本文主要是介绍Redis(十二)Bigkey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 游标案例
- 生成100万测试数据key
- 生产上限制keys */flushdb/flushall等危险命令
- 不使用keys *:scan
- Biigkey案例
- 多大算大
- 发现bigkey
- 渐进式删除
- 生产调优
- 示例问题
游标案例
生成100万测试数据key
shell:
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;
cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
生产上限制keys */flushdb/flushall等危险命令
通过配置设置禁用这些命令,redis.conf在SECURITY这一项中 自
# Example:
#
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#
# It is also possible to completely kill a command by renaming it into
# an empty string:
#
# rename-command CONFIG ""rename-command keys ""rename-command flushdb ""
#
不使用keys *:scan
SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组,
第一个元素是用于进行下一次迭代的新游标,
第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
scan 0 match * count 1

Biigkey案例
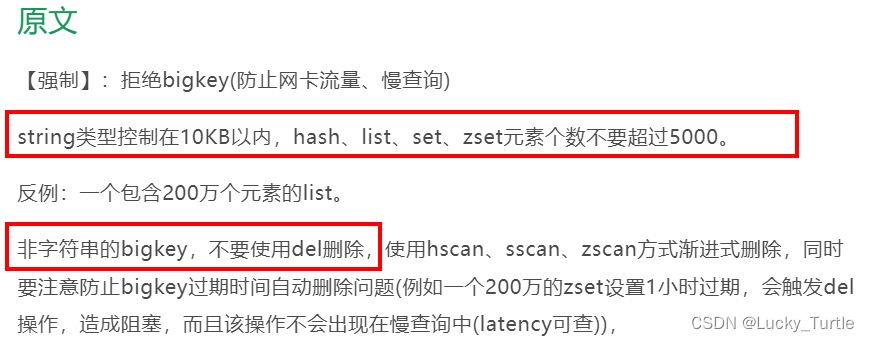
多大算大
来源:阿里云Redis规范
发现bigkey
redis-cli --bigkeys -a 111111
好处
给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
不足
想查询大于10kb的所有key,–bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
# 每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
计算每个键值
https://redis.com.cn/commands/memory-usage.html

渐进式删除
- String
一般用del,如果过于庞大unlink
- hash
使用hscan每次获取少量field-value,再使用hdel删除每个field
- list
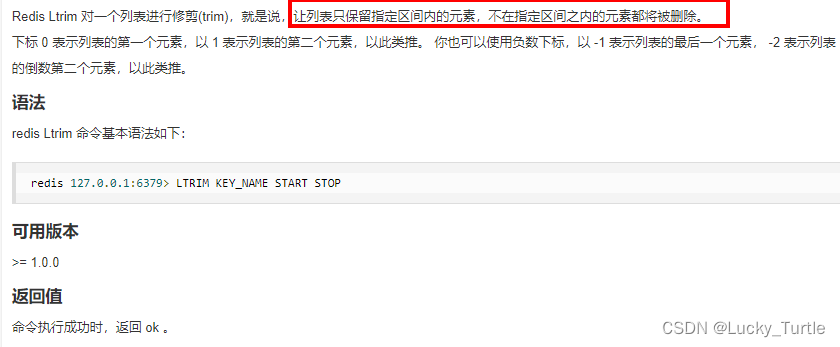
使用ltrim渐进式逐步删除,直到全部删除完成

- set
使用sscan每次获取部分元素,再使用srem命令删除每个元素

- zset
使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素

生产调优
redis.conf
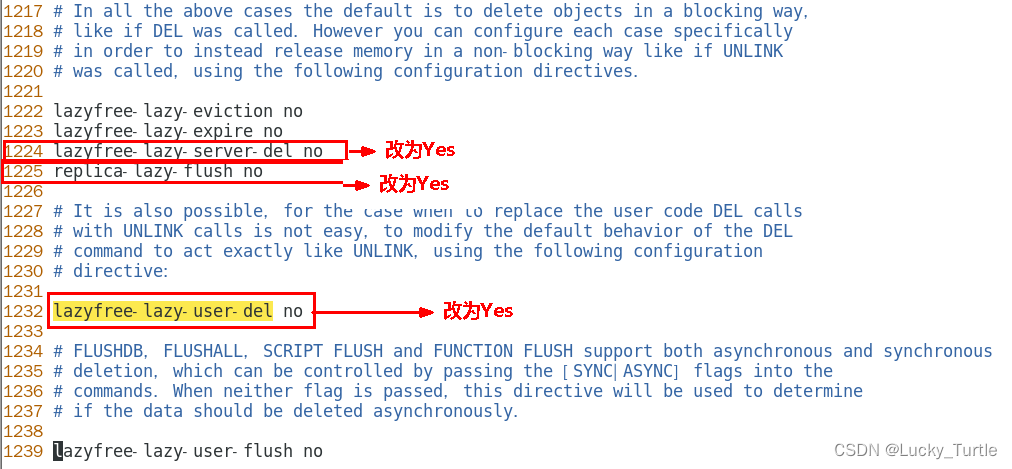
LAZY FREEING

示例问题
-
阿里广告平台,海量数据里查询某一固定前缀的key
-
小红书,你如何生产上限制keys */flushdb/flushall等危险命令以防止误删误用?
-
美团,MEMORY USAGE 命令你用过吗?
-
BigKey问题,多大算big?你如何发现?如何删除?如何处理?
-
BigKey你做过调优吗?惰性释放lazyfree了解过吗?
-
Morekey问题,生产上redis数据库有1000W记录,你如何遍历?key*可以吗?
这篇关于Redis(十二)Bigkey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





