本文主要是介绍Elasticsearch7.3.0启动指定JDK11,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前篇提要
Centos7安装Elasticsearch7.3.0版本
linux开发环境的jdk是1.8,在启动Elasticsearch7.3.0的时候,启动日志会有如下信息:
[esuser@izm5e1lllyaje4uovv8cbdz elasticsearch-7.3.0]$ ./bin/elasticsearch
future versions of Elasticsearch will require Java 11; your Java version from [/data/jdk/jdk1.8.0_181/jre] does not meet this requirement
这是由于Elasticsearch依赖于jdk,es和jdk有着对应的依赖关系。具体可见:
https://www.elastic.co/cn/support/matrix
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/setup.html
这里是说Elasticsearch该版本内置了JDK,而内置的JDK是当前推荐的JDK版本。当然如果你本地配置了JAVA_HOME那么ES就是优先使用配置的JDK启动ES。(言外之意,你不安装JDK一样可以启动,我试了可以的。)
ES推荐使用LTS版本的JDK(这里只是推荐,JDK8就不支持),如果你使用了一些不支持的JDK版本,ES会拒绝启动。
那么哪些版本的JDK支持LTS呢?https://www.oracle.com/java/technologies/java-se-support-roadmap.html
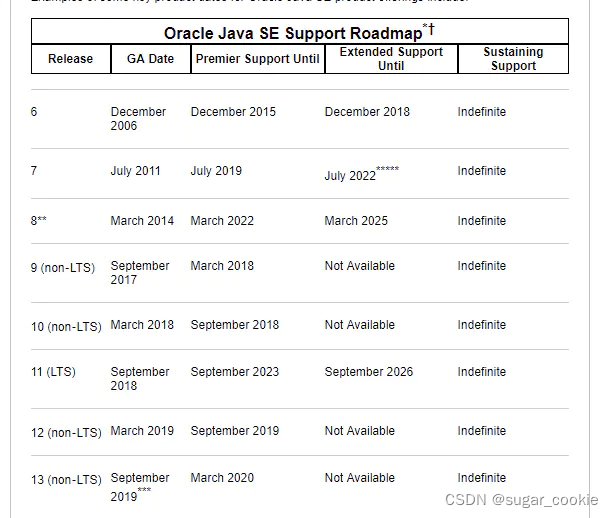
根据启动信息我们看到Elasticsearch7.3.0推荐使用JDK11,并且从刚才的截图得知可以下载openjdk 11.
安装OpenJDK11
下载安装包
[root@izm5e1lllyaje4uovv8cbdz jdk]# pwd
/data/jdk
[root@izm5e1lllyaje4uovv8cbdz jdk]# wget https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz
百度云
链接:https://pan.baidu.com/s/1AjA7Mboih-fpEBIPp2pBTg
提取码:jstl
解压到指定目录
[root@izm5e1lllyaje4uovv8cbdz jdk]# tar -xzvf openjdk-11.0.1_linux-x64_bin.tar.gz
到此结束
由于我们日常的代码开发都是使用的JDK1.8,所以这里不会把JAVA_HOME配置成JDK11,我们只需更改Elasticsearch的启动文件,使它指向我们下载的JDK11.
修改配置文件
[root@izm5e1lllyaje4uovv8cbdz bin]# pwd
/home/esuser/es/elasticsearch-7.3.0/bin
[root@izm5e1lllyaje4uovv8cbdz bin]# vim elasticsearch
添加一下几行内容
#配置自己的jdk11
export JAVA_HOME=/data/jdk-11.0.1
export PATH=$JAVA_HOME/bin:$PATH#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; thenJAVA="/data/jdk-11.0.1/bin/java"
elseJAVA=`which java`
fi
为了方便大家参考,这里贴上完整的配置文件
#!/bin/bash# CONTROLLING STARTUP:
#
# This script relies on a few environment variables to determine startup
# behavior, those variables are:
#
# ES_PATH_CONF -- Path to config directory
# ES_JAVA_OPTS -- External Java Opts on top of the defaults set
#
# Optionally, exact memory values can be set using the `ES_JAVA_OPTS`. Note that
# the Xms and Xmx lines in the JVM options file must be commented out. Example
# values are "512m", and "10g".
#
# ES_JAVA_OPTS="-Xms8g -Xmx8g" ./bin/elasticsearch#配置自己的jdk11
export JAVA_HOME=/data/jdk/jdk-11.0.1
export PATH=$JAVA_HOME/bin:$PATHif [ -z "$ES_TMPDIR" ]; thenES_TMPDIR=`"$JAVA" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.TempDirectory`
fiES_JVM_OPTIONS="$ES_PATH_CONF"/jvm.options
JVM_OPTIONS=`"$JAVA" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.JvmOptionsParser "$ES_JVM_OPTIONS"`
ES_JAVA_OPTS="${JVM_OPTIONS//\$\{ES_TMPDIR\}/$ES_TMPDIR}"#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; thenJAVA="/data/jdk/jdk-11.0.1/bin/java"
elseJAVA=`which java`
fi# manual parsing to find out, if process should be detached
if ! echo $* | grep -E '(^-d |-d$| -d |--daemonize$|--daemonize )' > /dev/null; thenexe c\
rt JAVA_HOME=/opt/jdk-11.0.1
export PATH=$JAVA_HOME/bin:$PATH:"$JAVA" \$ES_JAVA_OPTS \-Des.path.home="$ES_HOME" \-Des.path.conf="$ES_PATH_CONF" \-Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \-Des.distribution.type="$ES_DISTRIBUTION_TYPE" \-Des.bundled_jdk="$ES_BUNDLED_JDK" \-cp "$ES_CLASSPATH" \org.elasticsearch.bootstrap.Elasticsearch \"$@"
elseexec \"$JAVA" \$ES_JAVA_OPTS \-Des.path.home="$ES_HOME" \-Des.path.conf="$ES_PATH_CONF" \-Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \-Des.distribution.type="$ES_DISTRIBUTION_TYPE" \-Des.bundled_jdk="$ES_BUNDLED_JDK" \-cp "$ES_CLASSPATH" \org.elasticsearch.bootstrap.Elasticsearch \"$@" \<&- &retval=$?pid=$![ $retval -eq 0 ] || exit $retvalif [ ! -z "$ES_STARTUP_SLEEP_TIME" ]; thensleep $ES_STARTUP_SLEEP_TIMEfiif ! ps -p $pid > /dev/null ; thenexit 1fiexit 0
fiexit $?
启动ES
[esuser@izm5e1lllyaje4uovv8cbdz bin]$ ./elasticsearch
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
[2019-08-02T15:33:27,994][INFO ][o.e.e.NodeEnvironment ] [node-1] using [1] data paths, mounts [[/ (rootfs)]], net usable_space [32.6gb], net total_space [35.7gb], types [rootfs]
[2019-08-02T15:33:28,014][INFO ][o.e.e.NodeEnvironment ] [node-1] heap size [1015.6mb], compressed ordinary object pointers [true]
[2019-08-02T15:33:28,017][INFO ][o.e.n.Node ] [node-1] node name [node-1], node ID [8zGCWQhBS3OpVShqjSgU-w], cluster name [es-application]
[2019-08-02T15:33:28,017][INFO ][o.e.n.Node ] [node-1] version[7.2.0], pid[1545], build[default/tar/508c38a/2019-06-20T15:54:18.811730Z], OS[Linux/3.10.0-862.el7.x86_64/amd64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/11.0.1/11.0.1+13]
[2019-08-02T15:33:28,017][INFO ][o.e.n.Node ] [node-1] JVM home [/opt/jdk-11.0.1]
[2019-08-02T15:33:28,018][INFO ][o.e.n.Node ] [node-1] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=/tmp/elasticsearch-5247006010869253587, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Djava.locale.providers=COMPAT, -Dio.netty.allocator.type=unpooled, -XX:MaxDirectMemorySize=536870912, -Des.path.home=/usr/local/src/elasticsearch, -Des.path.conf=/usr/local/src/elasticsearch/config, -Des.distribution.flavor=default, -Des.distribution.type=tar, -Des.bundled_jdk=true]
到这里我们又看到另一个警告
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was
deprecated in version 9.0 and will likely be removed in a future
release.
这是提醒你 cms 垃圾收集器在 jdk9 就开始被标注为 @deprecated
看下JDK11支持的垃圾回收器
HotSpot Virtual Machine Garbage Collection Tuning Guide
修改config下的 jvm.options
[root@izm5e1lllyaje4uovv8cbdz config]# pwd
/home/esuser/es/elasticsearch-7.3.0/config
[root@izm5e1lllyaje4uovv8cbdz config]# vim jvm.options
将 : -XX:+UseConcMarkSweepGC
改为:-XX:+UseG1GC
jvm.options 完整配置如下
## JVM configuration################################################################
## IMPORTANT: JVM heap size
################################################################
##
## You should always set the min and max JVM heap
## size to the same value. For example, to set
## the heap to 4 GB, set:
##
## -Xms4g
## -Xmx4g
##
## See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
## for more information
##
################################################################# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space-Xms1g
-Xmx1g################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don't tamper with them unless
## you understand what you are doing
##
################################################################## GC configuration
##-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly## G1GC Configuration
# NOTE: G1GC is only supported on JDK version 10 or later.
# To use G1GC uncomment the lines below.
# 10-:-XX:-UseConcMarkSweepGC
# 10-:-XX:-UseCMSInitiatingOccupancyOnly
# 10-:-XX:+UseG1GC
# 10-:-XX:InitiatingHeapOccupancyPercent=75## DNS cache policy
# cache ttl in seconds for positive DNS lookups noting that this overrides the
# JDK security property networkaddress.cache.ttl; set to -1 to cache forever
-Des.networkaddress.cache.ttl=60
# cache ttl in seconds for negative DNS lookups noting that this overrides the
# JDK security property networkaddress.cache.negative ttl; set to -1 to cache
# forever
-Des.networkaddress.cache.negative.ttl=10## optimizations# pre-touch memory pages used by the JVM during initialization
-XX:+AlwaysPreTouch## basic# explicitly set the stack size
-Xss1m# set to headless, just in case
-Djava.awt.headless=true# ensure UTF-8 encoding by default (e.g. filenames)
-Dfile.encoding=UTF-8# use our provided JNA always versus the system one
-Djna.nosys=true# turn off a JDK optimization that throws away stack traces for common
# exceptions because stack traces are important for debugging
-XX:-OmitStackTraceInFastThrow# flags to configure Netty
-Dio.netty.noUnsafe=true
-Dio.netty.noKeySetOptimization=true
-Dio.netty.recycler.maxCapacityPerThread=0# log4j 2
-Dlog4j.shutdownHookEnabled=false
-Dlog4j2.disable.jmx=true-Djava.io.tmpdir=${ES_TMPDIR}## heap dumps# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError# specify an alternative path for heap dumps; ensure the directory exists and
# has sufficient space
-XX:HeapDumpPath=data# specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log## JDK 8 GC logging8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m# JDK 9+ GC logging
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
# due to internationalization enhancements in JDK 9 Elasticsearch need to set the provider to COMPAT otherwise
# time/date parsing will break in an incompatible way for some date patterns and locals
9-:-Djava.locale.providers=COMPAT保存重新启动
[esuser@izm5e1lllyaje4uovv8cbdz bin]$ ./elasticsearch
[2019-08-02T15:58:33,923][INFO ][o.e.e.NodeEnvironment ] [node-1] using [1] data paths, mounts [[/ (rootfs)]], net usable_space [32.6gb], net total_space [35.7gb], types [rootfs]
[2019-08-02T15:58:33,951][INFO ][o.e.e.NodeEnvironment ] [node-1] heap size [1gb], compressed ordinary object pointers [true]
[2019-08-02T15:58:33,953][INFO ][o.e.n.Node ] [node-1] node name [node-1], node ID [8zGCWQhBS3OpVShqjSgU-w], cluster name [es-application]
[2019-08-02T15:58:33,953][INFO ][o.e.n.Node ] [node-1] version[7.2.0], pid[1700], build[default/tar/508c38a/2019-06-20T15:54:18.811730Z], OS[Linux/3.10.0-862.el7.x86_64/amd64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/11.0.1/11.0.1+13]
[2019-08-02T15:58:33,954][INFO ][o.e.n.Node ] [node-1] JVM home [/opt/jdk-11.0.1]
[2019-08-02T15:58:33,954][INFO ][o.e.n.Node ] [node-1] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseG1GC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=/tmp/elasticsearch-15008659954472371205, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Djava.locale.providers=COMPAT, -Dio.netty.allocator.type=unpooled, -XX:MaxDirectMemorySize=536870912, -Des.path.home=/usr/local/src/elasticsearch, -Des.path.conf=/usr/local/src/elasticsearch/config, -Des.distribution.flavor=default, -Des.distribution.type=tar, -Des.bundled_jdk=true]
警告消失了
这篇关于Elasticsearch7.3.0启动指定JDK11的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







