本文主要是介绍【python】香浓熵计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
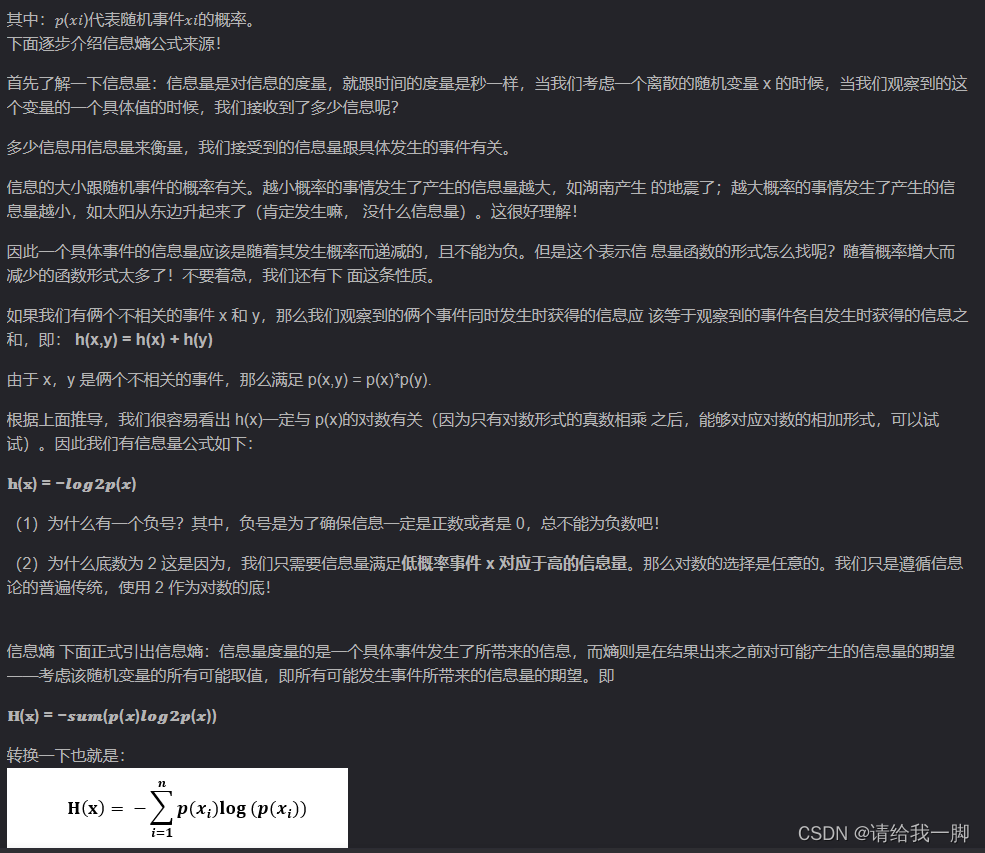
香农熵的公式:
不理解的可以看这个博文:傻子都能看懂的——信息熵(香农熵https://www.zhihu.com/question/22178202/answer/161732605
一个很通俗的例子解释香农熵:
来源:全国地研联:干货分享 | 城市功能混合程度计算 https://www.sohu.com/a/437716289_169228

代码
首先说一下我的数据。
主要数据,一列Name,一列percentage,分别是名字和比例。同上面通俗易懂的图对照,name就是不同区域,percentage就是用地分类占比。
代码gpt初稿,人工改的细节并根据需要做了修正
import csv
import math
import pandas as pddef calculate_shannon_entropy(csv_file, name_column, percentage_column):name_values = {}total_count = 0# 读取CSV文件with open(csv_file, 'r',encoding='utf-8-sig') as file:reader = csv.DictReader(file)for row in reader:name = row[name_column]percentage=float(row[percentage_column])if name in name_values:name_values[name].append(percentage)else:name_values[name]=[percentage]total_count += 1print('共读取 '+str(total_count)+' 行数据')print(name_values)entropy = 0.0result=[] # 计算每个分类的熵值for values in name_values.values():count=len(values) # 计算每个值的熵值value_entropy = sum(-p * math.log2(p) for p in values if p>0)print(value_entropy)result.append(value_entropy)entropy=value_entropydf = pd.DataFrame({'entropy': result, 'Names': list(name_values.keys())})print(df)df.to_csv(r"XXX.csv",header=True,encoding="utf_8_sig",index=False)return entropycsv_file = "XXX.csv"
name_column = 'Name' # 替换为名字列的列名
percentage_column = 'percentage' # 替换为poi分类列的列名shannon_entropy = calculate_shannon_entropy(csv_file, name_column, percentage_column)
print("最后一个香浓熵:", shannon_entropy)
这篇关于【python】香浓熵计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







