本文主要是介绍呆萝卜一面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2019.5.16晚
1自我介绍
2bug怎么解决:order的bug,

3对java的了解
4.string a ,b a+b,字符串如何连接,,创建a+b之后,a,b对象还在吗,
1)字符串拼接
1. plus方式
当左右两个量其中有一个为String类型时,用plus方式可将两个量转成字符串并拼接。
String a="";
int b=0xb;
String c=a+b;
2. concat方式
当两个量都为String类型且值不为null时,可以用concat方式。
String a="a";
String b="b";
String c= a.concat(b);
理论上,此时拼接效率应该最高,因为已经假定两个量都为字符串,做底层优化不需要额外判断或转换,而其他方式无论如何优化,都要先走到这一步。
3. append方式
当需要拼接至少三个量的时候,可以考虑使用StringBuffer#append()以避免临时字符串的产生
StringBuffer buf=new StringBuffer()
buf.append("a");
if(someCondition){
buf.append("b");
}
buf.append("c");
String d=buf.toString();
当a,b,c拼接起来会很长时,可以给在构造器中传入一个合适的预估容量以减少因扩展缓冲空间而带来的性能开销。
StringBuffer buf=new StringBuffer(a.length()+b.length()+c.length());
JDK对外提供的一些涉及可append CharSequence的参数或返回值类型往往是StringBuffer类型,毕竟安全第一,而StringBuffer大多数情况(包括append操作)线程安全。
若不会出现多线程同时对一实例并发进行append操作,建议使用非线程安全的StringBuilder以获得更好性能
5对象存储在哪里?堆、栈的区别?为什么栈要销毁?

所以堆与栈的区别很明显:
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
3.栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
6作用域说下,public/private/protect的作用范围?

7单继承类、多继承接口,说下为什么这么设计?
因为防止多继承类,如果有同名方法或者属性,不知道调用哪个类的方法或者属性,
之所以可以多继承接口是因为接口只有抽象方法,调用的时候都是由具体的子类实现的,因此不存在调用歧义的情况。。
8考下你数据结构,都知道啥数据结构?你实现一个栈的数据结构?
https://www.cnblogs.com/littlepanpc/p/3436419.html
9算法把?排序知道啥?冒泡知道吗?
原理:比较两个相邻的元素,将值大的元素交换至右端。
思路:依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。重复第一趟步骤,直至全部排序完成。
第一趟比较完成后,最后一个数一定是数组中最大的一个数,所以第二趟比较的时候最后一个数不参与比较;
第二趟比较完成后,倒数第二个数也一定是数组中第二大的数,所以第三趟比较的时候最后两个数不参与比较;
依次类推,每一趟比较次数-1;
10数据库吧?怎么建表?数据类型有哪些?varchar和char的区别?timestamp和datetime的区别?存的时间范围的区别?用哪一个好些?int占几个字节?java int占几个字节?(4个啊,我当时脑袋热,居然答得是8,,888)
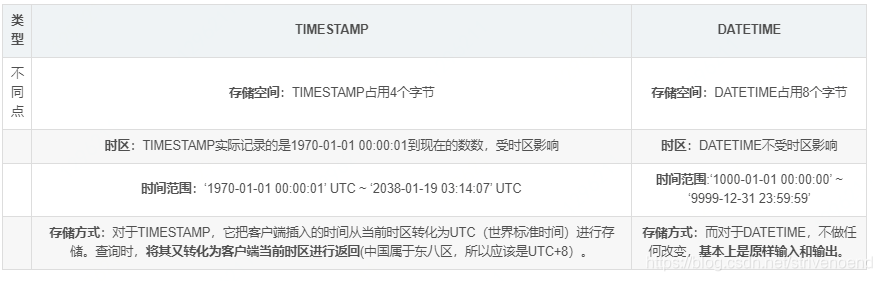
datetime
1. 占用8个字节
2. 允许为空值,可以自定义值,系统不会自动修改其值。
3. 实际格式储存(Just stores what you have stored and retrieves the same thing which you have stored.)
4. 与时区无关(It has nothing to deal with the TIMEZONE and Conversion.)
5. 可以在指定datetime字段的值的时候使用now()变量来自动插入系统的当前时间。
6.datetime是可以设置默认值的, DEFAULT CURRENT_TIMESTAMP在mysql5.7中亲测可用
结论:datetime类型适合用来记录数据的原始的创建时间,因为无论你怎么更改记录中其他字段的值,datetime字段的值都不会改变,除非你手动更改它。
timestamp
1. 占用4个字节
2. 允许为空值,但是不可以自定义值,所以为空值时没有任何意义。
3. TIMESTAMP值不能早于1970或晚于2037。这说明一个日期,例如'1968-01-01',虽然对于DATETIME或DATE值是有效的,但对于TIMESTAMP值却无效,如果分配给这样一个对象将被转换为0。
4.值以UTC格式保存( it stores the number of milliseconds)
5.时区转化 ,存储时对当前的时区进行转换,检索时再转换回当前的时区。
6. 默认值为CURRENT_TIMESTAMP(),其实也就是当前的系统时间。
7. 数据库会自动修改其值,所以在插入记录时不需要指定timestamp字段的名称和timestamp字段的值,你只需要在设计表的时候添加一个timestamp字段即可,插入后该字段的值会自动变为当前系统时间。
8. 默认情况下以后任何时间修改表中的记录时,对应记录的timestamp值会自动被更新为当前的系统时间。
9. 如果需要可以设置timestamp不自动更新。通过设置DEFAULT CURRENT_TIMESTAMP 可以实现。
修改自动更新:
`field_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
修改不自动更新
`field_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
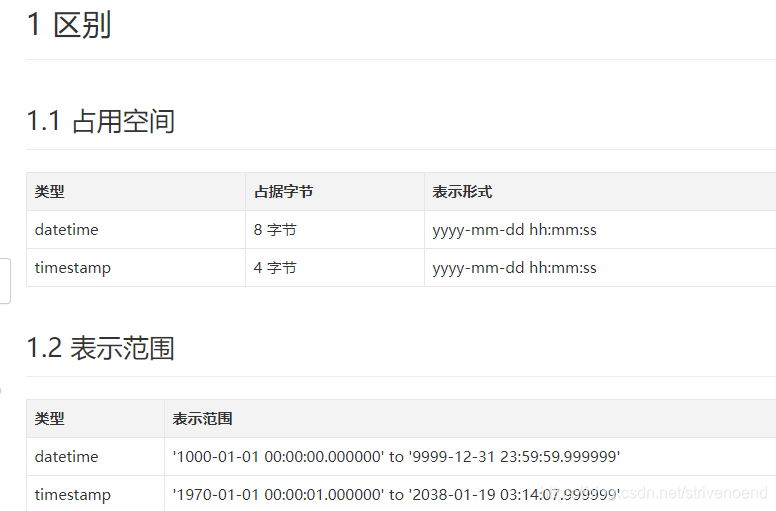
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
数值类型
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
11最大的优点?
12你有啥问题?我问了broker挂了,redis没及时更新怎么办?
zookeeper
1.ZooKeeper是什么?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
2.ZooKeeper提供了什么?
1)文件系统
2)通知机制
3.Zookeeper文件系统
每个子目录项如 NameService 都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
<ignore_js_op>
4.Zookeeper通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
5.Zookeeper做了什么?
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
6.Zookeeper命名服务
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
7.Zookeeper的配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好
<ignore_js_op>
8.Zookeeper集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
<ignore_js_op>
9.Zookeeper分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
<ignore_js_op>
10.Zookeeper队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
11.分布式与数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
12.Zookeeper角色描述
<ignore_js_op>
13.Zookeeper与客户端
<ignore_js_op>
14.Zookeeper设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2.可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
15.Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
16.Zookeeper 下 Server工作状态
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
17.Zookeeper选主流程(basic paxos)
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
1.选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2.选举线程首先向所有Server发起一次询问(包括自己);
3.选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4.收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5.线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图所示:
<ignore_js_op>
18.Zookeeper选主流程(fast paxos)
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。
<ignore_js_op>
19.Zookeeper同步流程
选完Leader以后,zk就进入状态同步过程。
1. Leader等待server连接;
2 .Follower连接leader,将最大的zxid发送给leader;
3 .Leader根据follower的zxid确定同步点;
4 .完成同步后通知follower 已经成为uptodate状态;
5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
<ignore_js_op>
20.Zookeeper工作流程-Leader
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING 消息是指Learner的心跳信息;
REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;
ACK消息是 Follower的对提议的回复,超过半数的Follower通过,则commit该提议;
REVALIDATE消息是用来延长SESSION有效时间。
<ignore_js_op>
21.Zookeeper工作流程-Follower
Follower主要有四个功能:
1.向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并进行处理;
3.接收Client的请求,如果为写请求,发送给Leader进行投票;
4.返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
3 .COMMIT消息:服务器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
<ignore_js_op>
好了,以上就是我对zookeeper的 理解了,以后我还会继续为大家更新新的技术请大家期待吧!!!
这篇关于呆萝卜一面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!