本文主要是介绍Catboost学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
梯度提升概述
要理解 boosting,我们首先理解集成学习,为了获得更好的预测性能,集成学习结合多个模型(弱学习器)的预测结果。它的策略就是大力出奇迹,因为弱学习器的有效组合可以生成更准确和更鲁棒的模型。集成学习方法分为三大类:
- Bagging:该技术使用随机数据子集并行构建不同的模型,并聚合所有预测变量的预测结果。
- Boosting:这种技术是可迭代的、顺序进行的和自适应的,因为每个预测器都是针对上一个模型的错误进行修正。
- Stacking:这是一种元学习技术,涉及结合来自多种机器学习算法的预测,例如 bagging 和 boosting。
提升方法(Boosting):主要思想为,把多个高偏差的弱学习器组合利用起来,降低整体偏差,形成一个强学习器
梯度提升机(Gradient Boosting Machine,GBM)是 Boosting 的一种实现方式,让新的分类器拟合负梯度来降低偏差
系统梳理GBM相关
GBDT
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是 GBM + CART。CART 作为 GBM 的基模型,GBM 做为 CART 的集成方法。
CART决策树
决策树原理
采用基尼系数来进行定义一个系统中的失序现象,即系统的混乱程度(纯度)。基尼系数越高,系统越混乱(不纯)。建立决策树的目的就是降低系统的混乱程度,降低基尼系数。
基尼系数计算公式如下:
g i n i ( T ) = 1 − ∑ p i 2 gini(T)=1-\sum p_i^2 gini(T)=1−∑pi2
其中pi为类别i在样本T中出现的频率,即类别为i的样本占总样本个数的比率。
在分类问题中,决策树模型会优先选择使得整个系统的基尼系数下降最大的划分方式来进行节点划分。划分后的基尼系数为各部分基尼系数的样本数量加权平均值。
在回归问题中,决策树一般使用均方误差MSE作为其划分标准
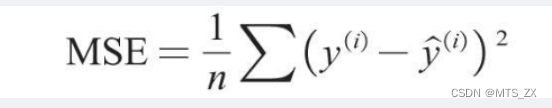

catboost算法
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
它自动采用特殊的方式处理类别型特征(categorical features)。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。这也是这个算法最大的motivtion,有了catboost,再也不用手动处理类别型特征了。
catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
采用ordered boost的方法避免梯度估计的偏差,进而解决预测偏移的问题。
catboost的基模型采用的是对称树,同时计算leaf-value方式和传统的boosting算法也不一样,传统的boosting算法计算的是平均数,而catboost在这方面做了优化采用了其他的算法,这些改进都能防止模型过拟合。
主要特点
对称决策树
在每一步中,前一棵树的叶子都使用相同的条件进行拆分。选择损失最低的特征分割对并将其用于所有级别的节点。这种平衡的树结构有助于高效的 CPU 实现,减少预测时间,模型结构可作为正则化以防止过度拟合。
在对称决策树中,只使用一个特性来构建每个树级别上的所有分支。共有三种类型的拆分:“FloatFeature”、“OneHotFeature” 和 “OnlineCtr”
分类特征的处理
catboost算法解读
空值处理
在CatBoost包的说明文档中,类别型特征的空值处理做了这样的说明:CatBoost does not process categorical features in any specific way,意思就是不做特别处理。将空值全部转换为最小值(默认),或者最大值
Greedy TS编码
在决策树中,标签的平均值将作为节点分裂的标准。这种方法称为Greedy Target Statistics
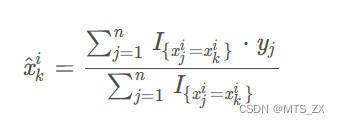
使用 x ^ k i \hat x_k^i x^ki表示第 k k k个训练样本的第 i i i个类别特征。
但使用以上方法,当只有一条记录的时候,该编码值等于该记录的标签值,会造成过拟合,因此一般加上一些先验值p来平滑它:
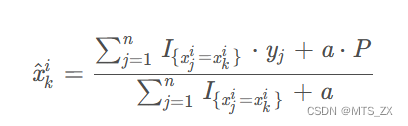
其中 a > 0 a>0 a>0为参数, P P P通常取所有数据中目标变量的平均值
但使用这样的贪婪方法会带来目标泄露的问题,使用了样本 k k k的目标值来计算 x k i x_k^i xki。会造成条件偏移。
ordered TS编码
这是基于TS编码改进的一种编码方式。对于一些类别基数比较小的特征,例如2~3类,可以直接使用one-hot编码,但对于类别基数较大的特征,one-hot编码会产生特征维度问题,这种情况下TS编码会合适一些。
CatBoost算法中采用了ordered TS编码方法来解决Greedy TS编码的目标泄露问题。ordered TS编码是基于排序的,在CatBoost算法中,会对样本进行多次洗牌,每次得到不同排序状态的样本集。为什么要排序?排序的目的产生一种随机性,减少过拟合。每一轮迭代、构建一个树时,都会选择一种排序状态的样本集,这样在不同轮次迭代中,不同排序状态的样本集综合起来,会使模型的方差更小,越不容易过拟合
特征组合
CatBoost以贪婪的方式构造组合。也就是说:对于树的第一次分割,不考虑任何组合,对于树的下一个分割,CatBoost将当前树中用于以前分割的所有分类特性(及其组合)与数据集中的所有分类特性组合在一起。组合被动态转换为TS。
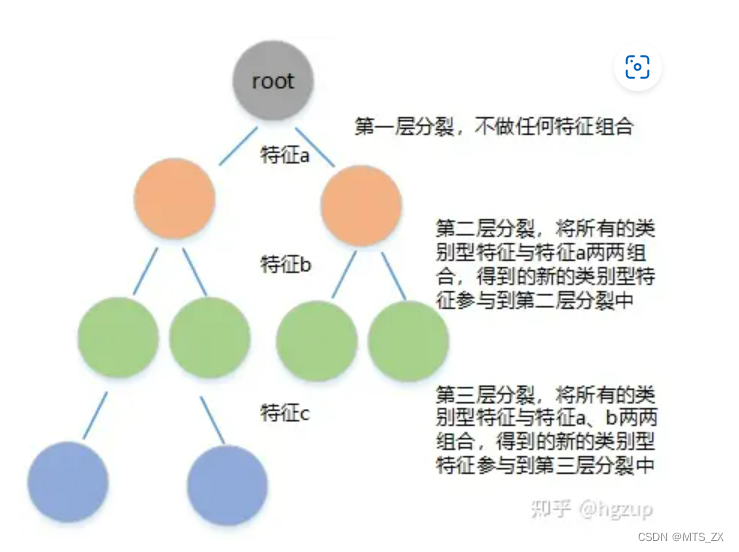
如果在某层中用到了组合特征,那么这个组合特征还可以和其他特征进行组合,参与下次的分裂过程。此外,CatBoost算法还可以将数值特征与类别特征进行组合,具体操作方式是:一句数值型特征分裂阈值,将其处理为两个类别型特征,然后参与特征组合,如某个数值型特征 p p p,分裂阈值为 p > 10 p>10 p>10,那么就可以将特征 p p p处理为 p > 10 , p < = 10 p>10,p<=10 p>10,p<=10两个类别特征
CatBoost处理Categorical features总结
- 首先会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是之后全是这种方式),训练之前需要打乱数据集。
- 第二,使用数据的不同排列。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。
- 第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的特征。当需要组合的categorical features变多时,CatBoost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个特征,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。
- 第四,除非像gender这种维数很小的情况,不建议自己生成One-hot编码向量,最好交给算法来处理。
预测偏移处理
在GBDT算法中,每一棵树都是为了拟合前一棵树上的梯度,构造树时所有的样本都参与了,一个样本参与了建树,然后又用这棵树去估计样本值,这样的估计就不是无偏估计,当测试集和训练集上的样本分布不一致时,模型就会因过拟合而性能不佳,即在测试集上产生了预测偏移。
- 梯度无偏估计
对于样本 x i x_i xi,如果用一个不包含它的模型去估计它的梯度,估计结果可以视为无偏估计。基于这种思路,CatBoost算法中采用了如下策略:在每一轮迭代时,将样本集排序,然后训练 n n n 个模型 M i , i = 1 , 2 , 3 , . . . , n M_i,i=1,2,3,...,n Mi,i=1,2,3,...,n, n n n为样本数量,其中 M i M_i Mi是由前 i i i个样本训练得到(基于本轮样本的排序,包含样本 i i i),然后估计样本 i i i的梯度时,使用模型 M i − 1 M_{i-1} Mi−1来估计,因为该模型是由不包含样本 i i i的样本训练得到,因此该估计结果是无偏估计。
这种方式尽管得到了无偏估计,但是对于排序靠前的样本,它的梯度估计结果可能并不太准确,具有较大的方差,因为估计它的模型是由较少的样本训练的,而且是基于本轮迭代中的样本排序计算的,为了减少预测方差,CatBoost在每轮迭代中都会对样本进行重新排序,然后按照相同的思路估计本轮中样本的梯度,这样多轮迭代的最终结果就可以获取一个较小的方差。 - 同种样本排序状态
在CatBoost算法中,为了保证预测不偏移,在每轮迭代中,计算样本TS值和估计样本梯度用到的是同一种排序状态的样本。 - 共用模型结构
在上文提到过,每一轮迭代都会创建n个模型,也就是创建n棵树,每棵都是预测之前结果和预测值的偏差,但训练树十分耗时,CatBoost算法在这部分进行了调整:<1> 在第一轮迭代中,给定样本排序状态下,分别用前 i i i个样本训练模型,得到n棵树,一个树的训练过程包含两部分:第一步,得到树结构;第二步,计算叶子节点的值。第一步中得到的树结构,也即是每一层选用什么分裂特征,分裂阈值是多少。<2>在得到第一次迭代的n个模型后,CatBoost会使该结构复用到后续所有迭代过程中。即直接使用该结构的划分特征和划分阈值,将样本划分到对应的叶子节点上。
训练过程
一个树的训练包含两部分:得到树结构,计算叶子节点的值
1. 生成树结构
CatBoost沿用了遍历所有候选特征和分裂阈值的节点分裂方式,但增加了分类特征处理和空值处理的策略。
to do
2. 样本叶子节点值计算
to do
CatBoost实践
最详细的Catboost参数详解与实例应用
catboost参数详解
其他参考网址:
30分钟学会CatBoost
one hot 编码
catBoost算法原理
这篇关于Catboost学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









