本文主要是介绍【初中生讲机器学习】9. 我是怎么用朴素贝叶斯实现垃圾邮件分类的?真的超全!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
创建时间:2024-02-14
最后编辑时间:2024-02-15
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名初三学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐ 那就让我们开始吧!
okkkk,大概十天以前我写了一篇关于朴素贝叶斯分类器原理的文章,but 没有更对应的实例代码,这篇来填坑~!
关于朴素贝叶斯的原理,这里:【初中生讲机器学习】5. 从概率到朴素贝叶斯算法,一篇带你看明白!
说到朴素贝叶斯,最出名的应用肯定就是垃圾邮件分类啦!这篇就来实现这个!
先讲大思路:判断一封邮件是否为垃圾邮件,我们需要从它所包含的词语入手(比如如果一封邮件包含 “彩票” 或 “广告”,那它很可能是一封垃圾邮件),也就是说,我们要求出 P ( 垃圾邮件 ∣ 词语 ) P(垃圾邮件|词语) P(垃圾邮件∣词语)。根据上一篇贝叶斯公式的推导, P ( 垃圾邮件 ∣ 词语 ) = P ( 词语 ∣ 垃圾邮件 ) P ( 垃圾邮件 ) P ( 词语 ) P(垃圾邮件|词语) = \frac{P(词语|垃圾邮件)P(垃圾邮件)}{P(词语)} P(垃圾邮件∣词语)=P(词语)P(词语∣垃圾邮件)P(垃圾邮件),等号右边这三个量,就是模型需要通过训练集学习出的。
在支持向量机的实例那一篇,我们是直接从 sklearn 中调用的数据集,但是这次不行了emm,so 我们需要自己下载:click here~,点 “同意协议”,然后下载 “trec06c.tgz” 那个,它是中文邮件数据集,一共有六万多封邮件数据。下载之后解压,注意和项目文件放在同一个文件夹中噢~
好,来看一下目录结构:
trec06c- data(存储所有邮件数据)- 000- 000- 001- ...- 299- 001- ...- 215- delay(没什么用)- index- full(存储所有邮件的标签:spam/ham)- index
嗯。。不过事情没有那么简单(()六万多组数据,内存会炸(我实验过了,的确炸了,but 我实在不想再去服务器训练一次了emm),所以我们可以拿出其中一些来用,我选了 3000 组数据放在一个新文件夹(test)当中。不用担心 3000 组不够,我训练的结果还是很不错的。
test 目录下只复制原 trec06c 目录下的 data 和 full 文件夹即可,并且注意删掉不用的数据,像这样:
okkk,准备完数据我们来导入相关库。
解释一下这些库的功能(注释里也有~):
- re:它负责正则表达式(regular expression),可以使用正则表达式来匹配、搜索和替换文本。
- jieba:它用来分词(结巴嘛)。
- os:它是 Python 用来和操作系统打交道的库,功能很广,包括但不限于路径(文件目录)操作、进程管理、环境参数等。
- codecs:它负责处理编码相关的问题,比如转换编码、解码等。
- matplotlib:老生常谈了,数据可视化。
- sklearn:这个之前讲过啦,不过提一句 TfidfVectorizer,它是专门用于计算文档中词语的 TF-IDF 值的一个函数,后面会详细讲哒。
'''第一步:导入相关库'''
import re # 正则(字符串匹配)
import jieba # 分词
import os # 文件执行
import codecs # 解码器(转换编码)
from sklearn import naive_bayes # 朴素贝叶斯
from sklearn import svm
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.metrics import roc_curve, recall_score, accuracy_score, roc_auc_score
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
andand,邮件数据这个比较难搞的是我们需要对数据进行一些预处理。毕竟鸢尾花数据集当中特征都给咱弄好了 but 这个没有,而且邮件散落在不同的文件夹。
好 ok 启动。
根据上面说的大思路,我们主要关注邮件中出现的词语,也就是邮件正文部分,所以我们可以大胆一点,把不是中文字符的东西全部去掉。去掉的部分包含邮件头、链接、电话号码这些。
(其实这些东西也能帮助判定是否为垃圾邮件,不过作用比较小,所以忽略也没什么大问题~)
这就需要正则表达式上场了。下面前两行正则表达式,帮我们去掉所有非中文字符,第三行去掉左右两端的空格。
# 去除非中文字符
def clear_email_content(string):string = re.sub(r"[^\u4e00-\u9fff]", "", string)string = re.sub(r"\s{2,}", "", string)return string.strip()
举个例子,我把一封邮件丢进去(这封邮件是 data/000/002),邮件的原文如下图:

然后经过一番洗礼,输出是这样的:

but,我们怎么对每一封邮件都这么操作呢?and 这个操作过后我们下一步干什么?别急,看过来:
first,先不管细节,但是多年的编程经验告诉我们, 我们需要先建立一个存储所有邮件数据的数组。
然后,我们得遍历邮件内容路径(根据上面的目录结构,是 data 文件夹),遍历到每一封邮件之后把它的内容读取出来,进行去非中文处理,保存在临时变量中。
接着我们对临时变量(它保存了处理后的邮件内容)进行分词,得到一个分词列表,但是由于后续计算 tf-idf 等需要,得再把这个列表拼接成字符串,得到一个分词后的字符串(别看挺复杂,实际最终效果就是把原始内容用空格分成了一个个词)。
最后,我们把分词字符串加入到存储所有邮件数据的数组中,这样我们就处理完了一封邮件,可以重复上述流程来处理下一封啦!
先写一下伪代码:
真的这绝对是最好理解的伪代码,,,,几乎没几个代码()
# 伪代码
邮件内容列表 = []
def 读取邮件内容函数(邮件内容路径):for 子路径 in 邮件内容路径:if 还是目录:递归调用 读取邮件内容函数else:记录邮件内容的变量 = ''邮件内容 = 打开文件()for 每一行 in 邮件内容:行 = 去除非中文字符函数()变量 += 行关闭文件()分词列表 = 分词(变量)邮件字符串 = 将分词列表拼接为字符串(分词列表)将 邮件字符串 添加到 邮件内容列表
现在是不是感觉代码呼之欲出了((来来来:
真的我保证你一定会了,注释超详细,实在不行就对着上面思路 and 伪代码~
讲两个函数。第一个是 “codecs.open()”。这个函数主要是把邮件编码(或者说读出来的东西的编码)转为 gbk,要不然会乱码,记住一定要写 ignore errors,否则会报错。
第二个是 jieba.cut() 函数,它是 jieba 分词中的精准模式(另外两种分别是全模式和搜索引擎模式),它不会考虑所有可能的分词方式(全模式),而是只给出一种最有可能的分词方式,具有较高的召回率和较低的错误率。
# 正经代码
content_list = [] # 存储所有邮件内容的数组
data_path = "D:\PyProject\\algorithm\classification\\naive bayes\\test\data" # 邮件内容路径# 获取邮件正文内容,分词后加入邮件内容列表
def get_email_content(path):# 遍历 data 目录,读取每一封邮件files = os.listdir(path) # 获取该路径下的目录和文件的路径,files 是一个路径列表for file in files:# 是目录就进入目录路径并继续遍历下一层,直到是文件为止if os.path.isdir(path + '/' + file):get_email_content(path + '/' + file)# 是文件就提取文件(邮件)内容else:email = '' # 记录邮件内容f = codecs.open(path + '/' + file, 'r', 'gbk', errors='ignore') # 转换为 gbk 编码# 对邮件数据进行预处理——调用 clear_mail_content() 函数for line in f:line = clear_email_content(line)email += line # 拼接成一个字符串f.close()# 对处理后的内容进行分词(精准模式),去掉长度为 1 的词(字)email = [word for word in jieba.cut(email) if (word.strip != '' and len(word)>1)]# 将列表转化为字符串,词之间用空格分隔email = (' '.join(email))# 将分词后的内容加入邮件内容列表(二维数组,每一个元素都是一封分词后的邮件)content_list.append(email)
get_email_content(data_path)
ok~这样所有邮件数据就读取完了,接下来把所有邮件的标签也这么搞一下,方便后续工作。
还是一样的套路,建一个数组,然后遍历 test/full/index.txt,如果标签是 spam,说明是垃圾邮件,就记录为 1,如果是 ham 就记录为 0.
label_list = [] # 存储所有邮件标签的数组
label_path = "D:\PyProject\\algorithm\classification\\naive bayes\\test\\full\index.txt"# 将邮件标签存入数组中,1 代表垃圾邮件,0 代表正常邮件
def get_email_label(path):f = open(path, 'r')# 将邮件标签转化为 0 和 1,添加到列表中for line in f:# 垃圾邮件 spamif line[0] == 's':label_list.append('1')# 正常邮件 hamelif line[0] == 'h':label_list.append('0')
get_email_label(label_path)
好哒!恭喜我们,已经完成了数据预处理!
接下来…好戏开场!
我们现在已经有了所有邮件分词后的数据,
回到最开始讲的大思路。模型的目标是求出 P ( 词语 ) P(词语) P(词语)、 P ( 词语 ∣ 垃圾邮件 ) P(词语∣垃圾邮件) P(词语∣垃圾邮件) 和 P ( 垃圾邮件 ) P(垃圾邮件) P(垃圾邮件)。 P ( 垃圾邮件 ) P(垃圾邮件) P(垃圾邮件) 还算好求,用垃圾邮件数量除以正常邮件数量就 ok 了,重点在词语上——我们怎么求出一个词语出现的概率 and 在垃圾邮件中,这个词语出现的概率?
难不成遍历存储所有邮件内容的数组???那这工作量也有点太大了。而且现在的所有数据都还是文字形式,是没法直接拿去训练的,我们必须得想办法把它们转化为**实数(矩阵)**的形式。
别担心,TF-IDF 来帮我们啦!
TF-IDF,中文名 “词频-逆文件概率”,英文全称 term frequency–inverse document frequency,常用于自然语言处理(NLP)。
它的主要思想是:如果一个词在该文档中出现的概率高,而在其它文档中出现的概率低,那么这个词(对于这个文件)有较好的代表性。
用到我们的任务当中,如果一些词在垃圾邮件中出现的概率高,而在正常邮件中出现的概率低,那么这些词可以较好地代表垃圾邮件。再通俗一点就是,有这些词的邮件很有可能是垃圾邮件。
ok,知道了我们用它干什么,再来看看它是怎么计算的。
先来看 TF,TF 的意思是词频,也就是一个词在文档中出现的次数。但是为了避免这个次数在长文件中比在短文件中多而影响判断,我们还需要对词频做归一化处理,通常是用词频除以文档总词数,得到 TF 值。
公式如下,其中 T F i , j TF_{i, j} TFi,j 表示该词条在该文档中的 TF 值,分子 n i , j n_{i,j} ni,j 表示词条 t i t_i ti 在文档 d j d_j dj 中出现的次数,分母表示文档的总词数。
T F i , j = n i , j ∑ k k i , j TF_{i, j} = \frac {n_{i,j}}{\sum_{k} k_{i,j}} TFi,j=∑kki,jni,j
emmm 但是,光有 TF 是不够的,因为有些词比如 “我们”、“他们” 可能在很多文件中的 TF 值都很高(即都出现了很多次),那这些词就不具有代表性了。为此,我们找来了 IDF。
牢记,TF-IDF 是为了衡量一个词对某个文档而言是否足够有代表性。
IDF 和词条在所有文档中的出现频率是反过来的。也就是说,如果一个词在很多文档中都出现了,那么它的 IDF 会较低,而如果它只在很少的文档中出现,那么它的 IDF 会很高。
公式如下,其中 N 为文档总数,j 是包含词条 t i t_i ti 的文档数,加 1 是为了防止出现分母为 0 的情况(类似拉普拉斯平滑)。
I D F = l g N 1 + ∣ j : t i ∈ d j ∣ IDF = lg\frac{N}{1+|j:t_i ∈d_j|} IDF=lg1+∣j:ti∈dj∣N
综上,如果某词条在某文档中出现的次数多,而在其它文档中出现的次数少,那么它会同时拥有较高的 TF 值和 IDF 值,它的 TF-IDF 值就等于 TF 值和 IDF 值的乘积,即:
T F − I D F = T F × I D F = n i , j ∑ k k i , j × l g N 1 + ∣ j : t i ∈ d j ∣ TF-IDF = TF × IDF = \frac{n_{i,j}}{\sum_{k} k_{i,j}} ×lg\frac{N}{1+|j:t_i ∈d_j|} TF−IDF=TF×IDF=∑kki,jni,j×lg1+∣j:ti∈dj∣N
最后放一张超好看的图来总结:

okkkk,用 TF-IDF,我们就可以用之前已经统计好的(分好词的邮件)计算每个词的 TF-IDF 值了~ Python 提供了相关的方法——sklearn 库中的 TfidfVectorizer。
先把代码放在这,然后再来讲。
# 将每一封邮件转化为词频矩阵(稀疏矩阵)
# TF-IDF,词频-逆文件频率,自然语言处理中常用的方法(加权技术)
# TF-IDF 用以评估一字词对于一个文件的重要程度。
# 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库(其他文章)中出现的频率成反比下降。
# 即,一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。
def tfidf(list):tf = TfidfVectorizer() # 实例化data = tf.fit_transform(list) # 训练,获得每一个词的 tf-idfglobal XX = data.toarray() # 二维数组,每一个元素都是一个邮件的词频矩阵
tfidf(content_list)
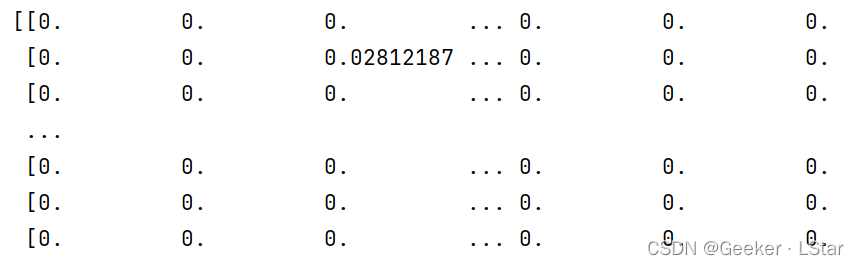
看函数体中的第二行,data 变量中保存了每一封邮件中的每一个词的 TF-IDF 值,从第一封邮件到第三千封邮件。不过不是数组的形式,输出以后会是这样的:
“0” 代表第一封邮件,“0” 后面的整数是这个词语在所有词语构成的词语表中的编码(索引),最后那个小数才是这个词的 TF-IDF 值。

再看第四行,“X” 是我们把原始数据转化为可用于训练的数据的结果(和 SVM 实例里面的鸢尾花数据集很像),X 是一个二维数组,数组中的每个元素(第一层)都代表一封邮件,“邮件” 里面(第二层)存储着词语的信息,和之前不同的是词语已经被转化成了一个个 TF-IDF 值,也就是词频矩阵。
其实就相当于把 data 转成数组,同一封邮件的词的 TF-IDF 构成一个元素,所有的元素(邮件)构成 X。
类似下面这样,嗷不要奇怪为什么一堆是 0,因为词语太多了,而一封邮件肯定不会包含所有的词,那些不被这封邮件包含的词在这封邮件中的 TF-IDF 值就是 0。呃有点绕但是其实还蛮好理解的啦~
ok!恭喜我们!好戏部分已经搞定啦~~接下来就是常规训练 & 测试环节咯。
这段就直接放在这了()实在没什么可讲的了,之前 SVM 和 KNN 的实例已经讲过 N 遍了。
'''第三步:训练 and 测试'''
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, label_list, test_size=0.3, random_state=218)
# 用三种模型进行训练,比较它们的结果
# 多项式贝叶斯
mul_bayes = naive_bayes.MultinomialNB() # 实例化
mul_bayes.fit(X_train, y_train) # 训练
y1_predict = mul_bayes.predict(X_test) # 预测(测试)
y1_proba = mul_bayes.predict_proba(X_test) # 预测属于两个类别(正常/垃圾)的概率
# 伯努利贝叶斯
bernoulli_bayes = naive_bayes.BernoulliNB()
bernoulli_bayes.fit(X_train, y_train)
y2_predict = bernoulli_bayes.predict(X_test) # 预测(测试)
y2_proba = bernoulli_bayes.predict_proba(X_test)
# 支持向量机
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train)
y3_predict = svm.predict(X_test) # 预测(测试)
y3_proba = svm.predict_proba(X_test)# 输出测试结果
# pos_label:正样本标签(本例中正样本为垃圾邮件)
print("多项式朴素贝叶斯准确率:", accuracy_score(y_test, y1_predict))
print("多项式朴素贝叶斯召回率:", recall_score(y_test, y1_predict, pos_label="1"))
print("多项式朴素贝叶斯 AUC 值:", roc_auc_score(y_test, y1_proba[:, 1]))
print("伯努利朴素贝叶斯准确率:", accuracy_score(y_test, y2_predict))
print("伯努利朴素贝叶斯召回率:", recall_score(y_test, y2_predict, pos_label="1"))
print("伯努利朴素贝叶斯 AUC 值:", roc_auc_score(y_test, y2_proba[:, 1]))
print("支持向量机准确率:", accuracy_score(y_test, y3_predict))
print("支持向量机召回率:", recall_score(y_test, y3_predict, pos_label="1"))
print("支持向量机 AUC 值:", roc_auc_score(y_test, y3_proba[:, 1]))
嗯!然后我们来画一个 ROC 曲线嘿嘿,之前在这篇【初中生讲机器学习】6. 分类算法中常用的模型评价指标有哪些?here! 里面我讲过 ROC。
注释里写了,画 ROC 需要知道模型预测数据为正样本的概率,然后再用 roc_curve() 得到真正率 TPR,假正率 FPR。如果不知道是怎么得到的,可以参考上面放的那篇文章~
# 绘制 ROC 曲线图
# 获取模型对测试集数据的预测情况(属于两个类别的概率)
# ROC 曲线需要获取模型预测数据为正样本的概率,即 [:, 1]
score_m = mul_bayes.predict_proba(X_test)[:, 1]
score_b = bernoulli_bayes.predict_proba(X_test)[:, 1]
score_s = svm.predict_proba(X_test)[:, 1]
#使用 roc_curve 方法得到三个模型的真正率 TP,假正率 FP和阈值 threshold
fpr_m, tpr_m, thres_m = roc_curve(y_test, score_m, pos_label="1")
fpr_b, tpr_b, thres_b = roc_curve(y_test, score_b, pos_label="1")
fpr_s, tpr_s, thres_s = roc_curve(y_test, score_s, pos_label="1")
最后就是画图环节啦~代码直接放在这了,有注释。
# 创建画布
fig, ax = plt.subplots(figsize=(10,8))
# 自定义标签名称(使用 AUC 值)
ax.plot(fpr_m,tpr_m,linewidth=2,label='MultinomialNB (AUC={})'.format(str(round(roc_auc_score(y_test, y1_proba[:, 1]), 3))))
ax.plot(fpr_b,tpr_b,linewidth=2,label='BernoulliNB (AUC={})'.format(str(round(roc_auc_score(y_test, y2_proba[:, 1]), 3))))
ax.plot(fpr_s,tpr_s,linewidth=2,label='SVM (AUC={})'.format(str(round(roc_auc_score(y_test, y3_proba[:, 1]), 3))))
# 绘制对角线
ax.plot([0,1],[0,1],linestyle='--',color='grey')
# 调整字体大小
plt.legend(fontsize=12)
# 展现画布
plt.show()
ok 啊!大功告成!!来看看投喂三千组数据是什么结果!~
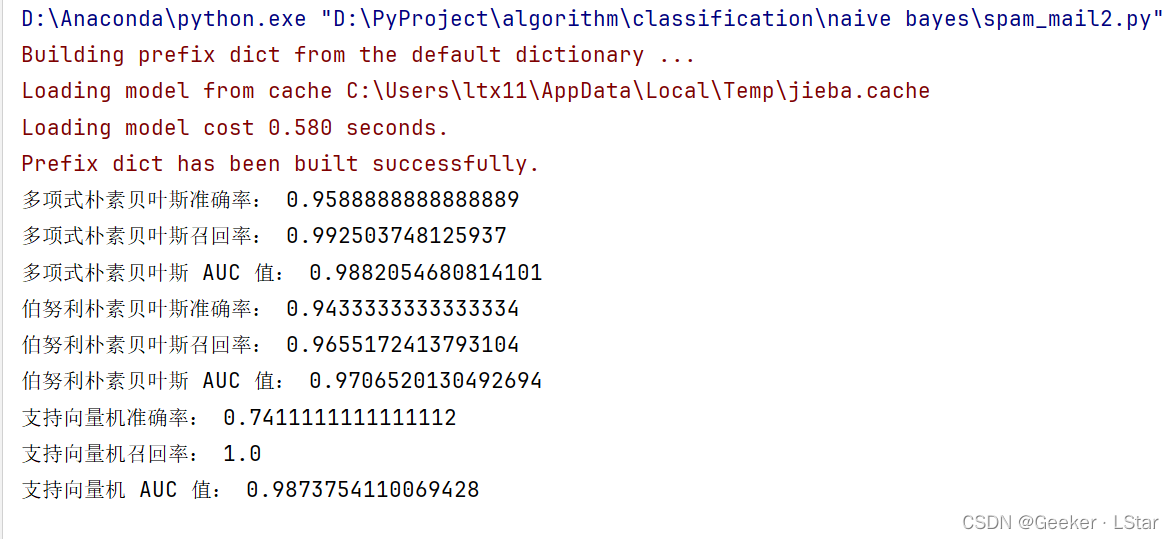
由此看来,两个贝叶斯模型表现的还是不错的!SVM 的准确率有点低了emm,可能是因为它有较高的召回率(查全率),导致部分非垃圾邮件也被分到了垃圾邮件,准确率就变低了。
来看看 ROC,它们仨都很好呢!
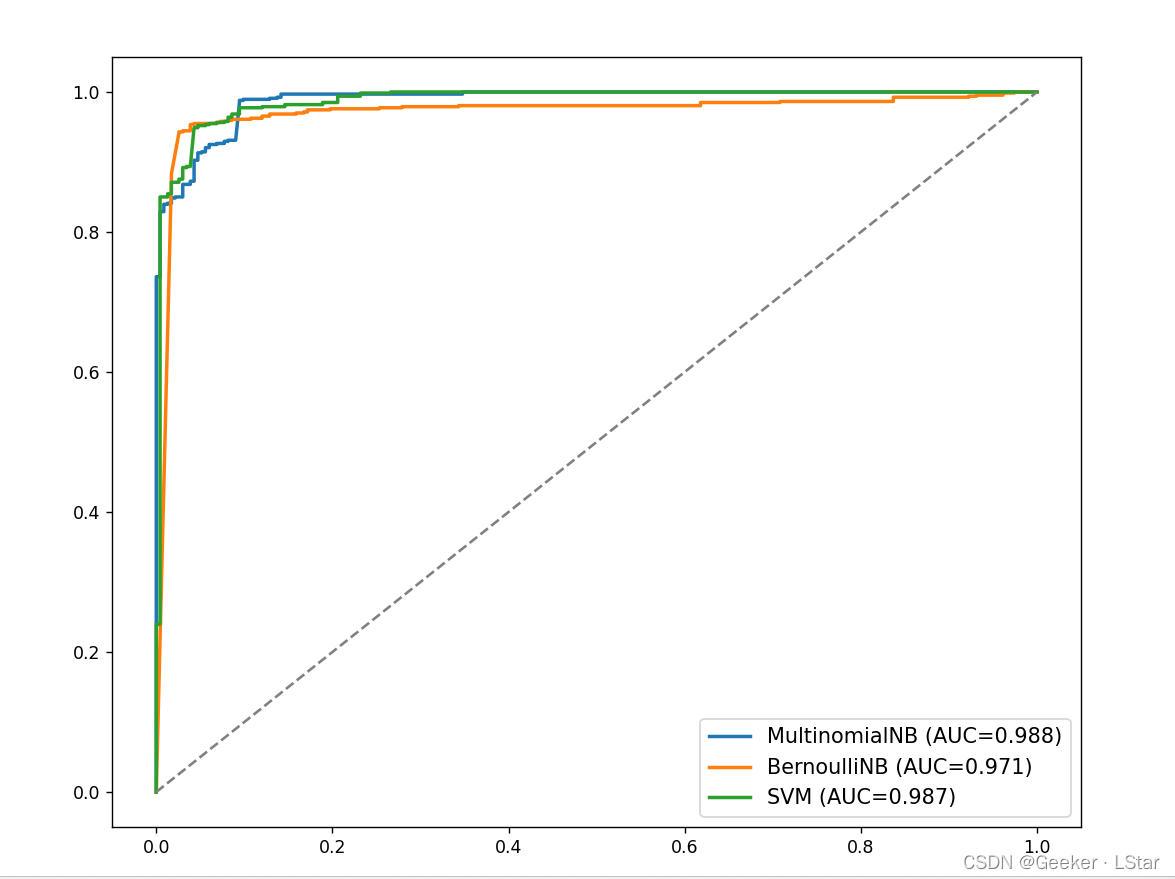
综合来看,指标最好的是多项式朴素贝叶斯。
完整代码:
# 垃圾邮件检索
# 朴素贝叶斯
# TF-IDF 技术
# 首先对数据进行预处理,然后利用 tf-idf 将每封邮件转化为词频矩阵,最后训练模型
# 数据集下载:https://plg.uwaterloo.ca/~gvcormac/treccorpus06/'''第一步:导入相关库'''
import re # 正则(字符串匹配)
import jieba # 分词
import os # 文件执行
import codecs # 解码器
from sklearn import naive_bayes # 朴素贝叶斯
from sklearn import svm
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.metrics import roc_curve, recall_score, accuracy_score, roc_auc_score
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt'''第二步:数据预处理'''
content_list = []
label_list = []
# data_path = "D:\PyProject\\algorithm\classification\\naive bayes\\trec06c\data"
# label_path = "D:\PyProject\\algorithm\classification\\naive bayes\\trec06c\\full\index"
# 原始数据集过大,此处选择 3000 组数据,900 组作为测试集
data_path = "D:\PyProject\\algorithm\classification\\naive bayes\\test\data"
label_path = "D:\PyProject\\algorithm\classification\\naive bayes\\test\\full\index.txt"# 数据预处理
# 去除非中文字符
def clear_email_content(string):string = re.sub(r"[^\u4e00-\u9fff]", "", string)string = re.sub(r"\s{2,}", "", string)return string.strip()# 获取邮件正文内容,分词后加入邮件内容列表
def get_email_content(path):# 遍历 data 目录,读取每一封邮件files = os.listdir(path) # 获取该路径下的目录和文件的路径,files 是一个路径列表for file in files:# 是目录就进入目录路径并继续遍历下一层,直到是文件为止if os.path.isdir(path + '/' + file):get_email_content(path + '/' + file)# 是文件就提取文件(邮件)内容else:email = '' # 记录邮件内容f = codecs.open(path + '/' + file, 'r', 'gbk', errors='ignore') # 转换为 gbk 编码# 对邮件数据进行预处理——调用 clear_mail_content() 函数for line in f:line = clear_email_content(line)email += line # 拼接成一个字符串f.close()# 对处理后的内容进行分词(精准模式),去掉长度为 1 的词(字)email = [word for word in jieba.cut(email) if (word.strip != '' and len(word)>1)]# 将列表转化为字符串,词之间用空格分隔email = (' '.join(email))# 将分词后的内容加入邮件内容列表(二维数组,每一个元素都是一封分词后的邮件)content_list.append(email)
get_email_content(data_path)# 将邮件标签存入数组中,1 代表垃圾邮件,0 代表正常邮件
def get_email_label(path):f = open(path, 'r')# 将邮件标签转化为 0 和 1,添加到列表中for line in f:# 垃圾邮件 spamif line[0] == 's':label_list.append('1')# 正常邮件 hamelif line[0] == 'h':label_list.append('0')
get_email_label(label_path)# 将每一封邮件转化为词频矩阵(稀疏矩阵)
# TF-IDF,词频-逆文件频率,自然语言处理中常用的方法(加权技术)
# TF-IDF 用以评估一字词对于一个文件的重要程度。
# 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库(其他文章)中出现的频率成反比下降。
# 即,一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。
def tfidf(list):tf = TfidfVectorizer() # 实例化data = tf.fit_transform(list) # 训练,获得每一个词的 tf-idfglobal XX = data.toarray() # 二维数组,每一个元素都是一个邮件的词频矩阵
tfidf(content_list)'''第三步:训练 and 测试'''
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, label_list, test_size=0.3, random_state=218)
# 用三种模型进行训练,比较它们的结果
# 多项式贝叶斯
mul_bayes = naive_bayes.MultinomialNB() # 实例化
mul_bayes.fit(X_train, y_train) # 训练
y1_predict = mul_bayes.predict(X_test) # 预测(测试)
y1_proba = mul_bayes.predict_proba(X_test) # 预测属于两个类别(正常/垃圾)的概率
# 伯努利贝叶斯
bernoulli_bayes = naive_bayes.BernoulliNB()
bernoulli_bayes.fit(X_train, y_train)
y2_predict = bernoulli_bayes.predict(X_test) # 预测(测试)
y2_proba = bernoulli_bayes.predict_proba(X_test)
# 支持向量机
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train)
y3_predict = svm.predict(X_test) # 预测(测试)
y3_proba = svm.predict_proba(X_test)# 输出测试结果
# pos_label:正样本标签(本例中正样本为垃圾邮件)
print("多项式朴素贝叶斯准确率:", accuracy_score(y_test, y1_predict))
print("多项式朴素贝叶斯召回率:", recall_score(y_test, y1_predict, pos_label="1"))
print("多项式朴素贝叶斯 AUC 值:", roc_auc_score(y_test, y1_proba[:, 1]))
print("伯努利朴素贝叶斯准确率:", accuracy_score(y_test, y2_predict))
print("伯努利朴素贝叶斯召回率:", recall_score(y_test, y2_predict, pos_label="1"))
print("伯努利朴素贝叶斯 AUC 值:", roc_auc_score(y_test, y2_proba[:, 1]))
print("支持向量机准确率:", accuracy_score(y_test, y3_predict))
print("支持向量机召回率:", recall_score(y_test, y3_predict, pos_label="1"))
print("支持向量机 AUC 值:", roc_auc_score(y_test, y3_proba[:, 1]))# 绘制 ROC 曲线图
# 获取模型对测试集数据的预测情况(属于两个类别的概率)
# ROC 曲线需要获取模型预测数据为正样本的概率,即 [:, 1]
score_m = mul_bayes.predict_proba(X_test)[:, 1]
score_b = bernoulli_bayes.predict_proba(X_test)[:, 1]
score_s = svm.predict_proba(X_test)[:, 1]
#使用 roc_curve 方法得到三个模型的真正率 TP,假正率 FP和阈值 threshold
fpr_m, tpr_m, thres_m = roc_curve(y_test, score_m, pos_label="1")
fpr_b, tpr_b, thres_b = roc_curve(y_test, score_b, pos_label="1")
fpr_s, tpr_s, thres_s = roc_curve(y_test, score_s, pos_label="1")
# 创建画布
fig, ax = plt.subplots(figsize=(10,8))
# 自定义标签名称(使用 AUC 值)
ax.plot(fpr_m,tpr_m,linewidth=2,label='MultinomialNB (AUC={})'.format(str(round(roc_auc_score(y_test, y1_proba[:, 1]), 3))))
ax.plot(fpr_b,tpr_b,linewidth=2,label='BernoulliNB (AUC={})'.format(str(round(roc_auc_score(y_test, y2_proba[:, 1]), 3))))
ax.plot(fpr_s,tpr_s,linewidth=2,label='SVM (AUC={})'.format(str(round(roc_auc_score(y_test, y3_proba[:, 1]), 3))))
# 绘制对角线
ax.plot([0,1],[0,1],linestyle='--',color='grey')
# 调整字体大小
plt.legend(fontsize=12)
# 展现画布
plt.show()OK!!!以上就是垃圾邮件分类器的完整实现啦!!快去试试吧~~
这篇文章用朴素贝叶斯算法实现了垃圾邮件分类,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar
这篇关于【初中生讲机器学习】9. 我是怎么用朴素贝叶斯实现垃圾邮件分类的?真的超全!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







