者注:
中国的数据库行业也迎来了一波新的热点事件。分布式数据库这块新消息不断,也让大家开始关注中国的分布式数据库。首先是短短一周内,Pingcap和SequoiaDB巨杉数据库陆续宣布了C轮的数千万美元融资,融资的消息在数据库和IT圈成功“刷屏”。此后,在杭州的云栖大会上,蚂蚁金服的Oceanbase也发布了 2.0。对于这些新消息,也侧面反映了国产的开源分布式数据库发展的迅速。那么这些国产分布式数据库,在互联网行业中的实践与使用上是如何呢?与传统开源数据库的对比如何?就由这篇文章作为去哪儿网这边的实践介绍。
开源数据库百花齐放新时代
MySQL目前是全球最流行,用户最多的开源数据库这是无可非议的事实。而同时,开源数据库PostgreSQL也一直在不断发展壮大,当然还包括众多的新一代NoSQL、NewSQL数据库不断涌现。
此前,本人有幸参与“MariaDB/MySQL vs PostgreSQL世纪大决战”,现场火药味十足。作为为MySQL战队的一员,我个人认为,“大决战”可能并不准确,更多的应该是碰撞,因为有史以来,在数据库界,两家不同数据库被摆到台上公开对标,他们应该是第一次走得这么近,我担心的是,这样的现象以后还会不会出现。
其实技术本身都是好的,我个人认为,我们应该本着“百花齐放、百家争鸣”的态度来学习,来使用。如果没有PostgreSQL,也许MySQL不会有现在这么好的口碑,当然反过来,如果没有了MySQL,PostgreSQL也亦因为找不到对手而感觉孤独不少。一家是“The world’s most advanced open source database”,另一家是“The world’s most popular open source database”,他们本来就应该相互学习,相互进步,所以这样的“碰撞”,以后应该还会再有,期待下一届“开源数据库大会”的到来。
MySQL是否是唯一选择?
而现在的事实是,MySQL确实如其所述,是“most popular”的开源数据库,而PostgreSQL确实做到了“most advanced”,这点在“世纪大决战”中也体现的淋漓尽致,做为“most advanced”的数据库PostgreSQL,难免显得有点高(级)冷(清),因为相比“most popular”的MySQL而言,用户确实少多了。MySQL在“popular”方面,做得确实不错,非常成功。因为正如大家所看到的,只要用到了数据库,绝大多数都会考虑MySQL,因为这个问题还是和我的观念比较契合的,所以我认为,任何结果,都是有其深层次的原因的,MySQL的popular,原因可能有以下几点:
1. 开源,这个可能无需多提,这个相比PostgreSQL,他没有优势,因为PostgreSQL也是开源的。
2. 简单,MySQL入门可以说是非常简单的,这个大家应该都有感受,只要想用数据库,除了使用access之外,MySQL可能就是不二之选了。
3. 插件式,插件式也是两面性的,一方面限制了他的发展;另一方面,灵活,功能强大,因为有很多插件可以自己选择,应用自如,而用户看重更多的是后者。
4. 先入为主,在PostgreSQL想要流行起来的时候,MySQL已经流行起来了。
5. 互联网大公司推动,在去O大潮中,因为上面的原因,大型互联网公司的推动,首选的是MySQL,导致了MySQL的快速发展。
原因有很多,现在的结果是,MySQL确实太火了,并且再加上MGR的出现,“用MGR完事”,也许真的是这样。
但MySQL也有其缺点,那就是他的存储都是单点。这当然也是大型通用数据库的通病,一般都需要通过多点冗余来实现数据的高可用、高性能,但如果数据量再大了,即超出单盘容量(目前PCIe SSD卡最大容量达到12.8T)之后,MySQL可能就出现瓶颈了,当然这也是有解的。
我们去哪儿的解决办法,通常都是在业务上面拆分,比如总数据量是20T,那就拆10个集群,每个集群都是2T的数据量,这样就可以解决存储的问题了,当然这都是从业务逻辑上面解决的,需要加上路由表来控制数据的存储节点位置。这样的解决办法,虽然可以解决问题,但是当下可能更多人想要的是一个更advanced的解决方案,即现在很火的分布式数据库。
理想中的解决方案是,我们无需关心数据存储,我们只需要向一个节点上写入,或者从一个节点上读取即可。不但数据量可以为任意大小,当这个节点挂了,我们还可以随时启动另一个节点“顶上”即可实现故障转移,这样就实现了真正的“云存储”。在这样的“云存储”中,我们不需要关心其高可用、多副本、容量、性能等问题,也不需要关心是不是存在多点写入,读写节点可以随时扩展,也许这样才是我们心目中的分布式。
所以从这点来看,MGR还是存在单盘的问题,并不能解决数据量极大情况下的分布式问题。
分布式数据库
那有没有比较好的,类似我们心目中的分布式数据库呢,我想是有的,至少是向这个方向在走。去哪儿网也一直在探索,所以我的要求基本有以下几点:
1. 要兼容MySQL,因为本人就是MySQL重度研究与使用者,高度认可MySQL这个数据库的架构及使用方式等(中毒已深)。兼容MySQL这个要求,其实是非常高的,我们每个人都知道。只是MySQL的语法比较乱(说到代码实现,可能更多的是骂了),很松散,如果说做到了90%的兼容度,那是不够的,最好要做到100%,这能做到吗?我想是可以的。
2. 存储率高,使用分布式数据库的业务,大部分应该是存储分析型,如果使用了分布式数据库,还需要占用太多的硬件资源,且存储不了太多数据的话,那这个在成本上就非常高了,得不偿失。
3. 有健全的圈子,使用中难免会碰到问题,碰到问题的时候,现在处于分布式发展的初级阶段,所以社区的人比较少,而只能去求助官方,如果官方不能提供帮助(也许是没给钱),那这样的数据库,可能就不具有诱惑力了,风险太大。
4. 性能够用,在使用了分布式数据库之后,其实已经默认接受了降低性能要求的条件,所以我们的要求只是说,性能够用即可,不会去和单点MySQL去比,因为没有意义。够用就好,当然在这方面如果足够好,那是再好不过了。
5. 少技术栈,这样的需求是非常高的,因为技术栈太长,会加重运维人员的成本,并且在现在这样人才难找更难招的情况下,这样的愿望是更迫切的。
符合这样要求的分布式数据库有吗?
最近在开源数据库大会上向开源社区做出分享的SequoiaDB巨杉数据库,这个名称应该是比较熟悉了,他们已经做了很多年的分布式数据库,只是最近才出现在了MySQL社区。其实一个很重要的原因就是,他们终于想清楚了,或者说意识到了MySQL的重要意义,所以他们也与MySQL保持了亲密关系,或者更准确的说,巨杉数据库,成为了MySQL圈内的一员,属于真正的MySQL体系。
SequoiaDB巨杉数据库
根据官方网站介绍,巨杉作为中国数据库产品,技术上,SequoiaDB的3.0版本采用了计算-存储分离的架构,这一架构是的SQL和存储引擎实现了松耦合,在资源分配和通用性上优化空间更大。其中,SequoiaDB的数据存储引擎是巨杉完全自研的分布式JSON数据存储引擎,是完全从零开始自研的。而数据库所有的数据管理、分布式控制、事务、ACID功能支持等都是在SequoiaDB的分布式存储引擎里完成的。SQL层,目前SequoiaDB通过连接器(sequoiasql-mysql)直接使用了MySQL的原生解析器,实现MySQL的完整兼容,同时目前也支持PGSQL和SparkSQL。
 1. 为什么说巨杉数据库属于MySQL体系内呢?因为他做到了一点,就是100%兼容了MySQL的语法,更准确的说,他成为了MySQL的一个插件,说到插件,我想每个人都熟悉,因为你不会觉得MySQL插件不是MySQL体系内的。所以这点完全满足了我的第一个需求,作为一个MySQL工作者,最喜欢看到这样的场景了;
1. 为什么说巨杉数据库属于MySQL体系内呢?因为他做到了一点,就是100%兼容了MySQL的语法,更准确的说,他成为了MySQL的一个插件,说到插件,我想每个人都熟悉,因为你不会觉得MySQL插件不是MySQL体系内的。所以这点完全满足了我的第一个需求,作为一个MySQL工作者,最喜欢看到这样的场景了; 2. 存储率方面,巨杉数据库,只需要三个节点就可以了;
3. 在健全的圈子方面,我想,巨杉做为一个MySQL的插件,这个圈子够大了,因为MySQL Server层的问题,我们自己就可以解决,仅剩下的巨杉数据库本身,那可能就需要去不断的学习与分享了,但至少少了很多问题;
4. 性能方面,我们已经测试过,在只向一个IP端口读写(数据没有分区,sdb只有一个节点)的情况下,性能基本是MySQL单点的三分之二,这是可以接受的,因为做为分布式数据库,这样的使用方式,必然是比不上单点MySQL的,这里重点在测试性能损失多少,如果想提升性能,则可以增加分区,或者增加协调节点等方式来实现,从而可以做到最大限度的发挥他的分布式优势;
5. 技术栈方面,这个和MySQL还是脱不了关系,对于Server层,轻车熟路,巨杉存储引擎,也只是几个独立进程,架构清楚简单,维护起来不会有太大困难。
巨杉数据库架构设计详解
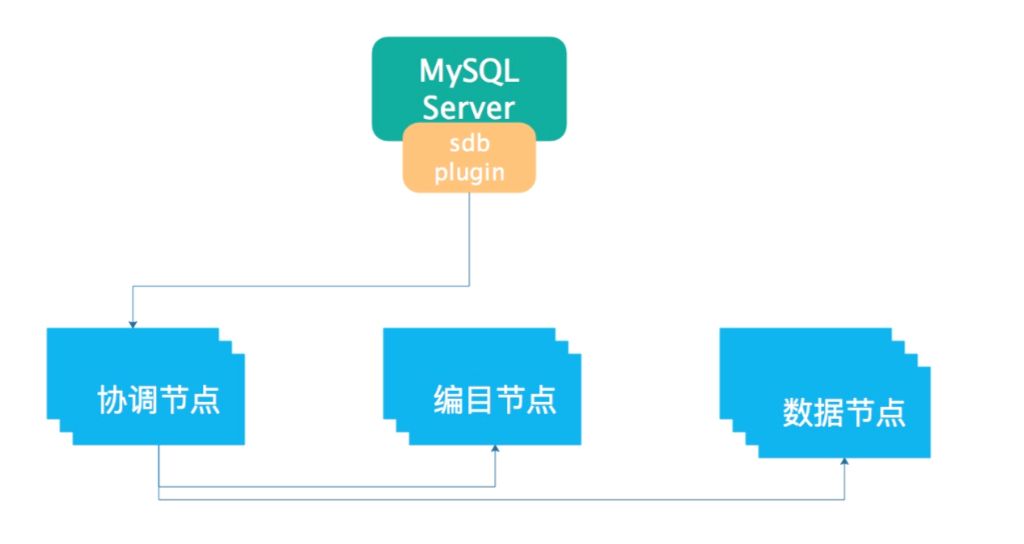 上面是巨杉数据库的架构图。这里涉及到多个模块,下面分别做一个解释:
上面是巨杉数据库的架构图。这里涉及到多个模块,下面分别做一个解释: 1. 协调节点:用来做数据的路由的,他的作用更像一个中间件,他会根据数据访问的KEY,以及编目节点,来确定数据的存储位置。可以有多个协调节点,用来提供更高的性能;
2. 编目节点:用来存储路由信息的,与数据节点配合,可以最终定位数据;
3. 数据节点:用来存储数据的;
4. sdb plugin:这就是MySQL插件,巨杉数据库,本身与MySQL没有任何关系,但MySQL通过这个插件,实现了所有访问数据的接口,二者这才建立了关系,所以sdb plugin更多的是一个适配器。MySQL Server与巨杉数据库的协议转换器。
从架构上来看,这真正的实现了MySQL的云化存储方案。此时的MySQL Server,自身不会存储任何内容,其作用更多的被转化为一个中间件了。
做为一个存储引擎,在创建一个表的时候,还需要遵守MySQL本身的规则,比如还需要创建一个frm文件。其实个人认为,这个frm文件,和巨杉数据库中对应的表没有强关联,它只是为了“骗过”MySQL Server,让其知道,这个表是存在的,可以正常访问这个数据库,那么在骗过MySQL Server之后,就会走到存储引擎层的访问。
在顺利通过了MySQL Server的各种考验之后,就到了存储引擎的访问,因为巨杉实现了所有的存储引擎与Server层的接口,所以存储引擎的访问,就会顺利访问到巨杉的sdb plugin,比如取一条数据、写一条数据、带条件的取数据(MySQL5.6中新增的condition push down特性)等,只要能顺利将Server请求的接口返回正确的数据,那Server层就会正常的处理这些数据,最终返回给客户端。
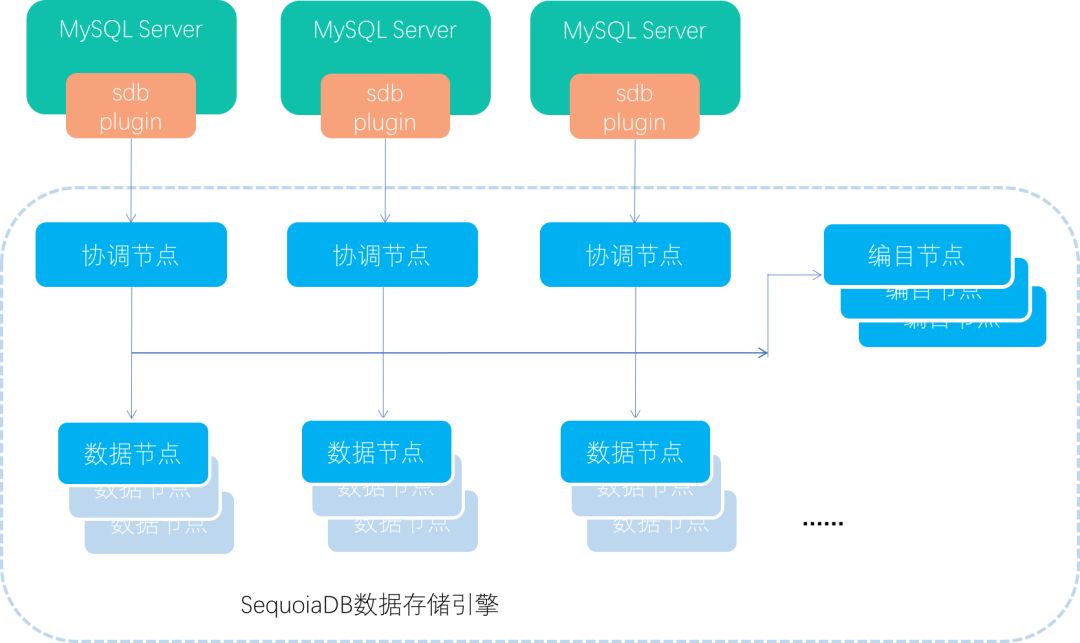 MySQL+SequoiaDB整体架构示意
MySQL+SequoiaDB整体架构示意 在将数据或者请求传给巨杉存储引擎之前,或者将数据从存储引擎返回给Server层的时候,这些所有的操作,与巨杉是没有关系的,这完全是MySQL Server层的工作,这些工作包括语法分析、语义分析、查询优化、MDL锁、数据库权限、如果开了复制,则还会包括主从复制等等,当然还包括我们经常运维的一些命令,比如show processlist; information schema; MySQL库信息的查询。基于这些熟悉的特征,这样的实现方式,给我们非常大的诱惑力。
从上面实现原理来看,从MySQL Server,到巨杉数据库,架构应该是如上图所示的,sdb plugin本身没有存储数据,所以其角色转换为一个轻量级的中间件了,由sdb plugin来转发应用的请求到协调节点,到这里,就是巨杉数据库的天地了,我就不再赘述,我这里重点要讲的是本身架构的问题。
现在把MySQL Server理解为中间层,最好的架构方式就是,有多套MySQL server在运行着,应用可以随便访问任意一套,这样有以下几点好处:
1. 可以增强读写性能。
2. 可以实现读写分离。
3. 可以实现故障转移
4. 支持多点写入功能,在故障切换时,随便切换无影响。
但多套中间层的情况下,就存在一个问题,即配置的同步问题,在这套架构中,配置指的更多的是其元数据,比如表结构,也就是用来“骗过”MySQL Server的表结构,因为如果这些信息在多个节点之间不能同步,首先MySQL Server这层就不能顺利通过,也就无法访问巨杉了。
这个问题目前的解决方案是,巨杉提供了一个脚本,通过MySQL Server的审计功能,订阅MySQL Server层的DDL操作,这样在有元数据变更的时候,自动同步到其它MySQL Server中,这样也就实现了元数据的同步功能。这样实现,既熟悉,又无奈,因为这是MySQL,插件没有办法提供这样的接口来同步元数据,只好这样实现了。不过对于MySQL足够熟悉时,这样的实现也不失为一个好办法。
我们进一步将这个架构完善一下,如下图:
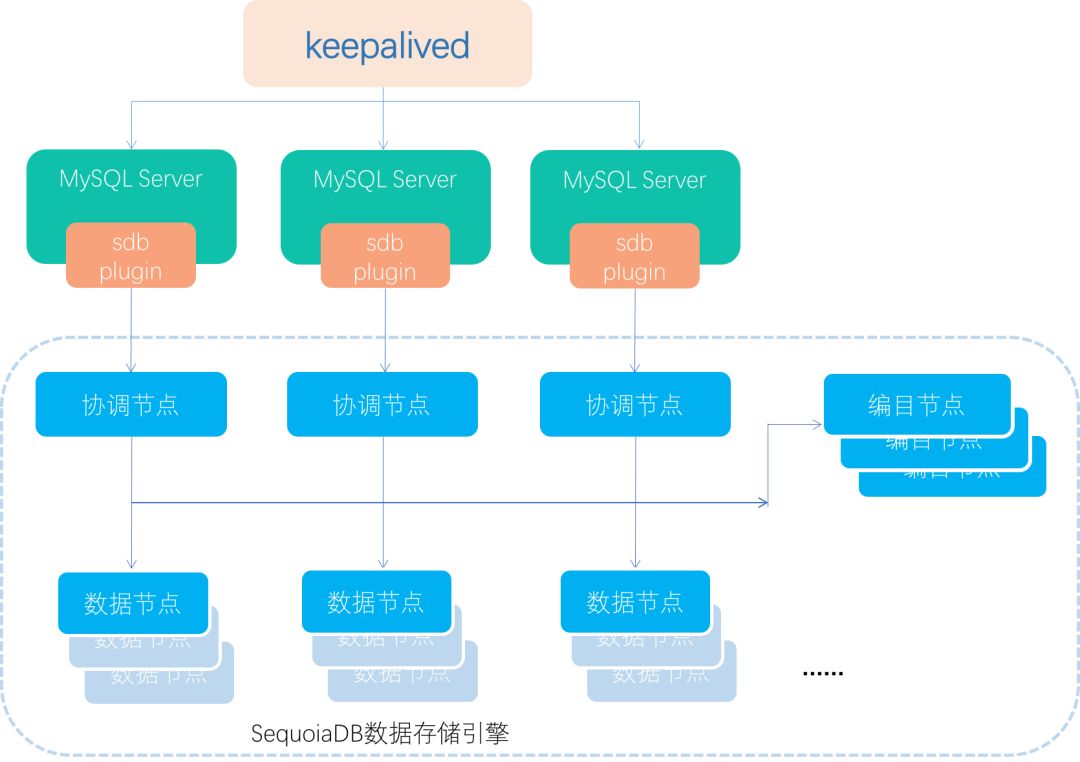 在多个MySQL Server(中间层)前面加上一个Keepalived,将VIP绑定在Server上,如果有一个down了,Keepalived会自动切换到活着的Server上面,实现了自动故障转移。当然也可以不加这层,由业务自行去轮循环判断死活来访问MySQL Server也是可以的,因为使用Keepalived的话,存在一个问题就是VIP切换,在正常维护的时候,也会影响到业务,所以可能会产生这么一点点的不友好。
在多个MySQL Server(中间层)前面加上一个Keepalived,将VIP绑定在Server上,如果有一个down了,Keepalived会自动切换到活着的Server上面,实现了自动故障转移。当然也可以不加这层,由业务自行去轮循环判断死活来访问MySQL Server也是可以的,因为使用Keepalived的话,存在一个问题就是VIP切换,在正常维护的时候,也会影响到业务,所以可能会产生这么一点点的不友好。 当然,如果想做到在正常维护时对业务无任何影响的话,还是再次演进,方案如下:
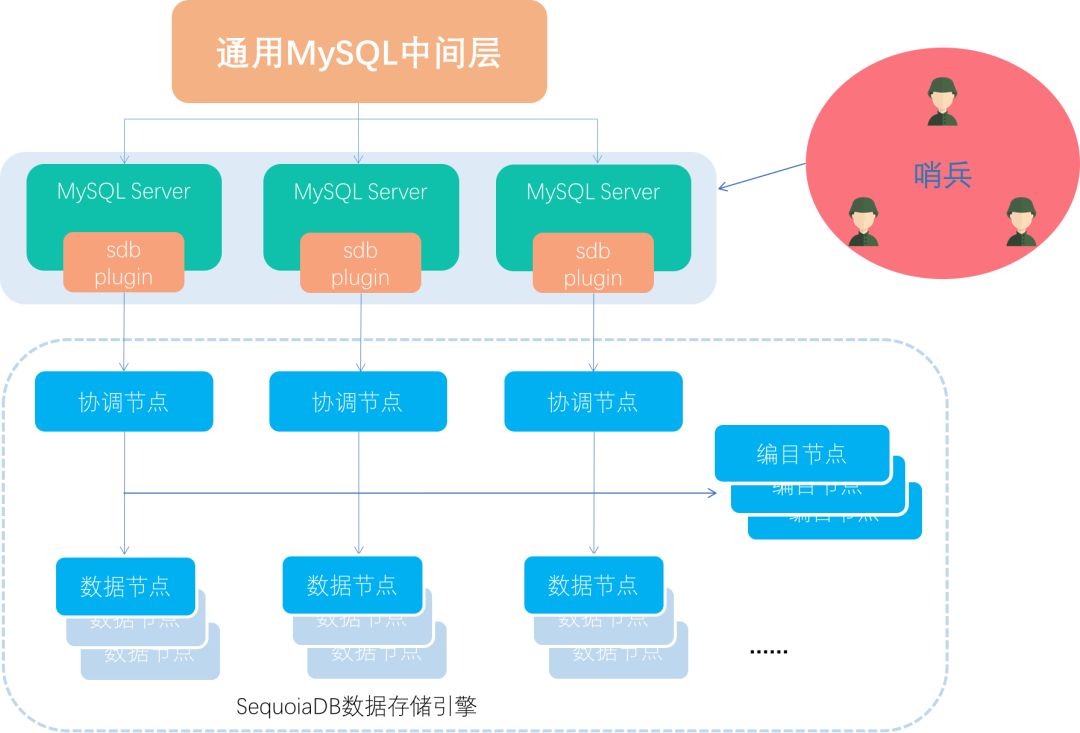 这种情况下,如果MySQL Server正常维护,只需要在通用中间层中做配置,让维护节点下线,这样流量就不会再路由到这个维护节点了,等所有操作执行完之后,就可以正常维护了。或者如果挂了,哨兵会发现其状态变化,哨兵会连接到通用中间层上面,做配置更改,然后就可以实现故障转移。
这种情况下,如果MySQL Server正常维护,只需要在通用中间层中做配置,让维护节点下线,这样流量就不会再路由到这个维护节点了,等所有操作执行完之后,就可以正常维护了。或者如果挂了,哨兵会发现其状态变化,哨兵会连接到通用中间层上面,做配置更改,然后就可以实现故障转移。 不过这种架构其实没有什么太大必要,因为这个时候,MySQL Server非常轻量级,并且其作用已经成为了一个中间层的角色,只有在其所在机器需要关机的时候,或者某些MySQL的参数是只读的情况,但又不得不修改的时候才会去维护,影响并不会太大。
至于巨杉本身架构中,很多节点的高可用如何实现故障转移,我想这可以更多的参考他们的实现原理,拒我所知,其内容使用了raft类似的算法,做选举判断状态等,这些都是目前主流的分布式实现方法,应该是足够可靠了,这里不再做过多赘述了。
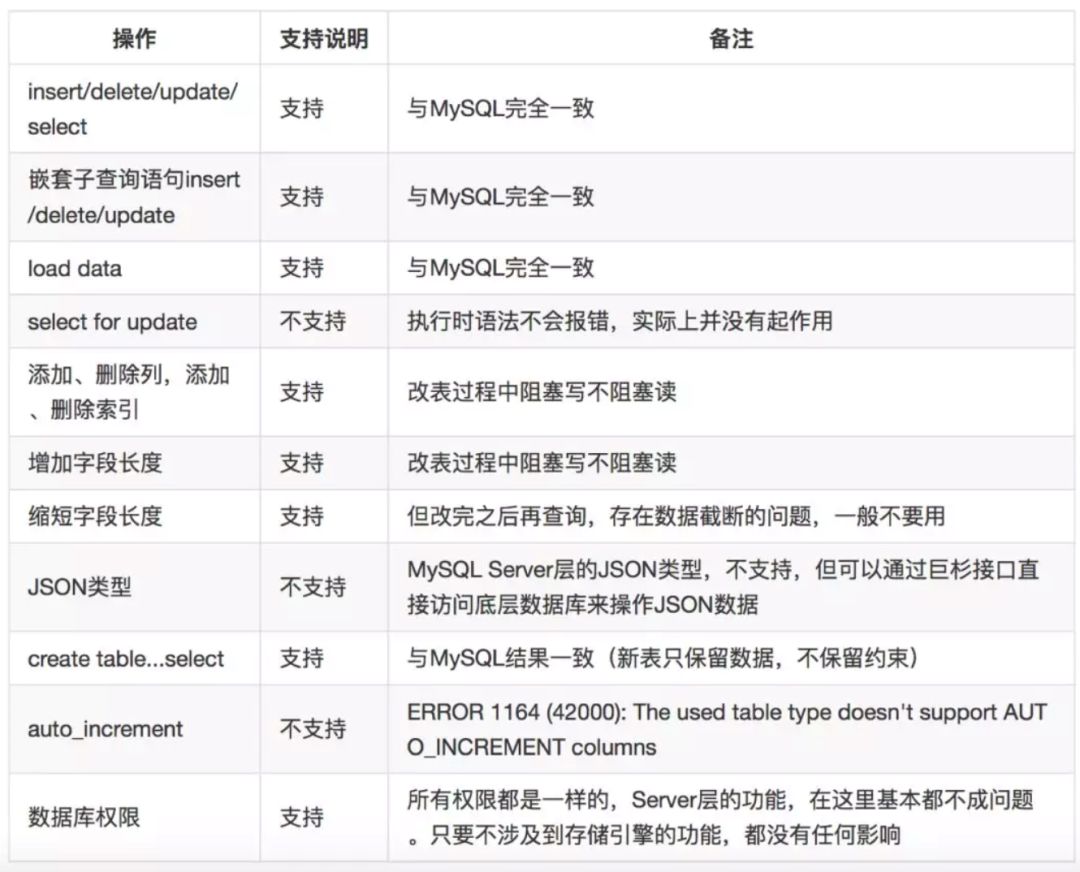
测试情况
 小结
小结 1. 不支持自增列,自增列在MySQL中用得比较多,但实际被使用时,都是一个无意义的列,并没有在业务逻辑中使用,但由于他的自增属性,导致很多业务程序在写SQL的时候,都不会指定这个列的数据,所以对自增列做了强依赖,所以目前巨杉还没有支持这个属性的列,在新业务上面问题不大,对于老业务的迁移,可能在兼容性上面还不够好。不过交流之后,官方声称在几个月之内可以上线。
2. 元数据同步,之前已经提到过了,只能说是不完美,功能是有了。
在经过功能和性能的测评之后,SequoiaDB已经满足了我们的要求,我们也将会在近期在合适的场景进行上线使用。
MySQL的未来肯定是光明的,我希望有更多的开源软件能加入到MySQL这个圈子里来,一起碰撞,一起共享,一起成长。我们也希望巨杉数据库可以很快的建立起一个分享技术的圈子,可以让更多人在开源的社区内受益。
作者简介:
王竹峰,去哪儿网数据库总监,中国计算机行业协会开源数据库专业委员会常务理事。擅长数据库开发、数据库管理及维护,一直致力于MySQL数据库源码的研究与探索,对数据库原理及实现有深刻的理解。曾就职于达梦数据库,从事多年数据库内核开发工作,后转战人人网,任职高级数据库工程师,目前在去哪儿网负责MySQL源码研究与运维、数据库管理和自动化运维平台设计开发及实践工作,是Inception开源项目及《MySQL运维内参》的作者,也是国内少数几个MySQL方向的Oracle ACE之一。







