本文主要是介绍Mysql高级一锅端,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、性能分析
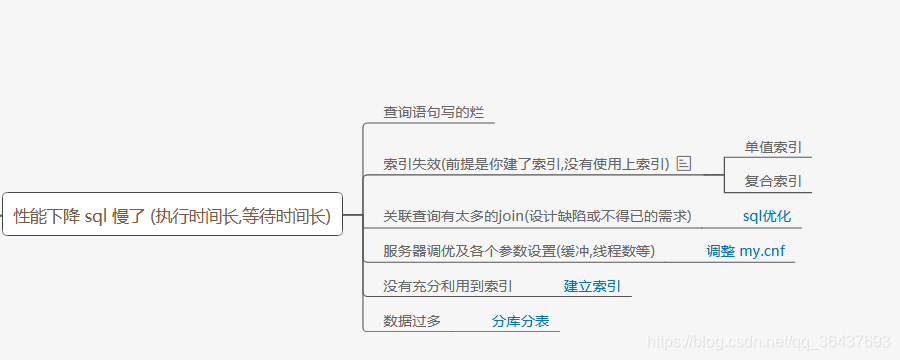
1、性能下降SQL慢(执行时间长,等待时间长)的原因
下面感觉是废话,查询语句写的烂才导致索引失效,总体就三点,SQL写的烂,数据量大,服务器调优不好
2、常见的通用Join查询
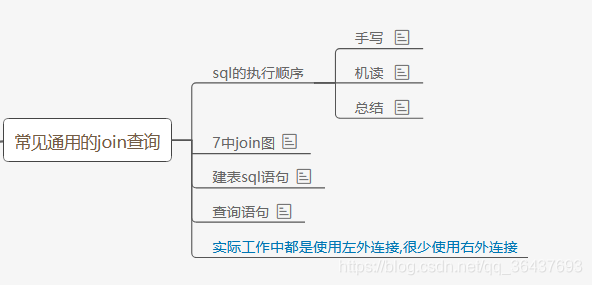
SQL手写执行顺序和SQL在机器中读取顺序
手写:
select district 查询字段
from 表名1
[left]/[right]/[inner] join 表名2
on 表1.字段=表2.字段
where 查询条件
group by 分组字段
having 分组后判断条件
order by 排序字段 [asc|desc]
limit 分页字段机器:
1.执行from 表名1
2.执行 on 关联条件得到它们的交集
3.执行[left|right|inner] join 表名2
4.执行 where 判断条件
5.执行 group by 进行分组
6.执行 having 对结果再次进行筛选
7.执行select
8.执行 order by 进行排序
9.执行limit下面的是对应的7中Join查询
学习文档:https://blog.csdn.net/software_Manito/article/details/108326619
友情提示:mysql的join没有全表的full out join,只能使用union,这个关键字会将重复的内容只取一份
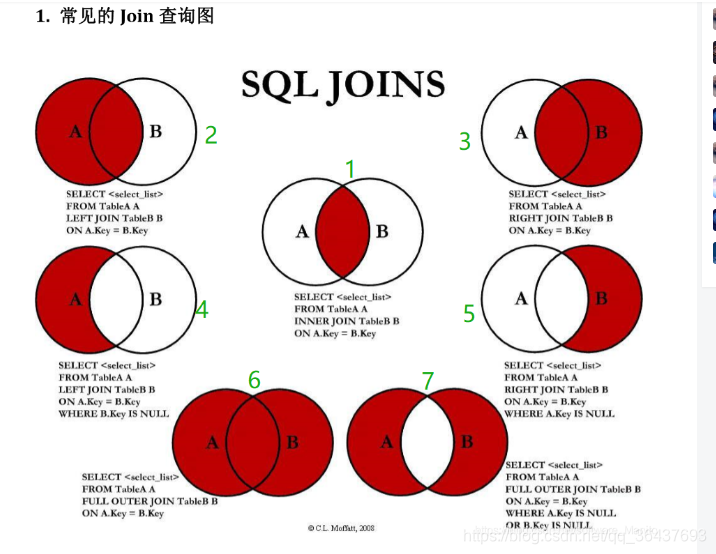
下面的对应上面的图片的7种查询
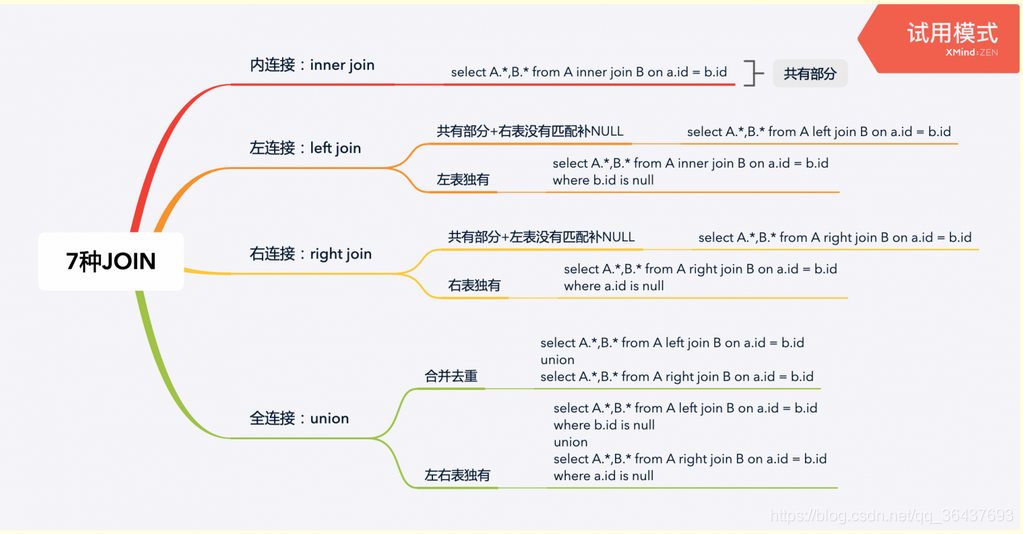
练习Join的7种情况
/**部门表*/
create table tbl_dept(
id int not null primary key auto_increment,
deptname varchar(30) default null,
locAddr varchar(40) default null
);/**员工表*/
create table tbl_emp(
id int not null primary key auto_increment,
empName varchar(30) default null,
deptld int not null,
constraint fk_emp_dept foreign key (deptld) references tbl_dept(id)
);insert into tbl_dept values (null,'RD',11),(null,'HR',12),(null,'MK',13),(null,'MIS',14),(null,'FD',15);insert into tbl_emp values (null,'zs1',1),(null,'zs2',1),(null,'zs3',1),(null,'wangwu1',2),(null,'王五2',2);alter table tbl_emp modify empName varchar(30) character set utf8;-- 员工表和部门表内连接
select * from tbl_emp e inner join tbl_dept d on e.deptld = d.id;-- 左连接
select * from tbl_emp e left join tbl_dept d on e.deptld = d.id;-- 右连接
select * from tbl_emp e right join tbl_dept d on e.deptld = d.id;-- 左外连接select * from tbl_emp e left join tbl_dept d on e.deptld = d.id where d.id is null;-- 右外连接
select * from tbl_emp e right join tbl_dept d on e.deptld = d.id where e.deptld is null;-- 全连接(mysql 不支持full outer )select * from tbl_emp e left join tbl_dept d on e.deptld = d.id
UNION
select * from tbl_emp e right join tbl_dept d on e.deptld = d.id;select * from tbl_emp e left join tbl_dept d on e.deptld = d.id where d.id is null
UNION
select * from tbl_emp e right join tbl_dept d on e.deptld = d.id where e.deptld is null;3、什么是索引
索引是帮助mysql高效获取数据的数据结构.在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级算法.这种数据结构,被称为索引。从本质上来说,索引就是数据结构.可以简单地理解为:索引是排好序的快速查找的数据结构.是为了解决SQL数据过于庞大引起效率下降的优化方案

为什么Mysql索引不用二叉树?
如果插入的数据是连续的,优先考虑的应该是链表,这样想到的应该是B树(又叫平衡树)
结论
数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引(B+树 或 Btree+)是B+树不是B树
索引的优势和劣势


劣势中为什么更新表会变慢
如对表进行 insert / update / delete 因为更新表时,Mysql不仅要保存记录,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新带来的键值变化后的索引信息。间隙锁
delete 删除一个数据后,数据之间会留下一个间隙 --后面会说
索引结构(重点)
1、快速理解平衡二叉树(AVL树)、B-tree(B树)、B+tree、B*tree(想了解RB树(红黑树)的可以百度)
参考地址:https://www.pianshen.com/article/48761526321/
简单理解参考地址:https://my.oschina.net/u/3370829/blog/1301732
参考地址:https://blog.csdn.net/v_JULY_v/article/details/6530142/
2、红黑树的区别

3、那么为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?

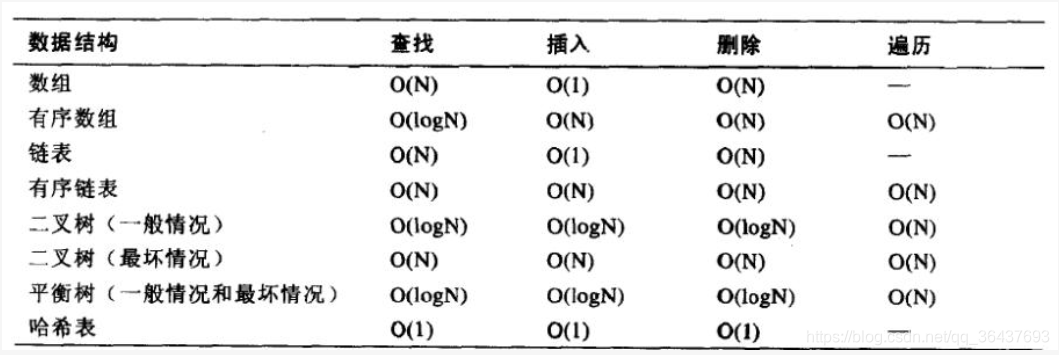
4、聚簇索引与非聚簇索引
聚簇索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
非聚簇索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
非聚集索引 vs 聚集索引
- MyISAM 是非聚集索引:索引和数据分开,索引只保存了数据记录的地址。Primary Key(主键/主索引)和Secondary Key(辅助索引)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。(适合读操作)
- InnoDB 是聚集索引: 索引和数据在一起,Primary Key(主键/主索引)的叶节点直接包含数据记录,Secondary Key(辅助索引)保存的是Primary Key的值。因此如果用Secondary Key(辅助索引)需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。(适合高并发写操作)
参考文档:https://blog.csdn.net/qq_29373285/article/details/85254407
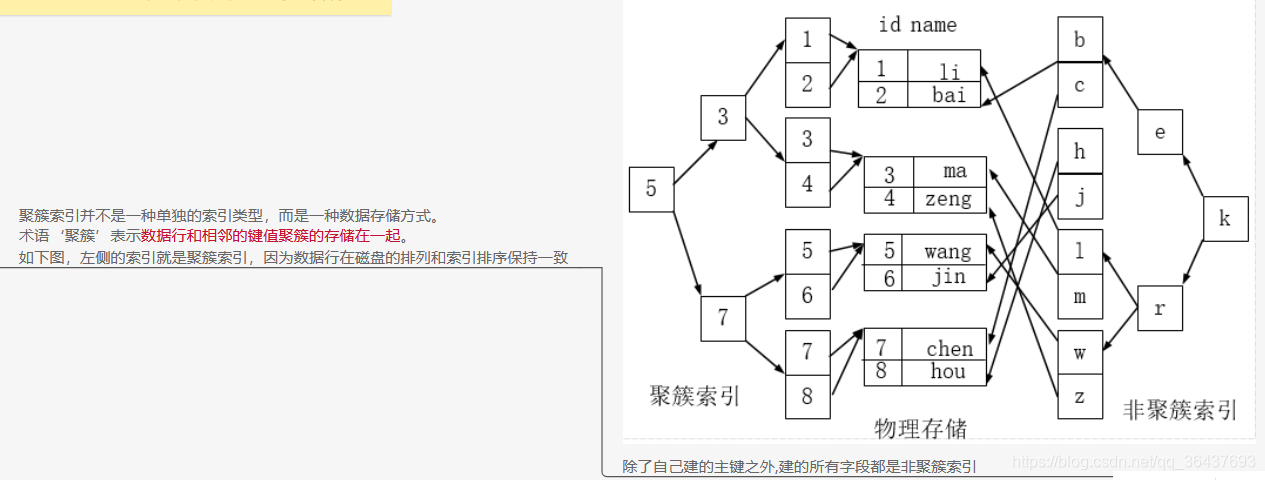
Mysql索引分类(4个)
友情提示:
1、建议:一张表的索引一般不要超过5个
2、聚焦索引又叫主键索引
3、MySql自带的全文索引只能用于数据库引擎为MYISAM的数据表,如果是其他数据引擎,则全文索引不会生效。此外,MySql自带的全文索引只能对英文进行全文检索,目前无法对中文进行全文检索。如果需要对包含中文在内的文本数据进行全文检索,我们需要采用Sphinx(斯芬克斯)/Coreseek技术来处理中文。
外加全文索引文档:http://blog.itpub.net/26736162/viewspace-2144690/

mysql索引基本用法
1.索引的建立
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName](columnname(length))
2.索引删除
drop index 索引名 on 表名
3.查询看索引
show index from 表名
alter四种创建索引方式
#给表添加一个主键,这意味着索引值必须是唯一的,且不能为null
alter table 表名 add primary key (主键字段);#创建索引的值必须是唯一的(除了null外,null可能会出现多次修改)
alter table 表名 add unique 表名(表字段);#添加普通索引
alter table 表名 add index 表名(字段);#全文索引
alter table 表名 add fulltext 表名(字段);不给索引名,如何根据表名和库名删除索引,只剩下主键索引
间接获取到索引命,直接删除就好
查询索引名:
SELECT s.INDEX_NAME,s.COLUMN_NAME,s.INDEX_TYPE,s.CARDINALITY FROM information_schema.STATISTICS s WHERE s.TABLE_NAME ='tbl_emp' AND s.TABLE_SCHEMA = 'hightmysql' and index_name <> 'test' and seq_in_index=1
使用存储过程删除代码
delimiter $$
create procedure drop_all_index(dbname varchar(200),tablename varchar(200))
begin
-- 创建变量
declare done int default 0;
declare ct int default 0;
declare _index varchar(200) default '';
-- 建立游标 cursor for 查询全部的非主键的索引名
declare _cur cursor for select s.INDEX_NAME from information_schema.STATISTICS s where s.table_name=tablename and s.table_schema=dbname and index_name <> 'PRIMARY' and seq_in_index=1;
declare continue handler for not found set done=2;-- 打开游标
open _cur;
-- 取出游标的一个值 赋值给_index
fetch _cur into _index;
-- 循环
while _index <> '' do
-- 拼写drop 语句
set @str=concat("drop index ",_index," on ",tablename);
-- @str预编译为sql语句
prepare sql_str from @str;
-- execute 执行sql
execute sql_str;
deallocate prepare sql_str;
-- _index 重新赋值为null
set _index='';
fetch _cur into _index;
end while;
-- 关闭游标
close _cur;
end $$Mysql索引结构
友情提示:下面的BTree索引改为B+树索引
B+树索引原理
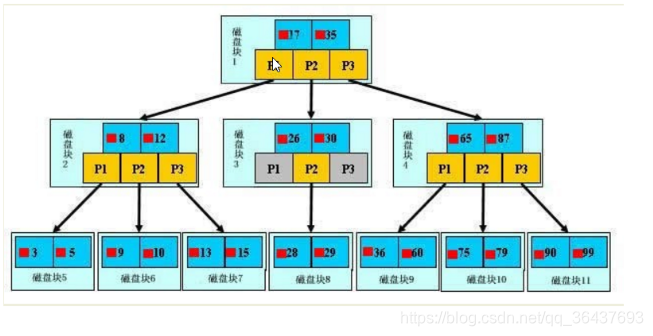
初始化介绍
一颗B+树,浅蓝色的块我们称为一个磁盘块,可以看成每个磁盘块包含几个数据项(深蓝色所示) 和 指针(黄色所示),如磁盘块17包含数据项17-35,包含指针P1,P2,P3,
P1表示小于17的磁盘块,P2表示17-35的磁盘块,P3表示大于35的磁盘块。
真实的数据存在于叶子节点 即 3,5,9,10,13,15,28,29,36,60,75,79,90,99
非叶子节点不存储真实的数据,只存储指针引搜索方向的数据项,如17-35并不真实存储于数据表中。
[查找过程]
1.如果要查找数据项29,那么首先会把磁盘块17由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29-35之间,锁定磁盘块1的P2指针,内存查找的时间因为非常短(相比磁盘的IO)可以忽略不计
2.通过磁盘块1的P2指针的磁盘块3由磁盘加载到内存,发生第二次IO,
3.29在26-30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分法查找到29,查询结束,总结三次IO
B树只有三层结构,只能横向拓展
真实的情况是,3层的B树可以表示上百万的数据,如果上百万的数据查找需要经过三次IO,性能提高是巨大的,如果没有索引,每个数据项都要发生一次,那么共需百万次IO,显然成本是非常高的。
什么情况下建立索引
友情提示:频繁的更新字段不适合建立索引是因为,修改字段的同时还要维护索引

什么情况下需要建立索引
友情提示:
1、为什么经常增删改的字段不适合建立索引:索引虽然提高了查询速度,同时却降低了更新表的速度,如对表进行 insert / update /delete 执行更新表,mysql 不仅要保存数据还需要保存一下索引文件
2、百万数据都是重复内容: 如果某个数据列包含许多重复的内容,Wie它建立索引就灭偶遇太大的实际效果,假如一个表中有10万行数据,有一个字段A只有 true 和 false 俩种值,且每个值的分布概率大约为 50%,那么对这种表A字段建立索引一般不会提高数据库的查询速度。索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中2000条记录,表索引列又1980个不同的值,那么这个索引的选择性就是 1980/2000 =0.99 。一个索引的选择越接近1,这个索引的效率就越高

性能分析:
1、Mysql Query Optimizer:(mysql 查询优化器)
1、Mysql 中有专门负责优化 select 语句的优化器模块,主要功能: 通过计算分析系统中手机到的统计信息,为了客户端请求的 Query 提供他认为最优的执行计划(它认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分是最耗时间的)这也是在后面进行分析执行表的顺序和自己写的不一样
2.当客户端向Mysql 发送一条Query ,命令解析器模块完成请求分类,去别出 Select 并转发给 Mysql Query Optimizer 时,Mysql Query Optimizer 首先会对整条的 Query 进行优化,处理掉一些常量表达式的预算,直接换算成常量值。并对 Query 进行简化和转换,如去掉一些无用或显而易见的条件,结构调整等,然后分析Query 中的 Hint 信息(如果有),看显示 Hint 信息是否完全确定该 Query 的执行计划。 如果没有 Hint 或 Hint 信息还不足于完全确认它的执行计划,则会读所涉及对象的统计信息,根据 Query 进行写相应的计算分析,然后再得出最后的执行计划。
2、Mysql常见的瓶颈

Explain详细介绍(重点)又叫mysql的执行计划
1、介绍:
使用Explain 关键字可以模拟优化器执行 sql 查询语句,从而知道 Mysql 是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
Mysql官网 Explain out format 官方网站
2、可以做什么
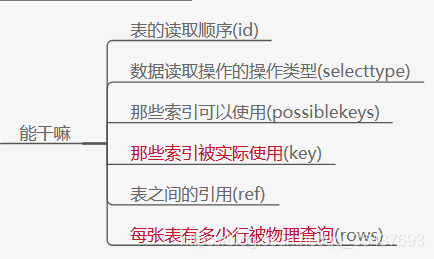
3、如何使用:

查询的字段有哪些(红色的是重点)

字段解释(重点)
1、id
作用:根据字段查看表在数据库中执行的顺序
友情提示:id的个数,表示一次独立的查询,ID个数越少越好
案例
1、ID相同,执行顺序由上到下
explain select * from tbl_emp e inner join tbl_dept d on e.deptld = d.id;
2、id 不同,编号大的先执行
explain select * from tbl_emp where deptld =(select id from tbl_dept where deptname = 'MK');
3、id有相同,有不同,先执行编号大的,编号一样的由上向下执行

2、Select_type
作用:查询类型,从宏观角度看,这个SQL是什么样的SQL,简单?嵌套的?结合的等,个人感觉没有,我不会看自己写的SQL吗
| select_type Value | 意思 |
|---|---|
| SIMPLE | 简单select(不使用UNION或子查询) |
| PRIMARY | 最外层的select(例如 鸡蛋壳) |
| UNION | 若在第二个select 出现在 union 之后则被标记为union,若union包含在from子句查询中,外层的select将被标记为derived |
| DEPENDENT UNION | UNION中的第二个或更高的SELECT语句,取决于外部查询 |
| UNION RESULT | 从UNION 表获取结果的 select |
| SUBQUERY | 子查询中的第一个 select |
| DEPENDENT SUBQUERY | 子查询而第一个select 依赖于外部查询 |
| DERIVED | 在from列表中包含子查询被标记为 derived(衍生) Mysql 会递归执行这些子查询,把结果放在临时表中 |
| MATERIALIZED | 实现子查询 |
| UNCACHEABLE SUBQUERY | 不能缓存其结果的子查询,并且必须针对外部查询的每一行重新求值 |
| UNCACHEABLE UNION | union中属于不可缓存子查询的第二个或更高版本的select |
3、table
作用:输出行的引用的表的名称。(结合id看的执行哪一张表,这就是要执行的表)
4、partitions(不知道没关系)
作用:查询将从中匹配记录的分区。对于未分区的表,该值为NULL。
5、type(重点)
作用:(就是看SQL写的好坏)
友情提示:如果你的type类型为 all 并且你的数据在 百万以上的请你优化你的sql语句
完整的集合排序:
system > const > eqref > ref > fulltext > refornull > indexmerge > uniquesubquery > indexsubquery > range > index > ALL
一般来说 ,得保证查询至少达到 range 级别,最好能达到 ref 。

type级别介绍
1、system:
表中总共只有一行数据,这个一般SQL语句看不到,这是const类型的特例,平时不会出现,这个也可以忽略不计
2、Const
表有索引,用于比较主键或者Union索引,并且查询只有一条记录(单值索引查询一条记录)
这类扫描效率极高,返回的数据少,效率块

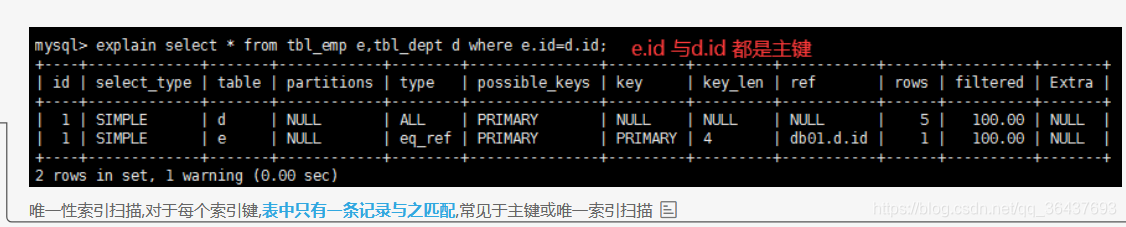
3、eq_ref
根据唯一性索引,在表中获取到唯一与之想匹配,(说白了就是查询的内容一一对应)
eq_ref扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:
(1)join查询;
(2)命中主键(primary key)或者非空唯一(unique not null)索引;
(3)等值连接;
如上例,id是主键,该join查询为eq_ref扫描。
这类扫描的速度也异常之快。
4、ref
当id改为普通非唯一索引后,常量的连接查询,也由const降级为了ref,因为也可能有多于一行的数据被扫描。ref扫描,可能出现在join里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比eq_ref要慢,但它仍然是一个很快的join类型。

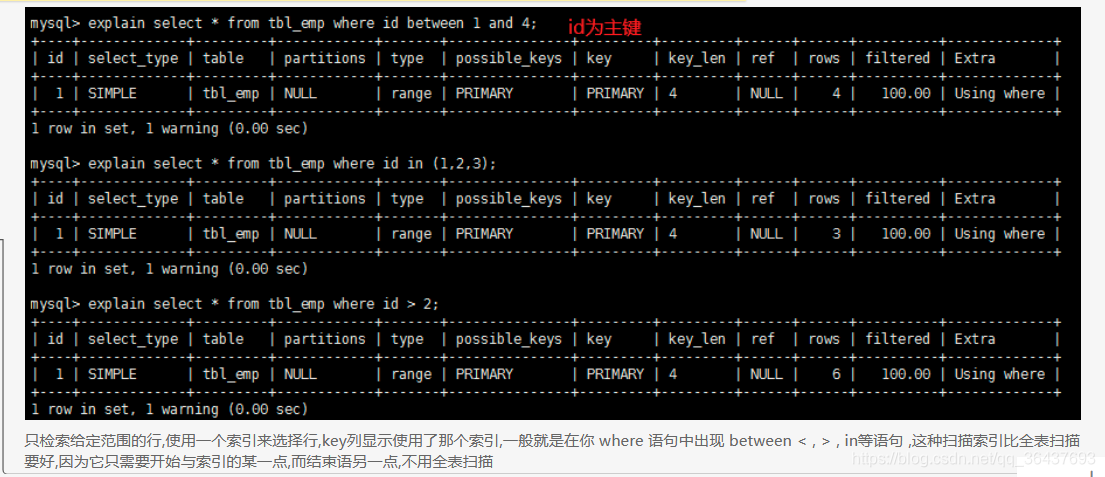
5、range
带有范围的检索,不是全表检索,效率比全表检索高
6、index
这种连接类型只是另外一种形式的全表扫描,只不过它的扫描顺序是按照索引的顺序。这种扫描根据索引然后回表取数据,和all相比,他们都是取得了全表的数据,而且index要先读索引而且要回表随机取数据,因此index不可能会比all快(取同一个表数据),但为什么官方的手册将它的效率说的比all好,唯一可能的原因在于,按照索引扫描全表的数据是有序的。这样一来,结果不同,也就没法比效率的问题了。
7、all
全表扫描,效率低下,有种排序算法种的暴力查找

7、index_merge
查询中用到了or

8、ref_or_null
关联的字段,这个字段值是Null

剩余二个字段

6、possiblekeys
(说白了,就是Mysql自己认为可能会用到的索引) possiblekeys和key结合使用
作用:显示可能应用在这张表的索引,一个或者多个,查询到该字段设计到的索引,都会被列出。

7、key
作用:展示实际用到索引
8、Key_len
计算索引长度,在后面分析那些字段走索引,字段走的索引越多,该长度越长
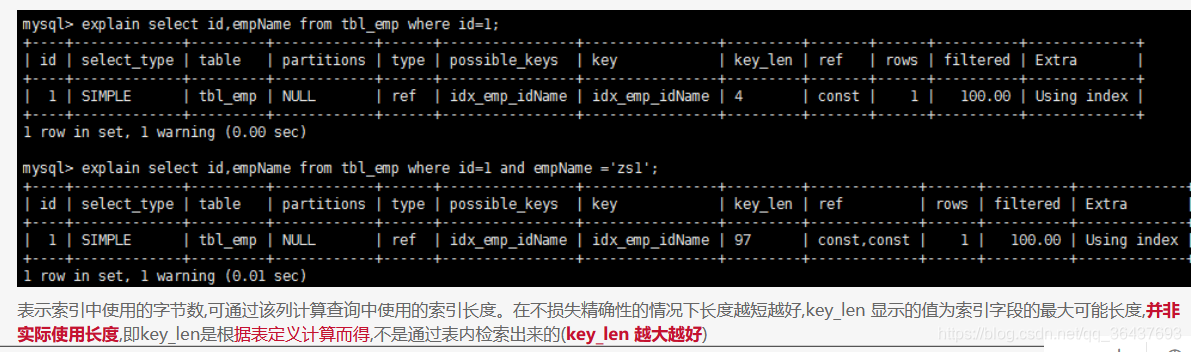
9、ref
(说白了,设置的字段索引,那些字段走索引,在这里都能显示)
友情提示:注意和type字段中的ref属性不要搞混淆
查询中与其它关联表的字段,外键关联建立索引,

9、row
值越小越好,表示查询的行数越短

10、filtered
表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。

11、extra(重点)
参考文档:https://www.jianshu.com/p/b49450f272f6
下面介绍对应的类型:
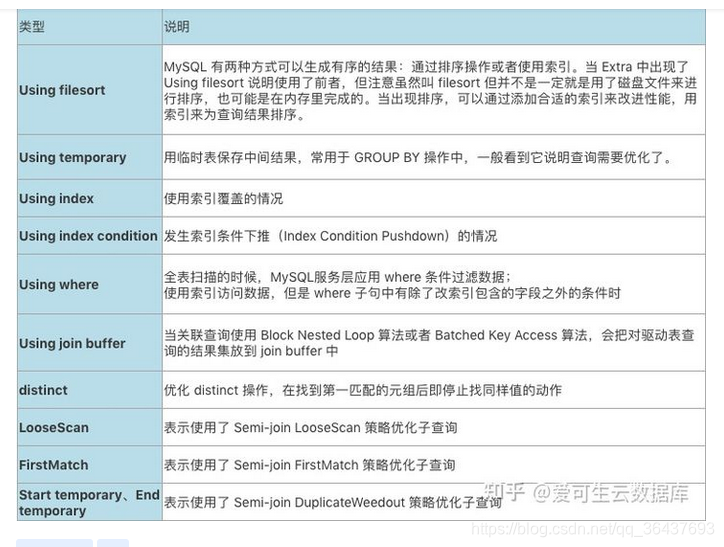
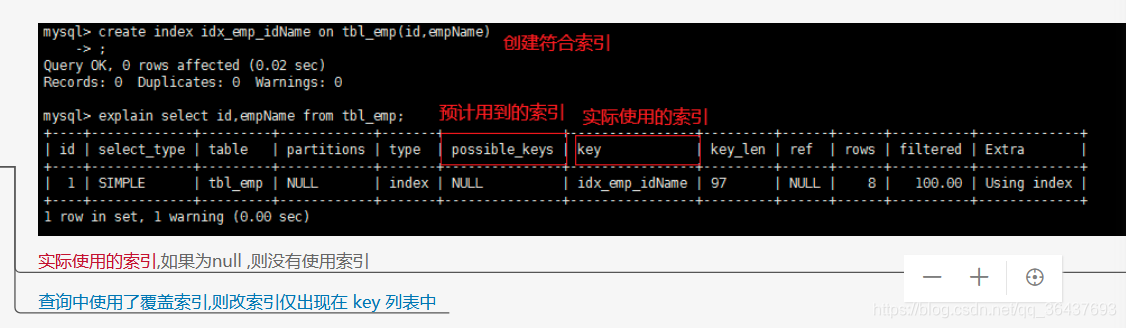
1、Using index
表示使用索引,如果只有 Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。如果同时出现Using where,代表使用索引来查找读取记录, 也是可以用到索引的,但是需要查询到数据表。
2、Using where
表示优化器需要通过索引回表查询数据 ,意思就是说,从索引表回到数据库表查询
友情提示:数据库查看执行计划,会看到extra出现using index & using where :表示的是查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
3、Using index condition
在5.6版本后加入的新特性(Index Condition Pushdown),会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行,也就是说需要回表查询
4、Using join buffer
使用了连接缓存(join太多个表,配置文件里面的JoinBuffer的值可以调大一点)
5、Impossible where
where条件后面查询不到,where条件后面查询一个既是女生又是男生。这个是查不到的。中国不谈人妖,只有男女
6、Select table optimized away
在没有GroupBy子句的情况下,基于索引优化Min/Max操作或者对于MyISAM存储引擎优化Count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化
7、Using filesort(要命三千)
Using filesort表示在索引之外,需要额外进行外部的排序动作。导致该问题的原因一般和order by有者直接关系,一般可以通过合适的索引来减少或者避免。
8、Using temporary(要命三万)
表示为了得到结果,使用了临时表,这通常是出现在多表联合查询,结果排序的场合。
9.distinct
优化distinct操作,在找到第一个匹配的元组后即停止找同样值的动作
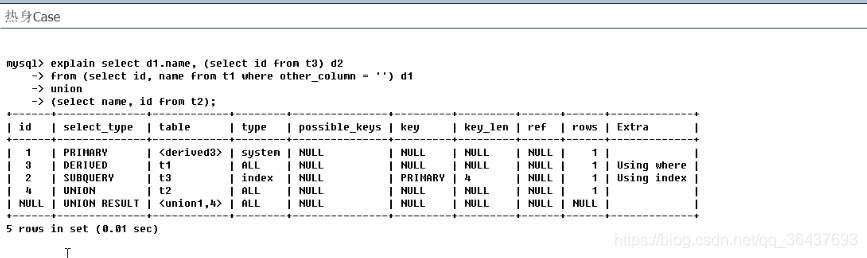
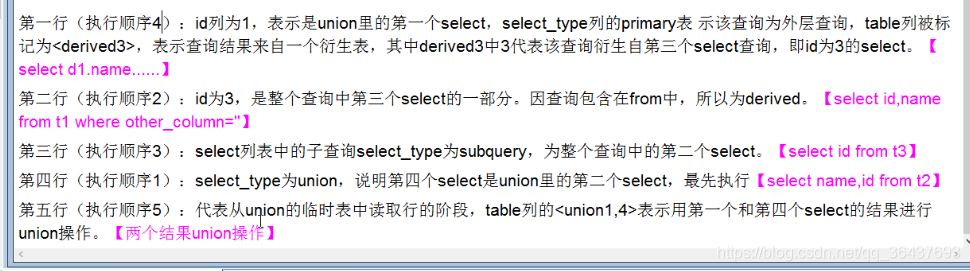
热身Case小案列
二、索引优化
索引分析
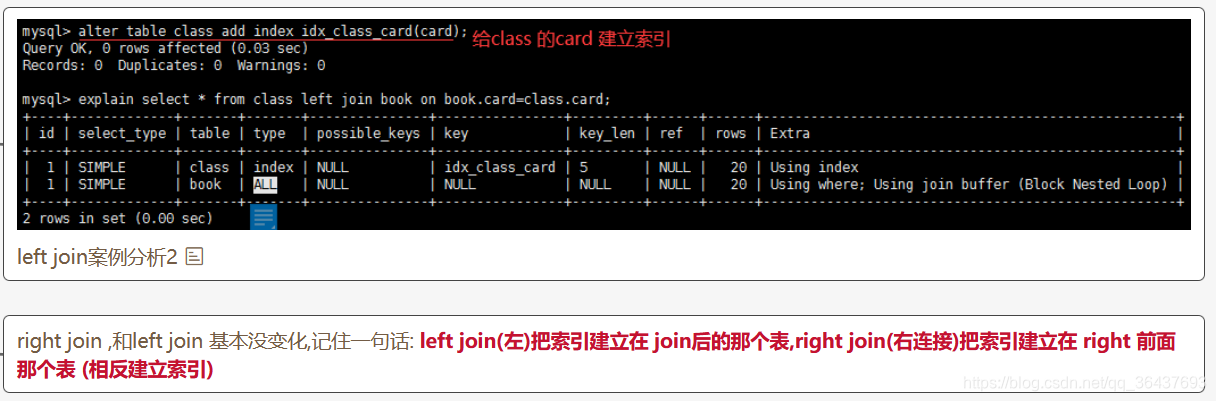
一定要记住重点
1、在进行左连接建立索引应该建立在join后面的那个表
2、如果是右连接建立索引应该建立在right前面的那张表
总结:

三、索引失效如何避免
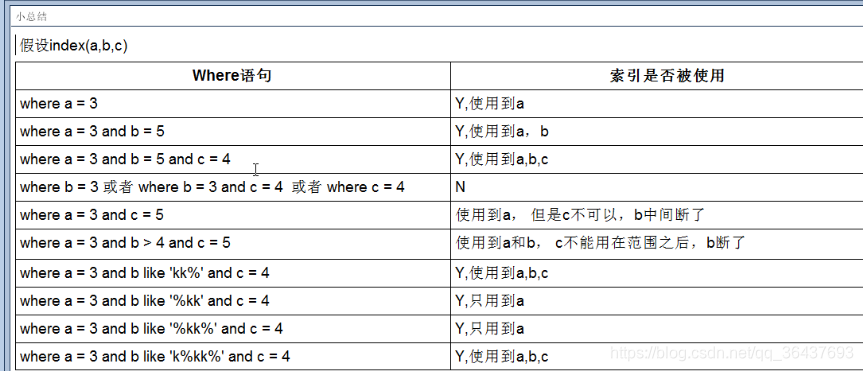
1、遵循最左原则,如果索引多列,要遵循最左前缀法则,指的是查询从索引的最左侧前列开始并且不要跳过索引中间列
2、不在索引where列上做任何操作,(计算,函数,(自动or手动)类型转换),会导致索引失效转向全表扫描
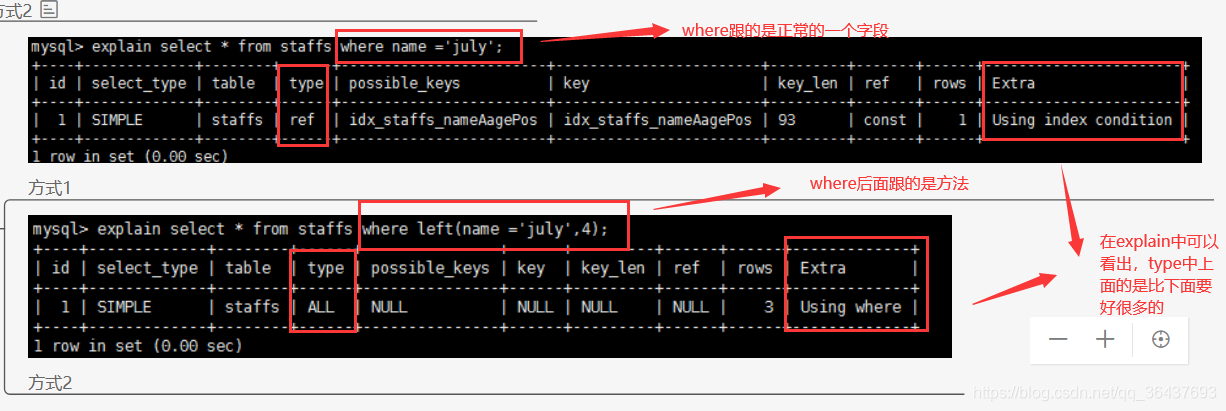
3、存储引擎不能使用索引中范围条件右边的列(这里说的是建索引的地方)
通俗点:在复合索引,在连续的索引字段中,如果某一个字段按照范围查找,后面的索引字段就会失效。相比之前的执行计划中的type类型也会上升一级变为range
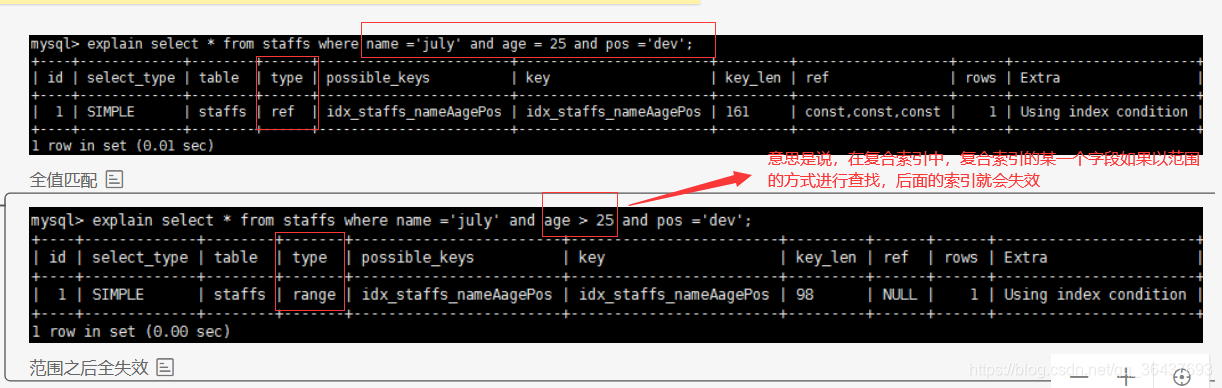
4、尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
5、在mysql中使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
6、is null走索引,is not null是不走索引的
7、 like 以通配符开头 ('%abc') mysql索引会失效会变为全表扫描,就是说Like右边只要有%,对应的索引就会失效
注意:针对上面的问题,如何不要索引失效,实现覆盖索引,覆盖索引(你建的索引和你查的字段个数顺序上最好完全一致),也就是说创建的索引的复合索引,在进行查询的时候,执行的是覆盖索引。
8、查询字段中,字符串不加单引号索引失效
9、使用Or进行连接索引会失效
10、小表驱动大表 ,小表放在驱动表 ,大表放在被驱动表,当我们进行关联查询的时候,尽量给被驱动表建立索引,驱动表不必建立索引
什么是小表和大表,参考文档:https://www.cnblogs.com/developer_chan/p/9247185.html
如何区分大表和小表在比如有两张表
在查询中最好使用小表驱动大表,因为在外层表循环内层的时候,会锁定外层表,如果大表在外,会锁定5k次 。
如果要求查询所有id相同的Aname 有两种查询方式
1.由B表驱动A表 会先执行子查询 大表驱动小表
2.由A表驱动B表 会先执行主查询 小表驱动大表
注意下面的exit和in之间是如何转换的
exit后面跟大表,in跟小表


友情提示:
下面结论都是针对in或exists的。
in后面跟的是小表,exists后面跟的是大表。
简记:in小,exists大。
对于exists
select .....from table where exists(subquery);
可以理解为:将主查询的数据放入子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据是否得以保留。
总结:
单表建议:

单表口诀:
1.头部打个不能丢,中间兄弟不能断
2.永远要符合最佳最左侧前缀法则
3.索引列上无计算
4.like %加右边
5.范围之后全失效
6.字符串里有引号
关联表建议:

子查询建议:

索引失效小总结
面试题讲解:
1、索引顺序和where查询的顺序不同(不包含< 或者 >)
看到下面可以看出在复合索引,都存在但是顺序不一致,但是还是走索引,这是mysql底层进行的一个内部调节
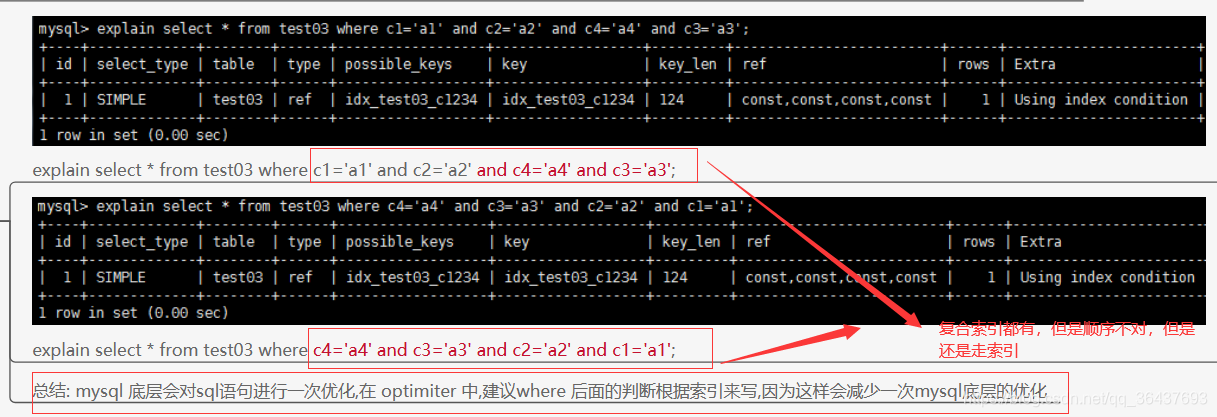
2、索引总用到order by(出现using filesort就是没有用到索引)
参考文档:https://www.cnblogs.com/developer_chan/p/9225638.html
友情提示:
①MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
②order by满足两种情况会使用Using index。
#1.order by语句使用索引最左前列。
#2.使用where子句与order by子句条件列组合满足索引最左前列。
③尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最佳左前缀法则。
④如果order by的条件不在索引列上,就会产生Using filesort。
三、查询截取分析

全文内容来自:https://www.processon.com/view/5f605d597d9c0833ecdec4e0#map
参考文档:https://www.cnblogs.com/developer_chan/p/9225638.html
参考文档:https://blog.csdn.net/cyd_0619/article/details/113662635?spm=1001.2014.3001.5501
这篇关于Mysql高级一锅端的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





