本文主要是介绍20211320LDK《Unix/Linux系统编程》第十一章学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、知识点归纳总结
1.EXT2文件系统简介
多年来,Linux一直使用EXT2(Card等1995)作为默认文件系统。EXT3(EXT3,2014)是EXT2的扩展。EXT3中增加的主要内容是一个日志文件,它将文件系统的变更记录在日志中。日志可在文件系统崩溃时更快地从错误中恢复。没有错误的EXT3文件系统与EXT2文件系统相同。EXT3的最新扩展是EXT4(Cao等2007)。EXT4的主要变化是磁盘块的分配。在EXT4中,块编号为48位。EXT4不是分配不连续的磁盘块,而是分配连续的磁盘块区,称为区段。除了这些细微的更改之外,文件系统结构和文件操作保持不变。
2.EXT2文件系统的数据结构
2.1 创建虚拟磁盘
在Linux下,命令mke2fs [-b blkesize -N ninodes] device nblocks可以在设备上创建一个带有nblocks个块(每个块大小为blksize字节)和ninodes个索引节点的EXT2文件系统。设备可以是真实设备,也可以是虚拟磁盘文件。如果未指定blksize,则默认块大小为1KB。如果未指定ninoides,mke2fs将根据 nblocks 计算一个默认的ninodes数。得到的EXT2文件系统可在Linux中使用。
我们可以在一个名为vdisk的虚拟磁盘文件上创建一个有1440个大小为1kb的块的EXT2文件系统:
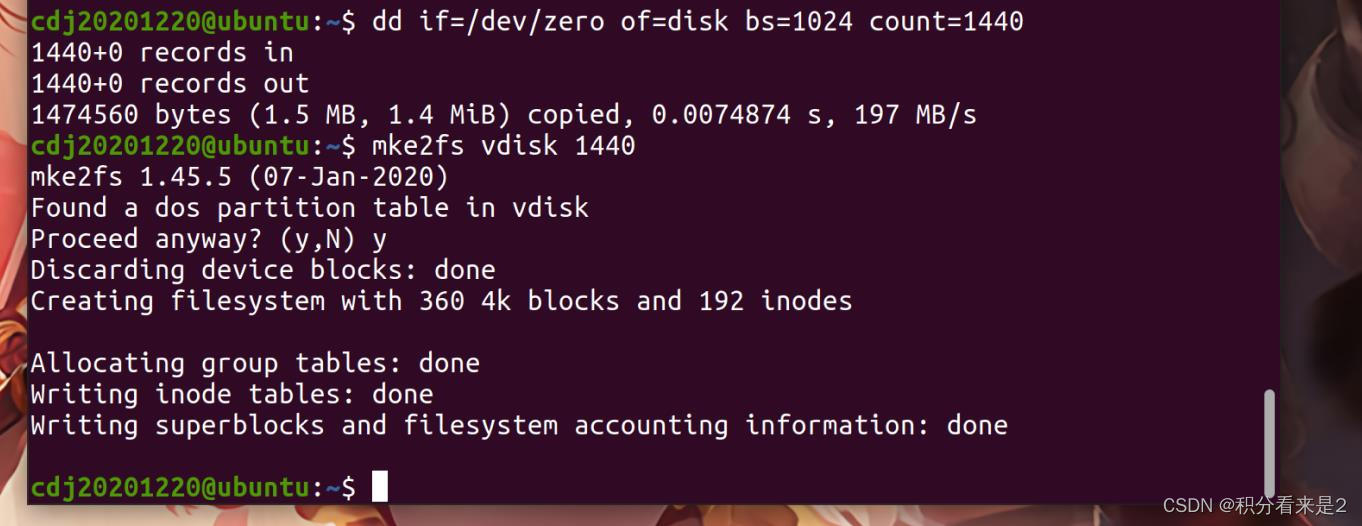
上述的EXT2文件系统的简单布局如下图:
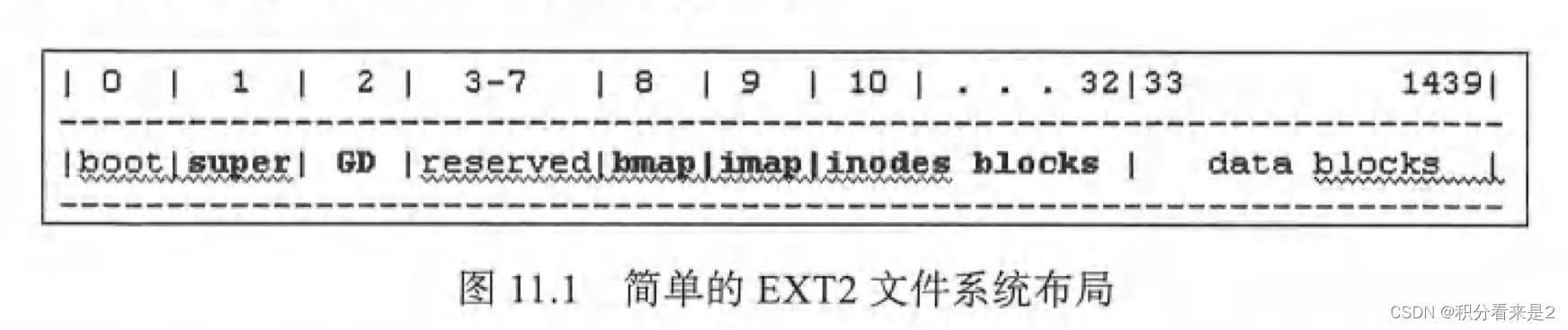
2.2 Block #1:超级块
(在硬盘分区中字节偏移量为1024)是用于容纳关于整个文件系统的信息的。以下是超级块结构中的一些重要字段:
struct ext2_super_block
{u32 s_inodes_count; // Inodes countu32 s_blocks_count; // Blocks countu32 s_r_blocks_count; // Reserved blocks countu32 s_free_blocks_count; // Free blocks countu32 s_free_inodes_count; // Free inodes countu32 s_first_data_block; // First Data Blocku32 s_log_block_size; // Block sizeu32 s_log_cluster_size; // Allocation cluster sizeu32 s_blocks_per_group; // # Blocks per groupu32 s_clusters_per_group; // # Fragments per groupu32 s_inodes_per_group; // # Inodes per groupu32 s_mtime; // Mount timeu32 s_wtime; // Write timeu32 s_mnt_count; // Mount countu16 s_max_mnt_count; // Maximal mount countu16 s_magic; // Magic signature// more non-essential fieldsu16 s_inode_size; // size of inode structure
};Block#2:块组描述块(硬盘上的s_first_data_blocks-1) EXT2将磁盘块分成几个组。每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体描述:
struct ext2_group_desc
{u32 bg_block_bitmap; // Bmap block numberu32 bg_inode_bitmap; // Imap block numberu32 bg_inode_table; // Inodes begin block numberu16 bg_free_blocks_count; // THESE are OBVIOUSu16 bg_free_inodes_count;ul6 bg_used_dirs_count;u16 bg_pad; // ignore theseu32 bg_reserved[3];};需要注意的是,由于一个虚拟软盘(FD)只有1440个块,而B2就只包含一个块组描述符。其中重要的字段是bg_block_bitmap、bg_inode_bitmap和bg_inode_table,他们分别指向块组的块位图、索引节点位图和索引节点起始块,而对于Linux格式的EXT2文件系统,保留了块3和7,所以它们分别为8,9,10。
2.3 Block#10:索引(开始)节点块
Block#10:索引(开始)节点块,每个文件都用一个128节点的独特索引节点结构体表示。下面是主要索引节点字段:
struct ext2_inode
{u16 i_mode; // 16 bits=|tttt |ugs|rwx|rwx|rwxlul6 i_uid; // owner uidu32 i_size; // file size in bytesu32 i_atime; // time fields in secondsu32 1_ctime; // since 00:00:00,1-1-1970u32 i_mtime;u32 i_dtime;i_gid; // group ID u16 i_links_count; // hard-link countu32 i_blocks; // number of 512-byte sectorsu32 i_flags; // IGNORE u32 i_reservedl; // IGNORE u32 i_block[15]; // See details belowu32 i_pad[7]; // for inode size = 128 bytes}其中i_block[15]数组包括指向文件磁盘块的指针,这些磁盘块有
- 直接块:0-11指向直接磁盘块;
- 间接块:12指向一个包含256个块编号的磁盘块,每个块编号指向一个磁盘块;
- 双重间接块:13指向一个指向256个的块,每个块指向256个磁盘块;
- 三重间接块:14是三重间接块,对于小型的“EXT2”文件系统,可以忽略这个块。
索引节点大小(128或256)用于平均分割块大小(1KB或4KB),所以,每个索引节点块都包含整数个索引节点。在简单的EXT2文件系统中,索引节点的数量是184个(Linux默认值)。索引节点块数等于184/8=23个。因此,索引节点块为B10至B32。每个索引节点都有一个唯一的索引节点编号,即索引节点在索引节点块上的位置+1。注意,索引节点位置从0开始计数,而索引节点编号从1开始计数。0索引节点编号表示没有索引节点。根目录的索引节点编号为2。同样,磁盘块编号也从1开始计数,因为文件系统从未使用块0。块编号0表示没有磁盘块。
3. 邮差算法
算法结构如下:
LA <=> BA
LA = infoBA = (blcok, inode)INODES_PER_BLCOK = BLCOK_SIZE/sizeof(INODE)
blcok = (info - 1) * INODES_PER_BLCOK + inode_table;inode = (info - 1) % INODES_PER_BLCOK教材上11.4给出了算法的具体实现,可以参考。
4. 遍历EXT2文件系统树
遍历算法
- 读取超级块。检查幻数s magic(0xEF53),验证它确实是 EXT2 FS。
- 读取块组描述符块(1+s first data block),以访问组0描述符。从块组描述符的bg_ inode_table条目中找到索引节点的起始块编号,并将其称为InodesBeginBlock。
- 读取InodeBeginBlock,获取/的索引节点,即INODE #2。
- 将路径名标记为组件字符串,假设组件数量为 n。例如,如果路径名=/a/b/c,则组件字符串是"a"“b”“c”,其中n=3。用name【0】,name【1】,…,name【n-1】来表示组件。
- 从3.中的根索引节点开始,在其数据块中搜索 name【0】。为简单起见,我们可以假设某个目录中的条目数量很少,因此一个目录索引节点只有12个直接数据块。有了这个假设,就可以在12个(非零)直接块中搜索 name【0】。目录索引节点的每个数据块都包含以下形式的 dir_entry结构体:
[ino rec_len name_len NAME] [ino rec_len name_len NAME] - 使用索引节点号ino 来定位相应的索引节点。回想前面的内容,ino 从1开始计数。使用邮差算法计算包含索引节点的磁盘块及其在该块中的偏移量
blk = (ino - 1) * INODES_PER_BLOCK + InodesBeginBlock;
offset = (ino - 1) % INODES_PER_BLOCK;然后在索引节点中读取/a,从中确定它是否是一个目录(DIR)。如果/a不是目录,则不能有/a/b,因此搜索失败。如果它是目录,并且有更多需要搜索的组件,那么继续搜索 下一个组件name【1】。现在的问题是:在索引节点中搜索/a的name【1】,与第5步相同。
可以编写一个搜索函数方便5~6步的循环。
二、苏格拉底大挑战




三、问题和解决思路
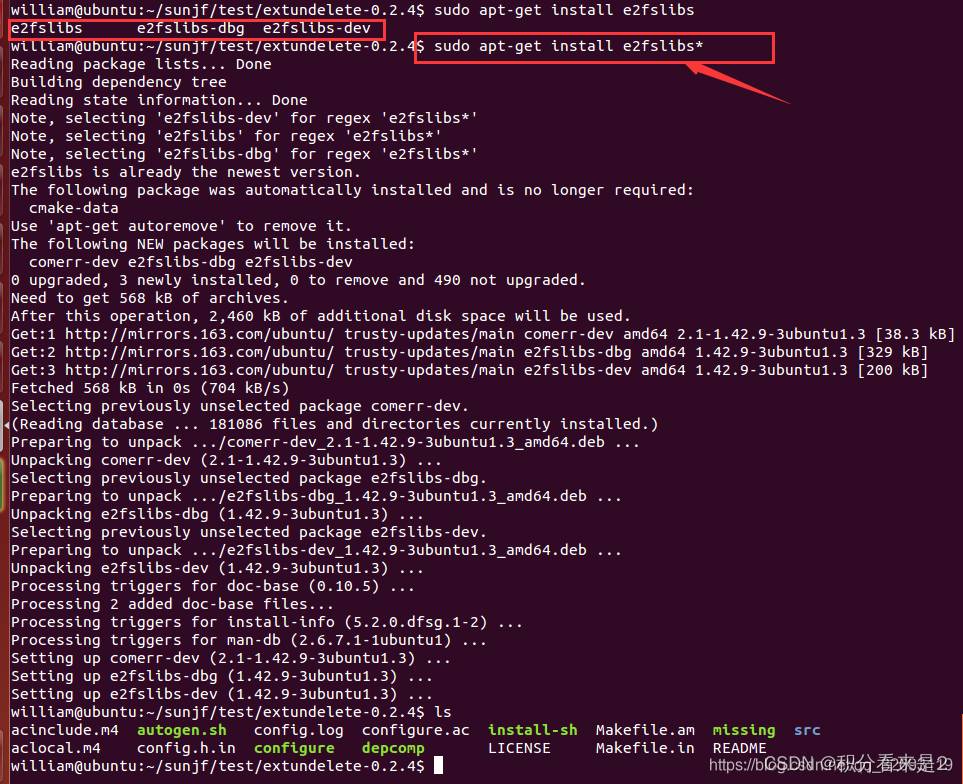
安装头文件时出错,询问gpt


四、代码实践
1.创建虚拟磁盘

2.使用df命令查看目前在 Linux 系统上的文件系统磁盘使用情况统计

这篇关于20211320LDK《Unix/Linux系统编程》第十一章学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





