本文主要是介绍平均负载(load average)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现象
今天在生产上遇到了平均负载很高,但是CPU使用率不高的问题。事情的经过是这样的,系统的目录会存临时文件,本来有定时任务会去清理,但是试运行期间关掉了五分钟执行一次的定时任务,导致该目录积累了大量的文件,有几十个G。该目录使用率升高后报警,打开了定时清理文件的任务。如下图
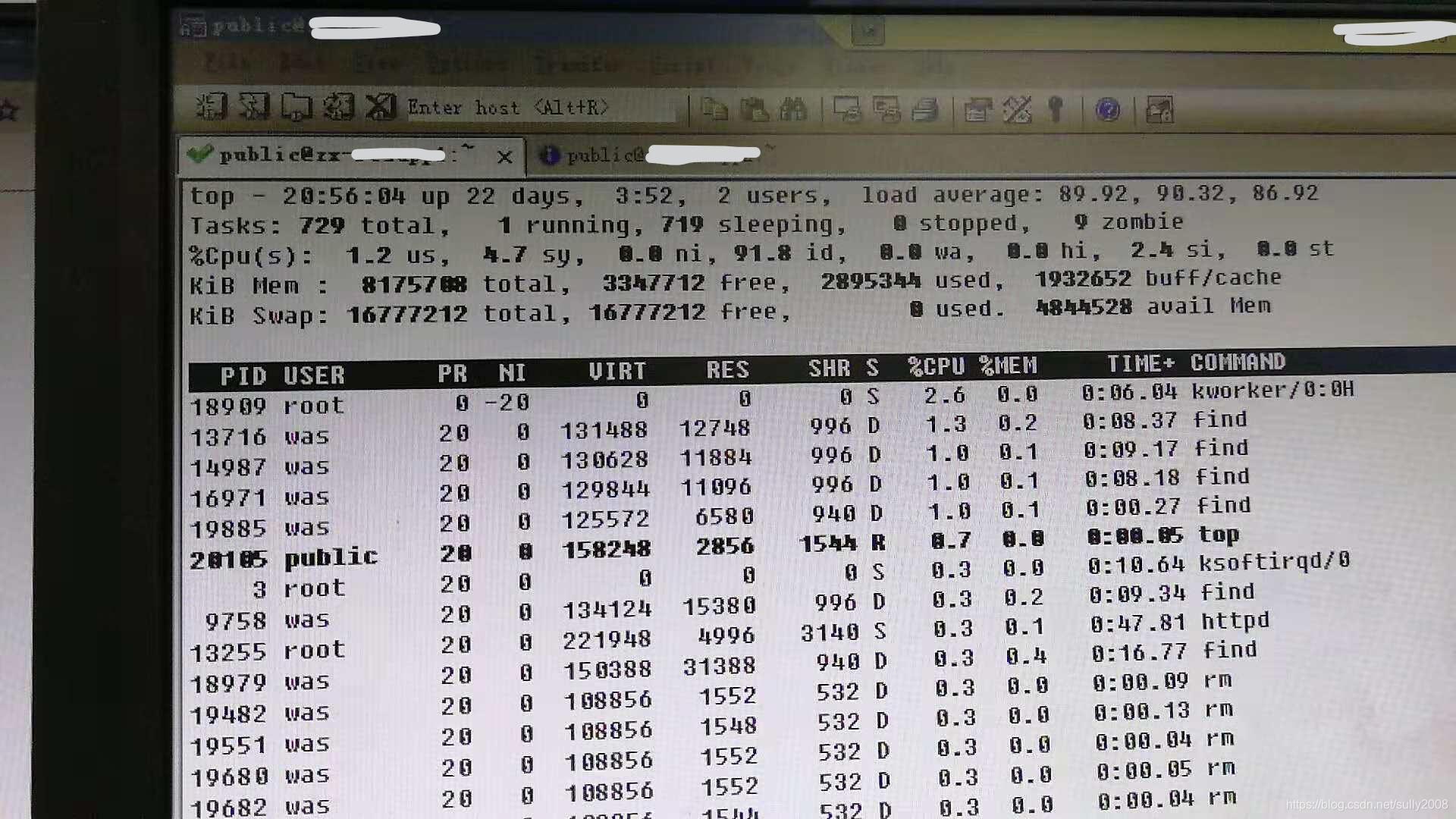
图一 平均负载
图二 删除进程较多
如上图一所示,CPU使用率不高,但是服务器负载奇高。
上图二所示,rm -f进程较多,同时find进程也很多(只是没截图)
原因是这样的,
1.清理脚本先使用“find -mtime =10”查找十分钟前的文件,然后使用“rm -f”删除
2.由于目录的文件数巨大,find和rm都非常耗时,导致五分钟一次的脚本中的查找和删除进越积越多
3.进程数随着时间的推移,越来越多;find检索和rm都耗费CPU较少,所以CPU使用率不高;由于find和rm进程较多,所以平均负载奇高
当find进程向磁盘读数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载定义
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
可运行状态的进程
所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
因此,你可以简单理解为,平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。这个“指数衰减平均”的详细含义你不用计较,这只是系统的一种更快速的计算方式,你把它直接当成活跃进程数的平均值也没问题。
当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的。
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高。
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
这篇关于平均负载(load average)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




