本文主要是介绍[大厂实践] Netflix容器平台内核panic可观察性实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在某些情况下,K8S节点和Pod会因为出错自动消失,很难追溯原因,其中一种情况就是发生了内核panic。本文介绍了Netflix容器平台针对内核panic所做的可观测性增强,使得发生内核panic的时候,能够导出信息,帮助排查问题。原文: Kubernetes And Kernel Panics
最近,我们为了减轻容器平台Titus客户(工程师,而不是最终用户)的痛苦,开始调查"孤儿(Orphaned)"pod。有些pod从不会结束,只能被垃圾收集,没有真正令人满意的最终状态。我们的服务任务(比如ReplicatSet)所有者不会太在意,但Batch用户会非常在意。如果没有真正的返回码,怎么才能知道重试是否安全?
即使只占系统中总pod的一小部分,这些孤儿pod对用户来说也是真正的痛苦。这些pod到底去哪儿了?为什么不见了?
本文展示了如何将最坏情况(内核panic)与Kubernetes(k8s)联系起来,并最终与我们的运维人员联系起来,这样我们就可以跟踪k8s节点是如何以及为什么消失的。
孤儿Pod从何而来?
因为底层k8s节点对象消失了,所以孤儿pod也消失了。一旦发生这种情况,GC[1]进程将删除该pod。在Titus上,我们运行自定义控制器来存储Pod和Node对象的历史,这样我们就可以保存一些解释并将其显示给用户。对应的失败模式在我们的UI中是这样的:
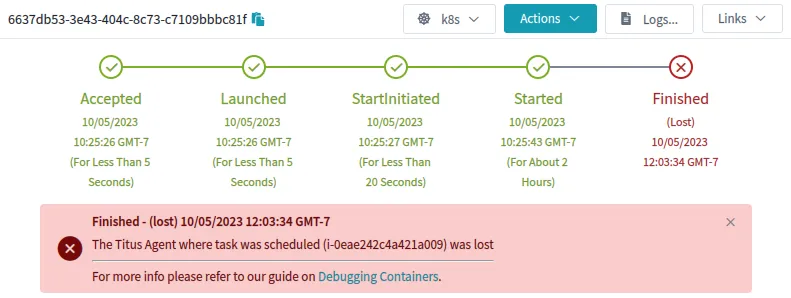
这是一种解释,但我和用户都不太满意。为什么代理丢失了?
丢失的节点从何而来?
节点可能因为任何原因消失,尤其是在"云"中。当这种情况发生时,通常是云供应商提供的k8s云控制器检测到实际的服务器(在我们的例子中是EC2实例)已经消失,并反过来删除k8s节点对象。这仍然没有真正回答为什么。
如何确保每个消失的实例都有原因,提供解释,并和pod关联在一起?这一切都始于一个注释:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"annotations": {
"pod.titus.netflix.com/pod-termination-reason": "Something really bad happened!",
...
创建存放这些数据的地方就是一个很好的开始。现在我们所要做的就是让GC控制器意识到这个注释,然后将其分发给任何可能导致pod或节点意外消失的进程中。添加注释(而不是修补状态)可以保留pod的其余部分。(我们还为终止原因添加了注释,并为标记添加了简短的reason-code)
pod-termination-reason注释对于填充人类可读的消息非常有用,例如:
-
"此pod被更高优先级的作业($id)抢占了" -
"由于底层硬件失败,必须终止此pod ($failuretype) " -
"这个pod必须被终止,因为$user在节点上运行sudo halt " -
"这个pod意外死亡,因为底层节点内核panic了!"
但是等等,我们如何为内核panic的节点注释pod呢?
捕获内核Panic
当Linux内核出现问题时,能做的就不多了。但是,如果可以发出某种"在我的最后一口气中,诅咒Kubernetes!"UDP数据包呢?
受这篇Google Spanner论文的启发,Spanner节点发出"最后一口气"UDP数据包来释放租约和锁,也可以配置服务器在内核panic时使用一个常用的Linux模块netconsole来做同样的事情。
配置Netconsole
事实上,Linux内核甚至可以发送带有字符串"kernel panic"的UDP数据包,而它正在panic,这有点令人惊讶。能做到这一点是因为netconsole需要配置实现填写好的整个IP头。没错,必须告诉Linux源MAC、IP和UDP端口是什么,以及目标MAC、IP和UDP端口是什么,实际上是在为内核构造UDP数据包。但是,有了这些准备工作,当时机成熟时,内核可以很容易的构造[2]数据包,并在系统崩溃时将其从(预配置的)网络接口中取出。幸运的是,netconsole-setup命令使设置变得非常简单,所有配置选项可以动态[3]设置,这样当端点发生变化时,就可以指向新的IP。
一旦设置完成,内核消息将在modprobe之后开始流动。想象一下,整个操作就像执行dmesg | netcat -u $destination 6666,只不过是在内核空间中。
Netconsole"最后的怒吼"数据包
通过netconsole设置,内核panic的最后怒吼看起来就像一组UDP数据包,就像人们可能期望的那样,其中UDP数据包的数据只是内核消息的文本。在内核panic的情况下,看起来像这样(每行一个UDP数据包):
Kernel panic - not syncing: buffer overrun at 0x4ba4c73e73acce54
[ 8374.456345] CPU: 1 PID: 139616 Comm: insmod Kdump: loaded Tainted: G OE
[ 8374.458506] Hardware name: Amazon EC2 r5.2xlarge/, BIOS 1.0 10/16/2017
[ 8374.555629] Call Trace:
[ 8374.556147] <TASK>
[ 8374.556601] dump_stack_lvl+0x45/0x5b
[ 8374.557361] panic+0x103/0x2db
[ 8374.558166] ? __cond_resched+0x15/0x20
[ 8374.559019] ? do_init_module+0x22/0x20a
[ 8374.655123] ? 0xffffffffc0f56000
[ 8374.655810] init_module+0x11/0x1000 [kpanic]
[ 8374.656939] do_one_initcall+0x41/0x1e0
[ 8374.657724] ? __cond_resched+0x15/0x20
[ 8374.658505] ? kmem_cache_alloc_trace+0x3d/0x3c0
[ 8374.754906] do_init_module+0x4b/0x20a
[ 8374.755703] load_module+0x2a7a/0x3030
[ 8374.756557] ? __do_sys_finit_module+0xaa/0x110
[ 8374.757480] __do_sys_finit_module+0xaa/0x110
[ 8374.758537] do_syscall_64+0x3a/0xc0
[ 8374.759331] entry_SYSCALL_64_after_hwframe+0x62/0xcc
[ 8374.855671] RIP: 0033:0x7f2869e8ee69
...
连接到Kubernetes
最后要连接的是Kubernetes (k8s),需要k8s控制器完成以下工作:
-
监听端口6666上的netconsole UDP数据包,观察来自节点的类似内核panic的情况。 -
在内核出现故障时,查找与传入netconsole数据包的IP地址相关联的k8s节点对象。 -
对于该k8s节点,找到绑定到它的所有pod,注释,然后删除这些pod。 -
对于k8s节点,注释节点,然后删除。
第1步和第2步可能是这样的:
for {
n, addr, err := serverConn.ReadFromUDP(buf)
if err != nil {
klog.Errorf("Error ReadFromUDP: %s", err)
} else {
line := santizeNetConsoleBuffer(buf[0:n])
if isKernelPanic(line) {
panicCounter = 20
go handleKernelPanicOnNode(ctx, addr, nodeInformer, podInformer, kubeClient, line)
}
}
if panicCounter > 0 {
klog.Infof("KernelPanic context from %s: %s", addr.IP, line)
panicCounter++
}
}
然后第3和第4步:
func handleKernelPanicOnNode(ctx context.Context, addr *net.UDPAddr, nodeInformer cache.SharedIndexInformer, podInformer cache.SharedIndexInformer, kubeClient kubernetes.Interface, line string) {
node := getNodeFromAddr(addr.IP.String(), nodeInformer)
if node == nil {
klog.Errorf("Got a kernel panic from %s, but couldn't find a k8s node object for it?", addr.IP.String())
} else {
pods := getPodsFromNode(node, podInformer)
klog.Infof("Got a kernel panic from node %s, annotating and deleting all %d pods and that node.", node.Name, len(pods))
annotateAndDeletePodsWithReason(ctx, kubeClient, pods, line)
err := deleteNode(ctx, kubeClient, node.Name)
if err != nil {
klog.Errorf("Error deleting node %s: %s", node.Name, err)
} else {
klog.Infof("Deleted panicked node %s", node.Name)
}
}
}
有了这些代码,一旦检测到内核故障,pod和节点就会立即消失。不需要等待任何GC进程。注释帮助记录发生在节点和pod上的事情:
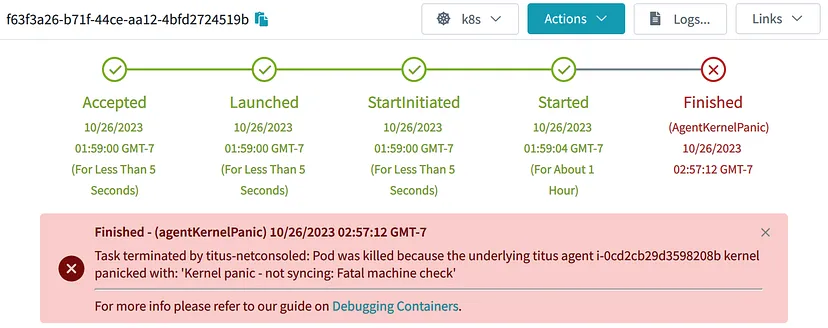
结论
将作业标记为由于内核panic而失败可能不会让客户满意。但当他们知道我们现在有必要的可观察性工具来开始修复这些内核panic时,就会感到满意!
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!
Pod garbage collection: https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-garbage-collection
[2]Linux netconsole.c: https://github.com/torvalds/linux/blob/94f6f0550c625fab1f373bb86a6669b45e9748b3/drivers/net/netconsole.c#L932
[3]Initialize netconsole at boot time: https://wiki.ubuntu.com/Kernel/Netconsole#Step_3:_Initialize_netconsole_at_boot_time
本文由 mdnice 多平台发布
这篇关于[大厂实践] Netflix容器平台内核panic可观察性实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






