本文主要是介绍docker 安装hadoop2.8.5和spark2.4.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
win7 + docker+ubuntu+java-1.8+hadoop-2.8.5+spark-2.4.0
win7系统下,docker的安装,本人是利用Docker Toolbox进行安装
参考博客:https://blog.csdn.net/xiangxiezhuren/article/details/79698913
下载地址https://docs.docker.com/toolbox/overview/
安装过程中,需要选择的方框都打勾即可,
安装完成后桌面会有三个快捷方式
1.Docker Quickstart Terminal:docker快速启动终端
2.Kitematic:进行镜像的管理 [其中,LOGIN是注册、登录Docker,需要连接外网进行注册]
进入docker终端,执行docker pull ubuntu,下载ubuntu镜像
docker images
docker ps -a 查看所有镜像
获取所有容器ip地址 docker inspect -f '{{.Name}} - {{.NetworkSettings.IPAddress }}' $(docker ps -aq)
更改tag:docker tag <images id> <images name>:<tag>
e.g. docker tag 569dd6d0e296 ubuntu : 16.02
执行docker run -it ubuntu:16.02后,会生成一个新的容器【注意:每执行一次该命令,就会有新的容器被创建】
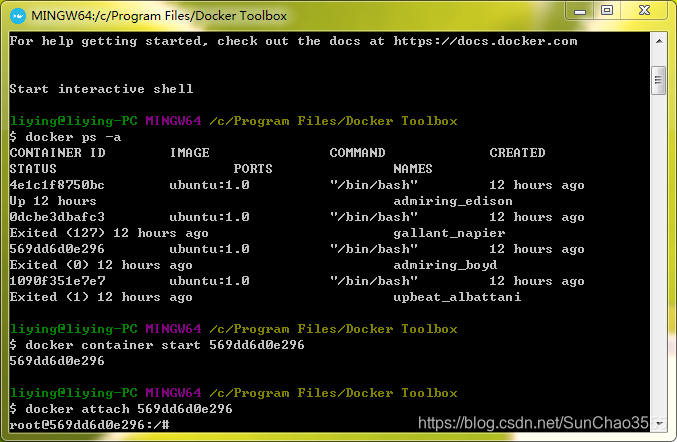
若想执行原来已创建的容器,需要首先执行:docker ps -a 查看容器对应id
然后执行
docker container start 569dd6d0e296
-->docker attach 569dd6d0e296,随后即进入指定版本的ubuntu创建的容器(linux系统中)
如图所示
对于新手会发现,创建的ubuntu无法使用vim编辑器,且执行apt-get install vim会报错
对于docker创建的ubuntu需要先执行 apt-get update【类似于更新系统,获取可下载的package】
然后执行apt-get install vim就可以正常下载了
类似的可以下载nano编辑器
vim常用命令:
o----下一行输入
i-----光标处输入
G---最后一行
上下左右--kjhl
删除x
多行删除
首先在命令模式下,输入“:set nu”显示行号; 2.通过行号确定你要删除的行; 3.命令输入“:32,65d”,回车键,32-65行就被 删除了,
如果无意中删除错了,可以使用‘u’键恢复(命令模式下)
启动第一个容器(ubuntu:1.0),安装java
sudo apt-get install software-properties-common python-software-properties
sudo add-apt-repository ppa:webupd8team/java
sodu apt-get update
apt-get install oracle-java8-installer
java -version这里安装的是java8(JDK1.8.)
将装好的java容器镜像保存为一个副本,可以在此基础上构建其他镜像
root@122a2cecdd14:~# exit
docker commit -m "java install" 122a2cecdd14 ubuntu:javaHadoop安装
启动已安装的java容器镜像
docker run -ti ubuntu:java安装wget
root@8ef06706f88d:cd ~
root@8ef06706f88d:~# mkdir soft
root@8ef06706f88d:~# cd soft/
root@8ef06706f88d:~/soft# mkdir apache
root@8ef06706f88d:~/soft# cd apache/
root@8ef06706f88d:~/soft/apache# mkdir hadoop
root@8ef06706f88d:~/soft/apache# cd hadoop/
root@8ef06706f88d:~/soft/apache/hadoop# wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
root@8ef06706f88d:~/soft/apache/hadoop# tar xvzf hadoop-2.8.5.tar.gz3.配置环境变量
修改~/.bashrc文件。在文件末尾加入下面配置信息:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export HADOOP_HOME=/root/soft/apache/hadoop/hadoop-2.8.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin配置完成后需要执行下面语句,使其立即生效
source ~/.bashrc
注意:我们使用apt-get安装java,不知道java装在什么地方的话可以使用下面的命令查看:
root@8ef06706f88d:~# update-alternatives --config java
There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-7-oracle/jre/bin/java
Nothing to configure.
root@8ef06706f88d:~#4.配置Hadoop
主要配置core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这四个文件
root@8ef06706f88d:~# cd $HADOOP_HOME/
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# mkdir tmp
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# cd tmp/
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/tmp# pwd
/root/soft/apache/hadoop/hadoop-2.8.5/tmp
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/tmp# cd ../
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# mkdir namenode
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# cd namenode/
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/namenode# pwd
/root/soft/apache/hadoop/hadoop-2.8.5/namenode
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/namenode# cd ../
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# mkdir datanode
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5# cd datanode/
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/datanode# pwd
/root/soft/apache/hadoop/hadoop-2.8.5/datanode
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5datanode# cd $HADOOP_CONF_DIR/
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# cp mapred-site.xml.template mapred-site.xml
root@8ef06706f88d:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# nano hdfs-site.xml1)core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/root/soft/apache/hadoop/hadoop-2.8.5/tmp</value><description>A base for other temporary directories.</description></property><property><name>fs.default.name</name><value>hdfs://master:9000</value><final>true</final><description>The name of the default file system. A URI whosescheme and authority determine the FileSystem implementation. Theuri's scheme determines the config property (fs.SCHEME.impl) namingthe FileSystem implementation class. The uri's authority is used todetermine the host, port, etc. for a filesystem.</description></property>
</configuration>注意:
hadoop.tmp.dir配置项值即为此前命令中创建的临时目录路径。fs.default.name配置为hdfs://master:9000,指向的是一个Master节点的主机(后续我们做集群配置的时候,自然会配置这个节点,先写在这里)
2)hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value><final>true</final><description>Default block replication.The actual number of replications can be specified when the file is created.The default is used if replication is not specified in create time.</description></property><property><name>dfs.namenode.name.dir</name><value>/root/soft/apache/hadoop/hadoop-2.8.5/namenode</value><final>true</final></property><property><name>dfs.datanode.data.dir</name><value>/root/soft/apache/hadoop/hadoop-2.8.5/datanode</value><final>true</final></property>
</configuration>注意:
- 我们后续搭建集群环境时,将配置一个Master节点和两个Slave节点。所以
dfs.replication配置为2。 dfs.namenode.name.dir和dfs.datanode.data.dir分别配置为之前创建的NameNode和DataNode的目录路径
3)mapred-site.xml
先执行 cp mapred-site.xml.template mapred-site.xml
再进行配置【移除可能老旧版本的配置】
<configuration> <property><name>mapreduce.framework.name</name><value> yarn</value></property>
</configuration>
4)yarn-site.xml
<configuration><!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.hostname</name><value>master</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property></configuration>
5)修改JAVA_HOME环境变量
nano hadoop-env.sh
修改文件中:export JAVA_HOME=/usr/lib/jvm/java-8-oracle
6)格式化 namenode
hdfs/hadoop namenode -format
4.安装SSH
实现无密码登陆
root@8ef06706f88d:~# sudo apt-get install ssh
SSH装好了以后,由于我们是Docker容器中运行,所以SSH服务不会自动启动。需要我们在容器启动以后,手动通过/usr/sbin/sshd 手动打开SSH服务。未免有些麻烦,为了方便,我们把这个命令加入到~/.bashrc文件中。通过nano ~/.bashrc编辑.bashrc文件(nano没有安装的自行安装,也可用vi),在文件后追加下面内容:
#autorun
/usr/sbin/sshd执行source ~/.bashrc
5.生成访问密钥
root@8ef06706f88d:/# cd ~/
root@8ef06706f88d:~# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
root@8ef06706f88d:~# cd .ssh
root@8ef06706f88d:~/.ssh# cat id_rsa.pub >> authorized_keys
root@8ef06706f88d:~/.ssh# chmod 600 authorized_keys
注意: 这里,我的思路是直接将密钥生成后写入镜像,免得在买个容器里面再单独生成一次,还要相互拷贝公钥,比较麻烦。当然这只是学习使用(这样会导致容器密钥就全都一样)
6.配置slaves
在master节点容器中执行如下命令:
root@master:~# cd $HADOOP_CONF_DIR/
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# nano slaves
将如下信息写入该文件末尾:
slave1
slave2
7.保存镜像副本
这里我们将安装好Hadoop的镜像保存为一个副本。
root@8ef06706f88d:~# exit
king@king:~$ docker commit -m "hadoop install" 8ef06706f88d ubuntu:hadoop搭建分布式集群
这里有几个问题:
- Docker容器中的ip地址是启动之后自动分配的,且不能手动更改
- hostname、hosts配置在容器内修改了,只能在本次容器生命周期内有效。如果容器退出了,重新启动,这两个配置将被还原。且这两个配置无法通过
commit命令写入镜像
我们搭建集群环境的时候,需要指定节点的hostname,以及配置hosts。hostname可以使用Docker run命令的h参数直接指定。但hosts解析有点麻烦,虽然可以使用run的--link参数配置hosts解析信息,但我们搭建集群时要求两台机器互相能够ping通,其中一个容器没有启动,那么ip不知道,所以--link参数对于我们的这个场景不实用。要解决这个问题,大概需要专门搭建一个域名解析服务,即使用--dns参数
我们这里只为学习,就不整那么复杂了,就手动修改hosts吧。
启动master容器
docker run -ti -h master ubuntu:hadoop
启动slave1容器
docker run -ti -h slave1 ubuntu:hadoop
启动slave2容器
docker run -ti -h slave2 ubuntu:hadoop执行此步骤后,各hadoop容器配置均相同,只需修改hosts和slaves即可
配置hosts
(ifconfig不能用时,可先执行apt-get install net-tools,然后再执行ifconfig)
- 通过
ifconfig命令分别获取各节点ip。环境不同获取的ip可能不一样,例如我本机获取的ip如下:- master:172.17.0.2
- slave1:172.17.0.3
- slave2:172.17.0.4
-
使用
sudo nano /etc/hosts命令将如下配置写入各节点的hosts文件,注意修改ip地址:172.17.0.2 master 172.17.0.3 slave1 172.17.0.4 slave2
启动Hadoop
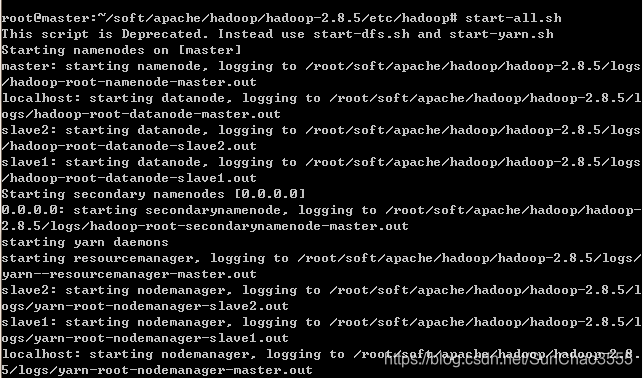
在master节点上执行start-all.sh命令,启动Hadoop。
只不过每次重新启动都得修改各节点/etc/hosts
成功执行如下图所示:
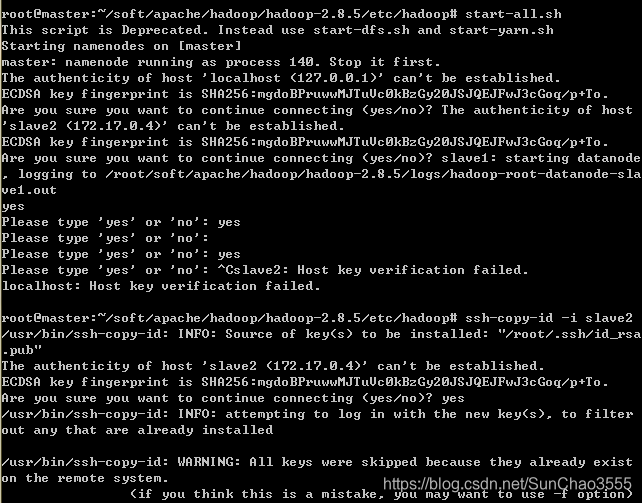
【此处若仍需要输入密码请转至本文末尾,进行另一种ssh免密登录方式】
【此处若出现以下信息,只需依次输入yes ,出现yes输入不能识别情况可按以下所示操作】
jps

可以在其他slave结点输入jps,查看状态
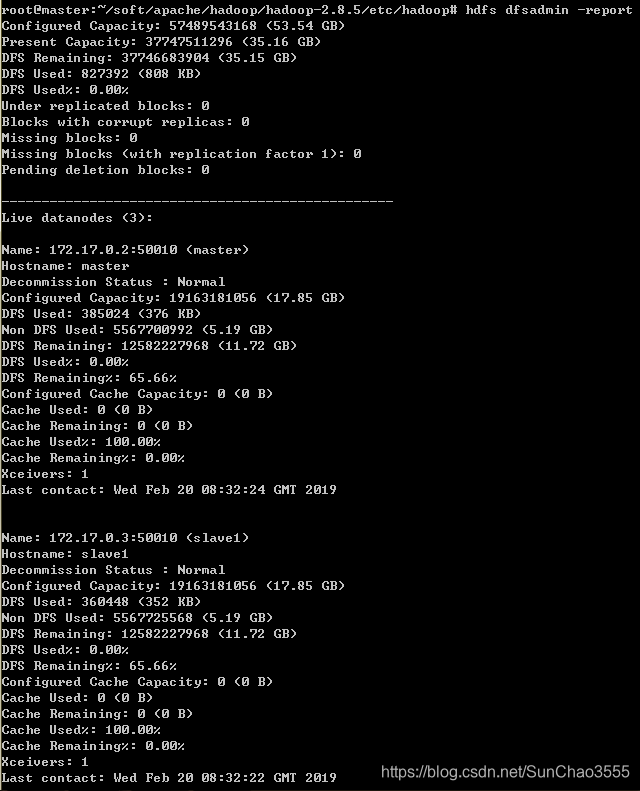
在master节点上通过命令hdfs dfsadmin -report查看DataNode是否正常启动
执行自带wordcount例子
参考博客:https://www.cnblogs.com/xiaomila-study/p/4973662.html
1)
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop fs -mkdir -p /data/wordcount2)
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop fs -mkdir -p /output/3)
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop fs -ls /4)
#其中需要说明的是,作为执行的输入文件可以随意选择,root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop fs -put ~/soft/apache/hadoop/hadoop-2.8.5/LICENSE.txt /data/wordcount/#即我这里直接选择hadoop-2.8.5下的证书文件作为输入【执行put类似于cp命令不会导致原文件变动】5)
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop fs -ls /data/wordcount6)#执行wordcount
root@master:~/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop# hadoop jar ~/soft/apache/hadoop/hadoop-2.8.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /data/wordcount /output/wordcount
7)#查看输出
hadoop fs -text /output/wordcount/part-r-00000 二、在hadoop基础上安装spark
1.scala环境搭建
1)下载scala-2.12.8.tgz,解压到/usr/share目录下
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgztar -zxvf scala-2.12.8.tgzmv scala-2.12.8 /usr/share
2)在~/.bashrc中添加配置:
export SCALA_HOME=/usr/share/scala-2.12.8
export PATH=$SCALA_HOME/bin:$PATH生效 source /.bashrc
2.spark2.4.0环境搭建
1)创建目录并下载解压到指定位置
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgzcd $HADOOP_HOME
cd ..
cd ..
mkdir spark
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
2) 在~/.bashrc中添加配置:
export SPARK_HOME=/root/soft/apache/spark/spark-2.4.0-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin
注意, 因spark sbin目录文件与hadoop sbin有相同,故这里不指定
生效 source /.bashrc
3)修改spark-env.sh
cd $SPARK_HOME/confcp spark-env.sh.template spark-env.shnano spark-env.sh #在末尾添加如下内容:export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SCALA_HOME=/usr/share/scala-2.12.8
export HADOOP_HOME=/root/soft/apache/hadoop/hadoop-2.8.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/root/soft/apache/spark/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g4)修改slaves
cp slaves.template slaves,打开后添加如下内容
slave1
slave2保存镜像副本
docker commit -m "spark install" XXX ubuntu:spark
docker run -it -h master ubuntu:spark
.........重复前面hadoop步骤...........
5)
启动hadoop:start-all.sh
启动spark:
cd $SPARK_HOME/sbin
./start-all.sh
注意:
鉴于之前已启动过hadoop,因此使用docker run -it -h <各节点hostname> ubuntu:spark 会导致 各个slave结点 的 $HADOOP_HOME路径下的tmp临时文件和存放datanode结点数据的文件/datanode/current/数据信息相同
出现Hadoop datanode正常启动,但是Live nodes中却缺少节点的问题且结点时而变化的问题
即 执行 hdfs dfsadmin -report 发现 datanode live 数量小于实际节点数
先停止slave节点服务,将slave节点的tmp和datanode文件下的文件删除,并重新启动 即可解决
参考博客:https://blog.csdn.net/u011462318/article/details/80439160
6)运行wordcount
#重复hadoop运行wordcount步骤 1)到6)
spark-shellscala> sc.textFile("/data/wordcount").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/output/wordcount")#以空格分词
查看输出略
附:
ubuntu可以通过编辑 sources list进行官方源和第三方源的更新【注意备份】
cp /etc/apt/sources.list /etc/apt/sources.list.bak #备份sudo vim /etc/apt/sources.list #修改cp /etc/apt/sources.list /etc/apt/sources.list.qinghua #备份第三方源apt-get update
VMware 虚拟环境ubuntu 安装docker不错的网站:
http://www.runoob.com/docker/ubuntu-docker-install.html
root@master:~# scp /root/soft/apache/hadoop/hadoop-2.8.5/etc/hadoop/yarn-site.xml slave1:/root/soft/apache/hadoop/had
oop-2.8.5/etc/hadoop/ #实现远程文件发送
另一种操作【各节点容器已创建后,实现ssh免密登陆】,
在master节点容器中
ssh-copy-id -i slave1 #登录slave1,将公钥拷贝到hadoop01的authorized_keys中;
ssh-copy-id -i slave2 #登录slave2,将公钥拷贝到hadoop01的authorized_keys中;
。。。注意:执行上述命令会要求输入slave的password 可能需要先在各个slave设置root密码(输入 passwd,按提示操作即可)
然后可能需要修改sshd_config
1.修改root密码:#sudo passwd root2.辑配置文件,允许以 root 用户通过 ssh 登录:sudo vi /etc/ssh/sshd_config找到:PermitRootLogin prohibit-password禁用添加:PermitRootLogin yes3.sudo service ssh restart授权authorized_keys文件,在.ssh目录下输入命令:
chmod 600 authorized_keys将授权文件拷贝到slave1、slave2...,命令如下:
scp /root/.ssh/authorized_keys slave1:/root/.ssh/ #拷贝scp /root/.ssh/authorized_keys slave2:/root/.ssh/ #拷贝
参考博客 https://www.cnblogs.com/ivan0626/p/4144277.html【Docker 安装hadoop 参考博客:https://www.cnblogs.com/onetwo/p/6419925.html该博客安装版本hadoop2.6.X版本与2.8.X有不同之处,不能照搬,请注意比较】
这篇关于docker 安装hadoop2.8.5和spark2.4.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






