本文主要是介绍杂谈--spconv导出中onnx的扩展阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Onnx 使用
Onnx 介绍

Onnx (Open Neural Network Exchange) 的本质是一种 Protobuf 格式文件,通常看到的 .onnx 文件其实就是通过 Protobuf 序列化储存的文件。onnx-ml.proto 通过 protoc (Protobuf 提供的编译程序) 编译得到 onnx-ml.pb.h 和 onnx-ml.pb.cc 或 onnx_ml_pb2.py,然后用 onnx_ml.pb.cc 和代码来操作 onnx 模型文件,实现增删改操作。onnx-ml.proto 则是描述 onnx 文件如何组成和结构,用于作为操控 onnx 的参照。但是这个.proto 文件(里面用的是 protobuf 语法)只是一个中间表示文件,不具备任何能力,即并不面向存储和传输(序列化,反序列化,读写)。所以需要用 protoc 编译 .proto 文件,是将 .proto 文件编译成不同语言的实现,得到 .cc 和 .py 文件这两个接口文件,这样不同语言中的数据就可以和自定义的结构化数据格式的数据进行交互。
onnx-ml.proto
查看 onnx-ml.proto 文件可以看到每个 proto 的不同的数据结构,message 就是结构化数据的关键字,用于描述数据的字段、类型和层次结构。之后加载了 onnx 模型后,就可以按照这个文件内部记录的数据结构来访问模型中的数据。

使用 repeated 就表示内部的属性是数组,使用 optional 就表示数据可选。NodeProto 中 input 就是一个数组,其中储存着 string,需要使用索引访问,name 就是一个 string。这些参数后面的数值表示每个属性特定的 id,这些 id 是不能冲突的,官方已经指定好了。
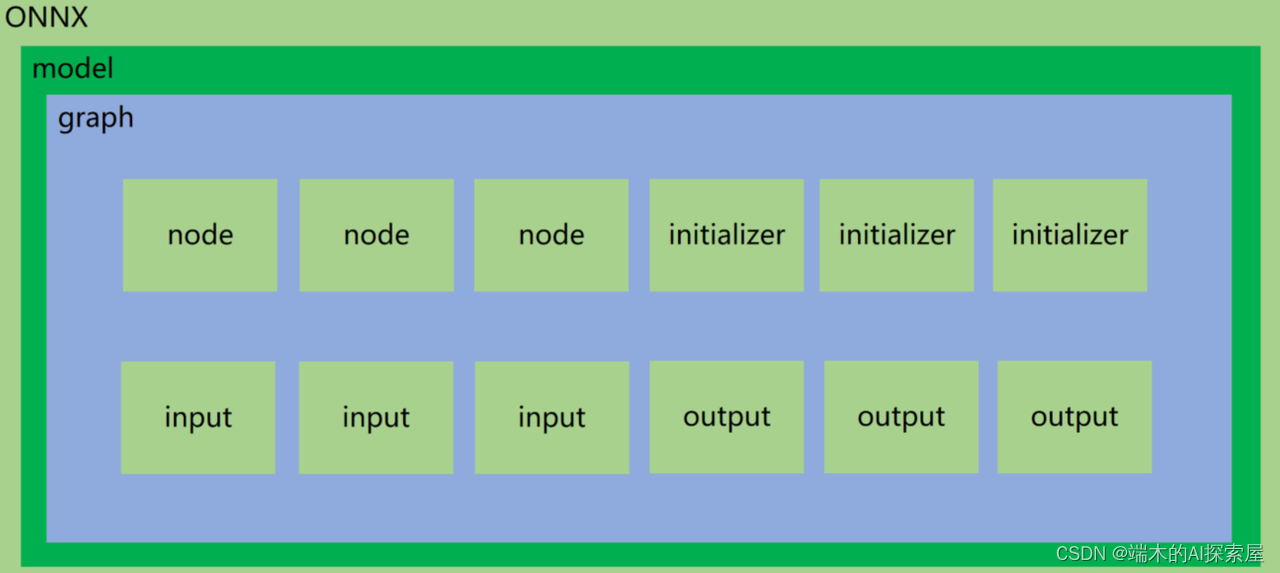
Onnx 结构
-
onnx.model: 这是一个具体的 ONNX 模型实例,它是一个
ModelProto对象,可以通过onnx.helper.make_model来构建。它包含了模型的所有信息,包括元数据、图(graph)、初始参数等。代码中对应ModelProto,其中opset_import是OperatorSetIdProto数据结构的数组;graph是GraphProto数据结构,一个 model 对应一个 graph。 -
onnx.model.graph: 这是 onnx 模型的计算图,它是一个
GraphProto对象,可以通过onnx.helper.make_graph来构建。计算图是一种描述模型计算过程的图形结构,它由一系列的节点 (node) 组成,这些节点代表了模型中的各种操作 (如卷积、激活函数等)。代码中对应GraphProto,其中node是NodeProto数据结构的数组;initializer是一个TensorProto数据结构的数组;sparse_initializer是一个SparseTensorProto数据结构的数组;input、output和value_info是ValueInfoProto数据结构的数组。 -
onnx.model.graph.node: 这是计算图中的一个节点,它是一个
NodeProto对象,可以通过onnx.helper.make_node。每个节点代表了一个操作,它有一定数量的输入和输出,这些输入和输出都是张量。节点还有一个操作类型 (如"Conv"、"Relu"等) 和一些特定的参数 (如卷积核的大小、步长、填充等)。代码中对应NodeProto,其中input和output是string类型数组;attribute是一个AttributeProto数据结构,用于定义 node 属性,常见用法是将 (key, value) 传入 Proto 中;op_type是一个string,需要对应 onnx 提供的 operators。 -
onnx.model.graph.initializer: 这是模型的初始化参数,它是一个
TensorProto对象,可以通过onnx.helper.make_tensor。每个TensorProto对象都包含了一个张量的所有信息,包括数据类型、形状、数据等。模型的所有权重和偏置都包含在这个列表中。代码中对应TensorProto,其中dims是int64类型数组;raw_data是bytes类型。 -
onnx.model.graph.input/output: 这是模型的输入/输出信息,它是一个
ValueInfoProto对象,可以通过onnx.helper.make_value_info或onnx.helper.make_tensor_value_info。每个ValueInfoProto对象描述了一个输入/输出的信息,包括名称、数据类型、形状等。主要是用于标记哪些节点是输入/输出。代码中对应ValueInfoProto,其中type是一个TypeProto数据结构,内部定义了标准 onnx 数据类型。
ONNX 模型的计算图中的节点可以有多种类型,其中包括 Constant,表示一种特殊的操作,它的作用是在计算过程中提供一个常量张量。这种常量张量的值在模型训练过程中不会改变,因此被视为常量。例如,对于大小为 (bs, N, H, W, 2) 的 anchorgrid 张量(其中,bs 是批处理大小,N 是锚框(anchor box)的种类数量,H 和 W 分别代表特征图的高度和宽度,最后的** 2 **代表每个锚框的宽度和高度),它可以被存储在一个 Constant 类型的节点中。值得注意的是,当使用ONNX图形可视化工具(如Netron)时,Constant 类型的节点可能不会显示出来。这是因为这些节点并不涉及任何计算操作,只是提供了一个常量张量。
另外,还有一种类型为"Identity"的节点。"Identity"节点表示一种标识操作,它的输出和输入完全相同。这种节点通常用于在需要保持计算图结构完整性的情况下,将某些张量传递到计算图的下一层。换句话说,它不会改变传递给它的任何信息,可以被视为一个透明的或者无操作的节点。
Onnx 模型生成
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import osclass Model(torch.nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(1, 1, 3, padding=1)self.relu = nn.ReLU()self.conv.weight.data.fill_(1)self.conv.bias.data.fill_(0)def forward(self, x):x = self.conv(x)x = self.relu(x)return x# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))model = Model()#dummy如果改成torch.zeros(8, 1, 3, 3),对生成的onnx图是没有影响的
dummy = torch.zeros(1, 1, 3, 3)#生成的onnx图的conv算子的bias为1,这是由输出通道数决定的,因为输出通道为1
torch.onnx.export(model, # 这里的args,是指输入给model的参数,需要传递tuple,因此用括号(dummy,), # 储存的文件路径"demo.onnx", # 打印详细信息verbose=True, # 为输入和输出节点指定名称,方便后面查看或者操作input_names=["image"], output_names=["output"], # 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11opset_version=11, # 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1# 通常,我们只设置batch为动态,其他的避免动态dynamic_axes={"image": {0: "batch", 2: "height", 3: "width"},"output": {0: "batch", 2: "height", 3: "width"},}
)print("Done.!")
Onnx 模型加载
import onnx
import onnx.helper as helper
import numpy as npmodel = onnx.load("demo.onnx")#打印信息
print("==============node信息")
# print(helper.printable_graph(model.graph))
print(model)conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]# initializer里有dims这个属性是可以通过打印model看到的
# dims在onnx-ml.proto文件中是repeated类型的,即数组类型,所以要用索引去取!
print(conv_weight.dims)
# 取node节点的第一个元素
print(f"===================={model.graph.node[1].name}==========================")
print(model.graph.node[1])# 数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存,通过np.frombuffer方法还原成类型为float32的ndarray
print(f"===================={conv_weight.name}==========================")
print(conv_weight.name, np.frombuffer(conv_weight.raw_data, dtype=np.float32))print(f"===================={conv_bias.name}==========================")
print(conv_bias.name, np.frombuffer(conv_bias.raw_data, dtype=np.float32))
==============node信息
ir_version: 6
producer_name: "pytorch"
producer_version: "1.13.1"
graph {node {input: "image"input: "conv.weight"input: "conv.bias"output: "/conv/Conv_output_0"name: "/conv/Conv"op_type: "Conv"attribute {name: "dilations"ints: 1ints: 1type: INTS}attribute {name: "group"i: 1type: INT}attribute {name: "kernel_shape"ints: 3ints: 3type: INTS}attribute {name: "pads"ints: 1ints: 1ints: 1ints: 1type: INTS}attribute {name: "strides"ints: 1ints: 1type: INTS}}node {input: "/conv/Conv_output_0"output: "output"name: "/relu/Relu"op_type: "Relu"}name: "torch_jit"initializer {dims: 1dims: 1dims: 3dims: 3data_type: 1name: "conv.weight"raw_data: "\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?"}initializer {dims: 1data_type: 1name: "conv.bias"raw_data: "\000\000\000\000"}input {name: "image"type {tensor_type {elem_type: 1shape {dim {dim_param: "batch"}dim {dim_value: 1}dim {dim_param: "height"}dim {dim_param: "width"}}}}}output {name: "output"type {tensor_type {elem_type: 1shape {dim {dim_param: "batch"}dim {dim_value: 1}dim {dim_param: "height"}dim {dim_param: "width"}}}}}
}
opset_import {version: 11
}[1, 1, 3, 3]
====================/relu/Relu==========================
input: "/conv/Conv_output_0"
output: "output"
name: "/relu/Relu"
op_type: "Relu"====================conv.weight==========================
conv.weight [1. 1. 1. 1. 1. 1. 1. 1. 1.]
====================conv.bias==========================
conv.bias [0.]
这个是 TensorProto 中使用的数据类型,initializer 中的 data_type 为 1 就表示数据类型为 FLOAT。
https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.proto#L88
https://onnx.ai/onnx/search.html?q=SparseConvolution&check_keywords=yes&area=default#

通过 helper 自定义 Onnx 模型
import onnx # pip install onnx>=1.10.2
import onnx.helper as helper
import numpy as np# https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.protonodes = [helper.make_node(name="Conv_0", # 节点名字,不要和op_type搞混了op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。outputs=["3"], pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。group=1,dilations=[1, 1],kernel_shape=[3, 3],strides=[1, 1]),helper.make_node(name="ReLU_1",op_type="Relu",inputs=["3"],outputs=["output"])
]initializer = [helper.make_tensor(name="conv.weight",data_type=helper.TensorProto.DataType.FLOAT,dims=[1, 1, 3, 3],vals=np.array([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], dtype=np.float32).tobytes(),raw=True),helper.make_tensor(name="conv.bias",data_type=helper.TensorProto.DataType.FLOAT,dims=[1],vals=np.array([0.0], dtype=np.float32).tobytes(),raw=True)
]inputs = [helper.make_value_info(name="image",type_proto=helper.make_tensor_type_proto(elem_type=helper.TensorProto.DataType.FLOAT,shape=["batch", 1, 3, 3]))
]outputs = [helper.make_value_info(name="output",type_proto=helper.make_tensor_type_proto(elem_type=helper.TensorProto.DataType.FLOAT,shape=["batch", 1, 3, 3]))
]graph = helper.make_graph(name="mymodel",inputs=inputs,outputs=outputs,nodes=nodes,initializer=initializer
)# 如果名字不是ai.onnx,netron解析就不是太一样了
opset = [helper.make_operatorsetid("ai.onnx", 11)
]# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "my.onnx")print(model)
print("Done.!")
Extra
pytorch_quantization.tensor_quant
该模块是用于对张量量化的,通常会使用 QuantDescriptor、TensorQuantFunction 和 FakeTensorQuantFunction。第一个为张量描述器,后面两个是用于对张量进行量化。TensorQuantFunction 和 FakeTensorQuantFunction 中的前向,即量化 (Quantization) 由_tensor_quant 进行计算,反向就是反量化 (Dequantization)。
TensorQuantFunction 和 FakeTensorQuantFunction 代码介绍:
前向:
- TensorQuantFunction 和 FakeTensorQuantFunction 在前向中的操作基本相同的,TensorQuantFunction 会对输入为 torch.half 精度的张量的 scale 进行截断操作,FakeTensorQuantFunction 中没有这样的操作。
- TensorQuantFunction 的输出是量化后的张量和 scale,FakeTensorQuantFunction 的输出仅仅是量化后的张量。
反向:
- TensorQuantFunction 和 FakeTensorQuantFunction 的反向过程是相同的。
pytorch_quantization.tensor_quant.QuantDescriptor
量化描述器,主要用于描述一个张量如何被量化,内部记录了量化方式、校准方法、缩放因子、零点等信息。
一般用于描述网络中的输入和权重。
QuantMixin 和 QuantInputMixin
QuantMixin 用于表示网络中有输入和权重,在进行量化时,要对这两个部分进行量化。
pytorch_quantization.nn.TensorQuantizer
TensorQuantizer 创建需要 Descriptor 做为入参。TensorQuantizer 通过量化描述器中的量化参数和量化方法来调用相应的量化方法从而实现对张量的量化。
Protobuf
Protocol Buffers(简称 Protobuf)是一种轻量级、高效的数据序列化格式,由 Google 开发。它旨在支持跨平台、跨语言的数据交换和存储。
Protobuf 使用一种结构化的数据描述语言来定义数据的结构和格式,这些描述文件被称为 .proto 文件。通过定义 .proto 文件,您可以指定消息的字段和数据类型,并使用 Protobuf 编译器将其转换为特定语言的类或结构体,用于在不同的编程语言中进行数据的序列化和反序列化。
与其他数据序列化格式相比,Protobuf 具有以下优势:
- 高效性:Protobuf 使用二进制编码,因此比文本格式(如 JSON、XML)更紧凑,占用更少的存储空间和网络带宽。
- 快速性:由于 Protobuf 的编解码过程是基于生成的高效代码实现的,因此比通用的解析器更快。
- 可扩展性:您可以在已定义的消息结构中添加新的字段,而不会破坏现有数据的兼容性。接收方可以选择性地忽略他们不理解的字段。
- 跨平台和跨语言支持:通过使用 Protobuf,您可以在不同的编程语言和平台之间进行数据交换,因为 Protobuf 提供了多种语言的支持,包括 C++、Java、Python、Go 等。
Protobuf 在众多领域中被广泛使用,特别是在大规模分布式系统、通信协议、数据存储和数据交换等方面。它提供了一种高效、灵活和可扩展的方式来处理结构化数据。
append_initializer 函数介绍
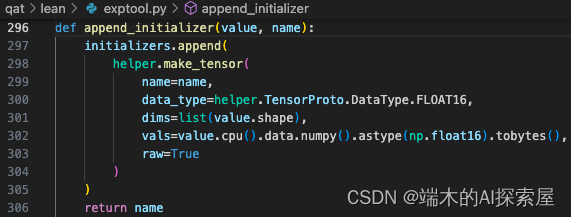
入参:
- value 是模型当前模块的权重,维度经过 permute 之后 KIO 变为 OKI。
- name 用于描述初始化是特定层的权重或偏置。
返回:
- 将 name 作为函数返回值
这里在 initializers 中添加了一个 TensorProto 对象,主要是用于记录权重和偏置的信息,其中记录了数据名称、类型、维度和数值。这里的 name 需要设置为唯一的,不能与其他相同的数据结构的 name 重复。这里的 dims 需要使用 list 来储存,是因为在 TensorProto 数据结构中,是使用 repeated int64 来定义的。raw 设置为了 True,这里的 vals 就需要转换为 bytes 类型,如果是 False,就只需要转换为 np.float16 类型。
make_node 函数介绍
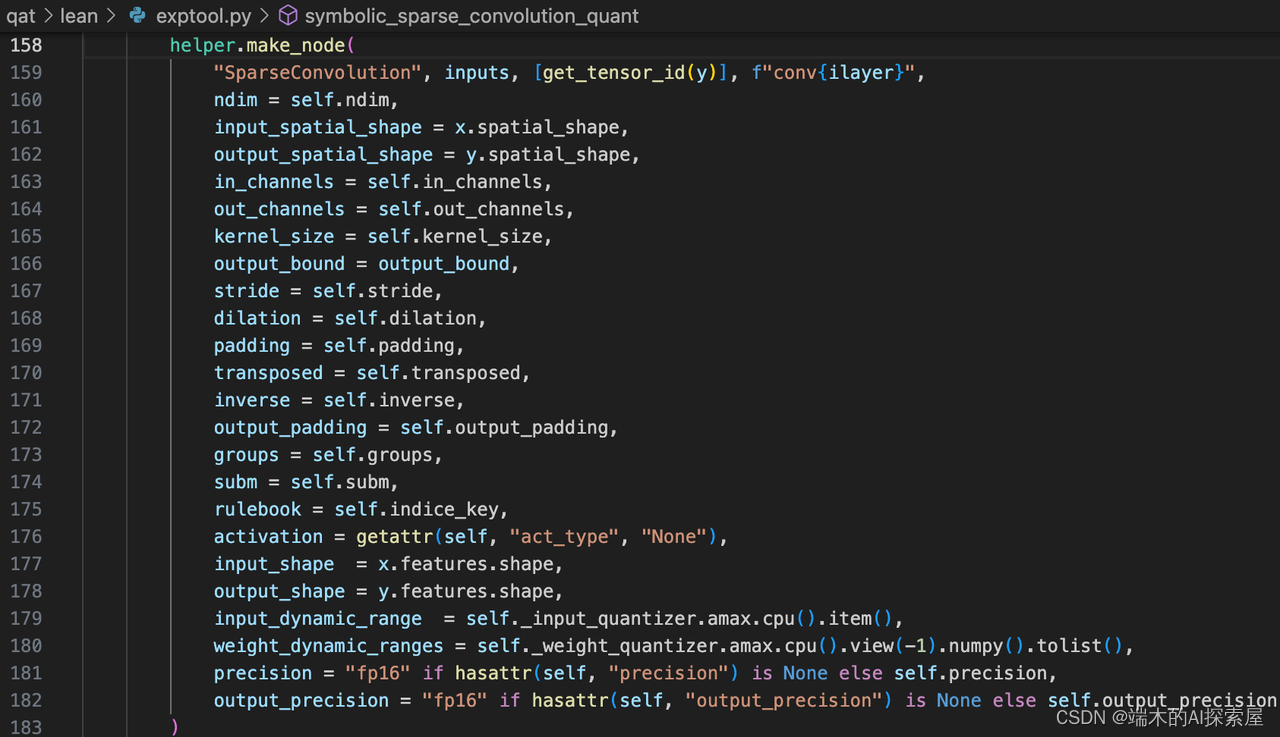
通过 make_node 函数可以创建一个 NodeProto 对象,这个节点会记录了指定的操作,用于之后生成 GraphProto 对象表示计算图。
以上面这段代码为例,先介绍一下参数的含义:
- ops_type:数据类型为 str,该参数需要设置为特定的官方操作类型名称,当前的 ops_type 为 “SparseConvolution”,这里使用了自定义的操作,并不是官方提供的默认操作。
- input/output:数据类型为 list[str],该参数表示节点的输入/输出的名称,当前的 input 为 [‘0’, ‘spconv0.weight’, ‘spconv0.bias’],output 为 [‘1’]。
- name: 数据类型为可选的 str,该参数表示节点的名称,当前的 names 为 conv0。
- doc_string: 数据类型为可选的 str,用于提供节点的文档字符串 (Documentation String),用于描述节点的功能和用途。它对于理解和解释节点的作用非常有用。可以使用该参数为节点添加描述性的文本。这里没有设置该参数。
- domain: 数据类型为可选的 str,指定节点所属的域(Domain)。域是用于标识特定领域或框架的字符串。不同的域可能有不同的操作类型和语义。默认情况下,节点属于 ONNX 的主要域。如果要使用特定域的扩展或自定义操作类型,可以指定相应的域。例如,“com.example.custom” 表示自定义域。域的使用可以帮助在不同框架之间进行模型转换和兼容性。
- **kwargs: 数据类型为 dict,用于描述节点的属性,这里用于储存当前稀疏卷积模块的属性。
这篇关于杂谈--spconv导出中onnx的扩展阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






