本文主要是介绍本地连接hdfs操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
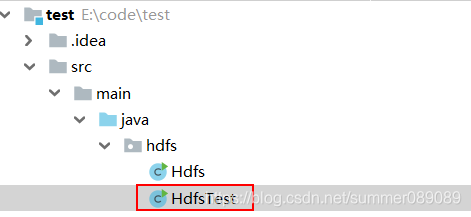
1.java代码,结构如下入
注意:cdh环境hdfs端口是8020,hadoop环境hdfs端口是9000
1.pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>tcl.java</groupId><artifactId>test</artifactId><version>1.0-SNAPSHOT</version><dependencies><!--hadoop核心jar包--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency><!--hadoop之上传文件,文件夹到hdfs,从hdfs中下载文件,文件夹所依赖的jar包--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.2</version></dependency><!--控制打印日志等级的jar包--><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency></dependencies></project>
2.log4j日志等级设置
#志输出级别为INFO,输出到stdout
log4j.rootLogger=INFO, stdout
#org.apache.log4j.ConsoleAppender(控制台)
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
#org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
#org.apache.log4j.FileAppender(文件)
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
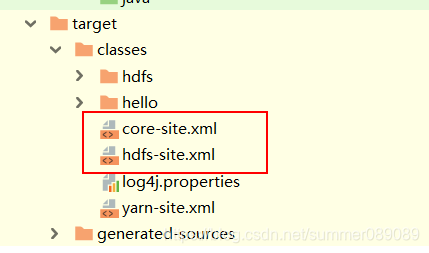
3.将core-site.xml和hdfs-site.xml放入resources中。不论CDH集群还是原生hadoop集群都有这个文件,编译后在target目录下生产才算生效。
3. 测试类
作用:读取/test目录下的文件
package hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;public class HdfsTest {public static void main(String[] args) throws Exception {test1();}//kerberospublic static void test1() throws Exception{Configuration conf = new Configuration();//这里设置namenodeconf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");conf.set("dfs.nameservices", "nameservice1");conf.set("fs.defaultFS", "hdfs://nameservice1");FileSystem fileSystem1 = FileSystem.get(conf);System.out.println("===contains1===");//测试访问情况Path path=new Path("/test");System.out.println("===contains2===");if(fileSystem1.exists(path)){System.out.println("===contains3===");}System.out.println("===contains4===");RemoteIterator<LocatedFileStatus> list=fileSystem1.listFiles(path,true);while (list.hasNext()){LocatedFileStatus fileStatus=list.next();System.out.println(fileStatus.getPath());}}
}2.如果报错Could not locate executable null\bin\winutils.exe in the Hadoop binaries
参考文章:https://blog.csdn.net/hr786250678/article/details/89702671
没有克服不了的困难,只有畏惧的心。 生活之所以耀眼,是因为磨难与辉煌会同时出现。所以,别畏惧暂时的困顿,即使无人鼓掌,也要全情投入,优雅坚持。请相信:不管多险峻的高山,总会给勇敢的人留一条攀登的路。只要你肯迈步,路就会在你脚下延伸。
这篇关于本地连接hdfs操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



