本文主要是介绍编译原理:正则表达式/正规式转NFA(原理+完整代码+可视化实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从正则到自动机:正则表达式/正规式转换为NFA
【本文内容摘要】
(1)从中缀表达式转换为后缀表达式
(2)从后缀表达式转换为NFA
(3)打印NFA大致内容
(4)生成dot文件。
(5)完整代码
如果本文对各位看官有用的话,请记得给一个免费的赞哦(收藏也不错)!
文章目录
- 从正则到自动机:正则表达式/正规式转换为NFA
- 一、从中缀表达式转换为后缀表达式
- 二、从后缀表达式转换为NFA
- (A)本文用到的结构体
- (B)一些准备工作(后续需要用到的函数)
- (C)Thompson构造法(一些运算关系)
- (D)将正则表达式转换为NFA
- 三、生成dot文件
- 四、案例测试
- 五、C++代码完整实现
一、从中缀表达式转换为后缀表达式
下面链接详细讲述了如何从中缀表达式转换为后缀表达式,与本文的区别为符号优先关系表中部分元素不同,看完链接中的内容,我想下面的代码也可以理解了~
中缀表达式构建后缀表达式
//类里的各类元素定义
infixToPostfix::infixToPostfix(const string& infix_expression) : infix(infix_expression), postfix("") {isp = { {'+', 3}, {'|', 5}, {'*', 7}, {'(', 1}, {')', 8}, {'#', 0} };icp = { {'+', 2}, {'|', 4}, {'*', 6}, {'(', 8}, {')', 1}, {'#', 0} };
}int infixToPostfix::is_letter(char check) {if (check >= 'a' && check <= 'z' || check >= 'A' && check <= 'Z')return true;return false;
}int infixToPostfix::ispFunc(char c) {int priority = isp.count(c) ? isp[c] : -1;if (priority == -1) {cerr << "error: 出现未知符号!" << endl;exit(1); // 异常退出}return priority;
}int infixToPostfix::icpFunc(char c) {int priority = icp.count(c) ? icp[c] : -1;if (priority == -1) {cerr << "error: 出现未知符号!" << endl;exit(1); // 异常退出}return priority;
}void infixToPostfix::inToPost() {string infixWithHash = infix + "#";stack<char> stack;int loc = 0;while (!stack.empty() || loc < infixWithHash.size()) {if (is_letter(infixWithHash[loc])) {postfix += infixWithHash[loc];loc++;}else {char c1 = (stack.empty()) ? '#' : stack.top();char c2 = infixWithHash[loc];if (ispFunc(c1) < icpFunc(c2)) { // 栈顶操作符优先级低于当前字符,将当前字符入栈stack.push(c2);loc++;}else if (ispFunc(c1) > icpFunc(c2)) { // 栈顶操作符优先级高于当前字符,将栈顶操作符出栈并添加到后缀表达式postfix += c1;stack.pop();}else {if (c1 == '#' && c2 == '#') { // 遇到两个 #,表达式结束break;}stack.pop(); //其中右括号遇到左括号时会抵消,左括号出栈,右括号不入栈loc++;}}}
}string infixToPostfix::getResult() {postfix = ""; // 清空结果inToPost();return postfix;
}
补充:关于在中缀表达式中添加"+"
add_join_symbol函数的作用是在正则表达式中添加连接符号+,以便于后续的中缀转后缀操作。这是因为正则表达式中的连接运算是隐含的,没有明确的符号表示,例如ab表示a和b的连接,但是在中缀转后缀的过程中,需要有一个明确的符号来表示连接运算的优先级,否则会导致歧义或错误。例如,如果没有添加连接符号,那么a|b*的后缀表达式可能是ab*|或者a|b*,前者表示a或者b的闭包,后者表示a或者b的连接,这两者的含义是不同的。因此,为了避免这种情况,需要在正则表达式中添加连接符号+,表示连接运算的优先级高于或运算和闭包运算,举个栗子~,a(a|b)* ,加’+'后的表达式:a+(a|b)*,表示a和(a|b)*是拼接起来的。
//添加连接符号
string add_join_symbol(string add_string)
{int length = add_string.size();int return_string_length = 0;char* return_string = new char[2 * length + 2];//最多是两倍char first, second;for (int i = 0; i < length - 1; i++){first = add_string.at(i);second = add_string.at(i + 1);return_string[return_string_length++] = first;//要加的可能性如ab 、 *b 、 a( 、 )b 等情况//若第二个是字母、第一个不是'('、'|'都要添加if (first != '(' && first != '|' && is_letter(second)){return_string[return_string_length++] = '+';}//若第二个是'(',第一个不是'|'、'(',也要加else if (second == '(' && first != '|' && first != '('){return_string[return_string_length++] = '+';}}//将最后一个字符写入secondreturn_string[return_string_length++] = second;return_string[return_string_length] = '\0';string STRING(return_string);cout << "加'+'后的表达式:" << STRING << endl;return STRING;
}
二、从后缀表达式转换为NFA
(A)本文用到的结构体
-
node:
node表示NFA中的节点,每个节点有一个名称nodeName,用于标识唯一的状态。 -
edge:
edge表示NFA中的边,包括起始节点startName、目标节点endName和转换符号tranSymbol。
startName表示边的起始状态。
endName表示边的目标状态。
tranSymbol表示边上的转换符号,即从起始状态到目标状态的转换条件。 -
elem:
elem表示NFA的组成单元,它是一个大的NFA单元,可以由多个小单元通过规则拼接而成。
edgeCount表示该NFA拥有的边的数量。
edgeSet是一个包含边的数组,最多存储100条边。
startName表示NFA的开始状态。
endName表示NFA的结束状态。
(B)一些准备工作(后续需要用到的函数)
(a)创建新节点函数
//创建新节点
node new_node()
{node newNode;newNode.nodeName = nodeNum + 65;//将名字用大写字母表示nodeNum++;return newNode;
}
这里通过nodeNum + 65的方式为新节点分配一个唯一的名称,其中nodeNum是一个全局变量,表示节点的数量。比如第一个节点(nodeNum = 0时),这里将数字转换为大写字母(ASCII码为0+65 = 65),初始值为 ‘A’。
(b)组成单元拷贝函数 elem_copy
用于将一个 NFA 组成单元(elem 结构体)的内容复制到另一个组成单元中。
//组成单元拷贝函数
void elem_copy(elem& dest, elem source)
{for (int i = 0; i < source.edgeCount; i++) {dest.edgeSet[dest.edgeCount+i] = source.edgeSet[i];}dest.edgeCount += source.edgeCount;
}
(C)Thompson构造法(一些运算关系)
Thompson构造法(from 百度百科)
-
递归终点
对于正则表达式为ε或者只由一个符号构成的情况,则无需继续递归,对应的NFA可以直接由下列规则给出:
空表达式ε直接转化为:
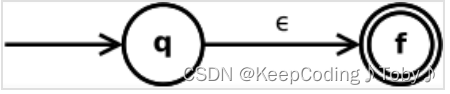
字母表中的单个符号a直接转化为:
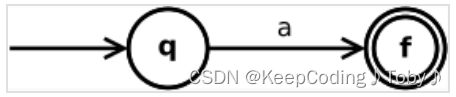
2.子表达式运算的构造规则
-
并运算 (s|t):
- 通过 ε 转移,状态
q可以直接到达N(s)或N(t)的初态。 N(s)或N(t)原来的终态可以通过 ε 转移直接到达整个 NFA 的新终态。
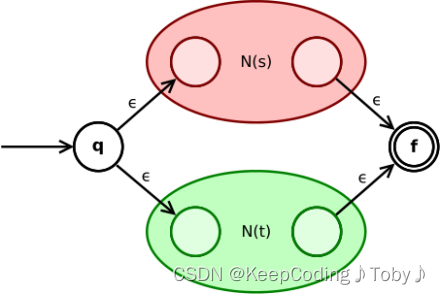
- 通过 ε 转移,状态
-
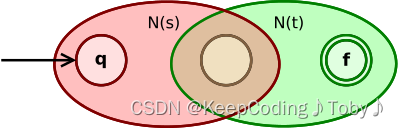
连接运算 (st):
N(s)的初态成为新的 NFA 的初态。- 原来
N(s)的终态成为N(t)的初态。 - 原来
N(t)的终态成为新的 NFA 的终态。
-
Kleene闭包 (s):
- 将新表达式的初态和终态以及夹在中间的子表达式的 NFA
N(s)连接起来的 ε 转移,使得可以选择经过或者不经过子表达式。 - 从
N(s)的终态到初态的 ε 转移,使得s可以重复任意多次。
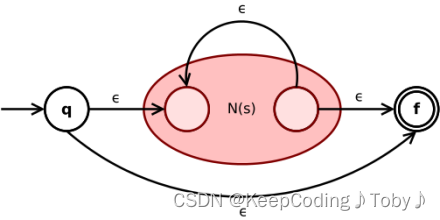
- 将新表达式的初态和终态以及夹在中间的子表达式的 NFA
-
加括号的表达式 (s):
- 直接转化为
N(s)自身即可。
- 直接转化为
下面根据Thompson构造法的规则来实现各种算法:
(a)处理单个字符(规则1)
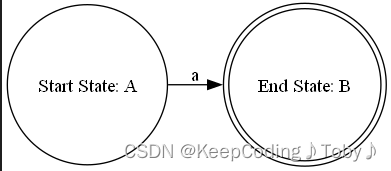
上图为a
//处理 a
elem act_Elem(char c)
{//新节点node startNode = new_node();node endNode = new_node();//新边edge newEdge;newEdge.startName = startNode;newEdge.endName = endNode;newEdge.tranSymbol = c;//新NFA组成元素(小的NFA元素/单元)elem newElem;newElem.edgeCount = 0; //初始状态newElem.edgeSet[newElem.edgeCount++] = newEdge;newElem.startName = newElem.edgeSet[0].startName;newElem.endName = newElem.edgeSet[0].endName;return newElem;
}
(b)处理a|b(规则2.1)
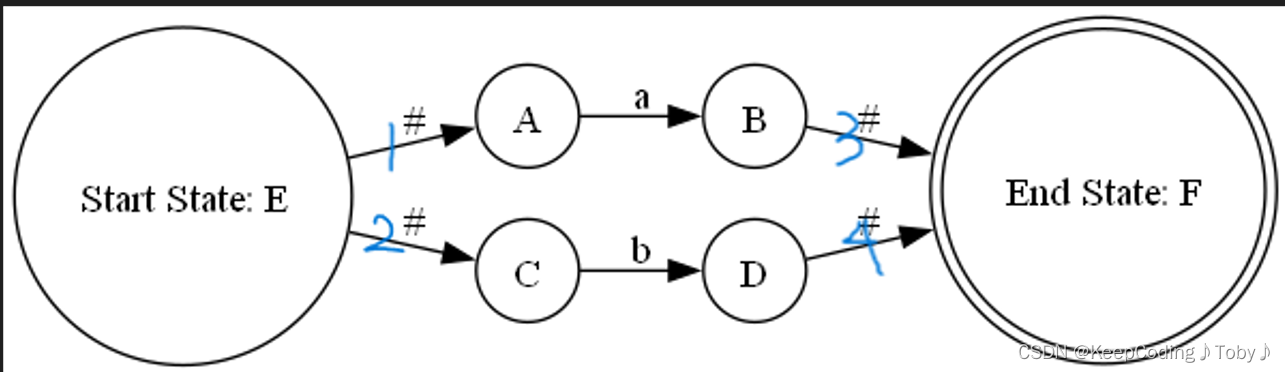
上图为a|b
step1:创建一个新的elem结构体,用于存储或运算的NFA的边集合、边数量、开始节点和结束节点。然后,创建两个新的节点,分别作为开始节点和结束节点,并调用了一个自定义的函数new_node(),它会给每个节点分配一个唯一的名称(用大写字母表示)。
step2:创建了四条空串转换的边,分别连接开始节点和两个子表达式的开始节点,以及两个子表达式的结束节点和结束节点。这样就可以从开始节点通过空串转换选择进入任意一个子表达式,然后从子表达式的结束节点通过空串转换到达结束节点。
step3:将两个子表达式的边集合合并到新的边集合中,并更新边的数量。这样就可以保留两个子表达式的内部转换关系。
//处理a|b
elem act_Unit(elem fir, elem sec)
{elem newElem;newElem.edgeCount = 0;edge edge1, edge2, edge3, edge4;//获得新的状态节点node startNode = new_node();node endNode = new_node();//构建e1(连接起点和AB的起始点A)edge1.startName = startNode;edge1.endName = fir.startName;edge1.tranSymbol = '#';//构建e2(连接起点和CD的起始点C)edge2.startName = startNode;edge2.endName = sec.startName;edge2.tranSymbol = '#';//构建e3(连接AB的终点和终点)edge3.startName = fir.endName;edge3.endName = endNode;edge3.tranSymbol = '#';//构建e4(连接CD的终点和终点)edge4.startName = sec.endName;edge4.endName = endNode;edge4.tranSymbol = '#';//将fir和sec合并elem_copy(newElem, fir);elem_copy(newElem, sec);//新构建的4条边newElem.edgeSet[newElem.edgeCount++] = edge1;newElem.edgeSet[newElem.edgeCount++] = edge2;newElem.edgeSet[newElem.edgeCount++] = edge3;newElem.edgeSet[newElem.edgeCount++] = edge4;newElem.startName = startNode;newElem.endName = endNode;return newElem;
}
(c)处理N(s)N(t)(规则2.2)

上图为N(s)N(t)即(a|b)(c|d)
step1:函数接收两个elem结构体作为参数,分别表示两个子表达式的NFA,我们可以用N(s)和N(t)来表示它们。
step2:函数的目标是将N(s)和N(t)连接起来,形成一个新的NFA,我们可以用N(st)来表示它。N(st)的开始状态就是N(s)的开始状态,N(st)的结束状态就是N(t)的结束状态。
step3:函数的关键步骤是将N(s)的结束状态和N(t)的开始状态合并为一个状态(图中这个合并后的状态就是F),这样就可以从N(s)的结束状态直接转移到N(t)的开始状态,实现连接运算。为了做到这一点,函数遍历了N(t)的所有边,如果边的起始节点或结束节点是N(t)的开始状态,就将它们替换为N(s)的结束状态。
step4:函数将N(t)的边集合复制到N(s)的边集合中,并更新边的数量。这样,就可以保留N(s)和N(t)的内部转换关系,同时添加了N(s)和N(t)之间的转换关系。
step5:函数将N(s)的开始状态和N(t)的结束状态赋值给一个新的elem结构体,并将其返回作为函数的输出。
//处理 N(s)N(t)
elem act_join(elem fir, elem sec)
{//将fir的结束状态和sec的开始状态合并,将sec的边复制给fir,将fir返回//将sec中所有以StartState开头的边全部修改for (int i = 0; i < sec.edgeCount; i++) {if (sec.edgeSet[i].startName.nodeName.compare(sec.startName.nodeName) == 0){sec.edgeSet[i].startName = fir.endName; //该边e1的开始状态就是N(t)的起始状态}else if (sec.edgeSet[i].endName.nodeName.compare(sec.startName.nodeName) == 0) {sec.edgeSet[i].endName = fir.endName; //该边e2的结束状态就是N(t)的起始状态}}sec.startName = fir.endName;elem_copy(fir, sec);//将fir的结束状态更新为sec的结束状态fir.endName = sec.endName;return fir;
}
(d)处理a*(规则2.3)
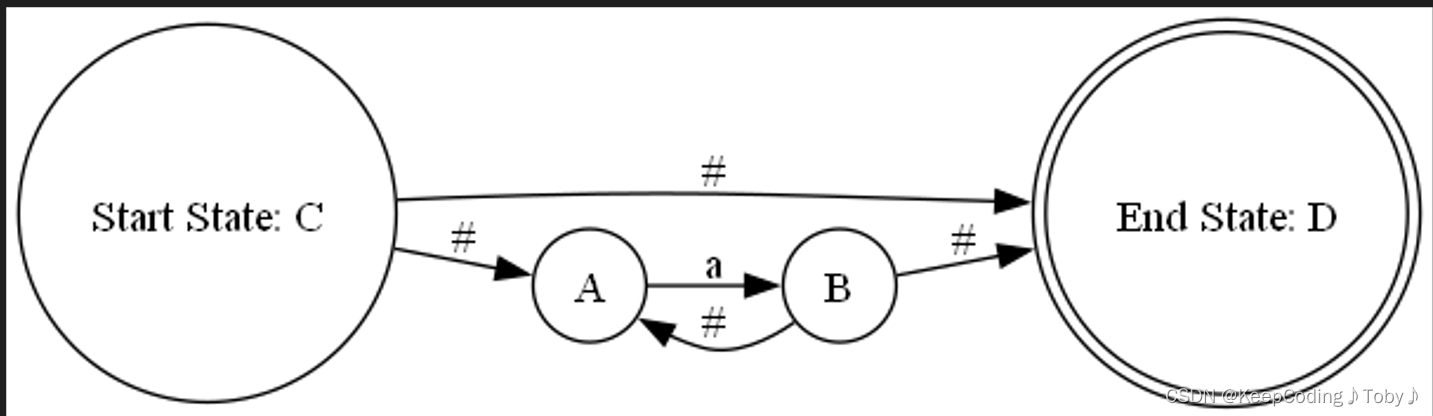
上图为a*
step1:首先,创建一个新的elem结构体,用于存储闭包运算的NFA的边集合、边数量、开始节点和结束节点。
step2:然后,创建两个新的节点,分别作为开始节点和结束节点,并调用了一个自定义的函数new_node(),它会给每个节点分配一个唯一的名称(用大写字母表示)。
step3:接着,创建了四条空串转换的边,分别连接开始节点和结束节点,开始节点和子表达式的开始节点,子表达式的结束节点和子表达式的开始节点,子表达式的结束节点和结束节点。这样就可以从开始节点通过空串转换到结束节点,或者从开始节点通过空串转换到子表达式,然后从子表达式的结束节点通过空串转换回子表达式的开始节点,重复任意次,最后从子表达式的结束节点通过空串转换到结束节点,实现闭包运算。
step4:然后,将子表达式的边集合复制到新的边集合中,并更新边的数量。这样就可以保留子表达式的内部转换关系。
step5:将开始节点和结束节点的名称赋值给新的elem结构体,并将其返回作为函数的输出。
//处理a*
elem act_star(elem Elem)
{elem newElem;newElem.edgeCount = 0;edge edge1, edge2, edge3, edge4;//获得新状态节点node startNode = new_node();node endNode = new_node();//e1edge1.startName = startNode;edge1.endName = endNode;edge1.tranSymbol = '#'; //闭包取空串//e2edge2.startName = Elem.endName;edge2.endName = Elem.startName;edge2.tranSymbol = '#';//e3edge3.startName = startNode;edge3.endName = Elem.startName;edge3.tranSymbol = '#';//e4edge4.startName = Elem.endName;edge4.endName = endNode;edge4.tranSymbol = '#';//构建单元elem_copy(newElem, Elem);//将新构建的四条边加入EdgeSetnewElem.edgeSet[newElem.edgeCount++] = edge1;newElem.edgeSet[newElem.edgeCount++] = edge2;newElem.edgeSet[newElem.edgeCount++] = edge3;newElem.edgeSet[newElem.edgeCount++] = edge4;//构建NewElem的启示状态和结束状态newElem.startName = startNode;newElem.endName = endNode;return newElem;
}
(e)规则2.4:N(s)转换为自身即可
(D)将正则表达式转换为NFA
这里解释代码即可:
/**表达式转NFA处理函数,返回最终的NFA集合
*/
elem express_to_NFA(string expression)
{int length = expression.size();char element;elem Elem, fir, sec;stack<elem> STACK;for (int i = 0; i < length; i++){element = expression.at(i);switch (element){case '|':sec = STACK.top();STACK.pop();fir = STACK.top();STACK.pop();Elem = act_Unit(fir, sec);STACK.push(Elem);break;case '*':fir = STACK.top();STACK.pop();Elem = act_star(fir);STACK.push(Elem);break;case '+':sec = STACK.top();STACK.pop();fir = STACK.top();STACK.pop();Elem = act_join(fir, sec);STACK.push(Elem);break;default:Elem = act_Elem(element);STACK.push(Elem);}}cout << "已将正则表达式转换为NFA!" << endl;Elem = STACK.top();STACK.pop();return Elem;
}
-
变量定义以及含义:
expression: 输入的正则表达式字符串。element: 正则表达式中的单个符号。Elem:elem结构体,表示一个NFA的组成单元。fir和sec: 两个子表达式的NFA。STACK: 存储和操作NFA的组成单元的栈。
-
遍历正则表达式:
- 对于每个符号执行不同的操作。
- 如果符号是
|,弹出两个NFA,调用act_Unit(fir, sec)构造或运算的NFA,将结果压入栈。 - 如果符号是
*,弹出一个NFA,调用act_star(fir)构造闭包运算的NFA,将结果压入栈。 - 如果符号是
+,弹出两个NFA,调用act_join(fir, sec)构造连接运算的NFA,将结果压入栈。 - 如果符号是其他字符,调用
act_Elem(element)构造单个字符的NFA,将结果压入栈。
- 如果符号是
- 对于每个符号执行不同的操作。
-
返回结果:
- 从栈中弹出最后一个NFA的组成单元,赋值给
Elem,并将其作为函数的输出返回。
- 从栈中弹出最后一个NFA的组成单元,赋值给
三、生成dot文件
NFA经过上面步骤已经基本成型了,下面讲一讲dot文件。
根据百度百科:graphviz (英文:Graph Visualization Software的缩写)是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形。
简单理解,生成这个dot文件丢给这个工具就可以实现可视化,我依据我的NFA实现了一个生成dot文件的函数。
//生成NFAdot文件
void generateDotFile_NFA(const elem& nfa) {std::ofstream dotFile("nfa_graph.dot");if (dotFile.is_open()) {dotFile << "digraph NFA {\n";dotFile << " rankdir=LR; // 横向布局\n\n";dotFile << " node [shape = circle]; // 状态节点\n\n";dotFile << nfa.endName.nodeName << " [shape=doublecircle];\n";// 添加 NFA 状态dotFile << " " << nfa.startName.nodeName << " [label=\"Start State: " << nfa.startName.nodeName << "\"];\n";dotFile << " " << nfa.endName.nodeName << " [label=\"End State: " << nfa.endName.nodeName << "\"];\n";// 添加 NFA 转移for (int i = 0; i < nfa.edgeCount; i++) {const edge& currentEdge = nfa.edgeSet[i];dotFile << " " << currentEdge.startName.nodeName << " -> " << currentEdge.endName.nodeName << " [label=\"" << currentEdge.tranSymbol << "\"];\n";}dotFile << "}\n";dotFile.close();std::cout << "NFA DOT file generated successfully.\n";}else {std::cerr << "Unable to open NFA DOT file.\n";}
}
代码思路:
step1:创建一个输出流对象dotFile,并尝试打开一个名为"nfa_graph.dot"的文件,用于存储dot文件的内容。
step2:如果文件打开成功,向文件中写入了一些dot语法的规则,例如:
digraph NFA表示这是一个有向图,图的名字是NFA。rankdir=LR表示图的布局方向是从左到右。node [shape = circle]表示图中的节点的形状是圆形。nfa.endName.nodeName [shape=doublecircle]表示NFA的结束状态的节点的形状是双圆形。
Step3:向文件中写入了NFA的状态和转移的信息,例如:
nfa.startName.nodeName [label="Start State: nfa.startName.nodeName"]表示NFA的开始状态的节点的标签是"Start State: nfa.startName.nodeName",其中nfa.startName.nodeName是节点的名称。nfa.endName.nodeName [label="End State: nfa.endName.nodeName"]表示NFA的结束状态的节点的标签是"End State: nfa.endName.nodeName",其中nfa.endName.nodeName是节点的名称。currentEdge.startName.nodeName -> currentEdge.endName.nodeName [label="currentEdge.tranSymbol"]表示NFA的一条转移的边,从currentEdge.startName.nodeName节点指向currentEdge.endName.nodeName节点,边上的标签是currentEdge.tranSymbol,表示转移的符号。
step4:向文件中写入了一个右花括号,表示图的结束,然后关闭文件,并输出一条提示信息,表示NFA的dot文件生成成功。如果文件打开失败,输出一条错误信息,表示无法打开NFA的dot文件。
四、案例测试
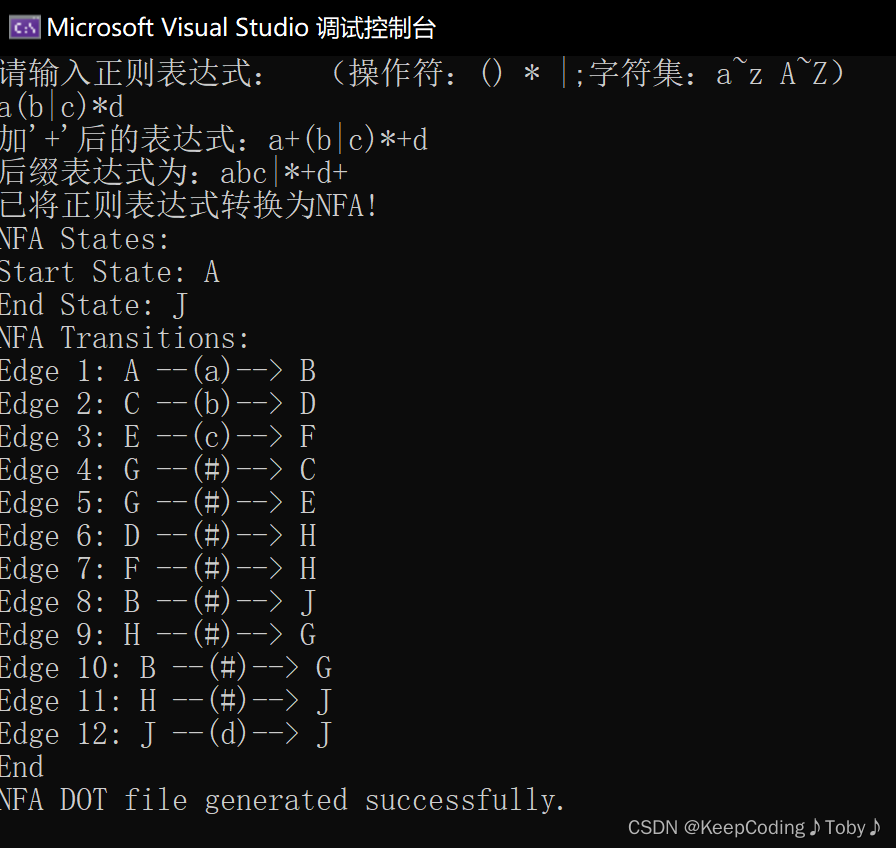
- (a|b|c)*
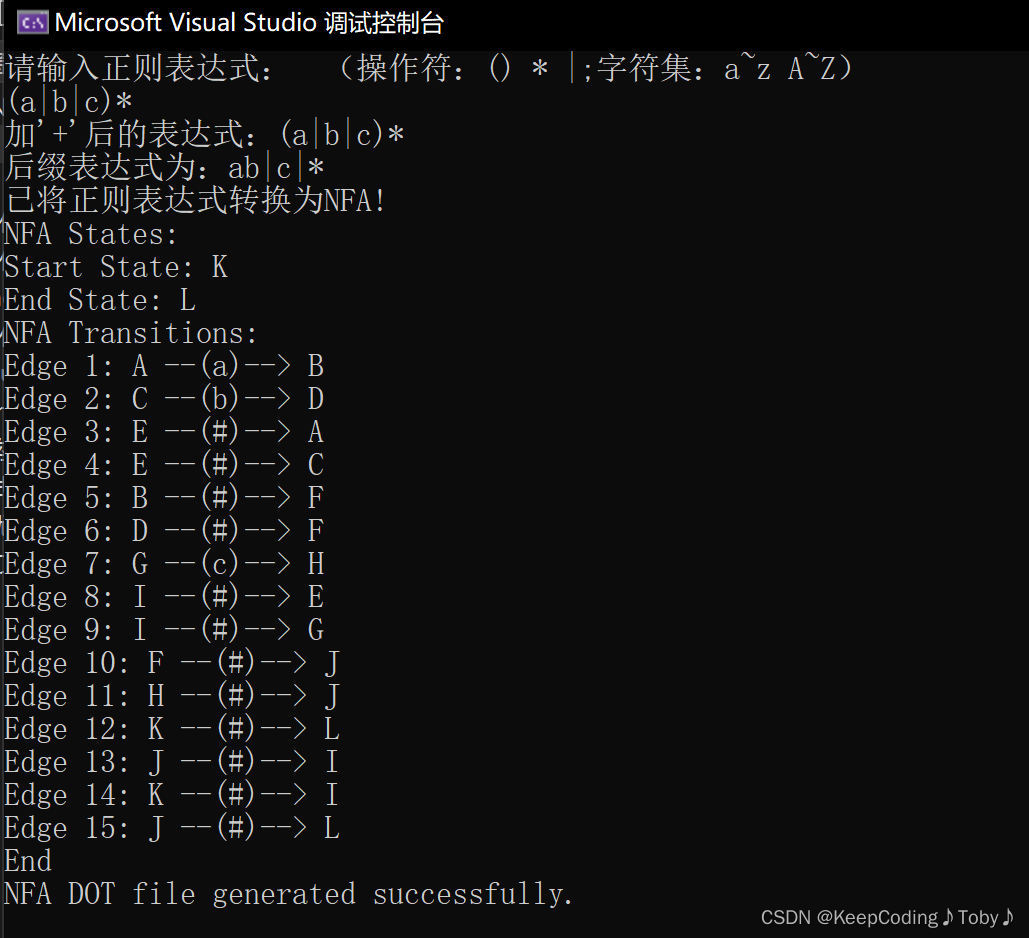
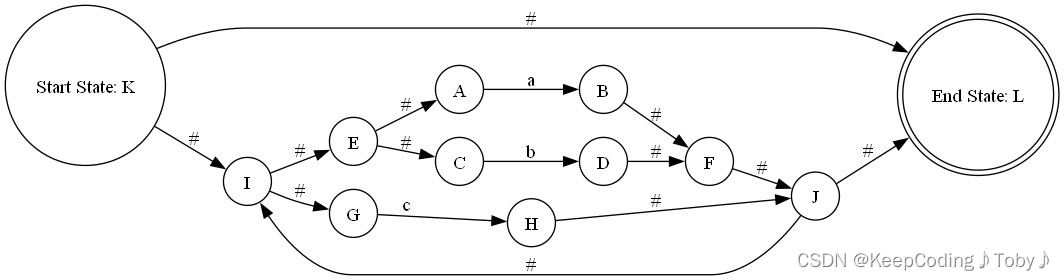
上面为在命令提示符中到指定目录下(你dot文件所在的目录下)输入指令将dot文件生成图片,然后打开visual studio目录,找到nfa.png:

- a(b|c)*de
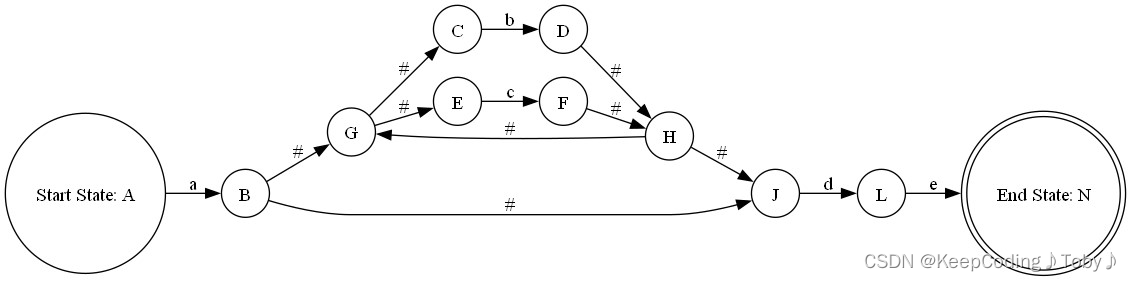
五、C++代码完整实现
//head.h
#ifndef HEAD_H
#define HEAD_H#include <iostream>
#include <stdio.h>
#include <cctype>
#include <stack>
#include <string>
#include <map>
#include <set>
#include <vector>
#include<iterator>
#include <fstream>using namespace std;//NFA的节点
struct node
{string nodeName;
};//NFA的边
struct edge
{node startName; //起始点node endName; //目标点char tranSymbol; //转换符号
};//NFA的组成单元,一个大的NFA单元可以是由很多小单元通过规则拼接起来
struct elem
{int edgeCount; //边数edge edgeSet[100]; //该NFA拥有的边node startName; //开始状态node endName; //结束状态
};//创建新节点
node new_node();//处理 a
elem act_Elem(char);//处理a|b
elem act_Unit(elem,elem);//组成单元拷贝函数
void elem_copy(elem&, elem);//处理ab
elem act_join(elem, elem);//处理 a*
elem act_star(elem);void input(string&);string add_join_symbol(string); //两个单元拼接在一起相当于一个+class infixToPostfix {
public:infixToPostfix(const string& infix_expression);int is_letter(char check);int ispFunc(char c);int icpFunc(char c);void inToPost();string getResult();private:string infix;string postfix;map<char, int> isp;map<char, int> icp;
};elem express_to_NFA(string);void Display(elem);int is_letter(char check);void generateDotFile_NFA(const elem& nfa);
#endif
//Func.cpp
#include "head.h"int nodeNum = 0;//创建新节点
node new_node()
{node newNode;newNode.nodeName = nodeNum + 65;//将名字用大写字母表示nodeNum++;return newNode;
}//接收输入正规表达式
void input(string& RE)
{cout << "请输入正则表达式: (操作符:() * |;字符集:a~z A~Z)" << endl;cin >> RE;
}//组成单元拷贝函数
void elem_copy(elem& dest, elem source)
{for (int i = 0; i < source.edgeCount; i++) {dest.edgeSet[dest.edgeCount+i] = source.edgeSet[i];}dest.edgeCount += source.edgeCount;
}//处理 a
elem act_Elem(char c)
{//新节点node startNode = new_node();node endNode = new_node();//新边edge newEdge;newEdge.startName = startNode;newEdge.endName = endNode;newEdge.tranSymbol = c;//新NFA组成元素(小的NFA元素/单元)elem newElem;newElem.edgeCount = 0; //初始状态newElem.edgeSet[newElem.edgeCount++] = newEdge;newElem.startName = newElem.edgeSet[0].startName;newElem.endName = newElem.edgeSet[0].endName;return newElem;
}//处理a|b
elem act_Unit(elem fir, elem sec)
{elem newElem;newElem.edgeCount = 0;edge edge1, edge2, edge3, edge4;//获得新的状态节点node startNode = new_node();node endNode = new_node();//构建e1(连接起点和AB的起始点A)edge1.startName = startNode;edge1.endName = fir.startName;edge1.tranSymbol = '#';//构建e2(连接起点和CD的起始点C)edge2.startName = startNode;edge2.endName = sec.startName;edge2.tranSymbol = '#';//构建e3(连接AB的终点和终点)edge3.startName = fir.endName;edge3.endName = endNode;edge3.tranSymbol = '#';//构建e4(连接CD的终点和终点)edge4.startName = sec.endName;edge4.endName = endNode;edge4.tranSymbol = '#';//将fir和sec合并elem_copy(newElem, fir);elem_copy(newElem, sec);//新构建的4条边newElem.edgeSet[newElem.edgeCount++] = edge1;newElem.edgeSet[newElem.edgeCount++] = edge2;newElem.edgeSet[newElem.edgeCount++] = edge3;newElem.edgeSet[newElem.edgeCount++] = edge4;newElem.startName = startNode;newElem.endName = endNode;return newElem;
}//处理 N(s)N(t)
elem act_join(elem fir, elem sec)
{//将fir的结束状态和sec的开始状态合并,将sec的边复制给fir,将fir返回//将sec中所有以StartState开头的边全部修改for (int i = 0; i < sec.edgeCount; i++) {if (sec.edgeSet[i].startName.nodeName.compare(sec.startName.nodeName) == 0){sec.edgeSet[i].startName = fir.endName; //该边e1的开始状态就是N(t)的起始状态}else if (sec.edgeSet[i].endName.nodeName.compare(sec.startName.nodeName) == 0) {sec.edgeSet[i].endName = fir.endName; //该边e2的结束状态就是N(t)的起始状态}}sec.startName = fir.endName;elem_copy(fir, sec);//将fir的结束状态更新为sec的结束状态fir.endName = sec.endName;return fir;
}elem act_star(elem Elem)
{elem newElem;newElem.edgeCount = 0;edge edge1, edge2, edge3, edge4;//获得新状态节点node startNode = new_node();node endNode = new_node();//e1edge1.startName = startNode;edge1.endName = endNode;edge1.tranSymbol = '#'; //闭包取空串//e2edge2.startName = Elem.endName;edge2.endName = Elem.startName;edge2.tranSymbol = '#';//e3edge3.startName = startNode;edge3.endName = Elem.startName;edge3.tranSymbol = '#';//e4edge4.startName = Elem.endName;edge4.endName = endNode;edge4.tranSymbol = '#';//构建单元elem_copy(newElem, Elem);//将新构建的四条边加入EdgeSetnewElem.edgeSet[newElem.edgeCount++] = edge1;newElem.edgeSet[newElem.edgeCount++] = edge2;newElem.edgeSet[newElem.edgeCount++] = edge3;newElem.edgeSet[newElem.edgeCount++] = edge4;//构建NewElem的启示状态和结束状态newElem.startName = startNode;newElem.endName = endNode;return newElem;
}int is_letter(char check) {if (check >= 'a' && check <= 'z' || check >= 'A' && check <= 'Z')return true;return false;
}
//添加连接符号
string add_join_symbol(string add_string)
{int length = add_string.size();int return_string_length = 0;char* return_string = new char[2 * length + 2];//最多是两倍char first, second;for (int i = 0; i < length - 1; i++){first = add_string.at(i);second = add_string.at(i + 1);return_string[return_string_length++] = first;//要加的可能性如ab 、 *b 、 a( 、 )b 等情况//若第二个是字母、第一个不是'('、'|'都要添加if (first != '(' && first != '|' && is_letter(second)){return_string[return_string_length++] = '+';}//若第二个是'(',第一个不是'|'、'(',也要加else if (second == '(' && first != '|' && first != '('){return_string[return_string_length++] = '+';}}//将最后一个字符写入secondreturn_string[return_string_length++] = second;return_string[return_string_length] = '\0';string STRING(return_string);cout << "加'+'后的表达式:" << STRING << endl;return STRING;
}//类里的各类元素定义
infixToPostfix::infixToPostfix(const string& infix_expression) : infix(infix_expression), postfix("") {isp = { {'+', 3}, {'|', 5}, {'*', 7}, {'(', 1}, {')', 8}, {'#', 0} };icp = { {'+', 2}, {'|', 4}, {'*', 6}, {'(', 8}, {')', 1}, {'#', 0} };
}int infixToPostfix::is_letter(char check) {if (check >= 'a' && check <= 'z' || check >= 'A' && check <= 'Z')return true;return false;
}int infixToPostfix::ispFunc(char c) {int priority = isp.count(c) ? isp[c] : -1;if (priority == -1) {cerr << "error: 出现未知符号!" << endl;exit(1); // 异常退出}return priority;
}int infixToPostfix::icpFunc(char c) {int priority = icp.count(c) ? icp[c] : -1;if (priority == -1) {cerr << "error: 出现未知符号!" << endl;exit(1); // 异常退出}return priority;
}void infixToPostfix::inToPost() {string infixWithHash = infix + "#";stack<char> stack;int loc = 0;while (!stack.empty() || loc < infixWithHash.size()) {if (is_letter(infixWithHash[loc])) {postfix += infixWithHash[loc];loc++;}else {char c1 = (stack.empty()) ? '#' : stack.top();char c2 = infixWithHash[loc];if (ispFunc(c1) < icpFunc(c2)) { // 栈顶操作符优先级低于当前字符,将当前字符入栈stack.push(c2);loc++;}else if (ispFunc(c1) > icpFunc(c2)) { // 栈顶操作符优先级高于当前字符,将栈顶操作符出栈并添加到后缀表达式postfix += c1;stack.pop();}else {if (c1 == '#' && c2 == '#') { // 遇到两个 #,表达式结束break;}stack.pop(); //其中右括号遇到左括号时会抵消,左括号出栈,右括号不入栈loc++;}}}
}string infixToPostfix::getResult() {postfix = ""; // 清空结果inToPost();return postfix;
}/**表达式转NFA处理函数,返回最终的NFA集合
*/
elem express_to_NFA(string expression)
{int length = expression.size();char element;elem Elem, fir, sec;stack<elem> STACK;for (int i = 0; i < length; i++){element = expression.at(i);switch (element){case '|':sec = STACK.top();STACK.pop();fir = STACK.top();STACK.pop();Elem = act_Unit(fir, sec);STACK.push(Elem);break;case '*':fir = STACK.top();STACK.pop();Elem = act_star(fir);STACK.push(Elem);break;case '+':sec = STACK.top();STACK.pop();fir = STACK.top();STACK.pop();Elem = act_join(fir, sec);STACK.push(Elem);break;default:Elem = act_Elem(element);STACK.push(Elem);}}cout << "已将正则表达式转换为NFA!" << endl;Elem = STACK.top();STACK.pop();return Elem;
}//打印NFA
void Display(elem Elem) {cout << "NFA States:" << endl;cout << "Start State: " << Elem.startName.nodeName << endl;cout << "End State: " << Elem.endName.nodeName << endl;cout << "NFA Transitions:" << endl;for (int i = 0; i < Elem.edgeCount; i++) {cout << "Edge " << i + 1 << ": ";cout << Elem.edgeSet[i].startName.nodeName << " --(" << Elem.edgeSet[i].tranSymbol << ")--> ";cout << Elem.edgeSet[i].endName.nodeName << endl;}cout << "End" << endl;
}//生成NFAdot文件
void generateDotFile_NFA(const elem& nfa) {std::ofstream dotFile("nfa_graph.dot");if (dotFile.is_open()) {dotFile << "digraph NFA {\n";dotFile << " rankdir=LR; // 横向布局\n\n";dotFile << " node [shape = circle]; // 状态节点\n\n";dotFile << nfa.endName.nodeName << " [shape=doublecircle];\n";// 添加 NFA 状态dotFile << " " << nfa.startName.nodeName << " [label=\"Start State: " << nfa.startName.nodeName << "\"];\n";dotFile << " " << nfa.endName.nodeName << " [label=\"End State: " << nfa.endName.nodeName << "\"];\n";// 添加 NFA 转移for (int i = 0; i < nfa.edgeCount; i++) {const edge& currentEdge = nfa.edgeSet[i];dotFile << " " << currentEdge.startName.nodeName << " -> " << currentEdge.endName.nodeName << " [label=\"" << currentEdge.tranSymbol << "\"];\n";}dotFile << "}\n";dotFile.close();std::cout << "NFA DOT file generated successfully.\n";}else {std::cerr << "Unable to open NFA DOT file.\n";}
}
//main
#include "head.h" // 包含提供的头文件int main() {string Regular_Expression;elem NFA_Elem;input(Regular_Expression);if (Regular_Expression.length() > 1) Regular_Expression = add_join_symbol(Regular_Expression);infixToPostfix Solution(Regular_Expression);//中缀转后缀cout << "后缀表达式为:";Regular_Expression = Solution.getResult();cout << Regular_Expression << endl;//表达式转NFANFA_Elem = express_to_NFA(Regular_Expression);//显示Display(NFA_Elem);//生成NFAdot文件generateDotFile_NFA(NFA_Elem);// 初始化 DFA 状态集合和转换关系vector<DFAState> dfaStates; //用于存储所有的DFA状态vector<DFATransition> dfaTransitions; //用于存储DFA状态之间的转移set<string> nfaInitialStateSet; //存储NFA的初始状态nfaInitialStateSet.insert(NFA_Elem.startName.nodeName); DFAState dfaInitialState = eClosure(nfaInitialStateSet,NFA_Elem);//计算NFA初始状态的ε闭包dfaStates.push_back(dfaInitialState);// 开始构建 DFAfor (int i = 0; i < dfaStates.size(); i++) {DFAState dfaState = dfaStates[i];for (int j = 0; j <NFA_Elem.edgeCount; j++) {char symbol = NFA_Elem.edgeSet[j].tranSymbol;DFAState nextState = move(dfaState, symbol,NFA_Elem);DFAState dfaNextState = eClosure(nextState.nfaStates, NFA_Elem);if (!nextState.nfaStates.empty()) {if (!isDFAStateInVector(dfaStates, dfaNextState)) {dfaStates.push_back(dfaNextState);}//对于边也要去重,因为等于a的边可能会遍历到两次if (!isTransitionInVector(dfaState, dfaNextState, symbol, dfaTransitions)) {dfaTransitions.push_back({ dfaState,dfaNextState, symbol });}}}}// 显示 DFAdisplayDFA(dfaStates, dfaTransitions);//生成DFAdot文件generateDotFile_DFA(dfaStates,dfaTransitions);return 0;
}
这篇关于编译原理:正则表达式/正规式转NFA(原理+完整代码+可视化实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






