本文主要是介绍解释 OpenAI Sora 的时空补丁:关键因素,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

人工智能如何将静态图像转换为动态、逼真的视频?OpenAI 的 Sora 通过创新地使用时空补丁来引入答案。
在快速发展的生成模型领域,OpenAI 的 Sora 脱颖而出,成为一个重要的里程碑,有望重塑我们对视频生成的理解和能力。我们解读了 Sora 背后的技术及其在图像、视频和 3D 内容创作方面激发新一代模型的潜力。
cat-on-bed
上面的演示是由 OpenAI 使用提示生成的:一只猫叫醒了熟睡的主人,要求吃早餐。主人试图无视猫,但猫尝试了新的策略,最后主人从枕头下掏出一个秘密的零食,让猫多呆一会儿。— 借助 Sora,我们在视频内容生成方面接近于几乎无法区分的真实感。完整的模型尚未完全向公众发布,因为它正在测试中。
Sora的独特方法如何改变视频生成
在生成模型的世界里,我们已经看到了许多方法,从GAN到自回归和扩散模型,都有自己的优势和局限性。Sora 现在引入了一种范式转变,具有新的建模技术和灵活性,可以处理各种持续时间、纵横比和分辨率。
Sora 将扩散和转换器架构结合在一起,以创建扩散转换器模型,并能够提供以下功能:
- 文字转视频:正如我们所看到的
- 图片转视频: 让静止图像栩栩如生
- 视频到视频: 将视频样式更改为其他样式
- 及时延长视频:向前和向后
- 创建无缝循环: 看似永无止境的平铺视频
- 图像生成: 静止图像是一帧的电影(最大 2048 x 2048)
- 生成任何格式的视频: 从 1920 x 1080 到 1080 x 1920 以及介于两者之间的一切
- 模拟虚拟世界:像 Minecraft 和其他视频游戏一样
- 创建视频: 最长 1 分钟,包含多条短片
想象一下,你有一会儿在厨房里。传统的视频生成模型,如 Pika 和 RunwayML 就像厨师一样,严格遵循食谱。他们可以制作出出色的菜肴(视频),但受到他们所知道的食谱(算法)的限制。厨师可能专注于烘焙蛋糕(短片)或烹饪意大利面(特定类型的视频),使用特定的成分(数据格式)和技术(模型架构)。
另一方面,Sora 是一种了解风味基础知识的新型厨师。这位厨师不仅遵循食谱;他们发明了新的。Sora的食材(数据)和技术(模型架构)的灵活性使Sora能够制作各种高质量的视频,类似于主厨的多才多艺的烹饪创作。
索拉的秘密成分的核心:探索时空补丁
时空补丁是 Sora 创新的核心,它建立在 Google DeepMind 早期对 NaViT 和 ViT(视觉变形金刚)的研究之上,该研究基于 2021 年的论文 An Image is Worth 16x16 Words。
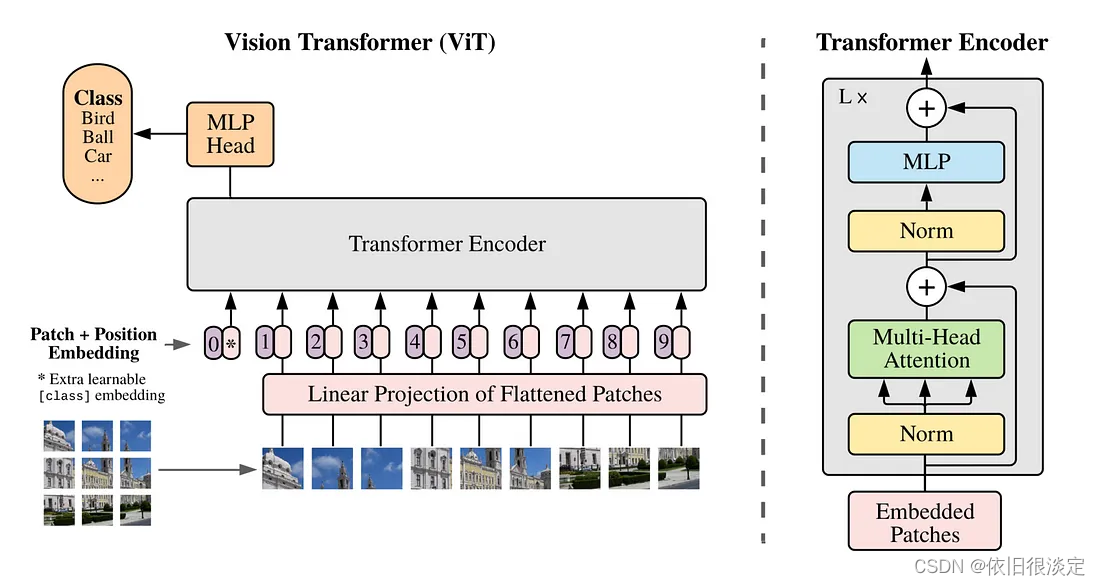
传统上,对于视觉转换器,我们使用一系列图像“补丁”来训练用于图像识别的转换器模型,而不是用于语言转换器的单词。这些补丁使我们能够摆脱卷积神经网络进行图像处理。

然而,对于视觉转换器,图像训练数据的大小和纵横比是固定的,这限制了质量,并且需要大量的图像预处理。

通过将视频视为补丁序列,Sora 保持了原始的纵横比和分辨率,类似于 NaViT 对图像的处理。这种保存对于捕捉视觉数据的真正本质至关重要,使模型能够从更准确的世界表示中学习,从而赋予 Sora 近乎神奇的准确性。
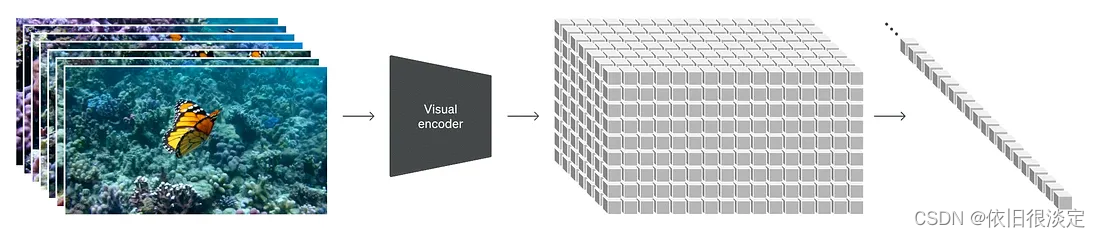
该方法使 Sora 能够有效地处理各种视觉数据,而无需调整大小或填充等预处理步骤。这种灵活性确保了每条数据都有助于模型的理解,就像厨师如何使用各种食材来增强菜肴的风味特征一样。
通过时空补丁对视频数据进行详细而灵活的处理,为精确的物理模拟和 3D 一致性等复杂功能奠定了基础。这些功能对于创建不仅看起来逼真而且符合世界物理规则的视频至关重要,让我们得以一窥 AI 创建复杂、动态视觉内容的潜力。
喂养 Sora:多样化数据在训练中的作用
训练数据的质量和多样性对于生成模型的性能至关重要。传统的视频模型是在限制性更强的数据集、更短的长度和更窄的目标上进行训练的。
Sora 利用了庞大而多样的数据集,包括不同持续时间、分辨率和纵横比的视频和图像。它能够重新创建像《我的世界》这样的数字世界,它可能还包括来自虚幻或Unity等系统的游戏玩法和模拟世界镜头,以捕捉视频内容的所有角度和各种风格。这使 Sora 进入了一个“通才”模型,就像文本的 GPT-4 一样。
这种广泛的培训使Sora能够理解复杂的动态,并生成既多样化又高质量的内容。该方法模仿了在各种文本数据上训练大型语言模型的方式,将类似的理念应用于视觉内容以实现通才功能。

正如 NaViT 模型通过将来自不同图像的多个补丁打包到单个序列中来展示显着的训练效率和性能提升一样,Sora 利用时空补丁在视频生成中实现类似的效率。这种方法允许从庞大的数据集中更有效地学习,提高模型生成高保真视频的能力,同时降低与现有建模架构相比所需的计算量。
让物理世界栩栩如生:Sora对3D和连续性的掌握
3D空间和物体持久性是Sora演示中的关键亮点之一。通过对各种视频数据进行训练,无需对视频进行调整或预处理,Sora 学会了以令人印象深刻的精度对物理世界进行建模,因为它能够以原始形式使用训练数据。
它可以生成数字世界和视频,其中物体和角色在三维空间中令人信服地移动和交互,即使它们被遮挡或离开框架也能保持连贯性。
展望未来:Sora的未来影响
Sora 为生成模型的可能性设定了新标准。这种方法很可能会激发开源社区对视觉模式的实验和改进,从而推动新一代生成模型的出现,从而突破创造力和现实主义的界限。
Sora 的旅程才刚刚开始,正如 OpenAI 所说,“扩展视频生成模型是构建物理世界通用模拟器的一条有前途的道路”
Sora的方法将最新的人工智能研究与实际应用相结合,预示着生成模型的光明未来。随着这些技术的不断发展,它们有望重新定义我们与数字内容的互动,使高保真、动态视频的创作更易于访问和通用。
节选自:《解释 OpenAI Sora 的时空补丁:关键因素》OpenAI 视频生成式 AI 的幕后花絮
这篇关于解释 OpenAI Sora 的时空补丁:关键因素的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






