本文主要是介绍10M上下文,仅靠提示就掌握一门语言,Google Gemini 1.5被OpenAI抢头条是真冤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

这两天,几乎整个AI圈的目光都被OpenAI发布Sora模型的新闻吸引了去。其实还有件事也值得关注,那就是Google继上周官宣Gemini 1.0 Ultra 后,火速推出下一代人工智能模型Gemini 1.5。
公司首席执行官 Sundar Pichai携首席科学家Jeff Dean等众高管在推特同时宣布了这一重大更新。
其中最亮眼的当属它在跨模态超长文本理解能力上的大幅突破。Gemini 1.5能够稳定处理的信息量高达100万个tokens。更直观去感受,这相当于1小时的视频、11小时的音频、超过3万行代码或70万个单词。
在此之前,世界上公开可用的LLM中,最大的上下文窗口来自Claude 2.1的20万tokens。同时GPT-4是12.8万tokens, Gemini 1.0 Pro是3.2万tokens——此次Gemini 1.5已在窗口长度上成功碾压所有大模型。
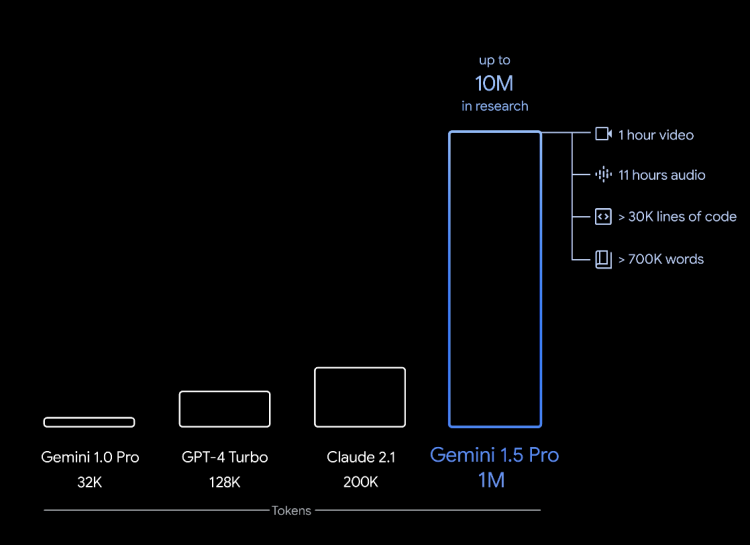
Google还表示,他们在研究中已成功测试了高达1000万tokens,相当于一次将整个《指环王》三部曲放进去。
Sundar Pichai认为更大的查询窗口对企业来说会非常有用, “电影制作人可能会上传他们的整部电影,询问Gemini评论家是什么意见,公司还能使用Gemini审查大量的财务记录。这是我们实现的重大突破之一。”
更高效的MoE架构
作为目前Google公开的最先进LLM,Gemini 1.5采用时下流行的混合专家(MoE)架构来提高效率,响应更快、质量更高。
与传统Transformer 作为一个大型神经网络运行不同, MoE 模型被划分为较小的专家模块。执行任务时会根据信息类型,选择性地激活最相关的专家路径,从而大大提升模型的效率和准确性。不仅更适应处理大规模数据集的复杂任务,还有更强的可扩展性和灵活性。
我们熟知的Mistral 8x7B、MiniMax abab6都是使用了Moe架构,更有爆料称GPT-4也是由8个或16个专家模型构成。
根据Google 数据,此次供早期测试的Gemini 1.5 Pro在使用更少计算资源的同时,对数学、科学、推理、多语言和视频等任务的执行水平已逼近1.0 Ultra。
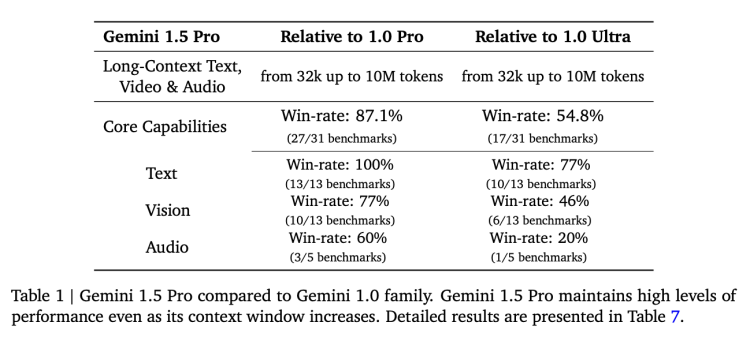
在官方演示和58页的技术论文中, Google还针对新模型的强大性能给出了以下几个用例:
大量信息的复杂推理和多模态分析
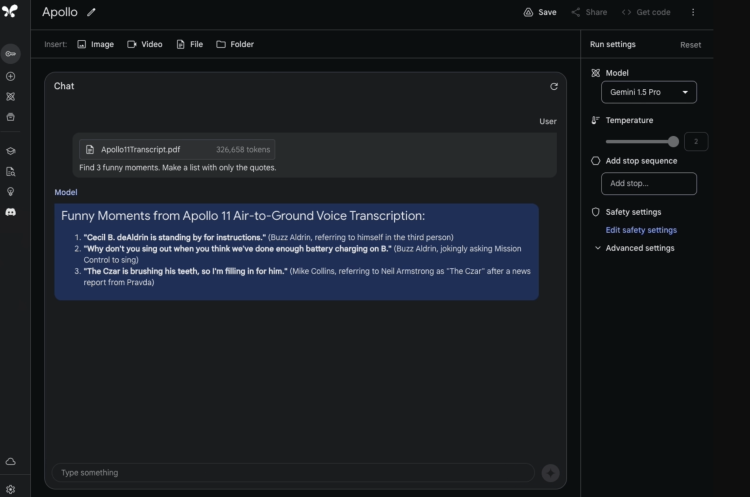
Gemini 1.5 Pro 可以无缝分析、分类和总结给定的长篇复杂文档。例如,上传阿波罗 11 号登月任务的 402 页pdf记录,让它根据要求列出3个有意思的瞬间,并引用原始对话细节。
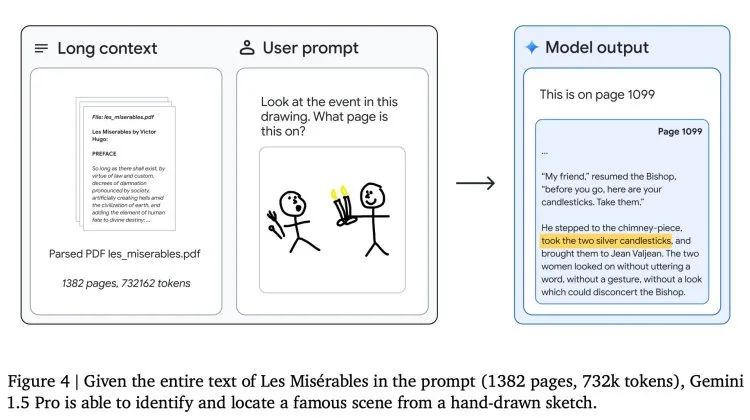
给出维克多·雨果的五卷本小说《悲惨世界》(1382页,73.2万tokens),粗略勾勒一个场景,并提问“看看这幅画中的事件是在哪一页上?”模型准确给出了页码,并标识出关键情节。
在超长视频理解上同样出色,能够快速准确地分析各种事件和情节点。比如给定一部相当于68.4万tokens、时长为44分钟的无声电影Sherlock Jr.,要求一句话总结电影情节:
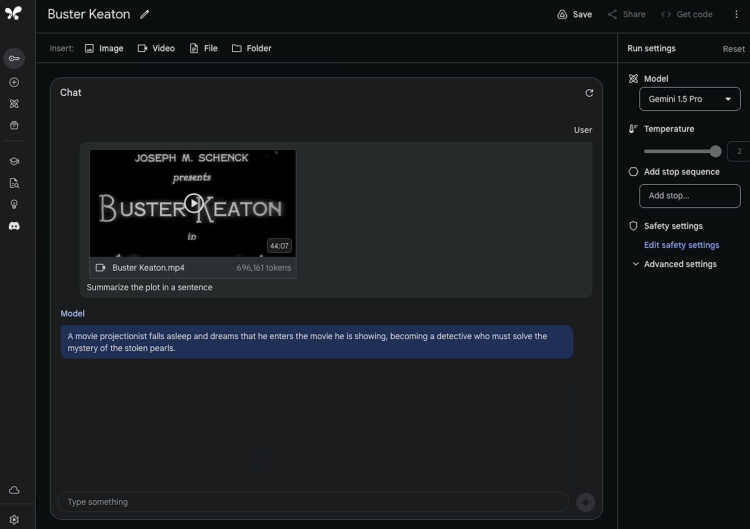
继续询问一个“纸张从口袋取出的关键信息和时间”。Gemini 1.5 Pro用时57秒给出详细答案。

另外,Gemini 1.5 Pro超大的上下文窗口还能够深入分析整个代码库。当发出一个81.6万tokens、超过10万行代码的提示时,它可以根据提问快速找到特定demo的代码,还能提出有用的修改建议并进行解释。
一本语法书,自学翻译新语言
另一项让人耳目一新的是Gemini 1.5 Pro的“上下文学习(in-context learning)”技能,意味着它能从一个长提示中给出的信息里学习新技能,而无需额外微调。
为此,Google使用“对一本书进行机器翻译 (MTOB)”进行测试,并选用新几内亚西部不到200名使用者的Kalamang语。由于该语言几乎没有任何网络信息,模型只能依赖于给定的上下文数据,而非训练权重中储存的知识来进行翻译。
在测试中, 工作人员向Gemini 1.5 Pro提供了500页参考语法、2000条双语词条和400个额外的平行句子——总计约25万tokens信息作为其输入上下文,要求从中学习并完成Kalamang语和英语的互译。
从测试结果可见,Gemini 1.5 Pro对整本书的翻译得分接近人类学习者,在半本书的表现中远超GPT-4 Turbo与Claude 2.1。

对于一门在模型训练过程中几乎完全没接触过的语言来说,这一成就尤为突出。不仅支持濒危语言的保护和复兴,也为其它低资源教育领域开辟了新的可能性。
从今天开始,Google将通过AI Studio和Vertex AI向开发者和企业客户提供 Gemini 1.5 Pro的有限预览权限。最终在完成所有安全部署和测试后取代Gemini 1.0。免费使用的Gemini 1.5 Pro标准版将采用12.8万个tokens上下文窗口,普通用户需要额外支付费用获得100万tokens使用权。
被OpenAI“夹心”,但仍不可小觑
此次Gemini 1.5的发布时间再次“不凑巧”,前有OpenAI放话开发网络搜索产品和推出GPT记忆功能,后面紧跟着两小时后又横空杀出个Sora。奥特曼武器库丰富且擅长针锋相对,每当Google有新动作,刚要炸起水花就被摁下去。
网友们形容当天的场面就如同:
但是,依然有不少声音站出来提醒大家切莫小看了Gemini 1.5 Pro,它对超长文本强大的分析推理能力是其它大模型做不到的。

NVIDIA高级科学家Jim Fan更是发表评论盛赞。表示尽管Gemini-1.5 Pro被抢走了风头,被人们拿梗图来开玩笑,但这仍是LLM能力的巨大跃升。测试中达到的1000万tokens上下文、擅长检索、在零样本情况下对极长指令进行泛化、多模态工作能力都是惊人的。
“重要的不是声明中实现多少上下文长度的神话,而是模型实际上如何使用上下文来解决现实世界的问题。”他认为1.5 Pro不通过微调而自主实现对Kalamang语的学习和应用,就展现出了这种神经激活中的复杂技能,超越了现有的技术水平。

如今OpenAI的急速扩张和Gemini逐步加快的升级速度,已经标志着生成式AI底层技术的狂热步伐。Google DeepMind 负责人Demis Hassabis表示,可以期待未来几个月会有更多的进步。
“这是一种新的节奏”,他说,“我正试图带来一种类似初创公司的心态。”
这篇关于10M上下文,仅靠提示就掌握一门语言,Google Gemini 1.5被OpenAI抢头条是真冤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









