本文主要是介绍前端预加载的3种方式 - 产品大佬都说好,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
公众号:程序员白特,可加前端群
概述
性能优化一直是个热门的话题,但是随着设备性能和网络速度的提升,需要做性能优化的项目可能并不是很多,所以每次做优化都是技术实践和累积的好机会。
性能优化的方式有很多,本文将从实例出发带你了解性能优化之预加载。
场景复现
页面内容和加载时序
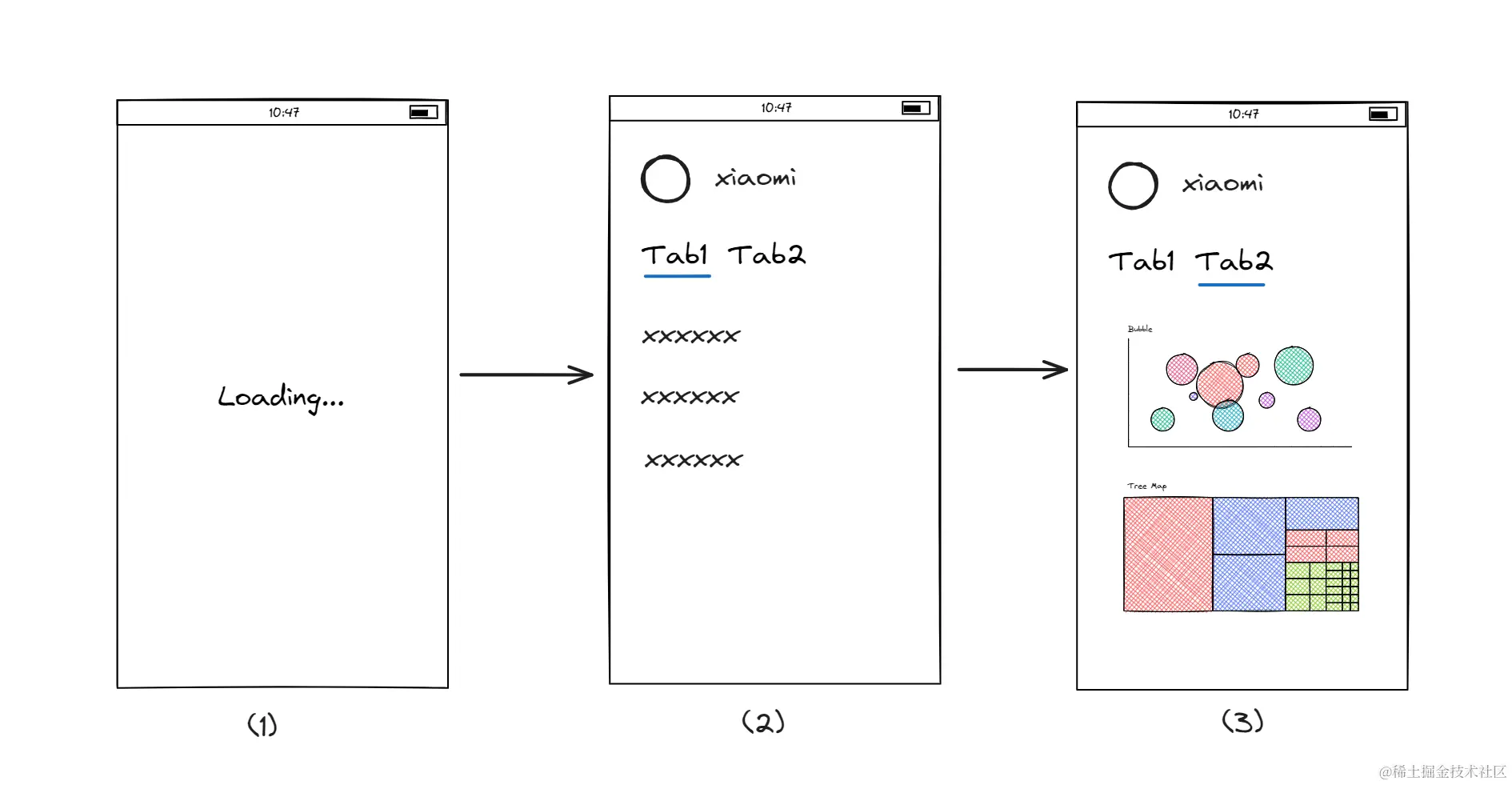
近期开发了一个移动端 H5 页面,页面大概如下:
- 一个普通的
loading页面,加载静态资源和请求接口 - 客户信息展示页,基础信息和
Tab1扩展信息展示 Tab2为数据可视化页面,展示一些图表
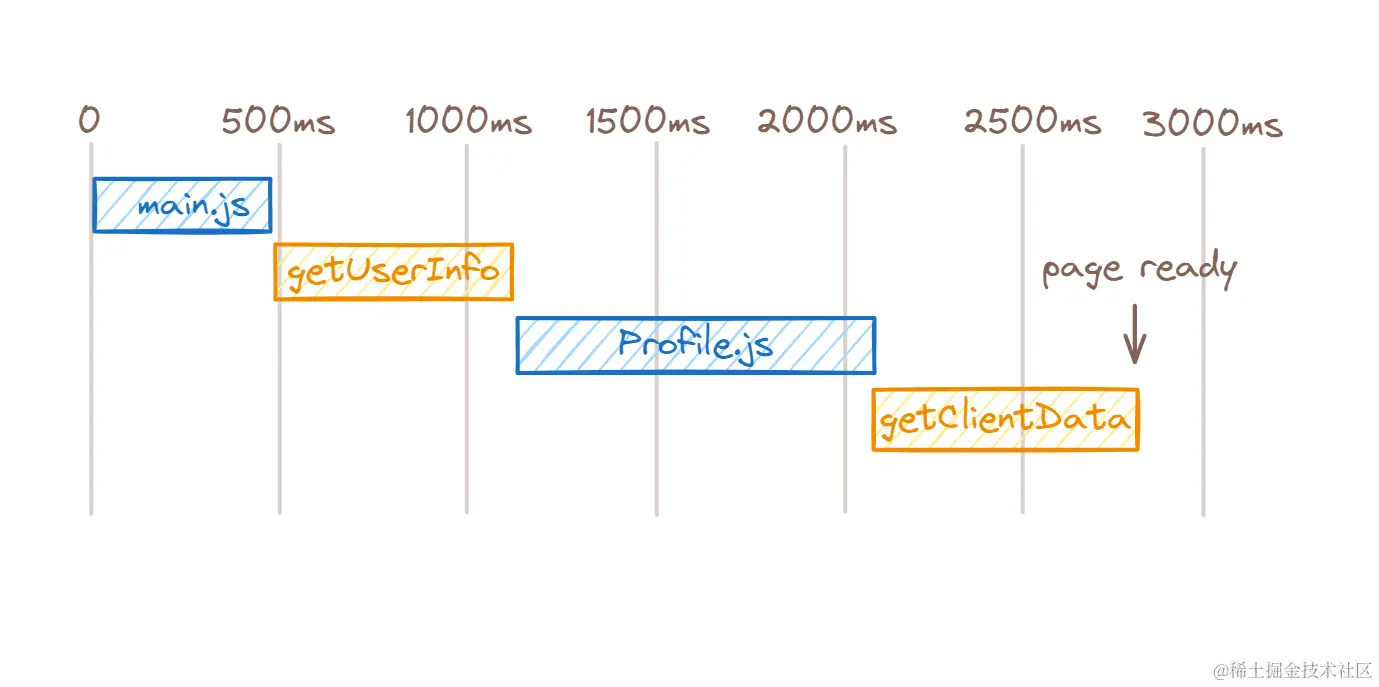
加载的时序如下:
- 先请求入口 JS 文件
main.js - 再请求登录用户信息接口
- 然后动态加载页面的 JS 文件
Profile.js - 最后请求客户相关数据接口,并展示页面
问题出现和分析
页面开发完成后,产品在验收环节提出了页面加载较慢的问题。
经过简单研究,初步梳理出了慢的几点原因:
- 移动端性能和网络原因影响,PC 端加载速度正常
- 接口请求返回较慢
- 静态资源加载慢
第一点移动端设备的情况总是比较复杂,无法改变;第二点需要服务端同学去优化;主要看第三点,具体分析后,得到了慢的原因:
- 前端加载时序整体是一个串行的状态,页面需要等待的时间较长
- 页面中使用到了图表库 Echarts,这个库相对比较大,即时按官方指南使用了按需加载,打包出来的体积还是比其他页面大许多
解决方案制定
对于第一点目前某些页面对用户信息有强依赖,所以都是等用户信息返回后,再去加载页面 JS,就造成了一个串行的结果。
可以通过用户信息获取和页面 JS 同时进行来优化,但是这样需要去修改对用户信息有强依赖的页面,影响范围较大,暂不考虑。
故采用另外一种方式解决并行问题,预加载页面 JS。
处理完第一点后的加载时序:
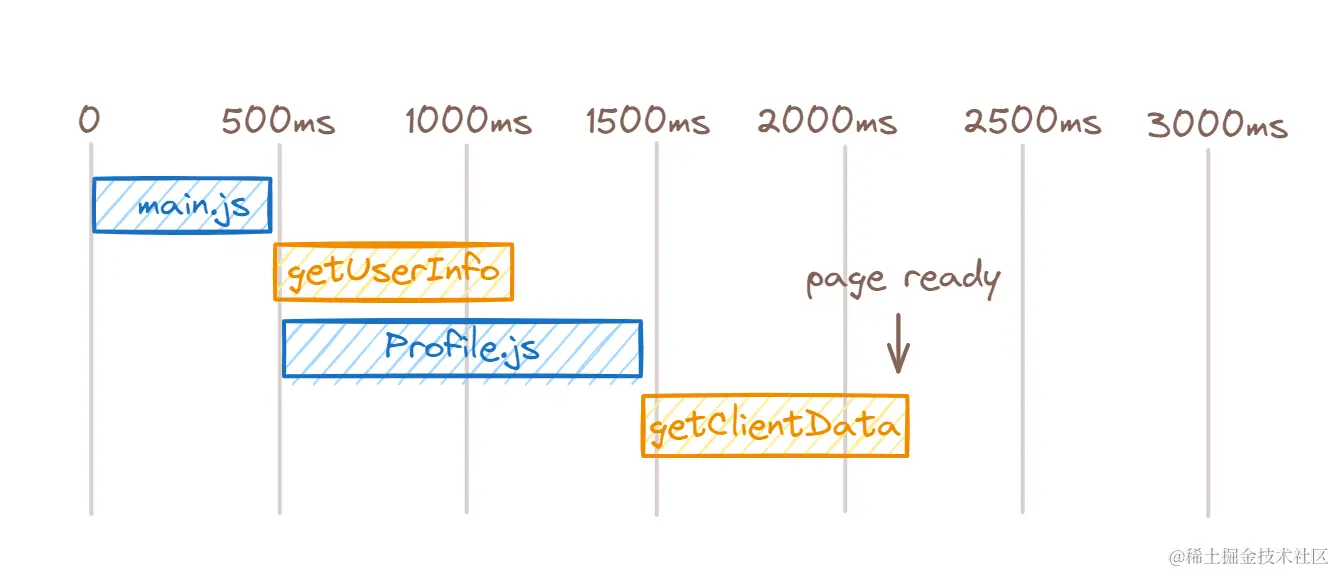
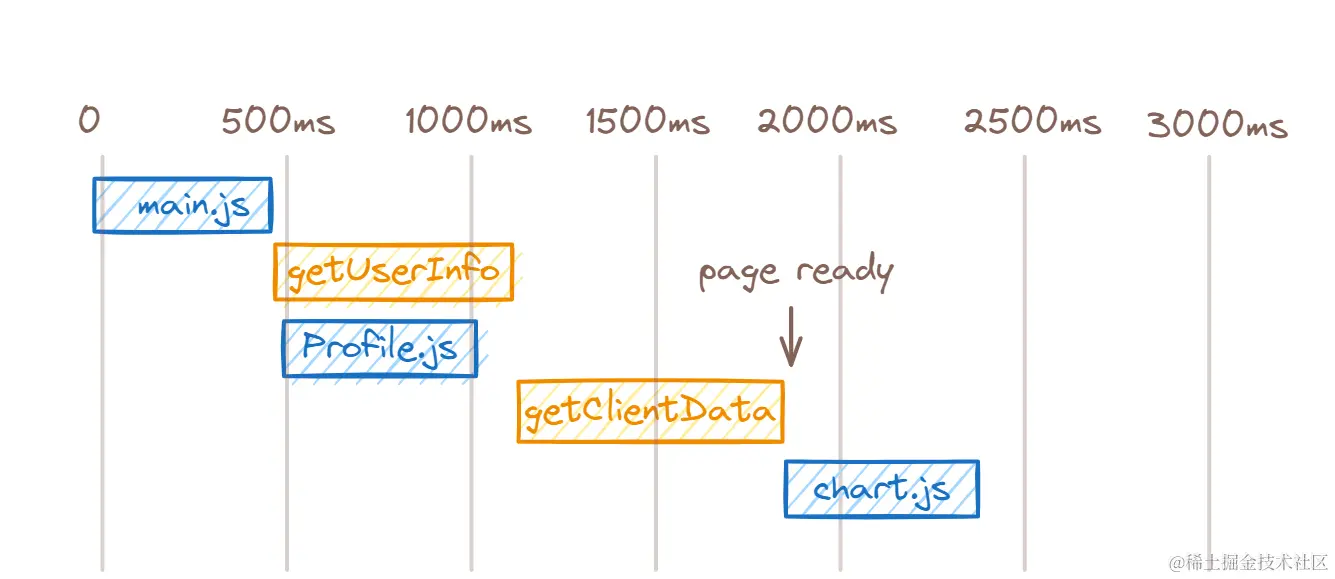
第二点就用动态加载 Echarts 组件来处理,并在第一个页面预加载这个组件来锦上添花,减少首页加载体积并在切换时能快速展示图表。
最终的加载时序:
技术优化
预加载的三种方式:
import动态加载,在某个节点import先发起,使用时可直接得到内容react-router的lazy属性,v6.4+ 支持webpack预加载,v4.6.0+ 支持
在开始前,我们先体验下预加载的效果。
- 无预加载
- 预加载

页面主要加载分为三步骤:
- 加载入口 main.js,请求登录用户信息接口
- 登录完成,加载页面 JS
- 请求 data 相关数据
可以看到有预加载的情况下,登录信息请求完成后页面就立即显示出来了。
import
import 函数是 ES2020 提案新增的功能,用于支持动态加载模块。
使用方法如下:
import * as mod from '/my-module.js'import('/my-module.js').then((mod2) => {console.log(mod === mod2)
})
在 React 项目中会配置 lazy 和 Suspense 使用,使用方法入如下:
import { lazy } from 'react';const MarkdownPreview = lazy(() => import('./MarkdownPreview.js'))function App() {return (<Suspense fallback="loading..."><h2>Preview</h2><MarkdownPreview /></Suspense>)
}
lazy 会将 import 方法返回对象的 default 值作为 React 节点返回,这样我们可以在 JSX 中直接渲染组件。同时 lazy 只有在尝试渲染该组件的时候,才会去调用 import 方法,所以是动态加载。
接下来看下项目中的 main.js 和动态加载路由配置:
// react-router
const config = [{path: '/home',component: React.lazy(() => import(/* webpackChunkName: 'IndexHome' */'@/pages/Home'))
}]// main.js 获取完用户信息后加载路由页面
import React, { useState, useEffect } from 'react'
import { Outlet } from 'react-router-dom'const LayoutPage = () => {const [useInfo, setUserInfo] = useState()const hasLogin = !!userInfouseEffect(() => {// ... getUserInfo}, [])return (<div>{hasLogin && <Outlet />}</div>)
}export default LayoutPage
支持预加载后代码如下:
// react-router 返回预加载函数
function lazyWithPreload(factory) {return {component: React.lazy(factory),preload: factory}
}const config = [{path: '/home',...lazyWithPreload(() => import(/* webpackChunkName: 'IndexHome' */'@/pages/Home'))
}]// main.js
import React, { useState, useEffect } from 'react'
import { Outlet, matchRoutes, useLocation } from 'react-router-dom'const LayoutPage = () => {const [useInfo, setUserInfo] = useState()const hasLogin = !!userInfoconst location = useLocation()useEffect(() => {// ... getUserInfo 同时发起预加载页面内容const matched = matchRoutes(routes, location) if (matched) {const pageRoute = matched[matched.length - 1]pageRoute.route?.preload?.()}}, [])return (<div>{hasLogin && <Outlet />}</div>)
}export default LayoutPage
可以看到代码中提供了 lazyWithPreload 方法,这方法中返回的 preload 方法,就是可以直接执行 import 操作。
预加载的操作就在于我们把 import 方法先调用了,这样页面 js 的加载就和请求登录用户信息是并行发起的。
react-router lazy 属性
react-router 在 v6.4+ 版本支持了 lazy 属性,该属性现实了动态加载页面,并且支持并行发起页面需要的接口数据请求。
使用方式如下:
- 使用支持 lazy 能力的路由创建方式
const router = createHashRouter(routerConfig)function App() {return <RouterProvider router={router} />
}
- 路由配置使用 lazy 属性
const routerConfig = [{element: <Layout />,children: [{ path: '/home', lazy: () => import('./pages/home') }]
}]
home/index.jsx文件改造,支持导出(loader, Component, ErrorBoundary)
export async function loader({ request }) {let data = await fetchData(request);return json(data);
}export function Component() {let data = useLoaderData();return (<div>{data}</div>)
}export function ErrorBoundary() {return 'error'
}
完成以上步骤,在访问 /home 路径的时候,代码会预加载页面 JS 和发起页面接口请求。
可以看到在页面显示的同时,data 数据也已经有了。
webpack 预加载
Webpack 4.6.0+ 支持了预加载能力,一个是 prefetch,一个是 preload。
prefetch: 资源在未来的某个时刻使用,在核心代码加载完成之后带宽空闲的时候再去加载需要用到的模块代码
preload: 资源在当前页面中也会使用,和核心代码文件一起去加载的。
import(/* webpackPrefetch: true */ './path/to/LoginModal.js')import(/* webpackPreload: true */ './path/to/LoginMdal.js')
webpack 预加载和路由无关联,也就是说不管加载什么页面的时候,这段 JS 都会预加载,这可能会出现加载资源浪费情况。
小结
综合上述技术方案和当前项目技术栈考虑,最终使用了第一种方案。
总结
本文从示例出发,带你了解了如何根据项目具体情况做对应的优化。预加载知识你可以亲自去体验下,会有更深的理解。
这篇关于前端预加载的3种方式 - 产品大佬都说好的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






