本文主要是介绍【自动化运维新手村】删库跑路第一步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【摘要】
到目前为止,自动化运维新手村中已经讲解了Python的基本数据类型及其操作,并且将其应用于一个简易的CMDB场景下;除此之外还介绍了一个主流的Web框架——Flask,并且本着最小上手范围的原则,已经可以通过向后端API发起请求的方式,对CMDB进行增删改查,而且还有了更为健壮的异常处理和更为安全的认证鉴权。
但有一个比较重要的内容始终没有提,这也是在后续的自动化运维中一定会用到的知识,那就是数据库。今天的章节,就对我们的后端应用进行改造,不管是用户信息还是CMDB信息,一律不再通过文件进行存储,而是使用关系型数据库来实现数据的读写。
【数据库】
数据库其实可以笼统的理解为可以支撑大批量数据进行存取的应用程序。
数据本身又分为关系型数据和非关系型数据,比如后端应用的用户信息,都具有用户名,密码,角色等信息,所以它们都是属于结构相同的关系型数据,但现在为止,我们CMDB的数据就属于非关系型数据,因为并没有强制的规定每台设备应该具有什么字段,而是通过一个json来实现灵活的信息读写。
那与之对应的数据库也就分为关系型数据库和非关系型数据库,这两者之间存在着比较大的差异,因为它们在底层实现上需要根据关系型数据或非关系型数据来做出不同的性能优化,实现更快的数据读写性能。但这两种数据库并不存在优劣之分,只存在适用的场景不同之分。
大家经常听到的MySQL、Oracle就属于关系型数据库,而Mongo、Redis就属于非关系数据库。
我们这一章节就使用MySQL来作为数据库提供数据的存取能力,但并不会十分深入的讲解关系型数据库的底层原理以及各种范式,这些如果有必要的话会在番外篇中提到。
【MySQL】
简介
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点如下:
1.数据以二维表格的形式出现
2.许多的行和列组成一张表单
3.若干的表单组成database
比如我们的CMDB的数据结构如下:
{"Beijing": {"idc": "Beijing","switch": {"10.0.0.1": {"ip": "10.0.0.1","role": "csw","port": ["Eth1/1/0", "Eth1/1/1"]}}}
}
之所以一开始将数据结构定义成非关系型最主要的一个原因是为了匹配讲解Python的几大基本数据类型。但作为设备资产数据,其实大多数时候它们的字段都是已经固定的,所以这一章节就将非关系型数据“打平”,将其转为关系型数据,如下:
[["10.0.0.1", "Beijing", "R01", "C01", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-01", "CSW"],["10.0.0.2", "Beijing", "R01", "C02", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-02", "CSW"],["10.0.0.3", "Beijing", "R01", "C03", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-03", "CSW"],
]
显而易见上面的数据是一个二维数组,即二维表格,那么他按理说就是可以存在MySQL里的,但在存进去之前需要先创建一个表结构,这个表结构包含了,这一张二维表中有几列,每一列的名称,数据类型,数据长度,默认值,注释等等信息,只有定义出一个表结构后,数据才能有存放的“容器”。
表结构操作
安装和连接MySQL的过程,省略不提。
其实MySQL的常用的操作并不多,无非是对表结构的增删改查(DDL),和对表数据的增删改查(DML)。
创建一个数据库的SQL语句:
CREATE DATABASE python_ops;
使用一个数据库的SQL语句:
USE python_ops;
创建设备表的SQL语句:
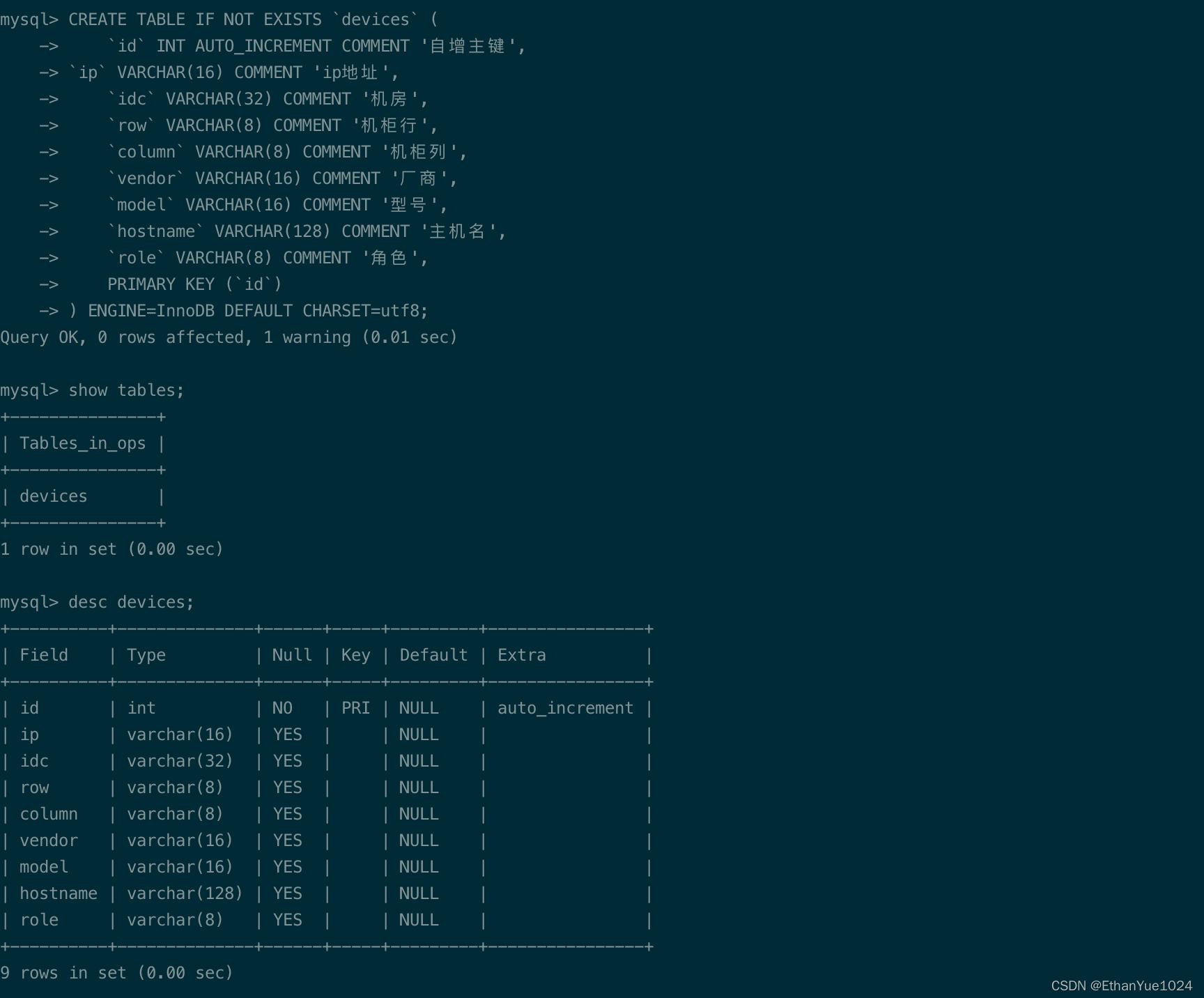
CREATE TABLE IF NOT EXISTS `devices` (`id` INT AUTO_INCREMENT COMMENT '自增主键',`ip` VARCHAR(16) COMMENT 'ip地址',`idc` VARCHAR(32) COMMENT '机房',`row` VARCHAR(8) COMMENT '机柜行',`column` VARCHAR(8) COMMENT '机柜列',`vendor` VARCHAR(16) COMMENT '厂商',`model` VARCHAR(16) COMMENT '型号',`hostname` VARCHAR(128) COMMENT '主机名',`role` VARCHAR(8) COMMENT '角色',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
关于表结构中的字段,有很多数据类型,较为常用的有 VARCHAR、INT、TEXT、TIMESTAMP、DATETIME、具体的使用会在用到的时候再进行具体讲解。
创建好后查看表结构的SQL语句如下:
SHOW TABLES;
DESC devices;
表数据操作
通过desc查看的只是表的结构,目前devices表中仍然没有数据。
SELECT * FROM devices; 查询devices表的SQL语句

INSERT INTO devices (`ip`, `idc`, `row`, `column`, `vendor`, `model`, `hostname`, `role`) VALUES
("10.0.0.1", "Beijing", "R01", "C01", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-01", "CSW"),
("10.0.0.2", "Beijing", "R01", "C02", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-02", "CSW"),
("10.0.0.3", "Beijing", "R01", "C03", "Cisco", "Nexus9000", "BJ-R01-C01-N9K-00-00-03", "CSW");

有一个需要注意的地方就是SQL语句中关于数据库名,表名,字段名在使用时最好加上反引号,这样可以避免与数据库内置的关键字冲突。
【总结】
这一章节主要对数据库的基本概念做了一个简介,也是我们使用Web应用与数据库交互的前置条件,下一章节便会开始讲解如何使用Flask框架完成数据的增删改查。
【篇后语】
可能部分有基础的朋友对Flask或者Django有一定的了解,这些Web框架会提供一些封装好的方法,通过代码中定义数据模型,来自动创建表结构。但我并不推荐这种方式,我觉得单从运维的角度来说,应该有一个理念,那就是不该存在任何黑盒操作,很明显通过一条指定就直接建好表结构这就属于黑盒操作,对于一些还没有数据库基础的朋友来说,虽然短时间内可以按照流程走通,长期来看绝对是弊大于利。
一键式的操作存在的意义,一是可以让已经完全熟悉原理的人节省重复的步骤,提高效率;二是可以让完全不懂的人不必在意底层实现进行无脑操作。但对于还处在正在学习自动化运维阶段的朋友来说,一定要有一个想法就是坚决不做第二种人。我一直提倡的理念最小上手范围,是指学习并运用有限但必要的知识来解决面对的场景,并不提倡在知识匮乏的情况下,通过一些奇技淫巧来一步登天。
这篇关于【自动化运维新手村】删库跑路第一步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






