本文主要是介绍20240212请问如何将B站下载的软字幕转换成为SRT格式?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20240212请问如何将B站下载的软字幕转换成为SRT格式?
2024/2/12 12:47
百度搜索:字幕 json 转 srt
json srt
https://blog.csdn.net/a_wh_white/article/details/120687363?share_token=2640663e-f468-4737-9b55-73c808f5dcf0
https://blog.csdn.net/a_wh_white/article/details/120687363
【python】实现将json字幕转srt,并将繁体中文翻译为简体中文
走着走着就走神了 已于 2022-04-13 12:55:45 修改
代码(json_to_srt)
import json
import math
import os
file = '' # 这个变量用来保存数据
i = 1
for doc in os.listdir(): # 遍历当前文件夹的所有文件
if (doc[-4:] == 'json'): # 若是json文件则进行处理
name = doc[:-5] # 提取文件名
# 将此处文件位置进行修改,加上utf-8是为了避免处理中文时报错
with open(doc, encoding='utf-8') as f:
datas = json.load(f) # 加载文件数据
f.close()
for data in datas['body']:
start = data['from'] # 获取开始时间
stop = data['to'] # 获取结束时间
content = data['content'] # 获取字幕内容
file += '{}\n'.format(i) # 加入序号
hour = math.floor(start) // 3600
minute = (math.floor(start) - hour * 3600) // 60
sec = math.floor(start) - hour * 3600 - minute * 60
minisec = int(math.modf(start)[0] * 100) # 处理开始时间
file += str(hour).zfill(2) + ':' + str(minute).zfill(2) + ':' + str(sec).zfill(2) + ',' + str(
minisec).zfill(2) # 将数字填充0并按照格式写入
file += ' --> '
hour = math.floor(stop) // 3600
minute = (math.floor(stop) - hour * 3600) // 60
sec = math.floor(stop) - hour * 3600 - minute * 60
minisec = abs(int(math.modf(stop)[0] * 100 - 1)) # 此处减1是为了防止两个字幕同时出现
file += str(hour).zfill(2) + ':' + str(minute).zfill(2) + ':' + str(sec).zfill(2) + ',' + str(
minisec).zfill(2)
file += '\n' + content + '\n\n' # 加入字幕文字
i += 1
with open('./{}.srt'.format(name), 'w', encoding='utf-8') as f:
f.write(file) # 将数据写入文件
f.close()

问题一:
百度:but no encoding declared; see https://python.org/dev/peps/pep-0263/ for deta
SyntaxError: Non-UTF-8 code starting with '\xb1' in file L:\json2srt\json2sr
https://blog.csdn.net/qq_39624528/article/details/86617197
Python常见错误
https://blog.csdn.net/weixin_43865196/article/details/104048879
python错误:but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
操作系统:windows
python版本:3.6版本
解决: 在文章的第一行 加入 :
# coding=gbk
操作系统:windows
python版本:2.7版本
错误原因 : 是 xxx.py文件里有中文字符
改正方法 :文件的第一行 加上
# -*-coding:utf8 -*-
问题二:
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
Traceback (most recent call last):
File "N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json\json2srt.py", line 18, in <module>
start = data['from'] # 获取开始时间
TypeError: string indices must be integers
百度:TypeError: string indices must be integers
https://blog.csdn.net/qq_36746815/article/details/127098919
python错误:TypeError: string indices must be integers
https://blog.csdn.net/hihell/article/details/123370933
Python 错误:TypeError String Indices Must be Integers 【已解决】
https://www.cnblogs.com/jiaoliuxuexi/p/12603090.html
TypeError: string indices must be integers
问题三:
rainlanuit 2022.07.18
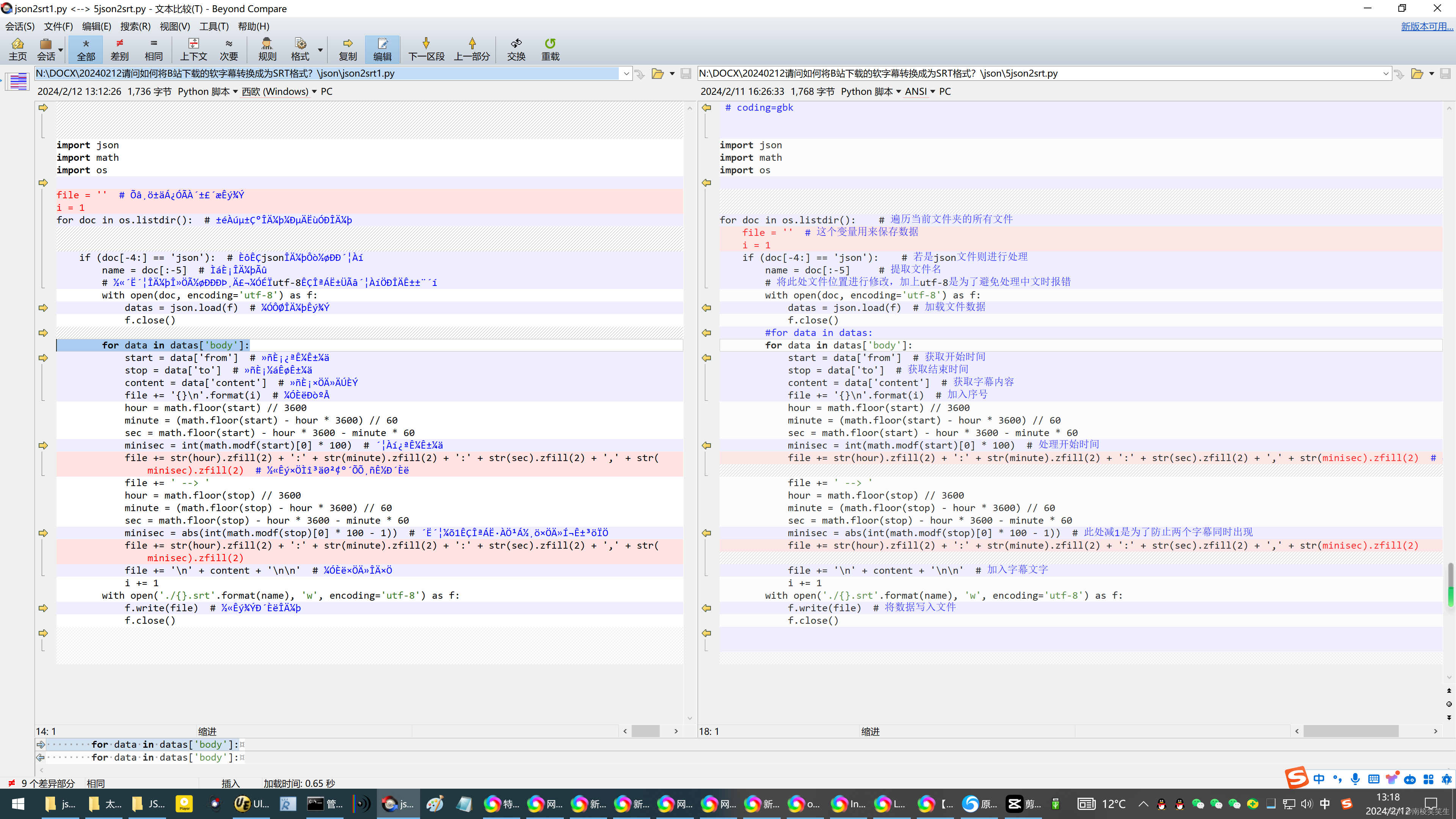
如果用来同时处理多个json文件的话,把第5、6行的两个全局变量放到外层for循环里。不然除了第一个json文件正常,其余全是叠加的。
最终结果:
json2srt.py
# coding=gbk
import json
import math
import os
for doc in os.listdir(): # 遍历当前文件夹的所有文件
file = '' # 这个变量用来保存数据
i = 1
if (doc[-4:] == 'json'): # 若是json文件则进行处理
name = doc[:-5] # 提取文件名
# 将此处文件位置进行修改,加上utf-8是为了避免处理中文时报错
with open(doc, encoding='utf-8') as f:
datas = json.load(f) # 加载文件数据
f.close()
#for data in datas:
for data in datas['body']:
start = data['from'] # 获取开始时间
stop = data['to'] # 获取结束时间
content = data['content'] # 获取字幕内容
file += '{}\n'.format(i) # 加入序号
hour = math.floor(start) // 3600
minute = (math.floor(start) - hour * 3600) // 60
sec = math.floor(start) - hour * 3600 - minute * 60
minisec = int(math.modf(start)[0] * 100) # 处理开始时间
file += str(hour).zfill(2) + ':' + str(minute).zfill(2) + ':' + str(sec).zfill(2) + ',' + str(minisec).zfill(2) # 将数字填充0并按照格式写入
file += ' --> '
hour = math.floor(stop) // 3600
minute = (math.floor(stop) - hour * 3600) // 60
sec = math.floor(stop) - hour * 3600 - minute * 60
minisec = abs(int(math.modf(stop)[0] * 100 - 1)) # 此处减1是为了防止两个字幕同时出现
file += str(hour).zfill(2) + ':' + str(minute).zfill(2) + ':' + str(sec).zfill(2) + ',' + str(minisec).zfill(2)
file += '\n' + content + '\n\n' # 加入字幕文字
i += 1
with open('./{}.srt'.format(name), 'w', encoding='utf-8') as f:
f.write(file) # 将数据写入文件
f.close()

参考资料:
https://blog.csdn.net/mondaiji/article/details/104294430?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163385446816780357213901%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163385446816780357213901&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-104294430.first_rank_v2_pc_rank_v29&utm_term=python%E4%B8%ADjson%E8%BD%ACsrt&spm=1018.2226.3001.4187
https://blog.csdn.net/mondaiji/article/details/104294430
Python实现json字幕转换为srt字幕
百度:b站自动生成字幕怎么下载
https://www.bilibili.com/read/cv19103155/?jump_opus=1
2022年10月15日 08:45-[2021]B站CC字幕下载的两种姿势(超超超超超简单)
2022年10月15日 08:45 6537浏览 · 41喜欢 · 15评论
视频地址: [2021]B站CC字幕下载的两种姿势(超超超超超简单)
重庆梁平扩展现实大学
粉丝:182文章:118
Microsoft Windows [版本 10.0.19045.2311]
(c) Microsoft Corporation。保留所有权利。
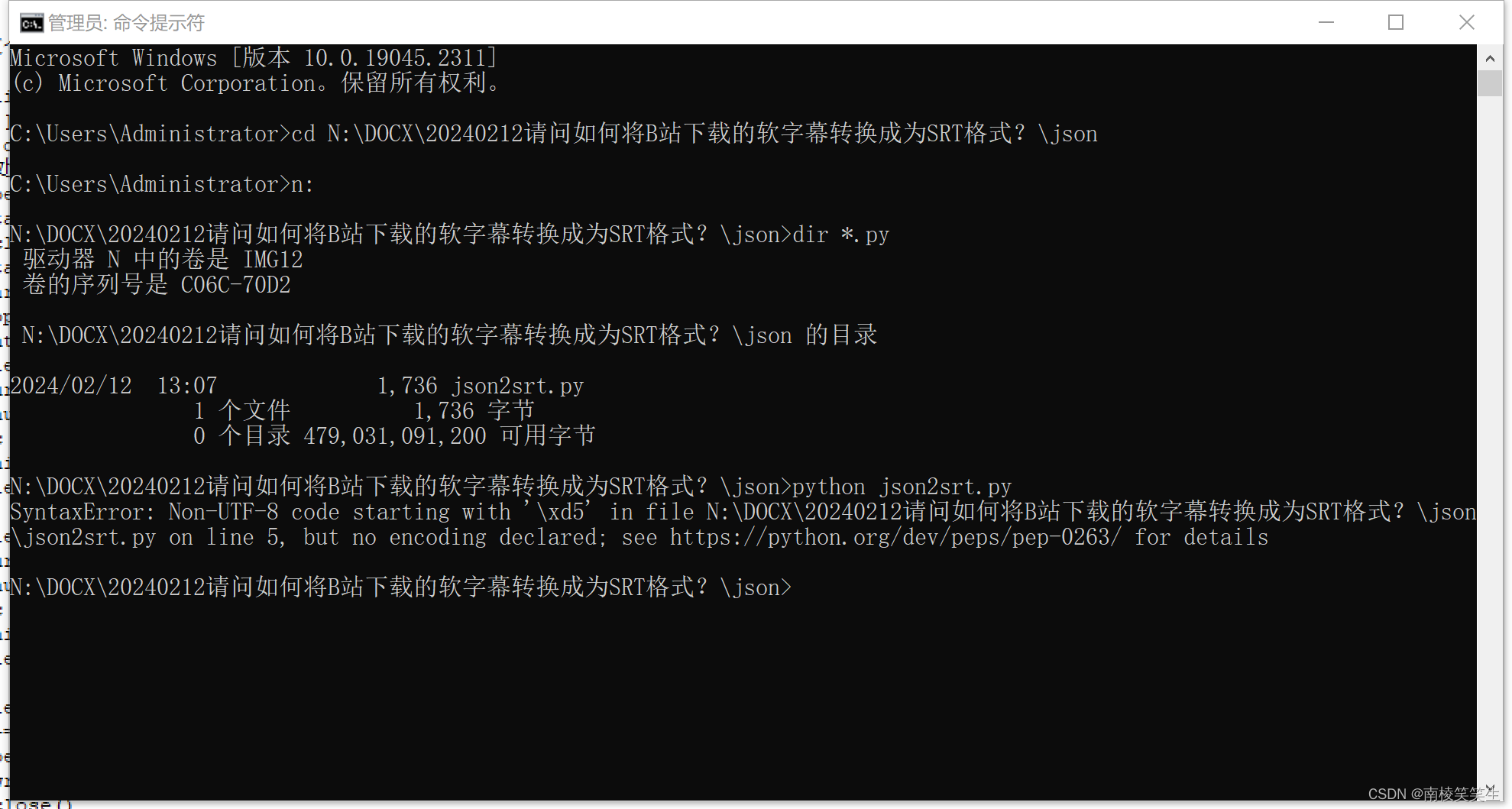
C:\Users\Administrator>cd N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json
C:\Users\Administrator>n:
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>dir *.py
驱动器 N 中的卷是 IMG12
卷的序列号是 C06C-70D2
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json 的目录
2024/02/12 13:07 1,736 json2srt.py
1 个文件 1,736 字节
0 个目录 479,031,091,200 可用字节
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
SyntaxError: Non-UTF-8 code starting with '\xd5' in file N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json\json2srt.py on line 5, but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>
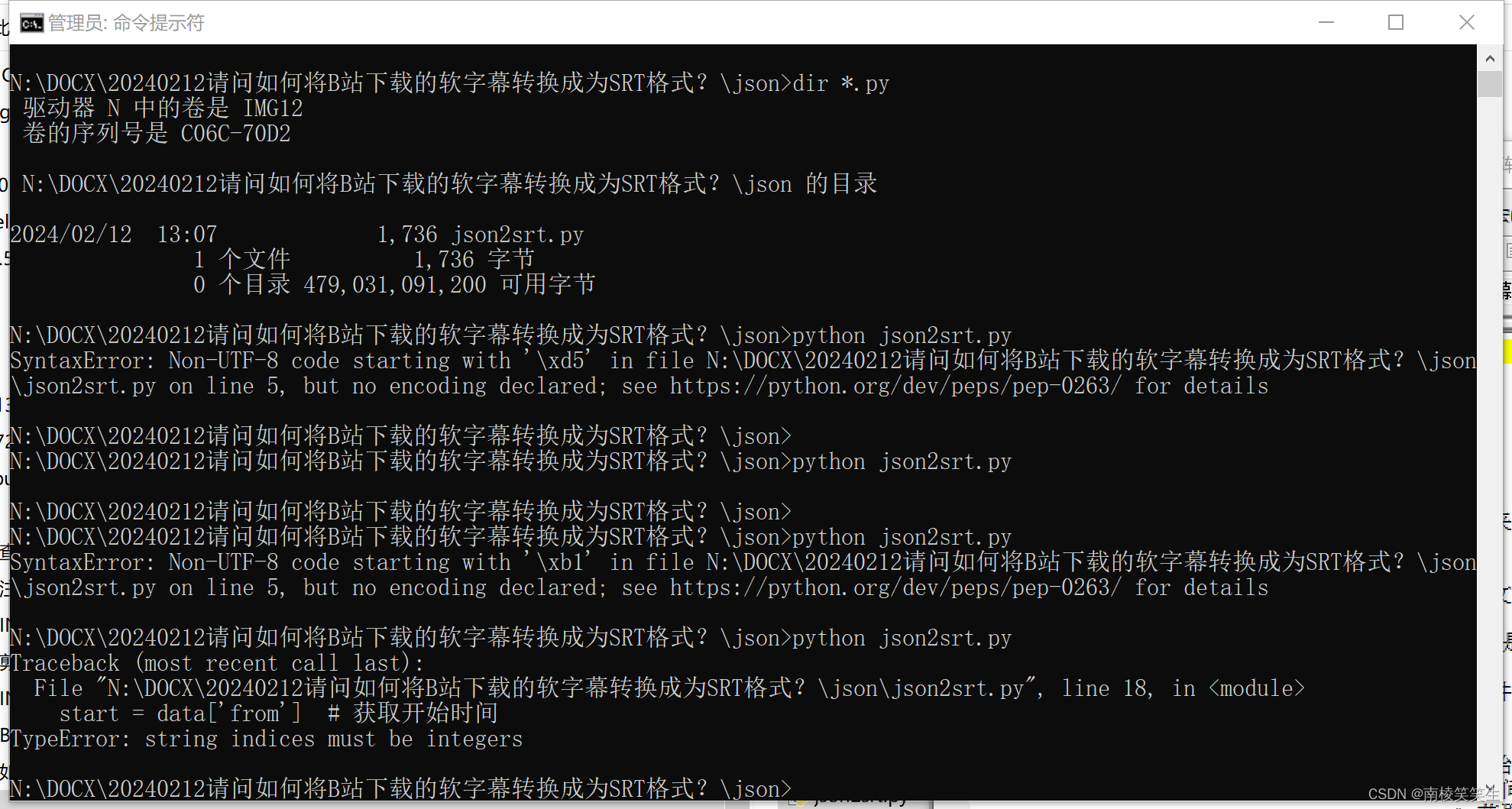
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
SyntaxError: Non-UTF-8 code starting with '\xb1' in file N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json\json2srt.py on line 5, but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
Traceback (most recent call last):
File "N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json\json2srt.py", line 18, in <module>
start = data['from'] # 获取开始时间
TypeError: string indices must be integers
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>python json2srt.py
N:\DOCX\20240212请问如何将B站下载的软字幕转换成为SRT格式?\json>
这篇关于20240212请问如何将B站下载的软字幕转换成为SRT格式?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






