本文主要是介绍2023(cpvr+顶刊)三维重建论文汇总(持续更新),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2023cpvr三维重建论文汇总(仅作为学习记录)
2023三维重建方向论文总结
【1】SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction(SparseFusion:用于三维重建的提取视图条件扩散)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhou_SparseFusion_Distilling_View-Conditioned_Diffusion_for_3D_Reconstruction_CVPR_2023_paper.pdf
代码链接:https://sparsefusion.github.io/
摘要:SparseFusion,这是一种稀疏视图三维重建方法,结合了神经渲染和概率图像生成的最新进展。现有的方法通常建立在具有重新投影特征的神经渲染上,但无法生成看不见的区域或在大的视点变化下处理不确定性。替代方法将其视为(概率)2D合成任务,虽然它们可以生成看似合理的2D图像,但它们不能推断出一致的底层3D。然而,我们发现3D一致性和概率图像生成之间的这种权衡不需要存在。事实上,我们证明了几何一致性和生成推理在模式寻求行为中是互补的。通过从视图条件的潜在扩散模型中提取3D一致的场景表示,我们能够恢复一个看似合理的3D表示,其渲染既准确又逼真。我们在CO3D数据集中的51个类别中评估了我们的方法。

图一:SparseFusion,这是一种在给定几个(例如只有两个)具有已知相对姿态的分割输入图像的情况下进行3D重建的方法。SparseFusion能够生成3D一致的神经场景表示,使我们能够渲染新的视图并提取底层几何体,同时能够在不确定或未观察到的区域(例如,消防栓前面、泰迪熊的脸、笔记本电脑后面或玩具车左侧)生成详细而合理的结构。
【2】RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation(RenderDiffusion:用于三维重建、修复和生成的图像扩散)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Anciukevicius_RenderDiffusion_Image_Diffusion_for_3D_Reconstruction_Inpainting_and_Generation_CVPR_2023_paper.pdf
代码链接:https://github.com/Anciukevicius/RenderDiffusion
摘要:扩散模型目前在有条件和无条件图像生成方面都实现了最先进的性能。然而,到目前为止,图像扩散模型不支持3D理解所需的任务,例如视图一致的3D生成或单视图对象重建。在本文中,我们提出了RenderDiffusion,这是第一个用于3D生成和推理的扩散模型,仅使用单目2D监督进行训练。我们方法的核心是一种新颖的图像去噪架构,该架构在每个去噪步骤中生成并渲染场景的中间三维表示。这在扩散过程中加强了强归纳结构,提供了3D一致的表示,同时只需要2D监督。生成的三维表示可以从任何视图进行渲染。我们在FFHQ、AFHQ、ShapeNet和CLEVR数据集上评估了RenderDiffusion,显示了在生成3D场景和从2D图像推断3D场景方面的竞争性能。
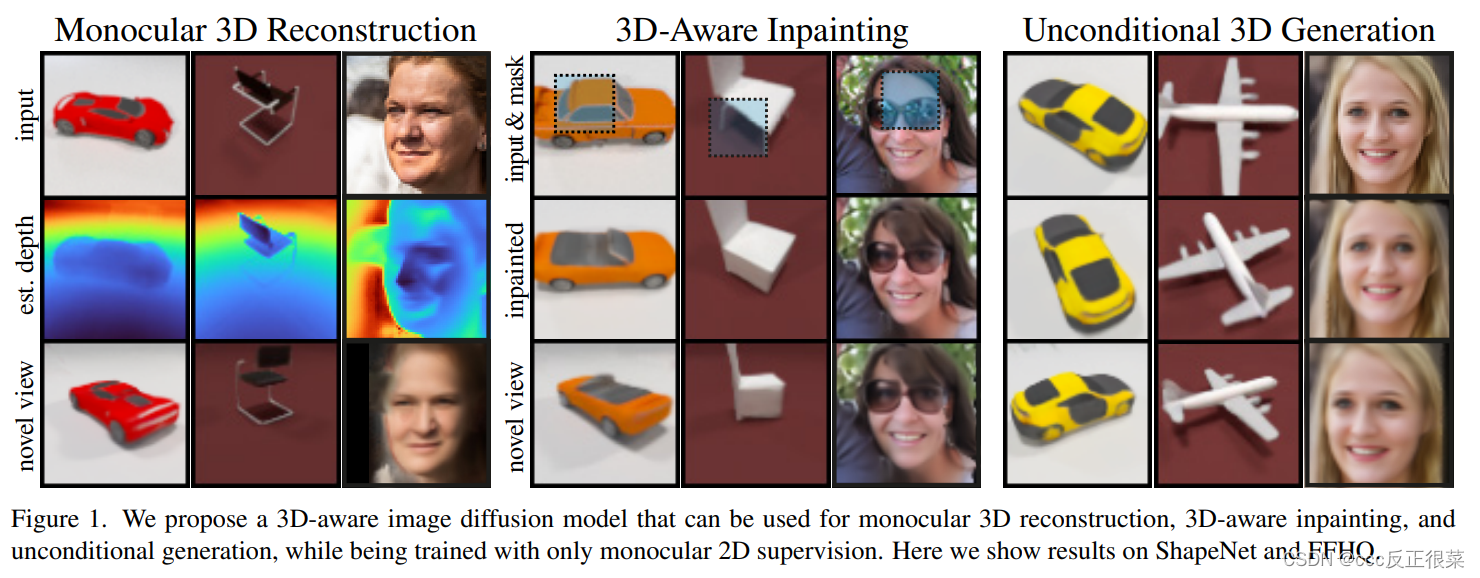 图一:我们提出了一种3D感知图像扩散模型,该模型可用于单目3D重建、3D感知修复和无条件生成,同时仅在单目2D监督下进行训练。在这里,我们展示了ShapeNet和FFHQ的结果。
图一:我们提出了一种3D感知图像扩散模型,该模型可用于单目3D重建、3D感知修复和无条件生成,同时仅在单目2D监督下进行训练。在这里,我们展示了ShapeNet和FFHQ的结果。
【3】Multiview Compressive Coding for 3D Reconstruction(用于三维重建的多视图压缩编码)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Wu_Multiview_Compressive_Coding_for_3D_Reconstruction_CVPR_2023_paper.pdf
代码链接:https://github.com/facebookresearch/MCC
摘要:视觉识别的中心目标是从单个图像中理解物体和场景。由于大规模学习和通用表示,二维识别已经取得了巨大的进步。相比之下,3D由于图像中未描绘的遮挡而带来了新的挑战。先前的工作试图通过从多个视图推断或依赖稀缺的CAD模型和特定类别的先验来克服这些问题,这些先验阻碍了向新设置的缩放。在这项工作中,我们通过学习受自监督学习进步启发的可推广表示来探索单视图三维重建。我们介绍了一个简单的框架,该框架对单个对象或整个场景的3D点进行操作,并结合来自不同RGB-D视频的类别不可知的大规模训练。我们的模型,多视图压缩编码(MCC),通过查询3D感知解码器来学习压缩输入外观和几何结构,以预测3D结构。MCC的通用性和效率使其能够从大规模和多样化的数据源中学习,并对DALL·E 2想象的或用iPhone在野外捕捉的新对象具有很强的泛化能力。

【4】ALTO: Alternating Latent Topologies for Implicit 3D Reconstruction(ALTO:用于隐式三维重构的交替潜在拓扑)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Wang_ALTO_Alternating_Latent_Topologies_for_Implicit_3D_Reconstruction_CVPR_2023_paper.pdf
项目链接:代码未公开
摘要:这项工作介绍了交替潜在拓扑(ALTO),用于从噪声点云中高保真重建隐式三维表面。先前的工作表明,潜在编码的空间排列对于恢复细节很重要。一种思想流派是为每个点编码一个潜在向量(点潜伏)。另一个学派是将点延迟投影到网格中(网格延迟),该网格可以是体素网格或三平面网格。每一种思想流派都有取舍。网格延迟是粗糙的,并且丢失了高频细节。相比之下,点延迟保留了细节。然而,点延迟更难解码为曲面,并且质量和运行时间会受到影响。在本文中,我们建议ALTO在几何表示之间顺序交替,然后收敛到易于解码的潜在表示我们发现,这保留了空间表现力,并使解码变得轻量级。我们在隐式3D恢复上验证了ALTO,并观察到不仅与最先进的技术相比性能有所提高,而且运行时间也提高了3-10倍。

【5】Evaluation of 3D Reconstruction for Cultural Heritage Applications(文化遗产三维重建应用评价)
论文链接:https://openaccess.thecvf.com/content/ICCV2023W/e-Heritage/papers/Llull_Evaluation_of_3D_Reconstruction_for_Cultural_Heritage_Applications_ICCVW_2023_paper.pdf
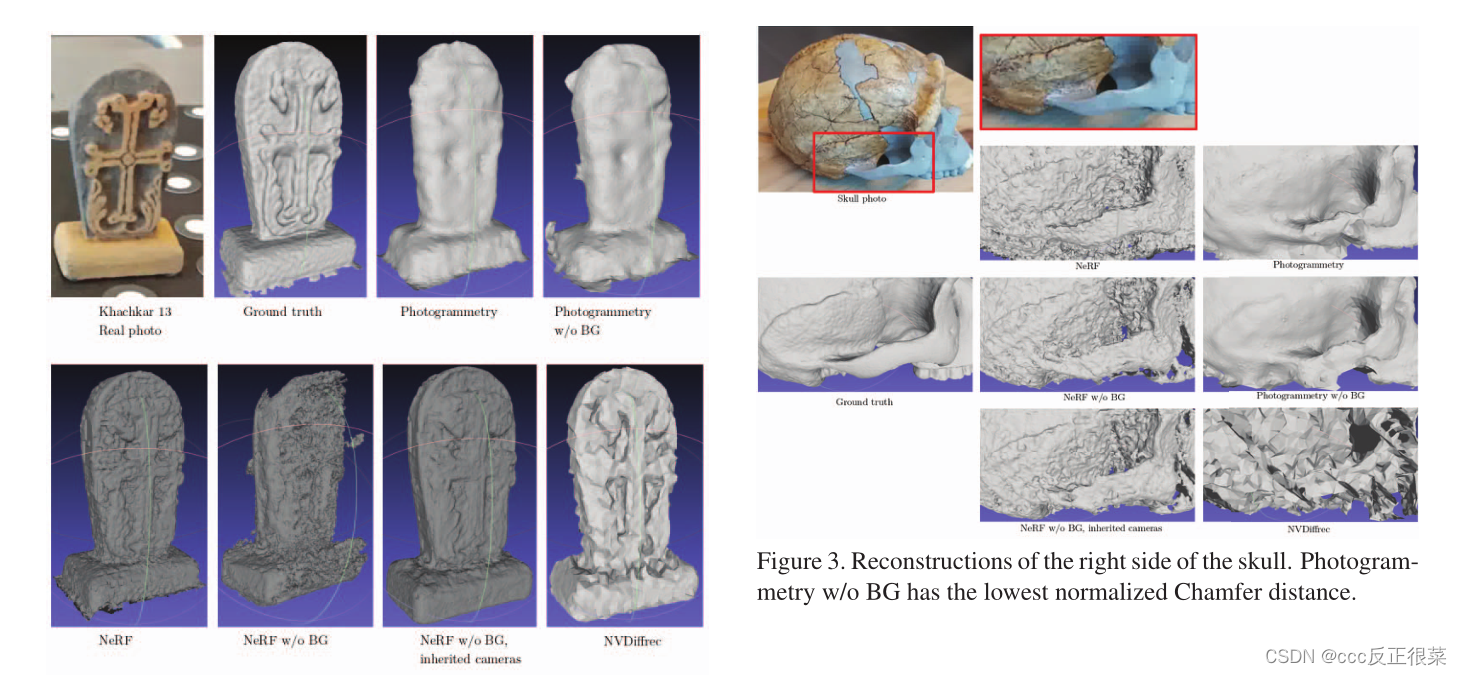
摘要:近年来,我们看到了使用照片创建物体的3D数字复制品的方法的出现。这些技术,特别是与智能手机等手持视频设备相结合时,在医学、博物馆学、力学和考古等各个领域都有重要应用。然而,以前的工作往往缺乏对所产生的模型质量的客观评估。为了解决这一问题,本文重点对重建方法进行了系统评价。本文研究了倒角距离的原理和应用,特别是平均值、前向和后向变量,用于评估不同方法(摄影测量、NeRF和NVDiffrec)产生的重建。我们还探讨了背景滤波对重建的影响。比较的基本事实是用结构光扫描仪获得的重建,这被认为是当前技术的最佳重建。结果表明,重建方法的综合评估需要考虑多种措施,因为它们提供了有关重建质量不同方面的信息。通过利用切角距离并与地面实况进行比较,我们强调了在分析不同重建方法的性能时评估各个方面的重要性。
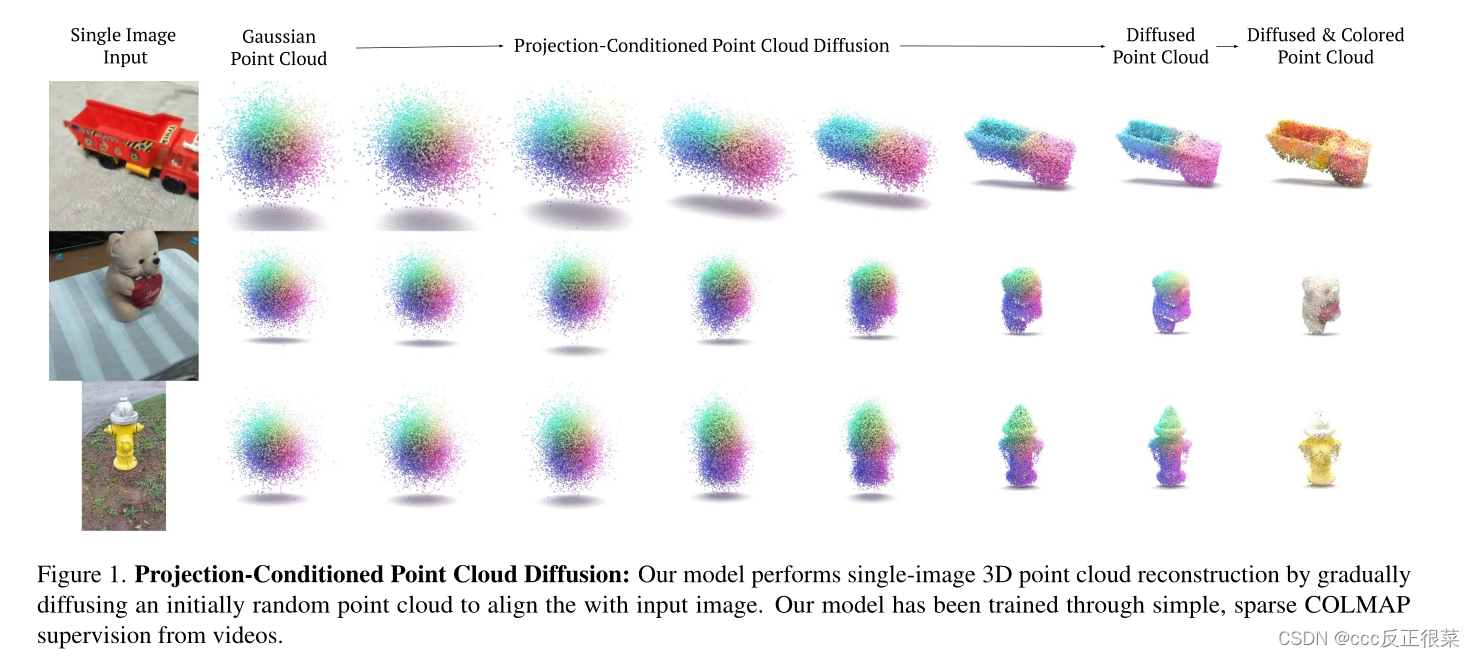
【6】PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction(PC2:用于单图像三维重建的投影条件点云扩散)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Melas-Kyriazi_PC2_Projection-Conditioned_Point_Cloud_Diffusion_for_Single-Image_3D_Reconstruction_CVPR_2023_paper.pdf
代码链接:https://github.com/lukemelas/projection-conditioned-point-cloud-diffusion
摘要:从单个RGB图像重建物体的3D形状是计算机视觉中长期存在的问题。在本文中,我们提出了一种新的单图像三维重建方法,该方法通过条件去噪扩散过程生成稀疏点云。我们的方法将单个RGB图像及其相机姿态作为输入,并将一组3D点逐渐降噪为对象的形状,这些3D点的位置最初是从三维高斯分布中随机采样的。我们方法的关键是一个几何一致的条件处理过程,我们称之为投影条件处理:在扩散过程的每一步,我们都会从给定的相机姿态将局部图像特征投影到部分去噪的点云上。这种投影条件处理过程使我们能够生成与输入图像良好对齐的高分辨率稀疏几何体,并且可以额外用于预测形状重建后的点颜色。此外,由于扩散过程的概率性质,我们的方法自然能够生成与单个输入图像一致的多个不同形状。与之前的工作相比,我们的方法不仅在合成基准上表现良好,而且在复杂的真实世界数据上也有很大的质量改进。
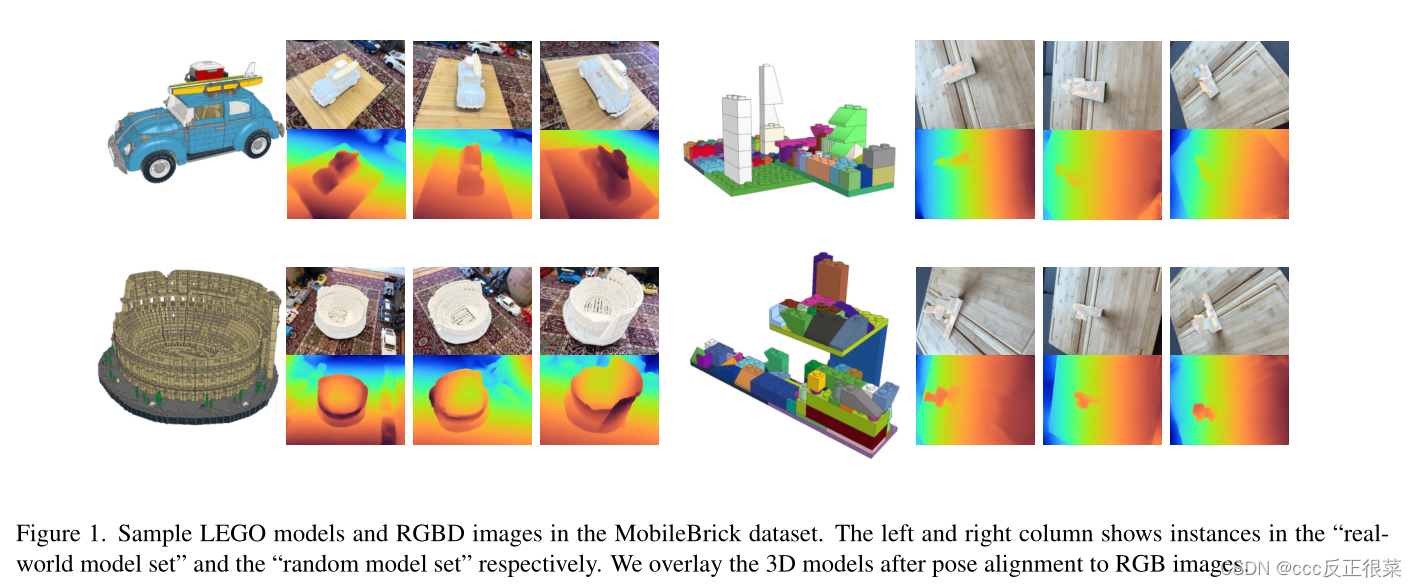
【7】MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices(MobileBrick:在移动设备上构建乐高3D重建)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Li_MobileBrick_Building_LEGO_for_3D_Reconstruction_on_Mobile_Devices_CVPR_2023_paper.pdf
摘要:高质量的3D地面实况形状对于3D对象重建评估至关重要。然而,在现实中很难创建对象的复制品,即使是由3D扫描仪生成的3D重建也会产生伪影,从而导致评估中的偏差。为了解决这个问题,我们介绍了一种使用移动设备捕获的新的多视图RGBD数据集,该数据集包括153个具有不同3D结构的对象模型的高精度3D地面实况注释。我们利用具有已知几何形状的乐高模型作为图像捕获的3D结构,在不依赖高端3D扫描仪的情况下获得精确的3D地面真实形状。移动设备上捕获的高分辨率RGB图像和低分辨率深度图提供的独特数据模式,与精确的3D几何标注相结合,为未来高保真3D重建研究提供了独特的机会。此外,我们在所提出的数据集上评估了一系列三维重建算法。
【8】PAniC-3D: Stylized Single-view 3D Reconstruction from Portraits of Anime Characters(PAniC-3D:动画人物肖像的风格化单视图三维重建)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Chen_PAniC-3D_Stylized_Single-View_3D_Reconstruction_From_Portraits_of_Anime_Characters_CVPR_2023_paper.pdf
摘要:我们提出了PAniC-3D,这是一个直接从(ani)me(c)个角色的(p)个肖像重建风格化的3D角色头部的系统。我们的动漫风格领域对单视图重建提出了独特的挑战;与自然的人头图像相比,人物肖像插图的头发和配饰具有更复杂多样的几何形状,并用非真实感的轮廓线进行了着色。此外,缺乏适合训练和评估这种模糊的风格化重建任务的3D模型和肖像插图数据。面对这些挑战,我们提出的PAniC-3D架构通过线填充模型跨越了插图到3D领域的空白,并用体积辐射场表示复杂的几何形状。我们用两个新的大型数据集(11.2k Vroid 3D模型,1k Vtuber肖像插图)训练我们的系统,并在一个新的AnimeRecon插图对3D对基准上进行评估。PAniC-3D显著优于基线方法,并为从肖像插图中建立风格化重建任务提供了数据。
 图一:我们的(A)PAniC-3D系统能够直接从基于线条的肖像插图中重建3D辐射场。我们收集了一个新的(B)Vtuber插图数据集和(C)Vroid 3D模型数据集,以跨越插图渲染领域的空白并监督重建。为了进行评估,我们提供了一个新的(D)AnimeRecon配对插图和3D模型基准,建立了动画角色风格化单视图重建的新颖任务。(补充中的艺术归属)
图一:我们的(A)PAniC-3D系统能够直接从基于线条的肖像插图中重建3D辐射场。我们收集了一个新的(B)Vtuber插图数据集和(C)Vroid 3D模型数据集,以跨越插图渲染领域的空白并监督重建。为了进行评估,我们提供了一个新的(D)AnimeRecon配对插图和3D模型基准,建立了动画角色风格化单视图重建的新颖任务。(补充中的艺术归属)
【9】Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments(高效的静态和动态三维重建、流式传输和可视化大规模环境下多客户端实时远程呈现的场景部件)
论文链接:https://openaccess.thecvf.com/content/ICCV2023W/CV4Metaverse/papers/Van_Holland_Efficient_3D_Reconstruction_Streaming_and_Visualization_of_Static_and_Dynamic_ICCVW_2023_paper.pdf
*摘要:*尽管远程呈现系统取得了令人印象深刻的进展,对于具有静态和动态场景实体的房间级场景,将其功能扩展到具有更大超过几个平方米的固定尺寸的动态环境仍然具有挑战性。在这篇论文中,我们的目标是在超过房间规模的大型环境中分享3D实时远程呈现体验,具有静态和动态场景实体,仅基于轻量级场景的带宽要求,使用单个移动的消费级RGB-D相机进行拍摄。
为此,我们提出了一种基于静态内容的基于体素的场景表示的组合的新型混合体积场景表示的系统,该系统不仅存储重建的表面几何形状,还包含关于对象语义及其随时间累积的动态移动的信息,以及用于动态场景部分的基于点云的表示,其中基于为输入帧提取的语义和实例信息来实现与静态部分的相应分离。通过对静态和动态内容进行独立但同时的流式传输,我们将潜在的移动但当前静态的场景实体无缝集成在静态模型中,直到它们再次变得动态,以及在远程客户端融合静态和动态数据,我们的系统能够以接近实时的速率实现基于VR的实时远程呈现。我们的评估证明了我们的新方法在视觉质量、性能和相关设计选择的消融研究方面的潜力。
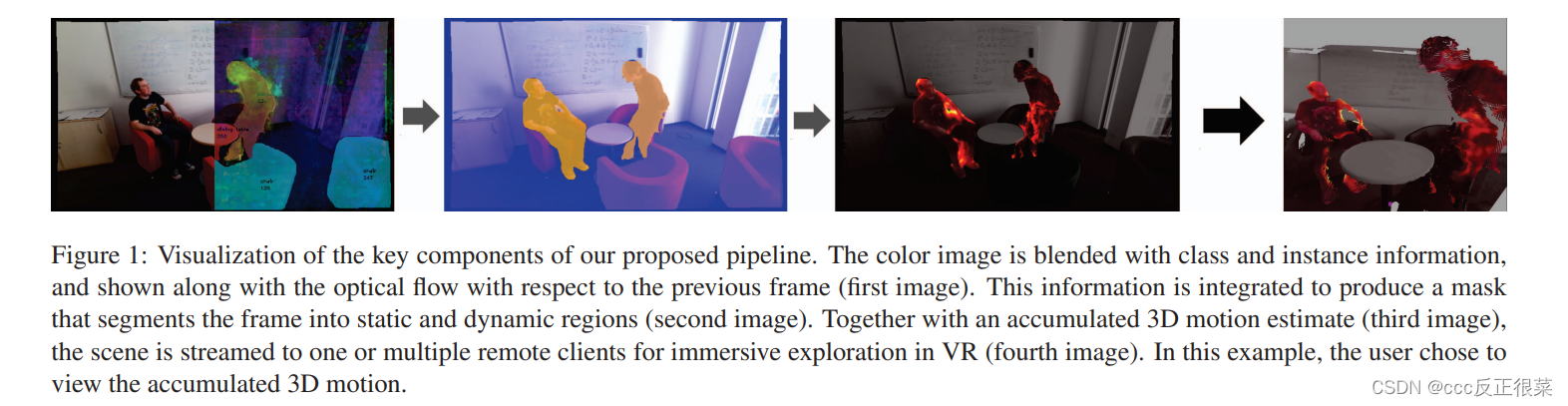
【10】Multi-sensor large-scale dataset for multi-view 3D reconstruction(用于多视图三维重建的多传感器大规模数据集)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Voynov_Multi-Sensor_Large-Scale_Dataset_for_Multi-View_3D_Reconstruction_CVPR_2023_paper.pdf
项目链接:https://skoltech3d.appliedai.tech/
*摘要:*我们提出了一种用于多视图三维表面重建的新的多传感器数据集。它包括来自不同分辨率和模式的传感器的注册RGB和深度数据:智能手机、英特尔RealSense、微软Kinect、工业相机和结构光扫描仪。选择场景是为了强调对现有算法具有挑战性的一组不同的材料特性。我们提供了在14种照明条件下从100个观看方向获取的107个不同场景的约140万张图像。我们希望我们的数据集将有助于评估和训练三维重建算法以及相关任务。

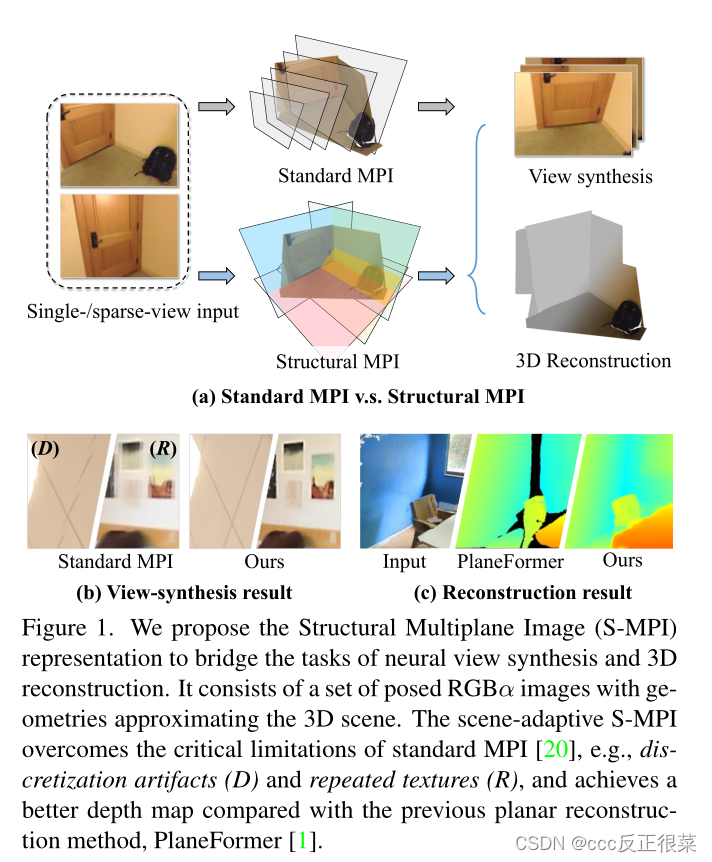
【11】Structural Multiplane Image: Bridging Neural View Synthesis and 3D Reconstruction(结构多平面图像:桥接神经视图合成和三维重建·)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhang_Structural_Multiplane_Image_Bridging_Neural_View_Synthesis_and_3D_Reconstruction_CVPR_2023_paper.pdf
摘要:多平面图像(MPI)包含一组前平行RGBα层,是从稀疏输入进行视图合成的有效表示。然而,它的固定结构限制了性能,尤其是对于以斜角成像的表面。我们介绍了结构MPI(SMPI),其中平面结构简明地近似于3D场景。S-MPI通过几何忠实的结构传递RGBα上下文,直接连接视图合成和3D重建。它不仅可以克服MPI的关键局限性,即斜面离散化伪影和冗余层的滥用,还可以获得平面三维重建。尽管应用S-MPI具有直观性和要求,但仍面临着巨大的挑战,例如,RGBα层和平面姿态的高保真近似、多视图一致性、非平面区域建模以及使用相交平面的高效渲染。因此,我们提出了一种基于分段模型[4]的基于变压器的网络。它预测了紧凑且富有表现力的S-MPI层及其相应的遮罩、姿势和RGBα上下文。在我们的统一框架中,非平面区域被视为一种特殊情况进行包容性处理。通过共享全局代理嵌入来确保多视图的一致性,全局代理嵌入对覆盖具有对齐坐标的完整3D场景的平面级特征进行编码。大量实验表明,我们的方法优于以前最先进的基于MPI的视图合成方法和平面重建方法。
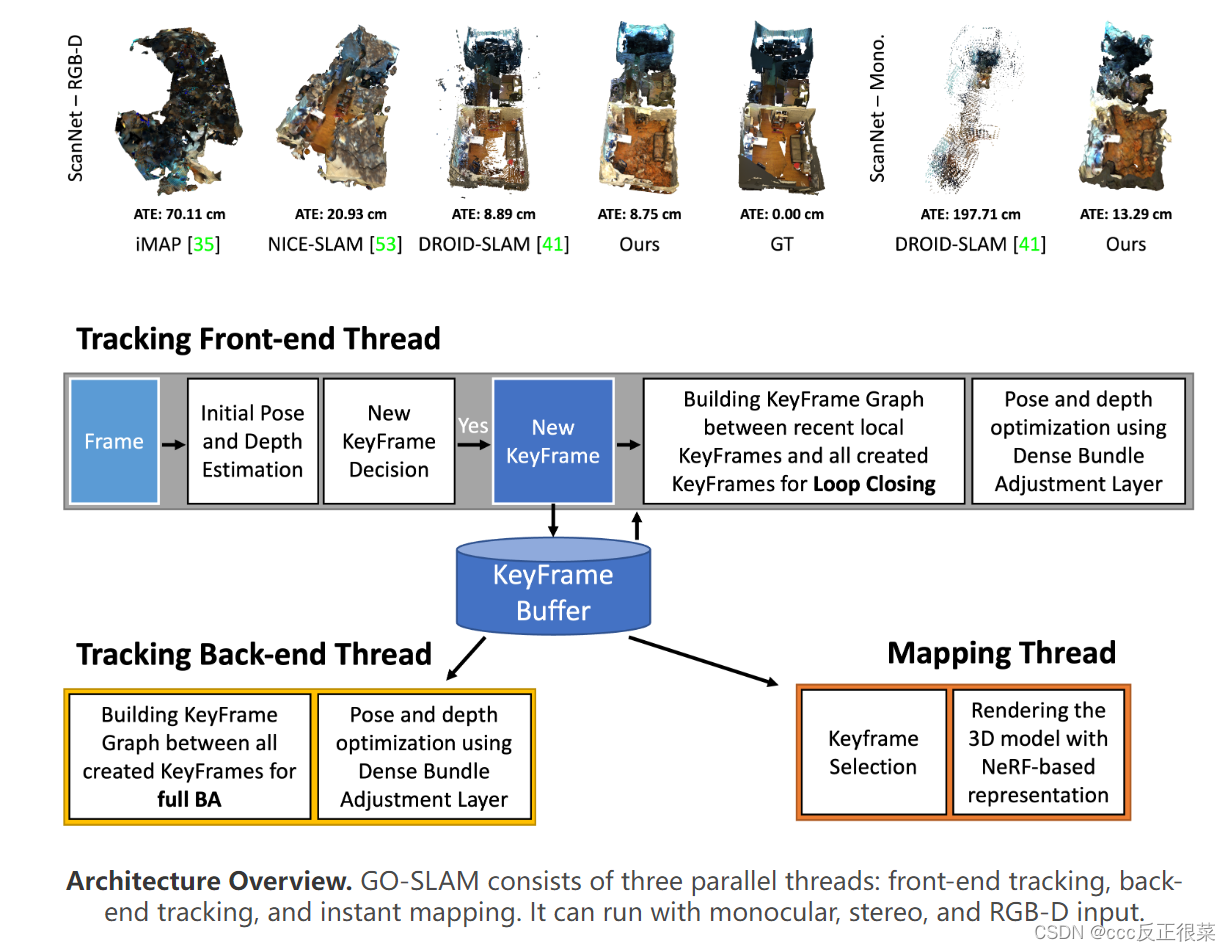
【12】GO-SLAM: Global Optimization for Consistent 3D Instant Reconstruction(GO-SLAM:一致三维即时重建的全局优化)
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_GO-SLAM_Global_Optimization_for_Consistent_3D_Instant_Reconstruction_ICCV_2023_paper.pdf
代码链接:https://github.com/youmi-zym/GO-SLAM
摘要:最近,神经隐式表示在密集同时定位和映射(SLAM)方面取得了令人信服的结果,但在相机跟踪和重建中存在误差积累和失真。有目的地,我们提出了GO-SLAM,这是一个基于深度学习的密集视觉SLAM框架,用于实时全局优化姿态和三维重建。鲁棒姿态估计是其核心,由有效的闭环和在线全束调整支持,通过利用输入帧完整历史的学习全局几何来优化每帧。同时,我们动态更新隐式和连续曲面表示,以确保三维重建的全局一致性。在各种合成和真实世界数据集上的结果表明,GO-SLAM在跟踪鲁棒性和重建精度方面优于现有技术。此外,GO-SLAM是通用的,可以与单眼、立体声和RGB-D输入一起运行。
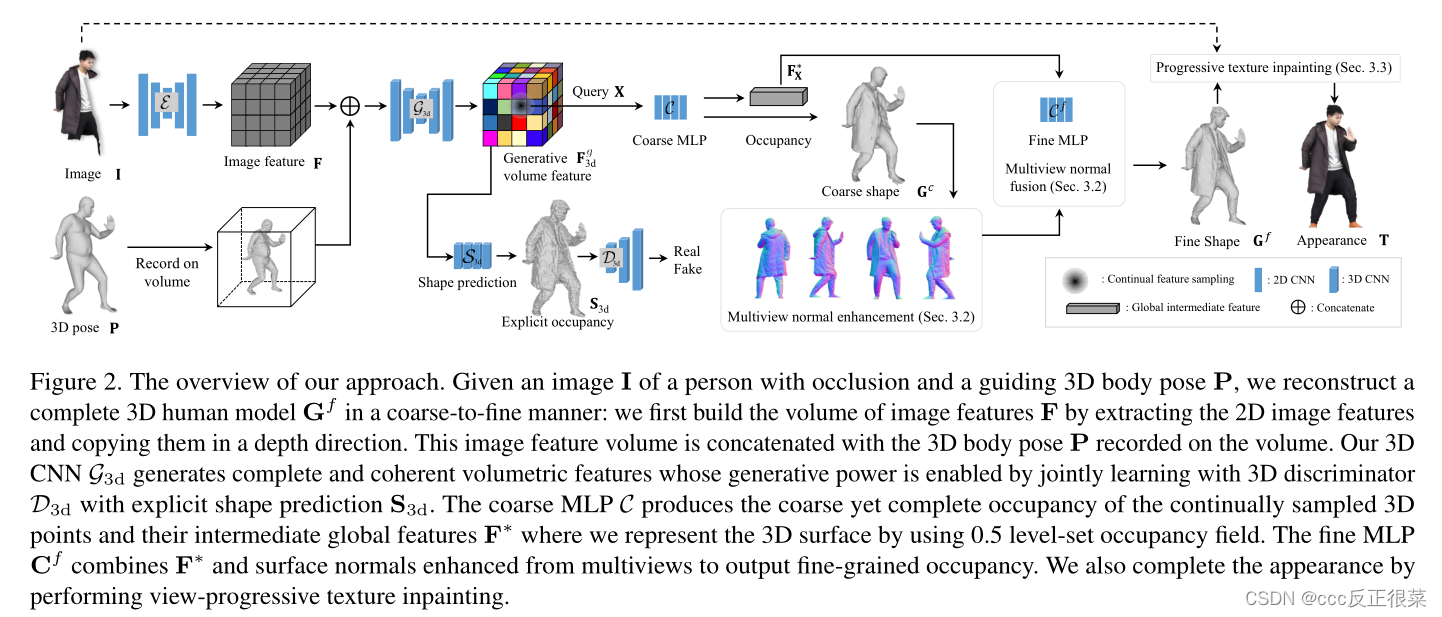
【13】Complete 3D Human Reconstruction from a Single Incomplete Image(从单个不完整图像进行完整的三维人体重建)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Wang_Complete_3D_Human_Reconstruction_From_a_Single_Incomplete_Image_CVPR_2023_paper.pdf
代码链接:
摘要:本文提出了一种从只观察到部分身体(如躯干)的人的图像中重建完整的人体几何结构和纹理的方法。核心挑战来自遮挡:在许多现有的单视图人体重建方法无法处理这些不可见部分的情况下,没有像素可重建,导致3D数据丢失。为了应对这一挑战,我们引入了一种新的从粗到细的人体重建框架。对于粗略重建,学习显式体积特征,以通过3D身体模型和可见部位的风格特征条件下的3D卷积神经网络生成完整的人体几何结构。隐式网络将学习到的3D特征与从多视点增强的高质量表面法线相结合,以产生精细的局部细节,例如高频褶皱。最后,我们进行渐进式纹理修复,以视图一致的方式重建人的完整外观,如果没有完整几何体的重建,这是不可能的。在实验中,我们证明了我们的方法可以重建高质量的3D人体,这对遮挡是鲁棒的。
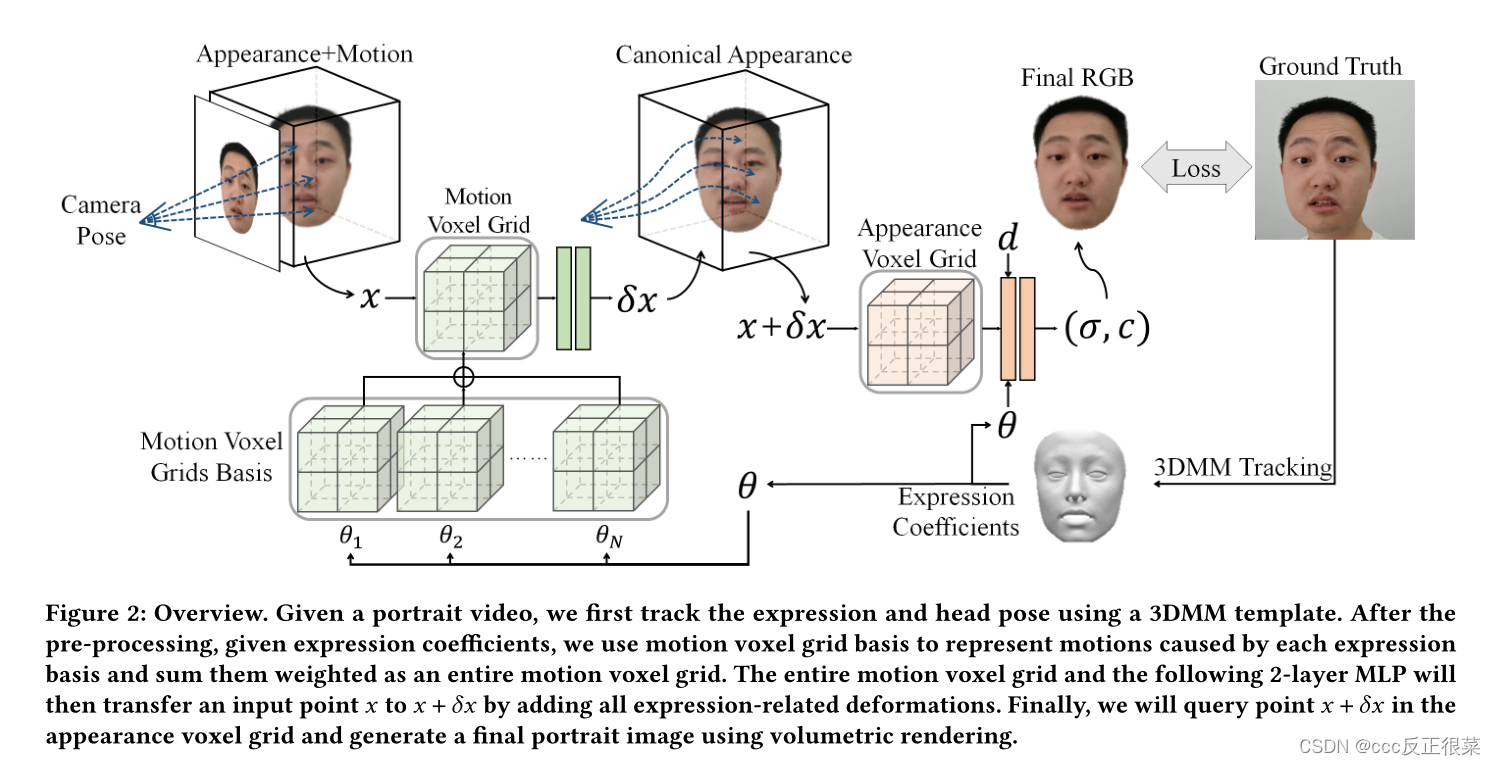
【14】AvatarMA V: Fast 3D Head Avatar Reconstruction Using Motion-Aware Neural Voxels(AvatarMA V:使用运动感知神经Voxels的快速3D头部头像重建)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3588432.3591567
代码链接:https://github.com/YuelangX/AvatarMAV
摘要:随着NeRF被广泛用于面部再现,最近的方法可以从单眼视频中恢复照片逼真的3D头部化身。不幸的是,基于NeRF的方法的训练过程相当耗时,因为基于NeRF方法中使用的MLP效率低下,并且需要太多迭代才能收敛。为了克服这个问题,我们提出了AvatarMAV,这是一种使用运动感知神经Voxels的快速3D头部化身重建方法。AvatarMAV是第一个通过头部化身的神经体素对规范外观和解耦表情运动进行建模的系统。特别地,运动感知神经体素是从多个4D张量的加权级联生成的。4D张量在语义上与3DMM表达式基础一一对应,并且共享与3DMM表达系数相同的权重。得益于我们的新颖表示,所提出的AvatarMA V可以在5分钟内恢复照片逼真的头部化身(用纯PyTorch实现),这明显快于现有技术的面部再现方法。
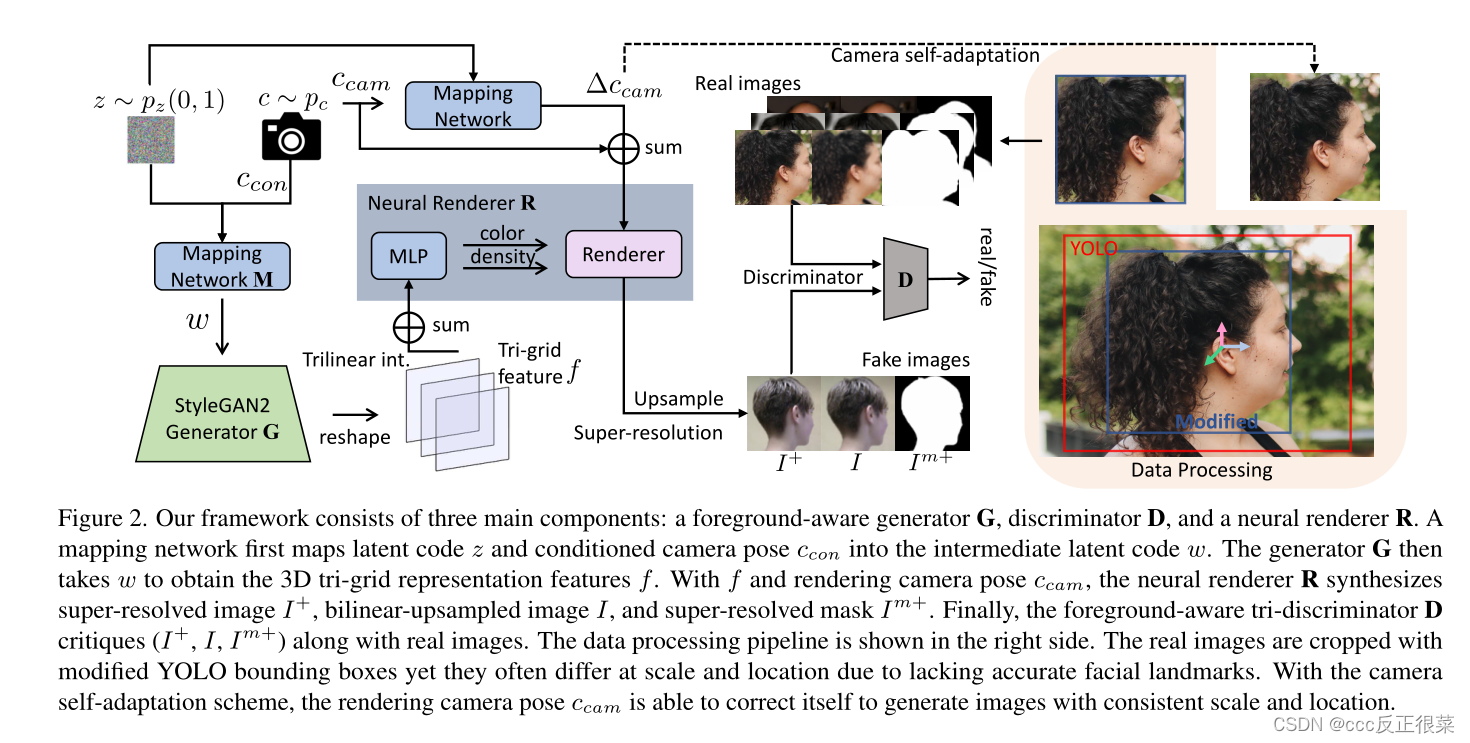
【15】PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360◦(PanoHead:360度的几何感知3D全头合成)
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/An_PanoHead_Geometry-Aware_3D_Full-Head_Synthesis_in_360deg_CVPR_2023_paper.pdf
代码链接:https://github.com/sizhean/panohead
摘要:近年来,三维人头的合成和重建在计算机视觉和计算机图形学领域引起了越来越多的兴趣。现有的用于3D人头合成的最先进的3D生成对抗性网络(GANs)要么局限于近正面视图,要么难以在大视角下保持3D一致性。我们提出了PanoHead,这是第一个3D感知生成模型,可以在360中实现全头的高质量视图一致图像合成◦ 具有多样的外观和详细的几何结构,仅在用于训练的未结构化图像中使用。其核心是,当从具有广泛分布视图的野外图像进行训练时,我们提高了最近的3D GANs的表示能力,并弥合了数据对齐差距。具体来说,我们提出了一种新的两阶段自适应图像对齐方法,用于鲁棒的3D GAN训练。我们进一步引入了一种三网格神经体积表示,该表示有效地解决了基于广泛采用的三平面公式的正面和背面特征纠缠。我们的方法在3D神经场景结构的对抗性学习中灌输了2D图像分割的先验知识,实现了在不同背景下的可合成头部合成。得益于这些设计,我们的方法显著优于以前的3D GANs,生成高质量的3D头,具有精确的几何结构和多样化的外观,即使是波浪形和非洲发型,也可以从任意姿势渲染。此外,我们展示了我们的系统可以从单个输入图像重建完整的3D头部,以获得个性化的逼真3D化身。
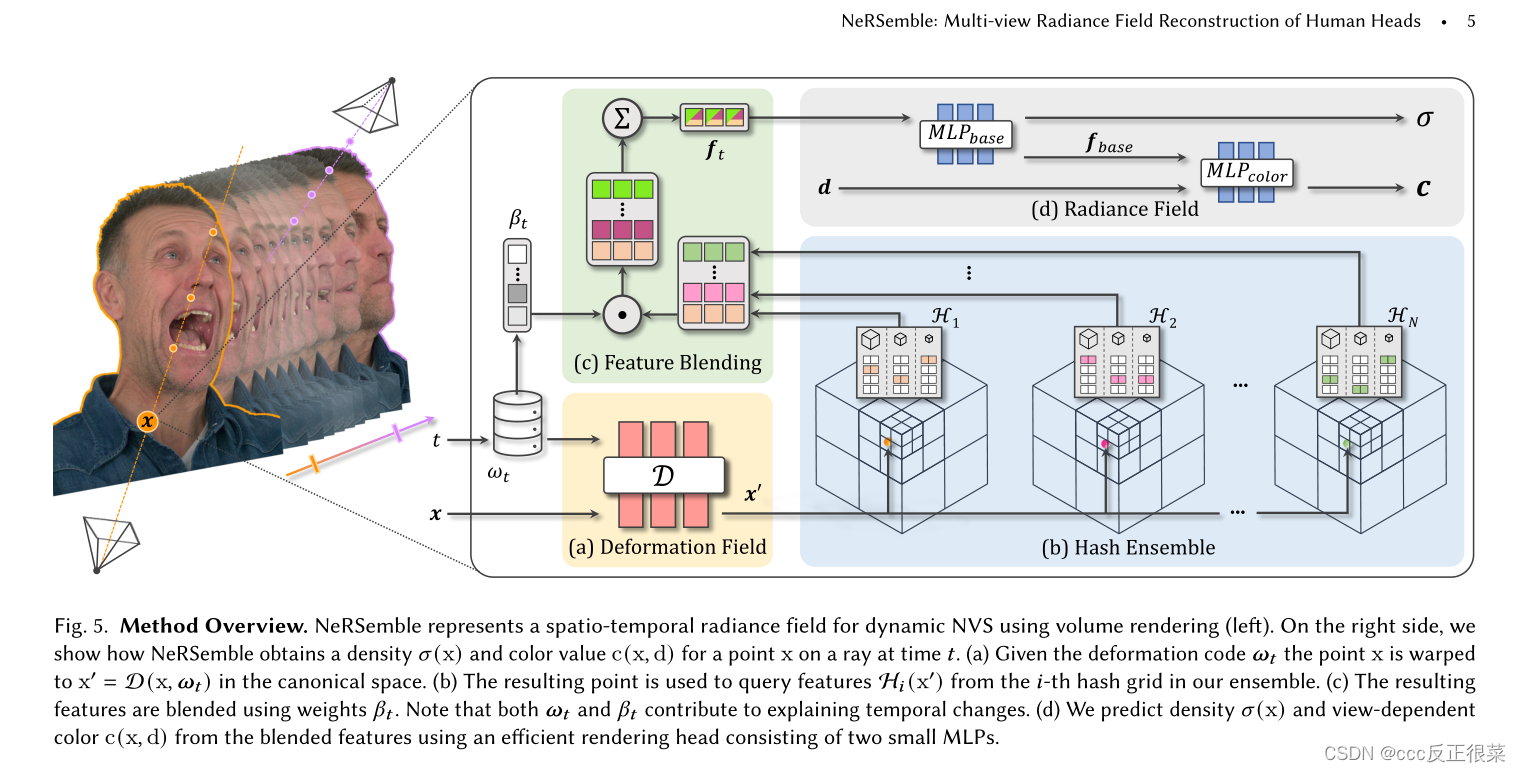
【16】NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads(NeRSemble:人类头部的多视角辐射场重建)
论文链接:https://arxiv.org/pdf/2305.03027.pdf
代码链接:https://github.com/tobias-kirschstein/nersemble
摘要:我们专注于重建人类头部的高保真辐射场,捕捉它们随时间变化的动画,并在任意时间步长从新颖的视点合成重新渲染。为此,我们提出了一种新的多视图捕捉装置,由16台经过校准的机器视觉相机组成,以7.1MP分辨率和每秒73帧的速度记录时间同步图像。通过我们的设置,我们收集了一个新的数据集,该数据集包含4700多个高分辨率、高帧率的220多个人头序列,我们从中引入了新的人头重建基准1。录制的序列涵盖了广泛的面部动态,包括头部动作、自然表情、情绪和口语。为了重建高保真度的人类头部,我们提出了使用哈希集合的动态神经辐射场(NeRSemble)。我们通过组合变形场和3D多分辨率哈希编码的集合来表示场景动力学。变形场允许对简单的场景移动进行精确建模,而哈希编码的集合有助于表示复杂的动力学。因此,我们获得了人类头部的辐射场表示,这些辐射场表示捕捉了随时间的运动,并有助于重新渲染任意新颖的视点。在一系列实验中,我们探索了我们方法的设计选择,并证明我们的方法显著优于最先进的动态辐射场方法。
【17】Accurate 3D Face Reconstruction with Facial Component Tokens(基于面部成分标记的精确三维人脸重建)
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_Accurate_3D_Face_Reconstruction_with_Facial_Component_Tokens_ICCV_2023_paper.pdf
代码链接:
摘要:
从单眼图像和视频中准确重建3D人脸对于各种应用至关重要,例如数字化身创建。然而,当前基于深度学习的方法在使用解纠缠的面部参数实现精确重建以及确保视频数据上3D人脸跟踪的单帧方法的时间稳定性方面面临着重大挑战。在本文中,我们提出了TokenFace,一个基于transformer的单目3D人脸重建模型。TokenFace为不同的面部组件使用单独的令牌来捕获关于不同面部参数的信息,并使用时间变换器来从视频数据中捕获时间信息。这种设计可以自然地解开不同的面部成分,并且对2D和3D训练数据都很灵活。经过2D和3D混合数据的训练,我们的模型显示了它在从图像中准确重建人脸和为视频数据产生稳定结果方面的能力。在流行的基准NoW和Stirling上的实验结果表明,TokenFace实现了最先进的性能,在所有指标上都大大优于现有方法。

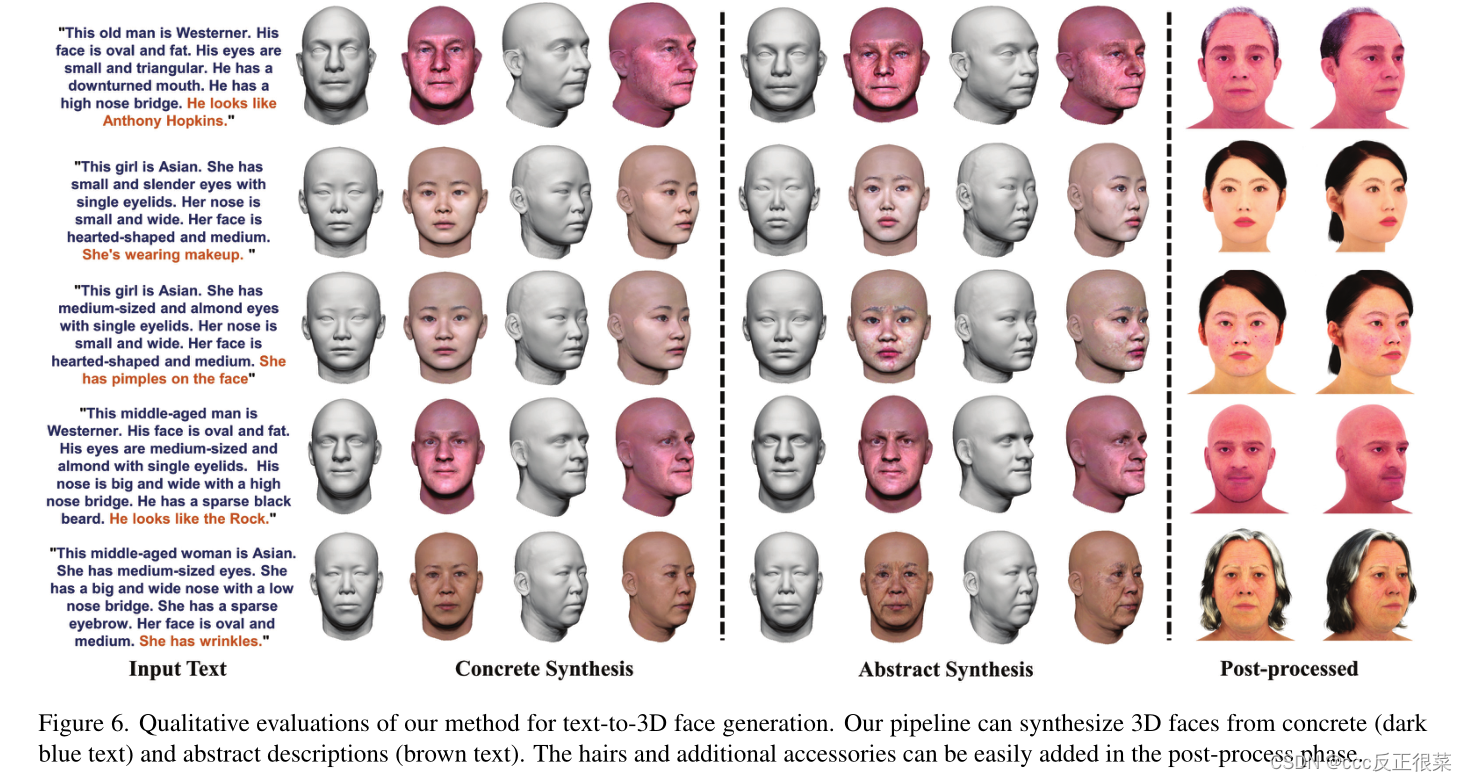
【18】High-Fidelity 3D Face Generation from Natural Language Descriptions(基于自然语言描述的高保真三维人脸生成
)
论文链接:https://arxiv.org/pdf/2305.03302.pdf
代码链接:https://github.com/zhuhao-nju/describe3d
摘要:从自然语言描述中合成高质量的3D人脸模型对许多应用非常有价值,包括化身创建、虚拟现实和远程呈现。然而,很少有研究涉及这项任务。
我们认为主要障碍在于1)缺乏具有描述性文本注释的高质量3D人脸数据,以及2)描述性语言空间与形状/外观空间之间的复杂映射关系。为了解决这些问题,我们构建了DESCRIBE3D数据集,这是第一个用于文本到3D人脸生成任务的具有细粒度文本描述的大规模数据集。然后,我们提出了一个两阶段框架,首先生成与具体描述相匹配的3D人脸,然后用抽象描述优化3D形状和纹理空间中的参数,以细化3D人脸模型。大量的实验结果表明,与以前的方法相比,我们的方法可以产生符合输入描述的忠实的3D人脸,具有更高的精度和质量
这篇关于2023(cpvr+顶刊)三维重建论文汇总(持续更新)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








