本文主要是介绍【C语言】指针专项练习 都是一些大厂的笔试真题 附有详细解析,带你深入理解指针,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.sizeof()与strlen()
sizeof是一个操作符,而strlen是一个库函数。
数组名代表首元素地址,有两种情况例外,第一种是数组名单独放在sizeof内部,第二种是&数组名,这两种情况下数组名代表的是整个数组。sizeof(arr)计算的是整个数组的大小,&arr是整个数组的地址,+1就跳过整个数组。
其实还有别的写法跟这两种等效,比如sizeof(*&arr) ,由于*和&抵消了,因此这个写法等价于sizeof(arr),因此此时的arr仍然代表整个数组。或者可以这么理解,&arr就是取出整个数组的地址,然后对他解引用,拿到的是整个数组,因此arr在这里代表整个数组。
strlen()函数需要的是一个地址,他会从这个地址开始往后找,直到碰见\0。在库函数的说明中strlen需要的是一个char*类型的参数,但其实传给他任何参数,他都会认为这是一个char*类型的地址,即使类型不是char*类型,strlen也会自动解读为传的参数是一个char*类型的地址。
下面是一系列的打印

这里有几个问题:第一个问题就是我们在创建数组arr的时候并没有人为的放\0进去,申请的内存空间就是申请了是六个字节大小的内存空间,那当我们把arr也就是数组首元素地址传递给strlen的时候,他从a开始往后统计,在f之后继续统计,直到碰见\0,这会不会造成越界访问?
把*arr也就是字符a的ASCII码值(97)传给strlen之后,strlen会把97当做一个地址,并试图从这里开始往后统计,但是此时编译器直接报错,是因为非法访问了,但是当我们把&arr+1传给strlen,却能够正常运行并得出一个随机值,而&arr+1代表跳过整个数组,后面的内存空间并没有向内存空间申请,为什么不报错?
首先回答第一个问题,会越界访问。
第二个问题,有些地址空间是不允许使用的,可能是系统留着自己用的,这个97就是不能使用的,因此会直接报错。
再来看一组打印

第一次打印,二维数组的数组名单独放在sizeof内部,计算的是整个数组的大小,结果为48
第二次打印,计算的是第一行第一列的元素大小,这个元素是int类型的,因此结果是4
第三次打印,sizeof内部放的是a[0],表示二维数组a的第一个元素,又因为二维数组是一维数组的数组,因此a[0]表示的是第一行的一维数组,a[0]是这个一维数组的数组名,数组名单独放在sizeof内部,计算的是整个一维数组的大小,结果是16
第四次打印,sizeof内部放的是a[0]+1,其中a[0]是第一行那个一维数组的数组名,这次没有单独放在sizeof内部,因此他代表第一行那个一位数组首元素的地址,也就是a[0][0]的地址,这个地址是int*类型的,+1跳过一个int类型的,因此sizeof内部放的其实是arr[0][1]的地址,他是int*类型的,打印结果是4或8。
第五次打印,sizeof内部放的是*(a[0]+1),前面我们已经分析过了,a[0]+1是a[0][1]的地址,对他解引用就是a[0][1],因此计算的就是这个元素的大小,结果是4
第六次打印,sizeof内部放的是a+1,a作为二维数组的数组名并没有单独放在sizeof内部,那a代表的就是a数组首元素的地址,也就是第一行的一维数组的地址,他是int(*)[4]类型的,+1跳过一个一维数组,指向了第二行一维数组,因此a+1是第二行那个二维数组的地址,类型也是int(*)[4],他的大小是4或8
第七次打印,sizeof内部放的是*(a+1),前面已经分析过了,a+1指向了第二行那个一维数组,因此解引用拿到了第二行的一维数组,他的类型是int [4],大小是16个字节,因此打印结果是16
第八次打印,sizeof内部放的是&a[0]+1,&a[0]表示第一行的一维数组的地址,类型是int(*)[4],+1跳过一个第一行指向了第二行,但终归也是一个地址,大小是4或8个字节,类型是int(*)[4],打印结果是4或8
第九次打印,sizeof内部放的是*(&a[0]+1),前面已经分析过了&a[0]+1是第二行的一维数组的地址,对他解引用就是第二行的一维数组,大小是16个字节
第十次打印,sizeof内部是*a,此时a是二维数组a的首元素地址,对他进行解引用就拿到了第一行,大小是16字节
第十一次打印,sizeof内部放的是a[3],这个东西实际上越界了,但是我们并没有实际去访问这块地址,sizeof在使用的时候只关心括号内是什么类型,类比a[0],a[1],a[2]编译器就知道a[3]应该是和他们同类型的,这是一维数组的数组名,代表整个一维数组,大小是16字节
注:sizeof在计算的时候只关注类型

因为a是short类型的,a+2显然是short类型的,因此不需要计算就知道了s的类型,最终就不会执行把a+2赋给s的语句,因此打印结果是2,4
实际上sizeof得到结果在编译阶段就已经结束了,而表达式的执行在运行期间才进行。
8道高质量笔试真题
1.

结果为2,5
&a表示拿到整个数组的地址,+1跳过了整个数组,指向了5后面的一个内存单元,然后把这个指针强制类型转换成int*类型,赋给ptr,打印的时候第一个打印的是
*(a+1),此时a代表的是数组首元素地址,所以类型是int*,+1跳过一个int类型,指向了第二个元素也就是2,因此第一次打印的是2,第二次打印*(ptr-1),因为ptr指向了5后面的单元并且已经被强制类型转换成int*类型,-1就会往前跳一个int类型指向5,所以第二次打印结果是5
2.

代码中创建了一个struct Test*类型的指针变量p,他的值是0x100000,+1跳过一个struct Test*类型,也就是20个字节,因此第一次打印结果是0x100014。
第二次打印先把p强制类型转换成了一个unsigned long类型,这就是个整数,都不是指针了,整数+1就是在这个数的基础上加1,现在p的值0x100000被编译器认为是一个整数,+1之后就是0x100001,因此第二次打印结果就是0x100001
第三次打印是把p强制类型转换成了一个int*类型的指针,这样走一步就是跳过一个int类型也就是四个字节,因此第三次打印结果是0x100004
3.运行结果是什么?

假设当前机器是小端字节序存储
数组a的每个元素都是int类型的,因此是4个字节,故在内存中的存储如图所示

&a+1代表跳过了整个数组,然后强制类型转换成int*类型并赋给ptr1,打印的是ptr1[-1]也就是*(ptr-1),因此第一次打印的是4。
a是数组首元素地址,把他强制类型转换成int类型然后+1,实际上就是在a原来的数值上直接加了1,只有指针+1的时候才去考虑是什么类型的,一个整数+1他就是+1,然后把a+1现在代表的值强制类型转换成int*并赋给ptr2,ptr2就指向了第二个字节单元,然后对他进行解引用,往后找四个字节,又因为小端存储,所以ptr2指向的这个int类型的元素是02 00 00 00,以16进制打印,打印的结果就是2000000。
4.打印结果是什么?

看清楚初始化的时候大括号里面是三个小括号,也就是三个逗号表达式,逗号表达式,从左往右开始计算,结果是最右边的结果,这三个逗号表达式的结果分别是1,3,5,数组剩下的元素补0。a[0]是第一行那个一维数组的数组名,代表这个一维数组首元素的地址也就是a[0][0]的地址,打印p[0]也就是*(p+0)就是打印a[0][0],因此打印结果是1。
5.运行结果是什么?


首先画出a数组在内存中的存储形式,实际上数组名a作为首元素的地址,是一个int(*)[5]类型的指针,而p是一个int(*)[4]类型的指针,类型不同,现在要把a赋给p,也不是不能赋,但是会发生隐式转换,这里不深究了,反正最后p也指向了a的首元素,而p[0]就是前四个字节,p[1]就是再后面四个字节,以此类推p[4]指向的位置如图所示,p[4]实际上是一个一维数组的数组名,p[4][2]是这个一维数组下标为2的元素,a[4][2]是这个数组a第五行第三列的元素,对他们两个取地址然后相减,指针减指针结果,如果以整数的形式进行打印,结果应该是两个指针之间的元素个数,但是这里是低地址减高地址,所以是-4,因此如果以%d的形式进行打印就是-4,具体过程就是,-4在内存中存的是补码,把补码还原成原码之后打印出来。但是如果以%p的形式进行打印,也就是打印一个地址,那地址就不管什么原码补码的了,直接就会认为存的这个-4的补码就是我们要打印的地址,最终以16进制展示出来,结果为0xFFFFFFFC。
6.

&aa拿到了整个数组的地址,+1跳过整个二维数组,指向了10后面的内存单元,然后把这个指针强制类型转换成int*类型赋给ptr1,打印的时候打印*(ptr1-1),打印的-1跳过一个int类型,因此打印了10。
aa+1不是&数组名也不是单独放在sizeof内部,因此这时候的aa是数组aa首元素地址,也就是第一行的一维数组的地址,+1跳过一个元素指向了第二行的一维数组,解引用就拿到了第二行的一维数组,实际上*(aa+1)就相当于aa[1]也就是第二行那个一维数组的数组名,他代表第二行那个一维数组首元素的地址,本身就是int*的,强制类型转换实际上没有意义,(ptr2-1)向前跳过一个int类型,指向了5,因此第二次打印的是5。
注:对二维数组的数组名进行解引用就拿到了一维数组,也就是一维数组的数组名。
7.

注:存储字符串用char*类型的指针来接收,上面看起来存的是三个字符串,实际上存的是这三个字符串的地址,因此a数组的每个元素都是char*类型的。

pa指向了数组a的首元素,pa是char**类型的,+1跳过一个char*类型指向了a的第二个元素,而这个元素也是一个char*类型的指针,这个指针指向了at,因此解引用之后打印出来的内容就是at
8.

字符串存储使用的是地址,应该使用一个char*类型的指针来接收,存放这四个字符串,应该使用四个char*类型的指针,那我们使用char*类型的数组c来存储。
再看数组cp,他里面存放的是c+3这样的东西,c是数组名,代表首元素的地址,也就是char**类型的,一共四个char**类型的元素,我们使用char**[4]类型的数组cp来存放。
再来看三级指针cpp,他存放的是数组名cp,也就是cp数组首元素的地址,又因为cp数组的首元素是c+3也就是char**类型的,因此cpp是char***类型的。
在内存中的存储关系图如图所示
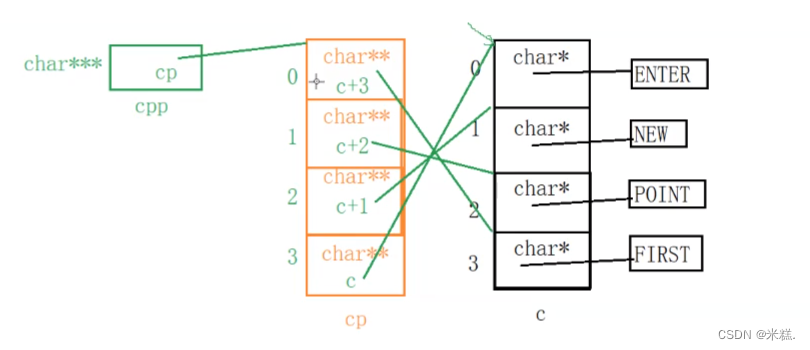
第一次打印**++cpp,先++后使用,cpp+1指向了cp数组的第二个元素,这个元素又指向了c数组的第3个元素,因此*++cpp就找到了c数组的第3个元素,这个元素又指向了POINT,因此**++cpp就拿到了POINT,第一次打印内容就是POINT
第二次打印*--*++cpp+3,通过查阅操作符优先级表格可知++操作符,--操作符和*操作符的优先级要比+高,因此+3是最后再算的,经过第一次打印,cpp现在已经指向了cp[1],再++,cpp现在指向了cp[2],解引用,找到了c[1],再--,就拿到了c[0],c[0]也是一个指针,指向字符串ENTER的首元素,类型是char*,再+3就跳过3个char类型指向了E,因此以%s的形式打印结果是ER
第三次打印cpp[-2]+3,就是打印 **(cpp-2)+3,计算顺序为cpp先-2,然后解引用两次,最后+3。cpp现在已经指向了cp[2],-2就会指向cp[0],解引用拿到cp[0],他指向了c[3],解引用就拿到了c[3],也就是FIRST中F的地址,类型是char*,+3跳过三个char类型指向S,因此打印的结果是ST
第四次打印cpp[-1][-1]+1,一层一层来,上一次打印cpp指向的位置改变是因为cpp-2,并不是cpp改变,现在cpp还是指向cp[2],所以cpp[-1]就拿到了cp[1],他指向c[2],因此cpp[-1][-1]就是c[1],也就是NEW中N的地址,类型是char*,+1跳过一个char类型指向了E,因此本次打印的结果是EW。
还可以这么理解最后一次打印,cpp[-1][-1]其实就是
*(*(cpp-1)-1)+1,cpp现在指向了cp数组第三个元素,-1就指向了cp数组的第二个元素,解引用就拿到了这个元素,这个元素是一个指针,指向了c数组的第三个元素,再-1,指向了c数组的第二个元素,解引用,拿到了c数组的第二个元素,这个元素是一个指针,存放的是NEW中N的地址,+1就是E的地址,因此打印结果是EW。
这篇关于【C语言】指针专项练习 都是一些大厂的笔试真题 附有详细解析,带你深入理解指针的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









