本文主要是介绍ABAP COLLECT 语法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们都知道collect语句,主要用于报表数据的合并计算的,简单理解是:如果非数据字段值相等,那么数值字段值相加,其实这种描述不准确。
COLLECT 简单的用法:
- LOOP AT t_data.
- COLLECT t_data INTO t_test.
- ENDLOOP .
复制代码
其中 t_data和t_test结构相同,那么有以下疑问:
- COLLECT实际运用中loop的内表(t_data)需要排序么?
- loop语句中能不能用if或者delete语句,筛选部分数据,然后collect计算呢
1、问题一:
- *----------------------------------------------------------------------*
- * define internal tables or workarea
- * 定义内表或者工作区
- *----------------------------------------------------------------------*
- DATA : BEGIN OF w_test,
- key TYPE string, "这是关键字段,用于根据这列来统计的V1、V2的值(这个关键字段可以是多个)
- v1 TYPE i ,
- v2 TYPE i ,
- END OF w_test.
- DATA : t_data LIKE w_test OCCURS 0 WITH HEADER LINE . "定义数据内表
- DATA : t_data_1 LIKE w_test OCCURS 0 WITH HEADER LINE .
- DATA : t_test LIKE w_test OCCURS 0 WITH HEADER LINE .
- *----------------------------------------------------------------------*
- * assign value to internal tables
- * 给内表赋值用于测试
- *----------------------------------------------------------------------*
- DO 8 TIMES .
- IF sy-index < 3 .
- t_data-key = 'A' .
- t_data-v1 = sy-index .
- t_data-v2 = sy-index + 1 .
- ELSEIF sy-index < 6 .
- t_data-key = 'B' .
- t_data-v1 = sy-index .
- t_data-v2 = sy-index - 1 .
- ELSE .
- t_data-key = 'C' .
- t_data-v1 = sy-index - 1 .
- t_data-v2 = sy-index - 2 .
- ENDIF .
- APPEND t_data.
- ENDDO .
- t_data_1[] = t_data[].
- DO 2 TIMES .
- APPEND LINES OF t_data_1 TO t_data.
- ENDDO .
- *----------------------------------------------------------------------*
- * process interal table
- * 处理内表(统计)
- *----------------------------------------------------------------------*
- LOOP AT t_data.
- COLLECT t_data INTO t_test. "按关键列统计值
- ENDLOOP .
- *----------------------------------------------------------------------*
- * output internal tables
- * 打印输出内表
- *----------------------------------------------------------------------*
- WRITE : sy-uline .
- WRITE : '内表数据:' .
- LOOP AT t_data.
- WRITE : / ' ' ,t_data-key ,t_data-v1, t_data-v2.
- ENDLOOP .
- WRITE : sy-uline .
- WRITE : sy-uline .
- WRITE : 'collect后的数据:' .
- LOOP AT t_test.
- WRITE : / ' ' ,t_test-key , t_test-v1, t_test-v2.
- ENDLOOP .
- WRITE : sy-uline .
复制代码
测试结果:
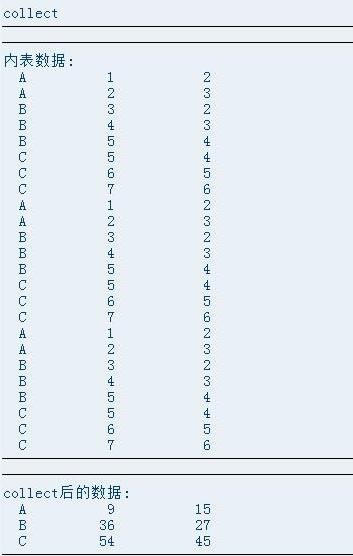
结论:COLLECT实际运用中loop的内表不需要排序,直接loop累加计算。
2、问题二:
以collect代码稍加改变:
- LOOP AT t_data.
- IF t_data-v1 = 2 OR t_data-v1 = 4 OR t_data-v1 = 5.
- COLLECT t_data INTO t_test. "按关键列统计值
- ELSE.
- DELETE t_data.
- ENDIF.
- ENDLOOP .
复制代码
测试结果: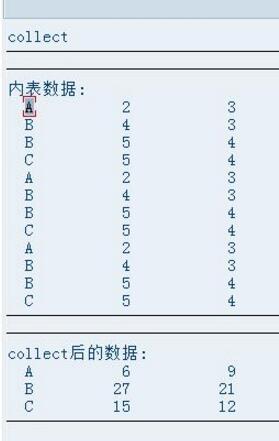
结论:COllECT语句支持这种在loop语句中筛选数据再计算。
由此可见,COLLECT语句还是很强大的,项目中经常会有这种筛选数据在计算,不需要再额外复制内表计算了
你在实际项目中可能使用collect是遇到下面问题:
- 'You can only use the collect command in a table if all of its non-keyfields are numeric(type I,P or F)
复制代码
只有在 COLLECT 命令的所有非关键字段均为数字(类型 I、P 或F)时才可在表中使用该命令。numeric (type I, P, or F)
使用collect就要求所有的非key fields均是I,P或者F数据类型,另外要注意的是对于standard table 而言,如果不指定key fields那么它的key fields就那些非I, P,F数据类型的fields,sorted table 和 hash table均必须指定key fields。
注意:货币类型CURR实际类型是P,所以也可以使用collect累加
这篇关于ABAP COLLECT 语法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





