本文主要是介绍RocksDB源码学习(二):读(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:本篇博客所用代码版本均为 v7.7.3。
文章目录
- 前言
- 从 GetImpl 开始分析
- LookupKey
- Saver
- MemTableRep
- iter -> Seek()
- SaveValue()
- 从 Txn 复盘调用链
前言
RocksDB 的所有对记录 delete 和 update 操作,都不是就地删或者就地更新,而是新增一个记录表示这个操作,而这个记录也是一个 <k, v>,和其他所有的 <k, v> 按照同样的方式存储。看完 RocksDB源码学习(一) 那一章就知道,key 实际上是存在 user_key => internal_key => memetable_key 这一个转化过程的,从 internl_key 开始,就可以通过 valueType 部分区分出这个 <k, v> 具体是什么操作类型,是插入、删除、更新还是别的什么。很直观的来看,我们只需要读取插入和更新的 <k, v>,删除的 <k, v> 就不用管了。
enum ValueType : unsigned char {kTypeDeletion = 0x0,kTypeValue = 0x1, // 这个就是 put,表示插入或更新,即这个值是要读的kTypeMerge = 0x2,// ...
}
同一个 key 通过 sequence num 区分不同记录的时间先后,就像一个时间戳一样。而我们的读操作,实际上就是如何读到一个 key 最新的记录,而且是带数据的记录。RocksDB中,数据是保存在两个地方,一个是 memtable(内存),一个是 sstable(磁盘),RocksDB 读数据也是主要从这两个地方读取。
-
writebatch:如果仍有 writebatch 还没有 commit,那么就先在这读,没读到在进入 DB 中读取。
-
memtable:在 RocksDB 中 memtable 的默认实现是 skiplist,RocksDB 会将用户传入的 user_key 改变为memtable 内部的 key(internal_key_size+internal_key),然后再加上用户传入的 value 之后,作为一个element 加入到 skiplist,而我们读取的时候需要读取到最新的那条数据。
-
immutable memtable:一旦一个 memtable 被写满,它就会转为 immutable memtable,用来作为向 sstable 过渡的中间态,然后被替换为一个新的 memtable。immutable memtable 和 memtable 的数据结构完全一致,只是前者只能读不能写,且一个 CF 只能有一个 memtable,但可以有多个 immutable memtable。当从 memtable 中没读到时,就会尝试在这些 immutable memtable 中读。
-
sstable:如果上面三者都没读到,则开始从磁盘中读。除 L0 层之外,记录在每一层中有序,排序的依据依次是 user_key 升序,sequence num 降序,type 降序。除 L0 层之外,每一层中的各 sstable 所存储的 key 范围不会重叠,但 L0 层可能出现重叠。因此,在 L0 需要读取所有 sstable,在其他层只要读到一个就行。
本篇博客分析读操作的框架以及在 memtable 中的读取,着急看结论可以直接跳到最后一张图。
从 GetImpl 开始分析
我们知道,用户显示传入的 key 只是 user_key,它需要先被转换为 internal_key,其格式有两种,如下:
user_key + sequence + type;
(user_key + ts) + sequence + type; // (since v6.6.4)
转换函数为:
InternalKey(const Slice& _user_key, SequenceNumber s, ValueType t) {AppendInternalKey(&rep_, ParsedInternalKey(_user_key, s, t));
}
InternalKey(const Slice& _user_key, SequenceNumber s, ValueType t, Slice ts) {AppendInternalKeyWithDifferentTimestamp(&rep_, ParsedInternalKey(_user_key, s, t), ts);
}void AppendInternalKey(std::string* result, const ParsedInternalKey& key) {result->append(key.user_key.data(), key.user_key.size());PutFixed64(result, PackSequenceAndType(key.sequence, key.type));
}void AppendInternalKeyWithDifferentTimestamp(std::string* result,const ParsedInternalKey& key,const Slice& ts) {assert(key.user_key.size() >= ts.size());result->append(key.user_key.data(), key.user_key.size() - ts.size());result->append(ts.data(), ts.size());PutFixed64(result, PackSequenceAndType(key.sequence, key.type));
}
我们知道,RocksDB 按照 user_key 升序,seq 降序,type 降序,三者优先级依次降低的方式组织 internal_key。因此,只要读取到对应 user_key 的最大 seq,就算读取成功。internal_key 的比较器如下所示,返回 0 表示 a == b,-1 表示 a < b,+1 表示 a > b。
int InternalKeyComparator::Compare(const ParsedInternalKey& a,const ParsedInternalKey& b) const {// Order by:// increasing user key (according to user-supplied comparator)// decreasing sequence number// decreasing type (though sequence# should be enough to disambiguate)int r = user_comparator_.Compare(a.user_key, b.user_key);if (r == 0) {if (a.sequence > b.sequence) {r = -1;} else if (a.sequence < b.sequence) {r = +1;} else if (a.type > b.type) {r = -1;} else if (a.type < b.type) {r = +1;}}return r;
}
LookupKey
当用户想要查找 user_key 时,RocksDB 会首先为本次查找构建一个 LookupKey,该类会在 DBImpl::Get() 中用的。LookupKey 和普通的 key 差不多,也是存在 user_key、 internal_key 和 memtable_key 的形式,其源码如下:
// A helper class useful for DBImpl::Get()
class LookupKey {public:// Initialize *this for looking up user_key at a snapshot with// the specified sequence number.LookupKey(const Slice& _user_key, SequenceNumber sequence,const Slice* ts = nullptr);~LookupKey();// Return a key suitable for lookup in a MemTable.Slice memtable_key() const {return Slice(start_, static_cast<size_t>(end_ - start_));}// Return an internal key (suitable for passing to an internal iterator)Slice internal_key() const {return Slice(kstart_, static_cast<size_t>(end_ - kstart_));}// Return the user keySlice user_key() const {return Slice(kstart_, static_cast<size_t>(end_ - kstart_ - 8));}private:// We construct a char array of the form:// klength varint32 <-- start_// userkey char[klength] <-- kstart_// tag uint64// <-- end_// The array is a suitable MemTable key.// The suffix starting with "userkey" can be used as an InternalKey.const char* start_;const char* kstart_;const char* end_;char space_[200]; // Avoid allocation for short keys// No copying allowedLookupKey(const LookupKey&);void operator=(const LookupKey&);
};
可以看到,kstart_ 就是 internal_key,start_ 就是 memtable_key。注意到,LookupKey 的构造函数中,需要传入一个 user_key 、一个 seq 和一个 ts,其中 user_key 当然是要查询的 user_key,那么 seq 是哪里来的呢?
我们查看 LookupKey 的调用者,也就是 DBImpl::GetImpl(),其部分源码如下,我们只看和 seq 有关的部分。
Status DBImpl::GetImpl(const ReadOptions& read_options, const Slice& key,GetImplOptions& get_impl_options) {// ...SequenceNumber snapshot;if (read_options.snapshot != nullptr) {if (get_impl_options.callback) {// Already calculated based on read_options.snapshotsnapshot = get_impl_options.callback->max_visible_seq();} else {snapshot =reinterpret_cast<const SnapshotImpl*>(read_options.snapshot)->number_;}} else {// Note that the snapshot is assigned AFTER referencing the super// version because otherwise a flush happening in between may compact away// data for the snapshot, so the reader would see neither data that was be// visible to the snapshot before compaction nor the newer data inserted// afterwards.snapshot = GetLastPublishedSequence();if (get_impl_options.callback) {// The unprep_seqs are not published for write unprepared, so it could be// that max_visible_seq is larger. Seek to the std::max of the two.// However, we still want our callback to contain the actual snapshot so// that it can do the correct visibility filtering.get_impl_options.callback->Refresh(snapshot);// Internally, WriteUnpreparedTxnReadCallback::Refresh would set// max_visible_seq = max(max_visible_seq, snapshot)//// Currently, the commented out assert is broken by// InvalidSnapshotReadCallback, but if write unprepared recovery followed// the regular transaction flow, then this special read callback would not// be needed.//// assert(callback->max_visible_seq() >= snapshot);snapshot = get_impl_options.callback->max_visible_seq();}}// If timestamp is used, we use read callback to ensure <key,t,s> is returned// only if t <= read_opts.timestamp and s <= snapshot.// HACK: temporarily overwrite input struct field but restoreSaveAndRestore<ReadCallback*> restore_callback(&get_impl_options.callback);const Comparator* ucmp = get_impl_options.column_family->GetComparator();assert(ucmp);if (ucmp->timestamp_size() > 0) {assert(!get_impl_options.callback); // timestamp with callback is not supportedread_cb.Refresh(snapshot);get_impl_options.callback = &read_cb;}TEST_SYNC_POINT("DBImpl::GetImpl:3");TEST_SYNC_POINT("DBImpl::GetImpl:4");// Prepare to store a list of merge operations if merge occurs.MergeContext merge_context;SequenceNumber max_covering_tombstone_seq = 0;Status s;// First look in the memtable, then in the immutable memtable (if any).// s is both in/out. When in, s could either be OK or MergeInProgress.// merge_operands will contain the sequence of merges in the latter case.LookupKey lkey(key, snapshot, read_options.timestamp);// ...if (!skip_memtable) {// ...}// ...
}
在 RocksDB源码学习(一) 中提到,RocksDB 的读实际上是快照读,即先生成一个 snapshot ,这个 snapshot 就是一个 seq,然后只读取该 seq 以及之前的记录,往后的均视为在读操作之后才发生的操作,所以不可见。而 GetImpl() 中就会生成这个 snapshot,然后把它视为 LookupKey 的 seq,然后只查找该 seq 之前的记录。
先不管 get_impl_options.callback 是什么。简单的来看,GetImpl() 首先会询问 read_options 中是否有对 snapshot 的要求,毕竟配置大于一切。如果没有,那么就通过 GetLastPublishedSequence() 获取到最新的 seq 作为 snapshot。该函数内容如下:
virtual SequenceNumber GetLastPublishedSequence() const {if (last_seq_same_as_publish_seq_) {return versions_->LastSequence();} else {return versions_->LastPublishedSequence();}
}
也就是,返回当前 version 的最新一个 seq。
GetImpl() 构造完 LookupKey 之后,会判断是否跳过 memtable,如果否,将会调用 MemTable::Get() 函数。该函数的部分内容如下:
bool MemTable::Get(const LookupKey& key, std::string* value,PinnableWideColumns* columns, std::string* timestamp,Status* s, MergeContext* merge_context,SequenceNumber* max_covering_tombstone_seq,SequenceNumber* seq, const ReadOptions& read_opts,bool immutable_memtable, ReadCallback* callback,bool* is_blob_index, bool do_merge) {// ...bool bloom_checked = false;if (bloom_filter_) {// when both memtable_whole_key_filtering and prefix_extractor_ are set,// only do whole key filtering for Get() to save CPUif (moptions_.memtable_whole_key_filtering) {may_contain = bloom_filter_->MayContain(user_key_without_ts);bloom_checked = true;} else {assert(prefix_extractor_);if (prefix_extractor_->InDomain(user_key_without_ts)) {may_contain = bloom_filter_->MayContain(prefix_extractor_->Transform(user_key_without_ts));bloom_checked = true;}}}if (bloom_filter_ && !may_contain) {// iter is null if prefix bloom says the key does not existPERF_COUNTER_ADD(bloom_memtable_miss_count, 1);*seq = kMaxSequenceNumber;} else {if (bloom_checked) {PERF_COUNTER_ADD(bloom_memtable_hit_count, 1);}GetFromTable(key, *max_covering_tombstone_seq, do_merge, callback,is_blob_index, value, columns, timestamp, s, merge_context,seq, &found_final_value, &merge_in_progress);}//...
}
在截取的这部分代码中,会首先通过 bloom_filter 进行存在性检查,如果得到了阴性,那么就不会在往下进行读操作了,如果得到了阳性,那么就调用 MemTable::GetFromTable() 来进一步读取。所以,Get() 的核心就是使用 bloom_filter 进行存在性检查,之后的读操作由 GetFromTable() 来完成。
Saver
GetFromTable() 的完整代码如下:
void MemTable::GetFromTable(const LookupKey& key,SequenceNumber max_covering_tombstone_seq,bool do_merge, ReadCallback* callback,bool* is_blob_index, std::string* value,PinnableWideColumns* columns,std::string* timestamp, Status* s,MergeContext* merge_context, SequenceNumber* seq,bool* found_final_value, bool* merge_in_progress) {Saver saver;saver.status = s;saver.found_final_value = found_final_value;saver.merge_in_progress = merge_in_progress;saver.key = &key;saver.value = value;saver.columns = columns;saver.timestamp = timestamp;saver.seq = kMaxSequenceNumber;saver.mem = this;saver.merge_context = merge_context;saver.max_covering_tombstone_seq = max_covering_tombstone_seq;saver.merge_operator = moptions_.merge_operator;saver.logger = moptions_.info_log;saver.inplace_update_support = moptions_.inplace_update_support;saver.statistics = moptions_.statistics;saver.clock = clock_;saver.callback_ = callback;saver.is_blob_index = is_blob_index;saver.do_merge = do_merge;saver.allow_data_in_errors = moptions_.allow_data_in_errors;saver.protection_bytes_per_key = moptions_.protection_bytes_per_key;table_->Get(key, &saver, SaveValue);*seq = saver.seq;
}
这一大堆代码只干了两件事,其一是构造 Saver,其二是将其交给 MemTableRep::Get() 来进一步执行读取。我们一个一个说,先看 Saver,这个结构用来保存读取时的上下文,比如 LookupKey、MemTable、SequenceNumber 等等,代码如下:
struct Saver {Status* status;const LookupKey* key;bool* found_final_value; // Is value set correctly? Used by KeyMayExistbool* merge_in_progress;std::string* value;PinnableWideColumns* columns;SequenceNumber seq;std::string* timestamp;const MergeOperator* merge_operator;// the merge operations encountered;MergeContext* merge_context;SequenceNumber max_covering_tombstone_seq;MemTable* mem;Logger* logger;Statistics* statistics;bool inplace_update_support;bool do_merge;SystemClock* clock;ReadCallback* callback_;bool* is_blob_index;bool allow_data_in_errors;size_t protection_bytes_per_key;bool CheckCallback(SequenceNumber _seq) {if (callback_) {return callback_->IsVisible(_seq);}return true;}
};
在构造 Saver 部分,先看这几个字段:
saver.key = &key;saver.value = value;saver.seq = kMaxSequenceNumber;saver.mem = this;
其中,saver.key 就是传入的 LookupKey,saver.value 就是要保存值的地址,saver.mem 就是当前的 MemTable 类。需要注意的是,saver.seq 被设置为了 kMaxSequenceNumber,即最大的 seq。
MemTableRep
接下来,查看 MemTable::Get(),其完整代码如下:
void MemTableRep::Get(const LookupKey& k, void* callback_args,bool (*callback_func)(void* arg, const char* entry)) {auto iter = GetDynamicPrefixIterator();for (iter->Seek(k.internal_key(), k.memtable_key().data());iter->Valid() && callback_func(callback_args, iter->key());iter->Next()) {}
}
需要知道的是,MemTableRep 这个类用来抽象不同的 MemTable 的实现,也就是说它是一个虚类,然后不同的MemTable 实现了它。实现它的数据结构有很多,每一个派生类都是一个实现方式,如下:
但是注意,MemTableRep::Get() 没有被声明为 virtual !也就说,具体使用哪一个函数体,将由调用者指针的类型决定,而非其指向的对象类型决定。在 MemTable::GetFromTable() 中,通过 table_ —> Get(xx) 语句调用,而 table_ 的类型为 std::unique_ptr< MemTable >,即 MemTable*,所以不管 table_ 具体指向哪个派生类,其 Get() 的函数体均为 MemTableRep::Get() 中定义的函数体,而非派生类的函数体。
那么怎么区别不同的 MemTable 实现(也就是派生类)呢?关键在于迭代器的生成。
auto iter = GetDynamicPrefixIterator();
上述通过 GetDynamicPrefixIterator() 生成一个迭代器,其类型为 auto。而 GetDynamicPrefixIterator() 被声明为了 virtual,说明其函数体由 table_ 具体指向的对象类型决定,即由派生类决定。
class MemTableRep {// ...virtual Iterator* GetIterator(Arena* arena = nullptr) = 0;virtual Iterator* GetDynamicPrefixIterator(Arena* arena = nullptr) {return GetIterator(arena);}// ...
}
每个派生均有自己的迭代器,而 RocksDB 默认使用 SkipList,即 table_ 实际指向 SkipListRep 对象。

迭代器的具体实现这里先不说,后续会专门进行 SkipList 的源码分析,那篇博客里会细说。但是不论怎么实现的, Seek() 和 Next() 的功能都是一致的,只是性能的差异罢了。继续回到 MemTableRep::Get() 中,有两个关键问题,我们一个一个分析。
- iter —> Seek()
- callback_func()
iter -> Seek()
iter —> Seek() 传递了两个参数,internal_key 和 memtable_key,也就是 kstart_ 和 start_。为了搞清楚这两个成员的内容,我们进入 LookupKey 的构造函数中看一看:
LookupKey::LookupKey(const Slice& _user_key, SequenceNumber s,const Slice* ts) {size_t usize = _user_key.size();size_t ts_sz = (nullptr == ts) ? 0 : ts->size();size_t needed = usize + ts_sz + 13; // A conservative estimatechar* dst;if (needed <= sizeof(space_)) {dst = space_;} else {dst = new char[needed];}start_ = dst;// NOTE: We don't support users keys of more than 2GB :)dst = EncodeVarint32(dst, static_cast<uint32_t>(usize + ts_sz + 8));kstart_ = dst;memcpy(dst, _user_key.data(), usize);dst += usize;if (nullptr != ts) {memcpy(dst, ts->data(), ts_sz);dst += ts_sz;}EncodeFixed64(dst, PackSequenceAndType(s, kValueTypeForSeek));dst += 8;end_ = dst;
}
很明显,internal_key 就是 kstart_ ,memtable_key 就是start_。同样,LookupKey 也会选择是否给 internal_key 加上 ts,注意以下三行:
if (nullptr != ts) {memcpy(dst, ts->data(), ts_sz);dst += ts_sz;
}
其中,ts 由 readoptions 决定,为 readoption.timestamp。在 ReadOptions 结构体中,对该字段有如下注释:
Timestamp of operation. Read should return the latest data visible to the specified timestamp. All timestamps of the same database must be of the same length and format. The user is responsible for providing a customized compare function via Comparator to order <key, timestamp> tuples.
For iterator, iter_start_ts is the lower bound (older) and timestamp serves as the upper bound. Versions of the same record that fall in the timestamp range will be returned. If iter_start_ts is nullptr, only the most recent version visible to timestamp is returned. The user-specified timestamp feature is still under active development, and the API is subject to change.
Default: nullptr
前两句话就解释了它的作用。在读取时,可以提供一个 timestamp,然后读取操作只会返回 key 在该 ts 可见范围内最新的记录,也就是 ts 可见的且 seq 最大的记录。那么问题来了,什么叫 ts 可见?这个我现在还没弄清,猜测是小于等于 ts 的都可见,即在该时间点之前就已经成功提交的记录。
讨论完 ts,来看一下 type,可以看到其值为 kValueTypeForSeek,官方对它的介绍如下:
// kValueTypeForSeek defines the ValueType that should be passed when
// constructing a ParsedInternalKey object for seeking to a particular
// sequence number (since we sort sequence numbers in decreasing order
// and the value type is embedded as the low 8 bits in the sequence
// number in internal keys, we need to use the highest-numbered
// ValueType, not the lowest).
const ValueType kValueTypeForSeek = kTypeWideColumnEntity;
可以看到,它是所有 type 中最大的一个,值为 0x16。为什么要这么做呢?因为 type 是降序排列的,所以当 user_key、seq 都确定时,只有将 type 设为最大,LookupKey 才能成为最小的 key,然后开始向其他 type 的 key 迭代。
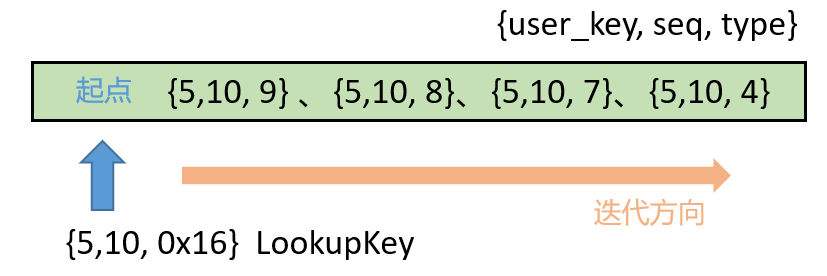
接着我们来分析源码,看看 Seek() 函数,位于 memtable/skiplistrep.cc。
// Advance to the first entry with a key >= target
void Seek(const Slice& user_key, const char* memtable_key) override {if (memtable_key != nullptr) {iter_.Seek(memtable_key);} else {iter_.Seek(EncodeKey(&tmp_, user_key));}
}
先说明一点,第一个形参虽然叫 user_key,但它实际上是 LookupKey 的 internal_key。但是我们只考虑 memtable_key 不为空的情况下,即一般情况,所以 internal_key 没用了。一直追踪下去,发现它最后会调用 SkipList 的查找函数,名为 InlineSkipList< Comparator >::FindGreaterOrEqual(),从这一步起,开始正式在 MemTable 中查找记录。函数源码如下:
InlineSkipList<Comparator>::FindGreaterOrEqual(const char* key) const {// Note: It looks like we could reduce duplication by implementing// this function as FindLessThan(key)->Next(0), but we wouldn't be able// to exit early on equality and the result wouldn't even be correct.// A concurrent insert might occur after FindLessThan(key) but before// we get a chance to call Next(0).Node* x = head_;int level = GetMaxHeight() - 1;Node* last_bigger = nullptr;const DecodedKey key_decoded = compare_.decode_key(key);while (true) {Node* next = x->Next(level);if (next != nullptr) {PREFETCH(next->Next(level), 0, 1);}// Make sure the lists are sortedassert(x == head_ || next == nullptr || KeyIsAfterNode(next->Key(), x));// Make sure we haven't overshot during our searchassert(x == head_ || KeyIsAfterNode(key_decoded, x));int cmp = (next == nullptr || next == last_bigger)? 1: compare_(next->Key(), key_decoded);if (cmp == 0 || (cmp > 0 && level == 0)) {return next;} else if (cmp < 0) {// Keep searching in this listx = next;} else {// Switch to next list, reuse compare_() resultlast_bigger = next;level--;}}
}
我们先不具体分析这段源码,但可以看出它的目的。都知道 SkipList 是多层的结构,迭代起点为最高层的最小节点,然后通过二分慢慢往低层行进。在该函数中,一旦找到了相同的 memtable_key,或者在最底层找到了恰好大于该目标的 memtable_key,那么就返回,否则继续找。SkipList 的逻辑可以看这篇文章:SkipList数据结构。该上段代码中,最为核心的就是 Next() 的实现以及 compare_() 的实现,这就涉及到 RocksDB 是如何实现 SkipList 的了,这里我们先不深入分析,后续会有一篇博客单独分析 SkipList 的源码实现:待填坑。
得到查找结果后,我们还有两个问题需要解决:
- 由于 memtable_key 是按照 user_key 是升序排列的,所以上述查找得到的 user_key 可能大于我们目标的 user_key,因此需要判断查找结果的 user_key 是否合目标吻合。
- 需要根据 type 的类型来判断这条记录是不是用来读值,如果是 delete 那当然不行。
SaveValue()
callback_func() 就是解决这两个问题的,当然,不止解决他们。
注意在 MemTable::GetFromTable() 调用 MemTable::Get() 时,传递的参数为 (key, &saver, SaveValue)。因此,callback_func() 实际长这样:
SaveValue(&saver, iter->key());
SaveValue() 函数比较长,但 switch-case 占了大部分,而且实现逻辑也很简单,这里截取重要的部分:
static bool SaveValue(void* arg, const char* entry) {Saver* s = reinterpret_cast<Saver*>(arg);// ...const char* key_ptr = GetVarint32Ptr(entry, entry + 5, &key_length);Slice user_key_slice = Slice(key_ptr, key_length - 8);const Comparator* user_comparator =s->mem->GetInternalKeyComparator().user_comparator();size_t ts_sz = user_comparator->timestamp_size();if (ts_sz && s->timestamp && max_covering_tombstone_seq > 0) {// timestamp should already be set to range tombstone timestampassert(s->timestamp->size() == ts_sz);}if (user_comparator->EqualWithoutTimestamp(user_key_slice,s->key->user_key())){// Correct user keyconst uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);ValueType type;SequenceNumber seq;UnPackSequenceAndType(tag, &seq, &type);// If the value is not in the snapshot, skip itif (!s->CheckCallback(seq)) {return true; // to continue to the next seq}// ...if (ts_sz > 0 && s->timestamp != nullptr) {if (!s->timestamp->empty()) {assert(ts_sz == s->timestamp->size());}// TODO optimize for smaller size tsconst std::string kMaxTs(ts_sz, '\xff');if (s->timestamp->empty() ||user_comparator->CompareTimestamp(*(s->timestamp), kMaxTs) == 0) {Slice ts = ExtractTimestampFromUserKey(user_key_slice, ts_sz);s->timestamp->assign(ts.data(), ts_sz);}}// ...switch (type) {// ... case xxxcase kTypeValue: {if (s->inplace_update_support) {s->mem->GetLock(s->key->user_key())->ReadLock();}Slice v = GetLengthPrefixedSlice(key_ptr + key_length);*(s->status) = Status::OK();if (*(s->merge_in_progress)) {if (s->do_merge) {if (s->value != nullptr) {*(s->status) = MergeHelper::TimedFullMerge(merge_operator, s->key->user_key(), &v,merge_context->GetOperands(), s->value, s->logger,s->statistics, s->clock, nullptr /* result_operand */, true);}} else {// Preserve the value with the goal of returning it as part of// raw merge operands to the usermerge_context->PushOperand(v, s->inplace_update_support == false /* operand_pinned */);}} else if (!s->do_merge) {// Preserve the value with the goal of returning it as part of// raw merge operands to the usermerge_context->PushOperand(v, s->inplace_update_support == false /* operand_pinned */);} else if (s->value) {if (type != kTypeWideColumnEntity) {assert(type == kTypeValue || type == kTypeBlobIndex);s->value->assign(v.data(), v.size());} else {Slice value;*(s->status) =WideColumnSerialization::GetValueOfDefaultColumn(v, value);if (s->status->ok()) {s->value->assign(value.data(), value.size());}}} else if (s->columns) {if (type != kTypeWideColumnEntity) {s->columns->SetPlainValue(v);} else {*(s->status) = s->columns->SetWideColumnValue(v);}}if (s->inplace_update_support) {s->mem->GetLock(s->key->user_key())->ReadUnlock();}*(s->found_final_value) = true;if (s->is_blob_index != nullptr) {*(s->is_blob_index) = (type == kTypeBlobIndex);}return false;}case kTypeDeletion:case kTypeDeletionWithTimestamp:case kTypeSingleDeletion:case kTypeRangeDeletion: {if (*(s->merge_in_progress)) {if (s->value != nullptr) {*(s->status) = MergeHelper::TimedFullMerge(merge_operator, s->key->user_key(), nullptr,merge_context->GetOperands(), s->value, s->logger,s->statistics, s->clock, nullptr /* result_operand */, true);}} else {*(s->status) = Status::NotFound();}*(s->found_final_value) = true;return false;}case kTypeMerge: {// ...}}}
}
首先,该函数判断找到的 user_key 是否为目标 user_key,使用的函数为 EqualWithoutTimestamp(),即在不考虑 ts 部分的情况下去比较两个 user_key 是否相同。接着,从找到的 user_key 中将其的 ts 提取出来,赋值给 saver 的 timestamp 字段。
在 switch-case 代码中,要注意,没有 break。
在 switch-case 代码中,我们先看 delete 相关。kTypeDeletion、kTypeDeletionWithTimestamp、kTypeSingleDeletion 都没有加 break,说明它们的操作都一样,交给 kTypeRangeDeletion 来做。简单的来看,当读到 delete 时,会触发一些 merge 操作,促使这个 user_key 被清理掉,或者直接返回 NotFound。
只有当 type 为 kTypeValue,才说明这条记录是被 Put 的,应该读值,所以我们重点关注它。在代码块中,有一些 merge 操作和 column 操作,我们不过,merge 会在另一篇博客中详细说明:待填坑。但是,可以看出的是,这一块主要是把找到的 user_key 的 value 赋值给 saver 中的 value,来作为最终的 Get 结果,然后将 found_final_value 设为 true,代表成功读取到 value。
else if (s->value) {if (type != kTypeWideColumnEntity) {assert(type == kTypeValue || type == kTypeBlobIndex);s->value->assign(v.data(), v.size());} else {Slice value;*(s->status) =WideColumnSerialization::GetValueOfDefaultColumn(v, value);if (s->status->ok()) {s->value->assign(value.data(), value.size());}}
}
那现在问题来了,只有当 s->value != nullptr 的时候,才会进行其中执行赋值,可是 s->value 本身就是用来保存查询结果的,那么此时它不应该还是空吗?还真不是,它确实没有值,但它不是 nullptr,它明确的指向了一个变量,所以判断能够成立。
从 Txn 复盘调用链
接下来我们就追溯这个 saver.value,看看它到底指向谁。这里一直要追溯到最上层的调用者,不管是读是写,调用者均为事务,因此要从 Transaction 开始追溯。RocksDB 提供了一段关于事务的示例代码,位于 examples/transaction_example.cc 中。刚好,借这个机会,我们从头开始捋一遍读取的流程,一直到从 MemTable 中找到 user_key。
函数链太长了,直接用图来表示,画板地址:读操作函数调用链(上)- memtable
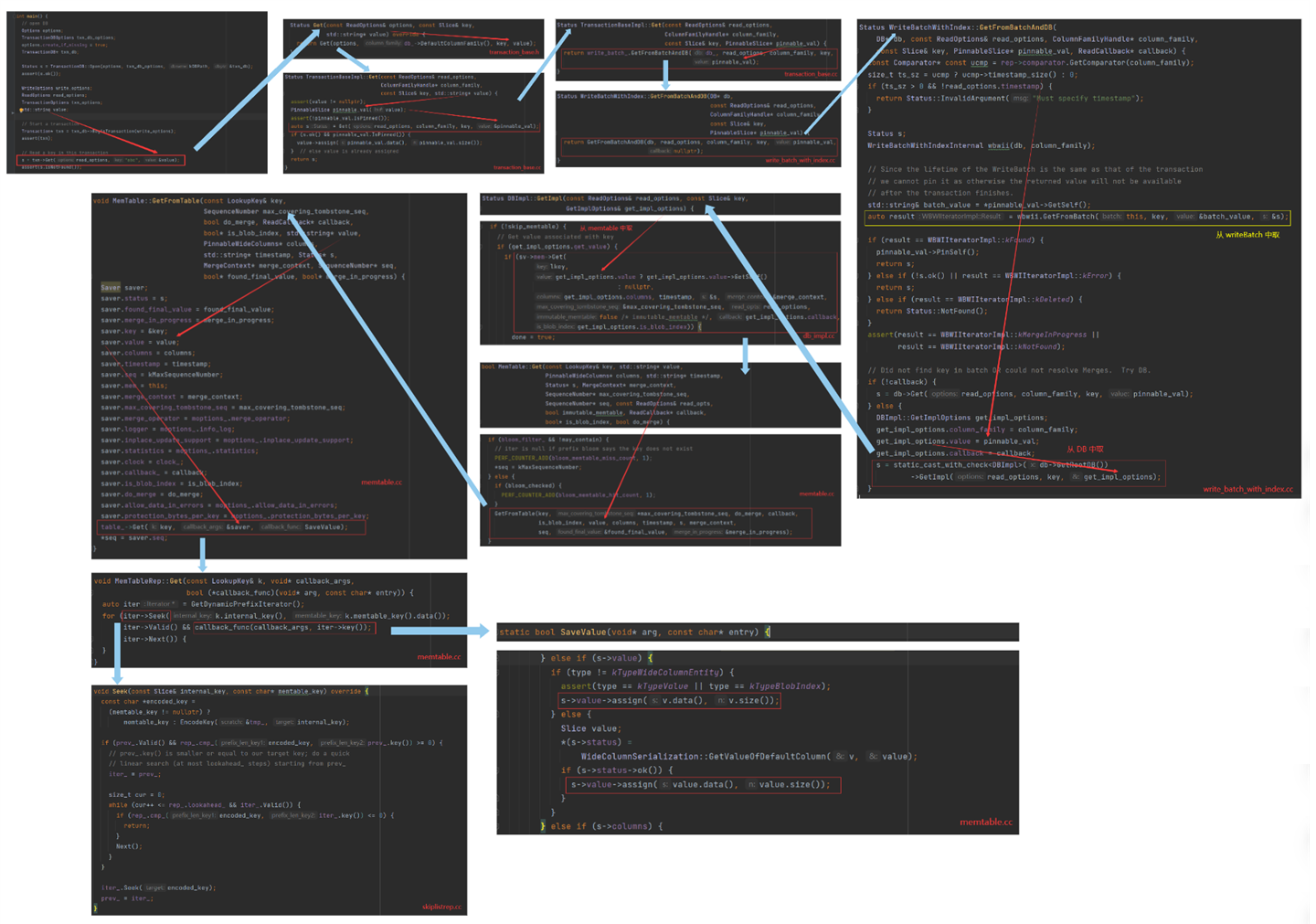
由此就可以回答上一章节遗留的问题了,saver.value 从始至终都指向了一个空值的 string,这个 string 是调用者用来保存读取结果 value 的,所以它并不是 nullptr。故 SaveValue 会在赋值前先判断 saver.value 是否为 nullptr,因为要确保调用者确确实实给它分配了一块空间用来存储,如果 saver.value 为 nullptr,则说明调用者根本没有分配空间来保存结果,当然不会在执行赋值了。
至此,RocksDB 的读框架以及在 memtable 的读操作就大致理完了,下一篇博客将关注在 immutable memtable 中的读取。
这篇关于RocksDB源码学习(二):读(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









