本文主要是介绍配置Hadoop伪分布模式时,SecondoryNamenode启动不了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
配置Hadoop伪分布模式时,Secondorynamenode启动不了,可是日志文件没有报错,被这个问题困扰好多天了,求大佬指点一二!
一、运行结果截图
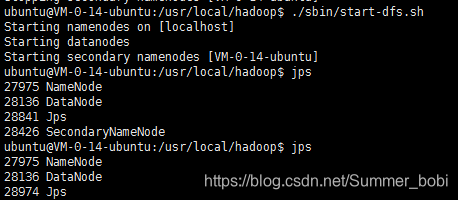
很奇怪的是,先开始jps时,显示了SecondoryNamenode的进程,第二次却没有了。
二、这是Secondorynamenode的日志文件(没看出来有错误的地方)
2019-04-12 21:32:45,103 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2019-04-12 21:32:50,288 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-04-12 21:32:50,940 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2019-04-12 21:32:50,941 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: SecondaryNameNode metrics system started
2019-04-12 21:32:55,638 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Edit logging is async:true
2019-04-12 21:32:55,788 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /usr/local/hadoop/tmp/dfs/namesecondary/in_use.lock acquired by nodename 28426@localhost.localdomain
2019-04-12 21:32:55,896 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: KeyProvider: null
2019-04-12 21:32:55,897 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsLock is fair: true
2019-04-12 21:32:55,922 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2019-04-12 21:32:55,922 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsOwner = ubuntu (auth:SIMPLE)
2019-04-12 21:32:55,922 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: supergroup = supergroup
2019-04-12 21:32:55,922 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: isPermissionEnabled = true
2019-04-12 21:32:55,922 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: HA Enabled: false
2019-04-12 21:32:56,214 INFO org.apache.hadoop.hdfs.server.common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2019-04-12 21:32:56,285 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2019-04-12 21:32:56,285 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2019-04-12 21:32:56,315 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2019-04-12 21:32:56,321 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: The block deletion will start around 2019 Apr 12 21:32:56
2019-04-12 21:32:56,327 INFO org.apache.hadoop.util.GSet: Computing capacity for map BlocksMap
2019-04-12 21:32:56,327 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2019-04-12 21:32:56,329 INFO org.apache.hadoop.util.GSet: 2.0% max memory 454.4 MB = 9.1 MB
2019-04-12 21:32:56,329 INFO org.apache.hadoop.util.GSet: capacity = 2^20 = 1048576 entries
2019-04-12 21:32:56,376 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: dfs.block.access.token.enable = false
2019-04-12 21:32:56,457 INFO org.apache.hadoop.conf.Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2019-04-12 21:32:56,474 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2019-04-12 21:32:56,474 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2019-04-12 21:32:56,474 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2019-04-12 21:32:56,493 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: defaultReplication = 1
2019-04-12 21:32:56,493 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxReplication = 512
2019-04-12 21:32:56,493 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: minReplication = 1
2019-04-12 21:32:56,493 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxReplicationStreams = 2
2019-04-12 21:32:56,494 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2019-04-12 21:32:56,494 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: encryptDataTransfer = false
2019-04-12 21:32:56,494 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2019-04-12 21:32:57,340 INFO org.apache.hadoop.util.GSet: Computing capacity for map INodeMap
2019-04-12 21:32:57,340 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2019-04-12 21:32:57,340 INFO org.apache.hadoop.util.GSet: 1.0% max memory 454.4 MB = 4.5 MB
2019-04-12 21:32:57,340 INFO org.apache.hadoop.util.GSet: capacity = 2^19 = 524288 entries
2019-04-12 21:32:57,351 INFO org.apache.hadoop.hdfs.server.namenode.FSDirectory: ACLs enabled? false
2019-04-12 21:32:57,351 INFO org.apache.hadoop.hdfs.server.namenode.FSDirectory: POSIX ACL inheritance enabled? true
2019-04-12 21:32:57,351 INFO org.apache.hadoop.hdfs.server.namenode.FSDirectory: XAttrs enabled? true
2019-04-12 21:32:57,351 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Caching file names occurring more than 10 times
2019-04-12 21:32:57,406 INFO org.apache.hadoop.hdfs.server.namenode.snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2019-04-12 21:32:57,436 INFO org.apache.hadoop.hdfs.server.namenode.snapshot.SnapshotManager: SkipList is disabled
2019-04-12 21:32:57,495 INFO org.apache.hadoop.util.GSet: Computing capacity for map cachedBlocks
2019-04-12 21:32:57,495 INFO org.apache.hadoop.util.GSet: VM type = 64-bit
2019-04-12 21:32:57,496 INFO org.apache.hadoop.util.GSet: 0.25% max memory 454.4 MB = 1.1 MB
2019-04-12 21:32:57,496 INFO org.apache.hadoop.util.GSet: capacity = 2^17 = 131072 entries
2019-04-12 21:32:57,611 INFO org.apache.hadoop.hdfs.server.namenode.top.metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2019-04-12 21:32:57,611 INFO org.apache.hadoop.hdfs.server.namenode.top.metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2019-04-12 21:32:57,611 INFO org.apache.hadoop.hdfs.server.namenode.top.metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2019-04-12 21:32:57,711 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Checkpoint Period :3600 secs (60 min)
2019-04-12 21:32:57,711 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Log Size Trigger :1000000 txns
2019-04-12 21:32:57,742 INFO org.apache.hadoop.hdfs.DFSUtil: Starting Web-server for secondary at: http://0.0.0.0:9868
2019-04-12 21:32:58,037 INFO org.eclipse.jetty.util.log: Logging initialized @17365ms
2
这篇关于配置Hadoop伪分布模式时,SecondoryNamenode启动不了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





