本文主要是介绍知识图谱:py2neo导入周杰伦歌单csv文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- py2neo导入csv文件
- py2neo导入周杰伦歌单csv
- 效果展示
py2neo导入csv文件
之前写的知识图谱指南
知识图谱:py2neo将csv文件导入neo4j

因为没有区分不同实体entity的类型,所以颜色相同,无法相互区分歌手、歌曲还是专辑等等。
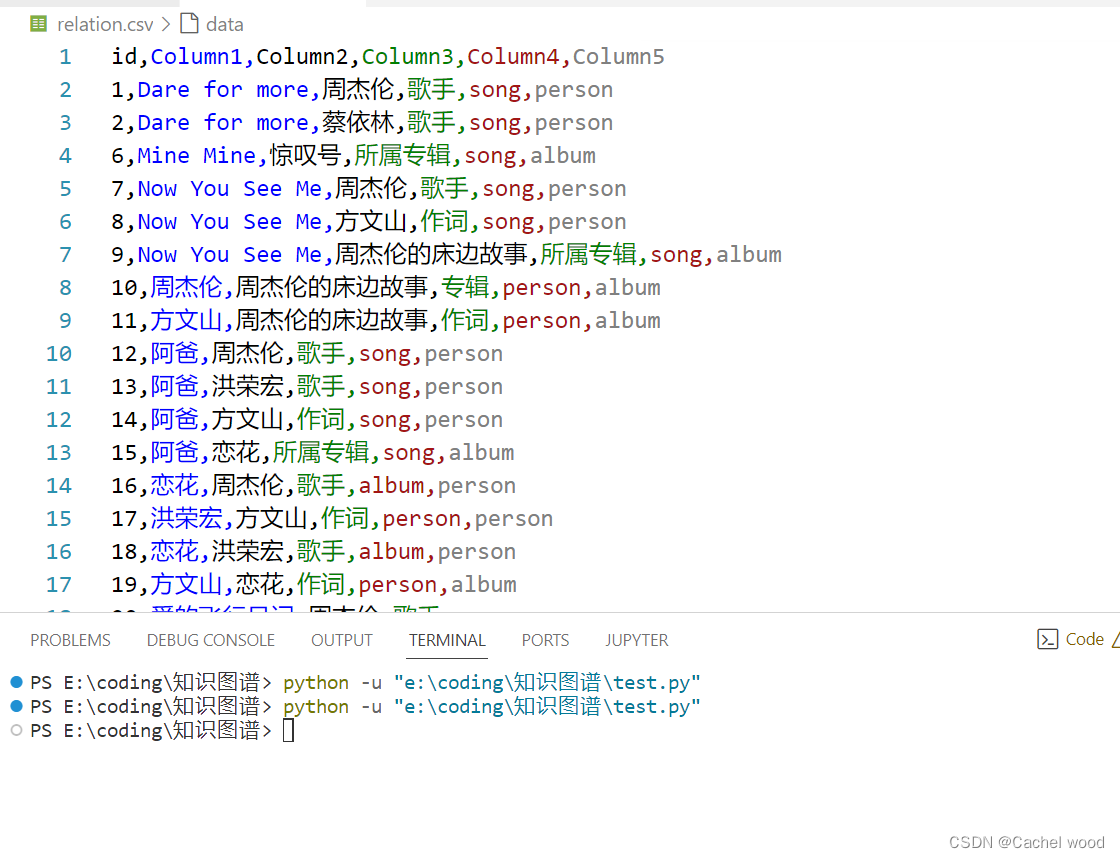
py2neo导入周杰伦歌单csv
如果以普通三元组的形式导入周杰伦歌单csv,会出现很多实体entity的冗余,无法形成完整的知识图谱。
通过添加对前两列的描述,则可以对第一列和第二列进行分类查询,此时如果实体entity已经存在,则不建立新的节点Node。
from py2neo import Graph, Node, Relationship
# 连接neo4j数据库,输入地址、用户名、密码
graph = Graph("http://localhost:7474", name="neo4j", password='xxxx')
import pandas as pddf = pd.read_csv('relation.csv',index_col=0)df
- 代码改进
如果节点没有被创建过,那么正常创建即可;
如果节点已经被创建过,那么通过py2neo的match函数进行节点查询,之后建立关系Relationship。
graph.delete_all() #清除neo4j中原有的结点等所有信息from py2neo import NodeMatcher
entity = []for index,row in df.iterrows():print(entity)if row[0] not in entity:entity.append(row[0])node1 = Node(row[-2],name=row[0])graph.create(node1)else:node_matcher = NodeMatcher(graph)#print(list(node_matcher.match(row[-2]).where(row[0]))) node1 = list(node_matcher.match(row[-2]).where(name=row[0]))[0]if row[1] not in entity:entity.append(row[1]) node2 = Node(row[-1],name=row[1])graph.create(node2)else:node_matcher = NodeMatcher(graph) node2 = list(node_matcher.match(row[-1]).where(name=row[1]))[0]each = Relationship(node1, row[2], node2)graph.create(each)
效果展示
- 保留50个实体

- 保留100个实体

这篇关于知识图谱:py2neo导入周杰伦歌单csv文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





