的机器人中的相关研究仍处于早期阶段。现有的基于检索的聊天机器人的工作主要是Retrieve-and-Rerank的框架,其具有以降低响应质量为代价来满足情感生成的常见问题。要解决此问题,我们提出了一种简单有效的Retrieve-Discriminate-Rewrite框架。该框架用新的discriminate-and-rewrite机制替换了重排序机制,该机制通过判别模块预测检索到的高质量响应的情感标签,并通过重写模块进一步重写不满足情感的响应。这不仅可以保证响应的质量,还可以满足给定的情感标签。此外,这项研究的另一个挑战是缺乏现成的情感响应数据集。为了解决这个问题并测试我们提出的框架,我们基于原始Douban对话语料库标注了Sentimental Douban Conversation Corpus。实验结果表明,我们提出的框架是有效的,且优于基线。
1.介绍

表达情感是构建类人对话系统的关键因素,这可以显着促进人机交互期间的情感沟通且增强用户满意度。这个问题在基于生成的聊天机器人中已经有过很多的研究,这通常被定义为给定情感标签和对话的上下文,来生成响应。
然而,基于检索的聊天机器人的相关研究仍处于早期阶段。基于检索的聊天机器人与基于生成的相比,能够获得更多样化和信息更丰富的响应,同样也被广泛使用,因此,获得情感响应对基于检索的聊天响应的研究是有意义的。在现有的研究中,情感被认为是总结感情,感觉和情绪的术语。在本文中,我们专注于情绪,并研究如何在基于检索的聊天机器人中获得特定情绪(正面或负面)的响应。
与可以生成新响应的基于生成的聊天机器人不同,基于检索的聊天机器人必须从响应存储库中检索出候选响应。因此,为了获得情感响应,如何有效地使用候选是一个重要问题。基于检索的聊天机器人的现有工作主要是基于Retrieve-and-Rerank框架,该框架对检索到的候选利用重排名的机制。具体地,该框架首先通过检索模块获得候选,然后根据给定的情感标签调整排名或匹配分数,最后输出具有适当情感和内容的响应。
但是, Retrieve-and-Rerank框架无法满足要求,因为它在满足给予给定的情感标签时会降低响应的质量。这意味着将丢弃高质量但不满足情感的响应,这将直接降低了基于检索的聊天机器人的核心优势。例如,在图1(a)中,当不考虑情感标签时,高质量的candidate 2应该是最好的,但由于给出了情感标签,因此只能选择具有普通质量的candidate 3。
为了同时保证内容和情感,我们提出了一种简单有效的Retrieve-Discriminate-Rewrite框架。 该框架用新的判别和重写机制替换重排名机制,该机制优先选择高质量的候选响应并重写其情感被判别为不满足的响应。例如,在图1(b)中,我们的新框架优先选择高质量的candidate 2,然后识别到candidate 2的情感是不满足的,并且最终对candidate 2进行少量修改,从而使影响满足要求。这表明该框架不仅可以保证响应的质量,还可以满足给定的情感标签。
此外,这一研究的另一个挑战是缺乏现成的情感数据集。 这样的数据集不仅可以在我们的框架中使用,而且能用于采用重排名机制的现有方法。为解决此问题并测试我们的框架,我们在原始Douban对话语料库的基础上,标注了情感Douban对话语料库。我们对该数据集进行实验,实验结果表明,我们具有简单架构的框架是有效的且优于基线。
这项工作的贡献总结如下:
- 我们提出了一种Retrieve-Discriminate-Rewrite框架,用于在基于检索的聊天机器人中获得情感响应,这解决了Retrieve-and-Rerank框架中的低质量响应问题。
- 我们标注并发布一个情感响应数据集,这些数据集解决了研究中缺乏必要情感数据集这一问题。
- 数据集上的实验结果表明,我们的框架是有效的且优于baseline。
2.相关工作
在对话系统中获得有情感响应的现有工作可以分为两个分支。第一类是基于生成的方法,它基于Seq2Seq模型为给定的会话上下文生成有情感的响应。基于生成的方法具有生成新响应的优点,并且已经具有很多好的工作。 第二类是基于检索的方法,它从响应存储库检索出候选响应来获得基于会话上下文的情感响应。基于检索的方法具有获得多样化和信息丰富响应的优势,与基于生成的方法相比仍然具有竞争力。本文重点介绍第二类。
与基于生成的方法不同,对基于检索的方法如何获得有情感响应的相关研究仍在早期阶段。Lubis et al. (2019) 提出了一种检索积极情绪的重排名策略,其方法也可以应用于生成情感反应。Qiu et al. (2020) 介绍了一种情感匹配网络,该网络融入了情绪因因子并实现情绪控制。从使用候选者的角度来看,这些方法都基于Retrieve-and-Rerank框架。虽然这些方法已经获得了有情感的反应,但Qiu et al. (2020) 观察到这些方法更喜欢满足于给定情感标签的响应,即使它们与上下文无关,这减少了基于检索的聊天机器人的核心优势。 如何平衡丰富的信息并给予期望情感标签仍然需要不断探索,在本文中,我们讨论了这个问题。
在我们的工作中涉及的另一个研究分支是自然语言处理中的风格迁移。我们框架中的重写机制将修改响应的情绪,这已经在某些风格转移工作中进行了研究。一些现有的工作侧重于如何获取独立于风格的句子表示,然后使用目标风格生成句子。这些工作都具有一定的有效性,但它们通常缺乏细粒度的控制并导致内容质量下降,这与我们对情绪进行细粒度控制的目标不一致。同时,一些现有的工作侧重于如何删除句子中与风格相关的单词,然后使用目标风格生成句子。受这些工作的启发,我们将情绪重写看作类似的两阶段过程处理。但是不同于这些工作,我们的情绪重写将涉及从中性表达到有情感表达的大量情况,而不仅仅是在不同情感表达之间的迁移。缺乏处理中性表达将导致我们的任务表现不佳,我们对此问题的处理与这些工作不同。此外,其他一些现有的工作从其他不同的角度实现了风格转移。这些工作旨在更通用的风格迁移问题,并且缺乏对情绪的细粒度控制,这与我们工作的目标不符。
3.The Retrieve-Discriminate-Rewrite Framework
3.1 Overview
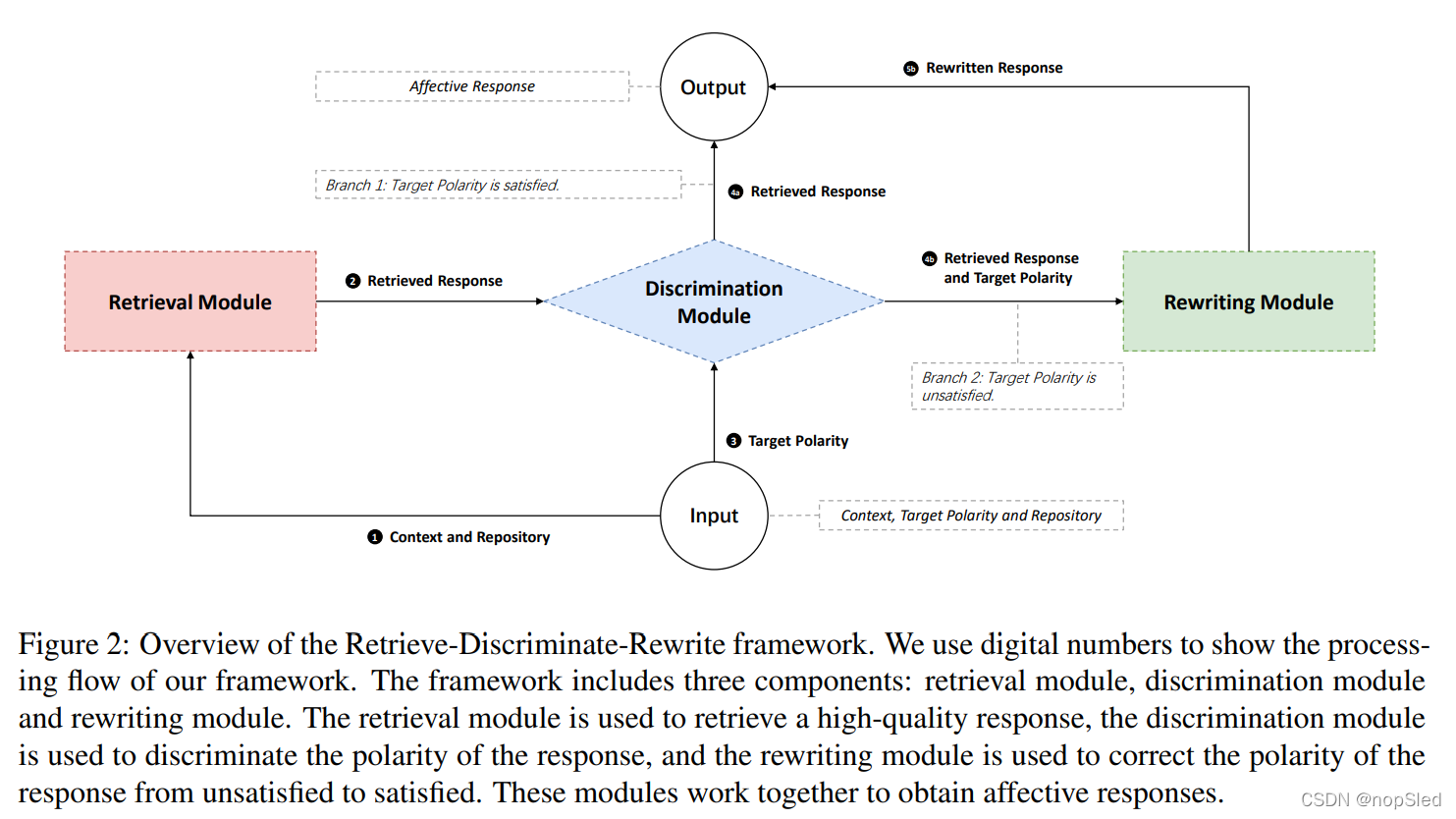
在这项工作中,我们的目标是在给定情感标签和基于检索的聊天机器人的对话上下文,来获取对应的情感响应。特别是,我们关注的情感标签是情绪(positive或negative)。
该问题可以定义如下:给定具有 N N N个语句的对话上下文 C = { u 1 , u 2 , . . . , u N } C=\{u_1,u_2,...,u_N\} C={u1,u2,...,uN},上下文相关的响应存储库 P = { r 1 , r 2 , . . . , r M } P=\{r_1,r_2,...,r_M\} P={r1,r2,...,rM}和目标情绪 s s s,目标是从响应储存库 P P P中检索到候选响应 Y Y Y,其不仅与上下文 C C C相干,而且与目标情绪 s s s相匹配。
对于此问题,我们的Retrieve-Discriminate-Rewrite框架如图2所示。该框架由三个组件组成:
(1)Retrieval Module:该模块用于与现有的基于检索的聊天机器人兼容,可以为后续模块提供高质量的响应。
(2)Discrimination Module:该模块从检索模块接收检索到的高质量响应,然后区分检索到的高质量响应的情绪,并输出满足情绪的响应。
(3)Rewriting Module:该模块从判别模块接收不满足情绪的响应,用以校正响应的情绪。
在以下部分中,我们将详细描述这些组件,并介绍在框架中如何使用它们来获得期望情感的响应。
3.2 Retrieval Module
在我们的框架中,检索模块用于与现有的基于检索的方法兼容。为了验证我们的框架是通用的,我们选择以下基于检索的方法来获得框架中的高质量响应,我们将根据这些方法分别进行实验。
GTM。这是真实标签模型,即总是输出正确的响应。我们使用这一理想模型来研究检索结果在完美情况下框架的表现。
SMN。这是基于检索的聊天机器人的经典工作,其提出了一个基于RNN的序列匹配网络,其在多个粒度上与每个语句进行匹配,并将获得的匹配向量累积来作为最终匹配分数。
MSN。这是最近在基于检索的聊天机器人的工作,其提出了一个多跳选择器网络,以减轻使用不必要的上下文语句的副作用。它是目前最好的方法之一。
3.3 Discrimination Module
在我们的框架中,判别模块用于从检索模块接收检索到的高质量响应,并判别响应的情绪。对于满足情绪的响应,模块则直接输出它。
该模块处理一个分类任务,因此我们可以利用许多现有分类器。在这项工作中,我们选择预训练的BERT模型作为我们的分类器,这在各种NLP任务中取得了最先进的性能。
对于预训练的BERT模型,给定响应 R = { w 1 , w 2 , w 3 , . . . , w n } R=\{w_1,w_2,w_3,...,w_n\} R={w1,w2,w3,...,wn},输入可以表示为:“ [ C L S ] w 1 w 2 w 3 . . . w n [ S E P ] [CLS]~w_1~w_2~w_3...w_n~[SEP] [CLS] w1 w2 w3...wn [SEP]”。与常用的操作相同,我们使用 [ C L S ] [CLS] [CLS]字符的隐藏表示来表示响应,然后将其带入到softmax层进行分类。
3.4 Rewriting Module
在我们的框架中,重写模块用于从判别模块接收具有不满足情绪的响应,并校正响应的极性。
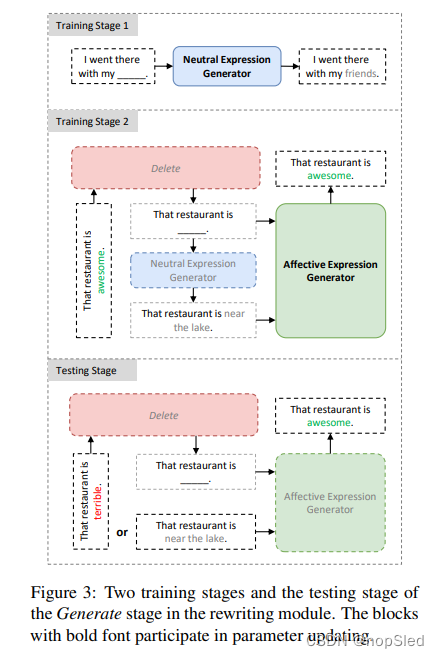
受先前在风格迁移中的工作的启发,我们将响应的情绪重写视为两阶段过程:Delete和Generate。 第一阶段采用预训练的情绪分类模型来删除响应中的情感表达,第二生成阶段采用两个基于transformer的生成器来产生满足情绪的响应。我们在以下部分中分别介绍这两个阶段。
3.4.1 Delete
在这个阶段,我们的目标是识别并删除情感响应中的情感表达。对于中性的响应,我们在这个阶段不进行任何处理。
我们的方法基于预训练的情绪分类模型,以自动识别单词级的情感表达。对于情感分类模型,句子中的情感表达是识别句子情绪的关键。因此,直观的想法是测量不同单词对句子情绪分类的重要性,影响最重要的单词应该是关键的情感表达。
具体而言,我们设计一个单词排名机制,用于识别响应中单词级的情感表达。我们计算响应 R R R中每个单词 w i w_i wi的重要性评分 I w i I_{w_i} Iwi。该方法是在响应中删除单词 w i w_i wi,并比较删除前后的目标情绪的预测得分,这可以分别表示为 S e ( R [ w i ] ) S_e(R_{[w_i]}) Se(R[wi])和 S e ( R [ w / o w i ] ) S_e(R_{[w/o~w_i]}) Se(R[w/o wi])。每个单词 w i w_i wi的重要性评分 I w i I_{w_i} Iwi则可以正式定义如下:
I w i = S e ( R [ w i ] ) − S e ( R [ w / o w i ] ) (1) I_{w_i}=S_e(R_{[w_i]})-S_e(R_{[w/o~w_i]})\tag{1} Iwi=Se(R[wi])−Se(R[w/o wi])(1)
我们首先计算每个单词的重要性分数,并选择前 λ \lambda % λ作为情感表达的单词。然后,我们删除这些情感表达并将修改后的响应发送到下一个阶段(Generate)。
3.4.2 Generate
这篇关于Retrieve, Discriminate and Rewrite: A Simple and Effective Framework翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!