本文主要是介绍【从零到Offer】MySQL最左匹配,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
相信大家在日常开发时,也经常能听到“最左匹配”这个词,那么什么是最左匹配呢?本篇文章就带你一起探索“最左匹配”的神奇秘密。
什么是最左匹配
最左匹配,通常指的是最左前缀匹配原则,即MySQL在检索数据时从联合索引的最左边开始匹配。
那么如何检验MySQL确实是按照最左匹配在查询数据呢?实践是检验真理的唯一标准。
create table index_table
(id int auto_increment,a int default 0 not null ,b int default 0 not null ,c int default 0 not null ,d int default 0 not null,constraint index_table_id_uindexunique (id)
);create index index_table_a_b_c_indexon index_table (a, b, c);
这里新建一张数据表,并建立(a,b,c)三列的联合索引。建好表后,往表中添入数据。
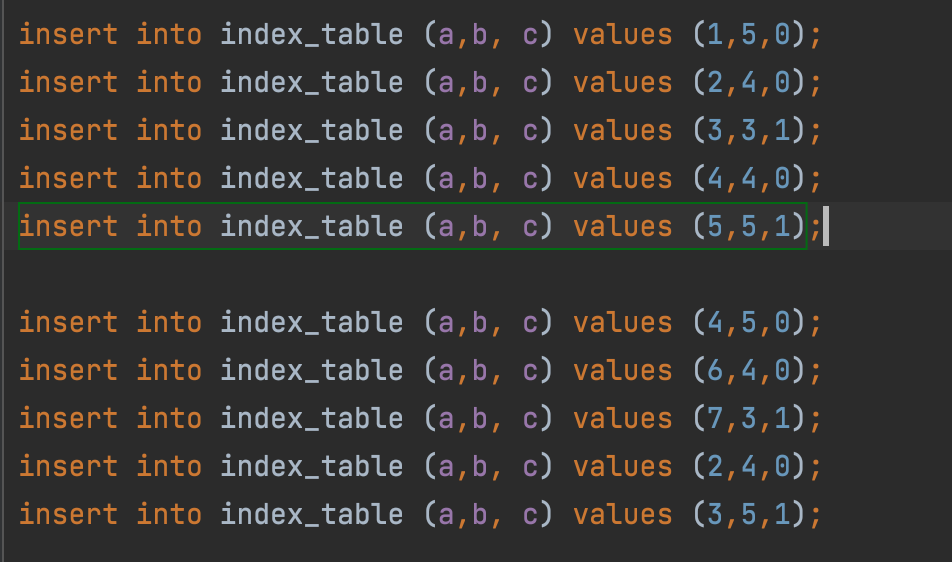
如此一来初始数据就准备好了。但是下一个问题来了,如何检验当前查询是否走了对应的索引呢?这里简单介绍下MySQL是如何执行SQL的:
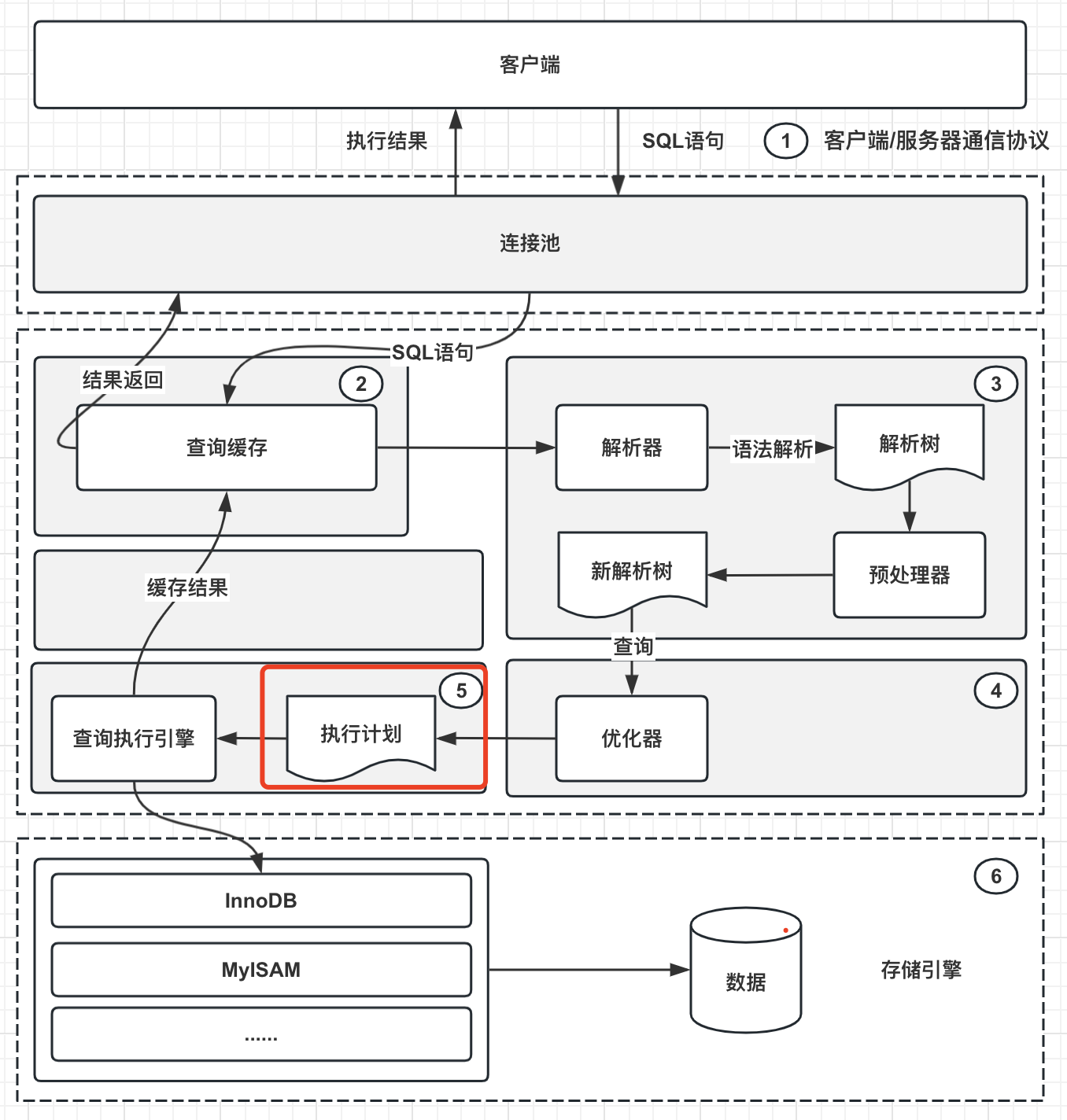
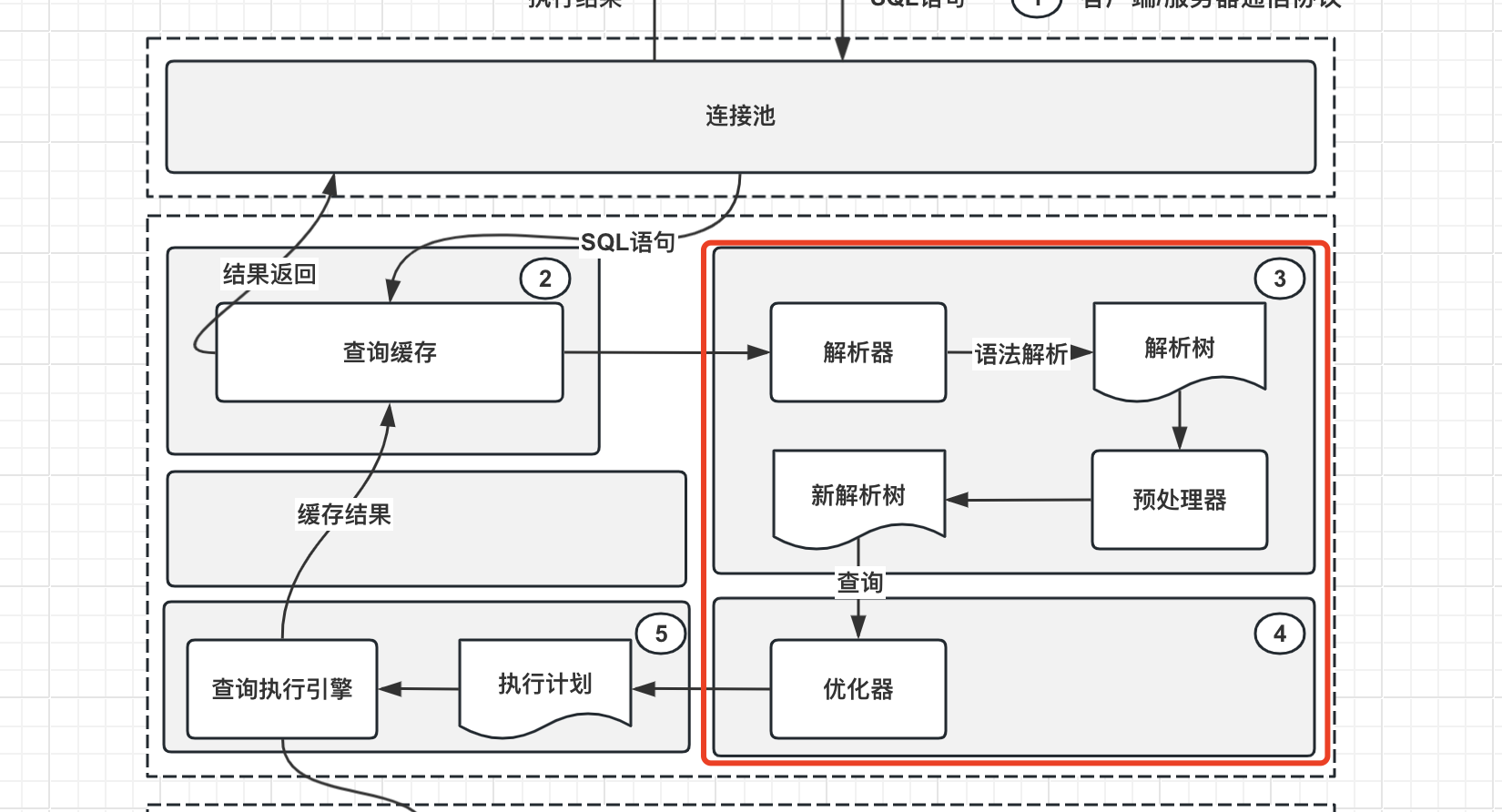
MySQL执行一句SQL主要经过以下几个步骤:
1、客户端同连接池建立通信协议链接。
2、MySQL将传入的SQL放入到查询缓存中执行。
3、若非查询SQL或缓存未命中,则请求解析器进行语法解析并生成语法树。
4、对生成的解析树,MySQL的优化器会再次按照最优路径等方法进行优化。
5、利用优化后的解析树生成执行计划。
6、存储引擎执行相应的执行计划,将查询结果或修改结果返回给用户,至此SQL执行流程结束。
可以看到在第5步,如果能拿到这句SQL的执行计划,那么SQL的执行效率、使用的索引情况就明了了。那么如何获取到SQL的执行计划呢?很简单,在MySQL中,有一个十分重要的关键字"Explain"。这里简单通过一个例子来说明:
explain select * from index_table where a = 1 and b = 20 and c = 0;explain select * from index_table where b = 20 and c = 0;
这里,采用explain关键字对SQL进行分析。可以看到执行完后,结果如下。


上述列所表达的意思简单解释如下:
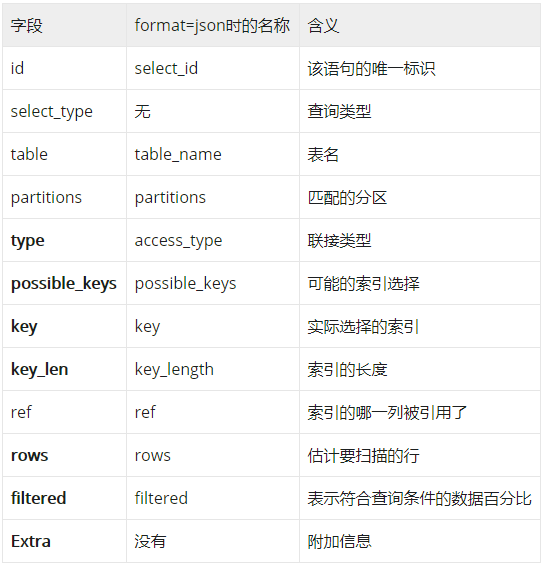
通过"Explain"关键字,可以看到MySQL在执行第一句SQL时是走了索引的,但是第二句SQL是没有走索引的。那么到此,可以知道,MySQL确实是按最左匹配的方式在查询数据的。
最左匹配原理
那么到这里,又有了新的疑问。为什么MySQL选择的是最左匹配的方式呢?这就还得从MySQL自身的索引结构说起。
众所周知,索引的结构种类其实是有很多的,如:哈希索引、二叉树索引、B+树索引等等。MySQL基于检索效率等方面考虑,选择B+树作为自身的索引结构。
这里以前面的数据为例,绘制出了MySQL建立的B+树索引:
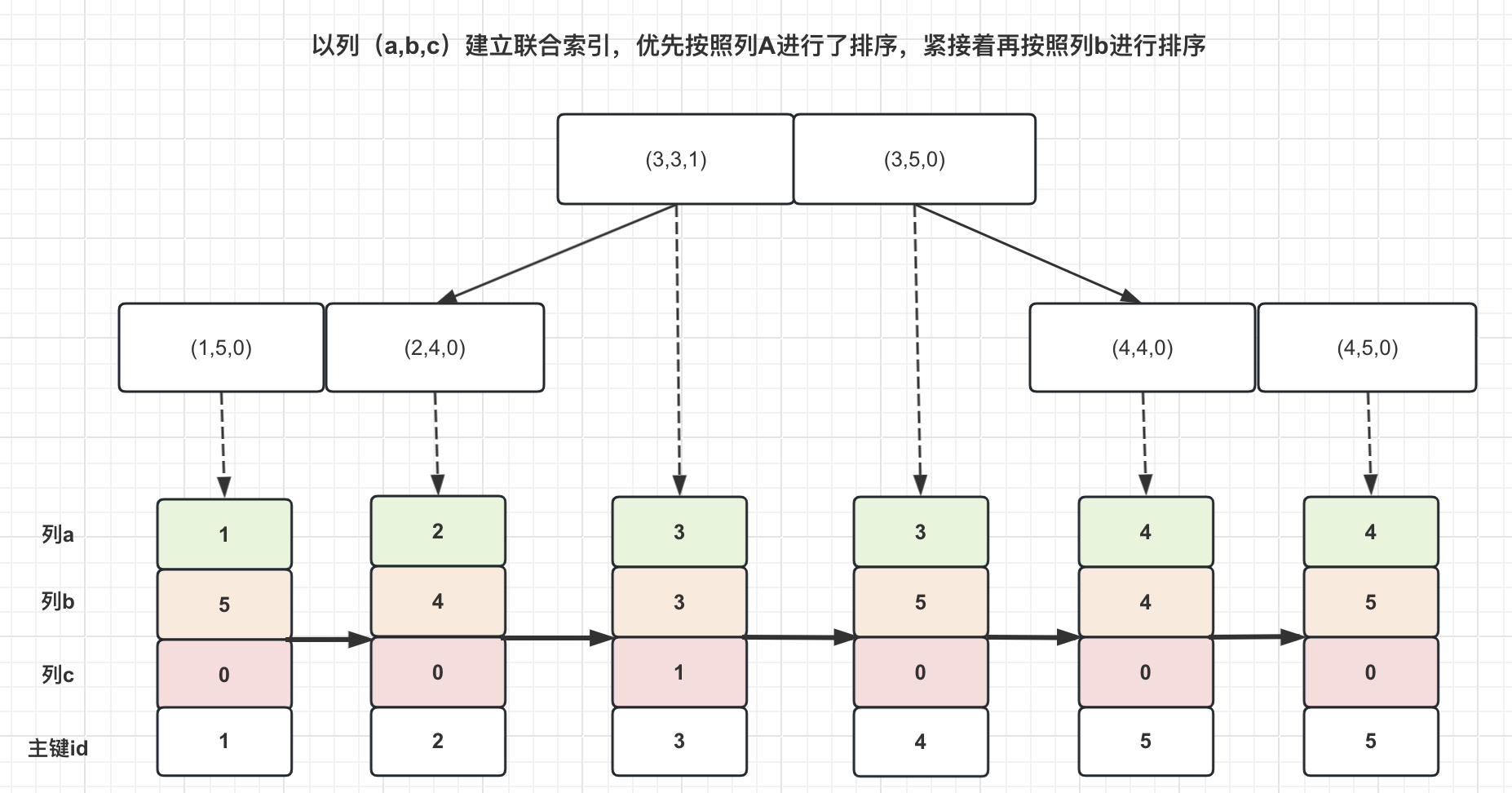
简单来讲,在建立联合索引的时候,MySQL会优先按照索引的左边的第一个字段进行排序。对应到图中,也就是优先按照了列a进行排序。
如果列a相同的情况下,MySQL则按联合索引的第二列b进行排序。聚焦到图中就是(3,3,1)和(3,5,0)这两个数据。它们的列a是相同的,但列b是从小到大排序的。
了解了索引的建立方式,想必你也就明白了为什么是最左匹配了吧?索引本身的顺序是从左到右建立的,因此在搜索的时候,自然也是需要从左到右去匹配生效的。
以刚才SQL为例,**“where a = 1 and b = 20 and c = 0;”**的部分,MySQL会优先选择用a=1搜索索引的位置(因为a已经是排好序的),倘如a=1的数据有多条。那么就会聚焦到b进行搜索,因为列b肯定也是按照顺序排列好的。因此只需要再按照b进行搜索即可。
注意事项
那么聊到这里,可能有些读者就有疑惑了。“那我们以后搜索使用where条件语句的时候,都需要按照索引的方式搜索么?”
答案显然是否定的。依旧以上文提到的(a,b,c)联合索引为例子,具体来说,可以分成如下几种特殊情况:
| 搜索SQL | 使用索引情况 | |
|---|---|---|
| 情况一 | where a=? and c=? and b=? | 正常使用索引 |
| 情况二 | where a=? and c=? | 仅仅对a列使用了索引,c采用索引下推。 |
| 情况三 | where b=? and c=? | 无法使用索引 |
情况一
按照情况一来看,可以看到where的条件并不是完全按照联合索引的顺序建立的,但是联合索引依旧生效了。可能很多人会有疑惑,不是说按照最左匹配才生效吗?回顾到前文中的SQL的执行流程,不难发现在生成SQL的执行计划之前,MySQL的解析器和优化器是会对传入的SQL语句进行解析、优化的。
在这个过程中,MySQL会自动调整where条件中的条件顺序,以便查询能够以最小的成本进行。所以并非是最左匹配的原则失效了,只是MySQL已经自动帮你处理好了这个转变过程,使得你在编程、查询的时候不需要再考虑索引顺序的问题。
情况二
对情况二,a列可以正常采用索引,因为前面已经提到,联合索引是从左到右建立有效序列的,因此a列肯定是可以有序搜索的。但后续并没有b列,因此联合索引就没法再使用了。那么这个时候,MySQL如何进行c列的搜索呢?
这里就不得不提及一个MySQL针对这种情况的优化,这种优化被称为索引下推。这里简单用例子:"select * from index_table where a>0 and c=1*"来解释一下。
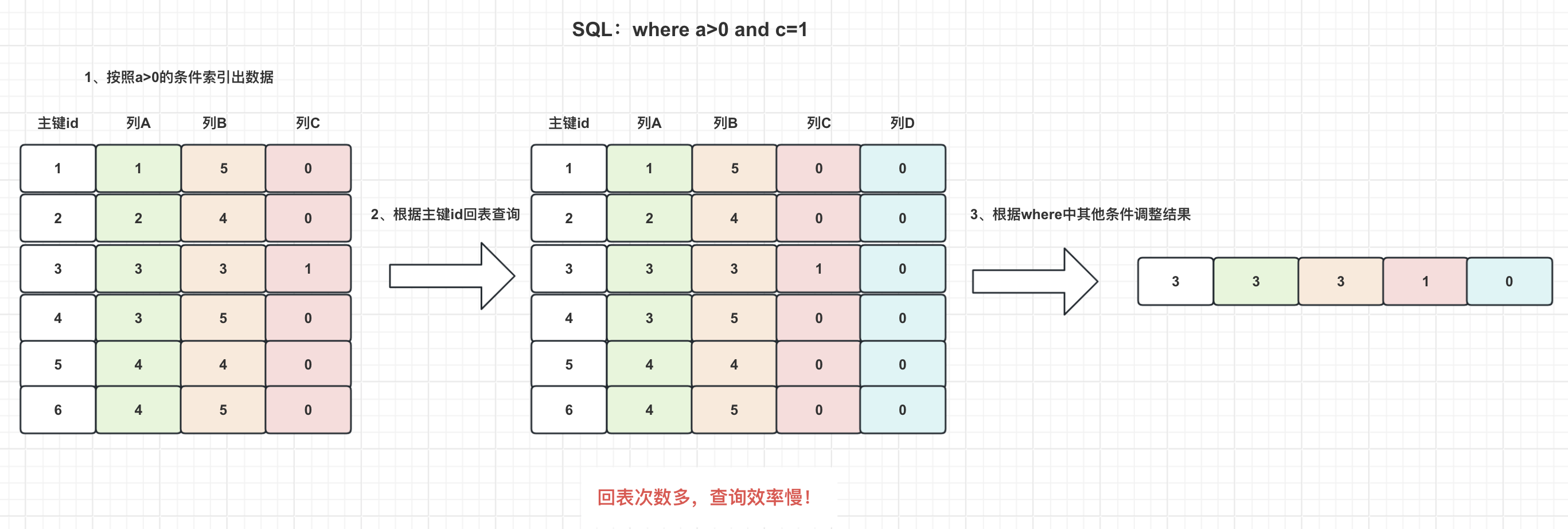
正常来说,在where条件语句中,a>0是可以采用索引的,此时根据这个条件能够获取出一大批数据。根据索引中的这批数据,MySQL会按找id进行回表查询,查询完成后再根据where的其他条件进行筛选。
但是,这种方法会带来很多的不必要回表,以图中为例,在联合索引中,其实保存了c列的数据,只需要根据c列再进行一次判断,就可以筛选出需要回表的数据只有一条,从而就可以大大减少回表的次数,达到优化查询的目的。
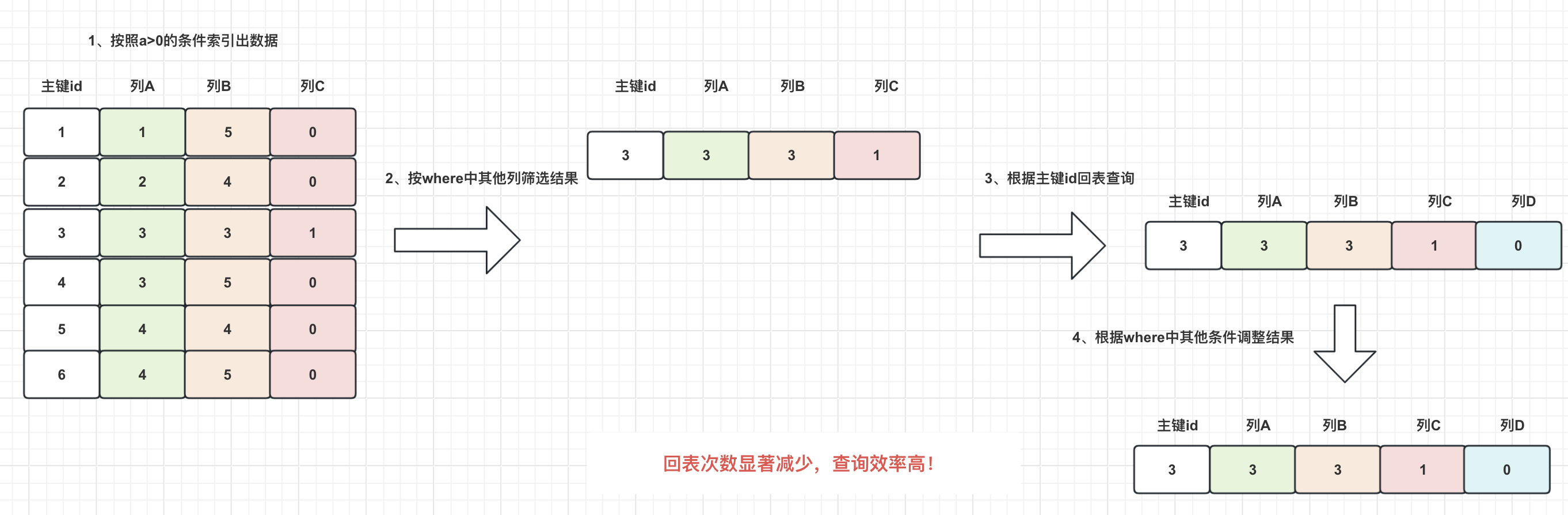
因此,MySQL为了减少回表查询的次数,就针对这种联合索引匹配不上的情况做了优化,就是在已经用联合索引筛选出数据的情况下,再次使用联合索引中的叶子结点数据,来判断where语句中的其余条件是否可以符合。若不符合,则不再对该数据做回表,从而加快数据查询的效率。
情况三
对于情况三,那么由于它没有以a列作为查询的条件,相当于最左侧的列都无法匹配上。那么此时无论MySQL如何处理,都是没法调整顺序使其符合联合索引的,因此只能按照全表搜索的方式,而这也是最慢的搜索情况。
总结
综合这以上三种情况,可以看到,MySQL在查询的时候,会优先用联合索引中最左侧的列进行匹配,并且会想方设法让用户的SQL能够符合联合索引。
这也提示我们,在建立联合索引的时候,联合索引的列查询频率应该是从左到右递减的,由此一来,联合索引才能发挥最大的功效,也尽可能避免出现索引失效的情况。
参考资料
腾讯面试官问我:MySQL索引原理是什么?
MySQL索引,最左前缀匹配的内部原理是什么?
这篇 MySQL 索引和 B+Tree 讲得太通俗易懂
这篇关于【从零到Offer】MySQL最左匹配的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






