本文主要是介绍内存刷脏机制触发的系统故障案例一则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关键词
- linux、centos
- cpu load、cpu iowait、sar监控、大页内存
-
vm.dirty_background_ratio、vm.dirty_ratio、vm.min_free_kbytes
There are many things that can not be broken!
如果觉得本文对你有帮助,欢迎点赞、收藏、评论!
一、问题现象
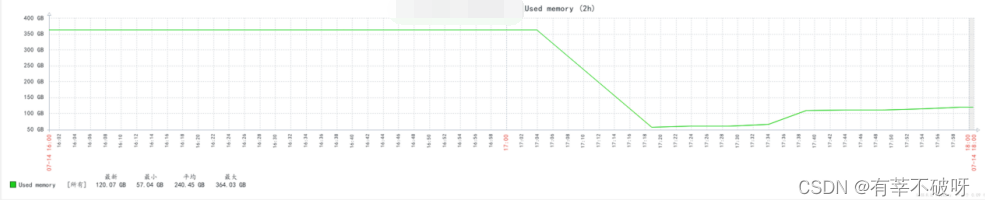
某数据库主机接连在几天里出现莫名hang死现象,造成业务中断,故障时间段,出现数据库连接数升高,cpu有陡增,cpu iowait time陡增,从监控曲线看cpu load负载过高,并伴随有大量的IO操作、事务等待会话、tps以及慢SQL,由于负载升高导致数据库自动主从切换失败,造成业务一定的中断影响。
二、问题分析
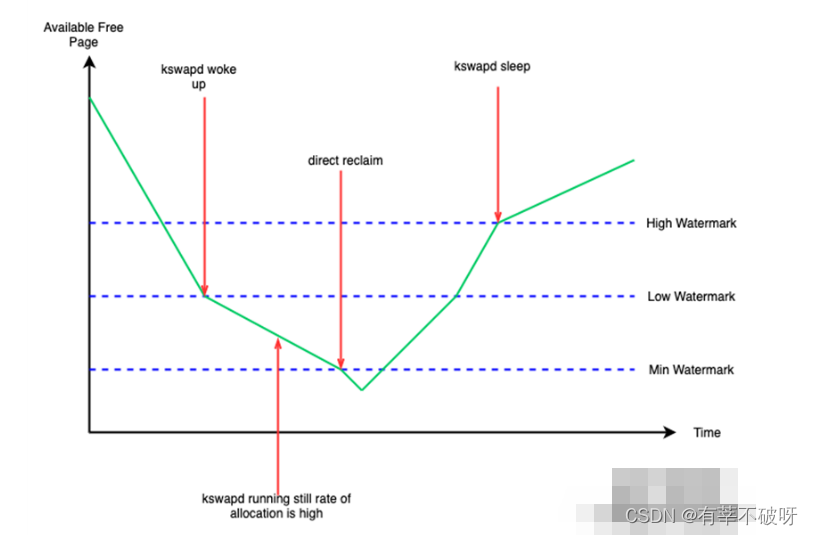
1、在集中复盘这几次故障中,发现故障主机几次故障之前出现过剩余内存严重不足情况,主机内存:377G,几乎耗尽,将故障原因怀疑的方向定位在是zone内存剩余达到min水位线导致直接内存回收,用户申请内存被阻塞,只有内核态可以正常申请剩余内存。
这种情况下,系统中剩余的内存极少,少到可能连回收内存操作本身需要的内存都不够,当 free 内存降到了 min 水线以下,此时如果操作系统忽然需要通过伙伴系统为用户进程分配一大块内存,或者需要创建一个很大的缓冲区,而当时系统中的内存没有办法提供足够多的物理内存以满足这种内存请求,这时候,操作系统就必须尽快进行页面回收操作,以便释放出一些内存空间从而满足上述的内存请求,这种页面回收方式也被称作"直接页面回收",这个过程会阻塞申请内存的进程,被阻塞进程的内存分配延迟就会提高,从而感受到卡顿。
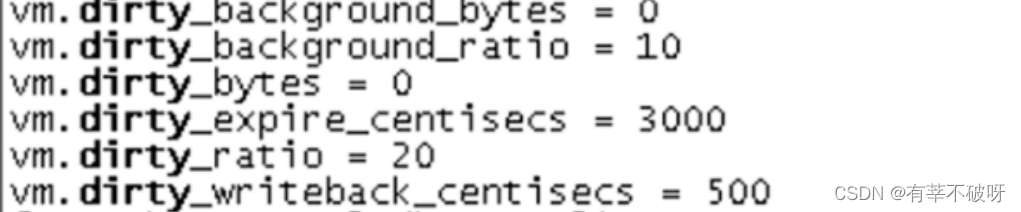
随后检查操作系统内存回收上的参数配置情况,发现此时的脏页vm.dirty_ratio过小,在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
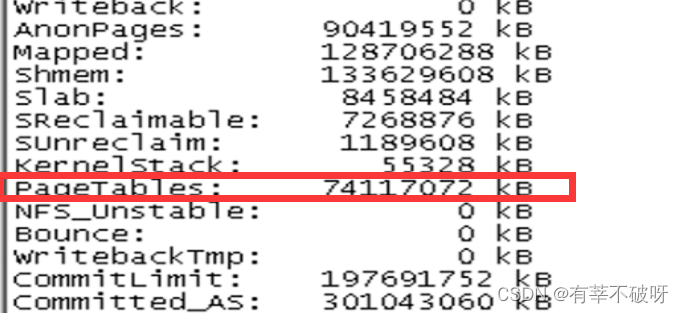
2、同时发现主机pagetables达到70G以上,建议数据库配置大页。使用大页(huge page)能够缩小page tables,减少cpu在内存管理上的的系统开销,提高性能。
三、处理过程
1、调整刷脏配置
vm.dirty_background_ratio = 50
vm.dirty_ratio = 80
vm.min_free_kbytes 为4G
2、配置大页,降低pagetables占用内存。
四、知识拓展
1、sysctl中的那些参数控制页高速缓存的参数
- vm.vfs_cache_pressure (默认值 = 100)
- 默认值vfs_cache_pressure=100,在回收页高速缓存(page cache)和交换缓存(swap cache)时,内核会以"相对公平"的比例回收dentries和inodes。
- 调整内核更趋向于回收内存中保存的目录项缓存(dentry)和索引节点对象 (inode objects)。
- 减少vfs_cache_pressure值,会使内核更倾向于保留目录项对象(dentry)以及索引节点缓存(inode caches); 增加vfs_cache_pressure 超过100 会使内核更倾向于释放目录项对象(dentry)以及索引节点缓存(inode caches)。
- 可以通过增加vfs_cache_pressure的值,来使内核更倾向于释放上述缓存,从而限制页高速缓存(page cache)的大小。
- vm.dirty_background_ratio (默认值 = 10)
- 此参数的值代表脏页占总内存的百分比, 当系统中脏页数量达到此值时,内核线程pdflush开始把脏页数据写入存储。
- 可以通过减少此值,来使pdflush进程更早把脏页写入存储,从而限制页高速缓存的大小。
- vm.dirty_ratio (默认值 = 20)
- 这个参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(默认值20%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外部存储);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
- 减少此值可使 系统更早来处理内存中的脏页,从而限制页高速缓存的大小。
- vm.dirty_writeback_centisecs (Red Hat Enterprise Linux 4 & 5: 默认值 = 499, Red Hat Enterprise Linux 6 and 7: 默认值 = 500)
- pdflush进程会定时被唤醒,把脏页中的数据写入硬盘。单位是 1/100 秒。缺省数值是500,也就是pdflush进程5秒钟会被唤醒一次。
- 减少此值可以更频繁的唤醒pdflush进程来处理脏页, 从而限制页高速缓存的大小。
- vm.dirty_expire_centisecs (Red Hat Enterprise Linux 4 and 5: 默认值= 2999, Red Hat Enterprise Linux 6 and 7: 默认值 = 3000)
- 这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,被唤醒的pdflush进程就开始考虑写到磁盘中去。单位是 1/100秒。缺省是 30000,也就是 30 秒的数据就算旧了,pdflush进程被唤醒后,将会把“旧”的数据写入磁盘。
- 减少此值意味着脏页会更快变“旧”,并被pdflush进程写入磁盘,从而限制页高速缓存的大小。
- vm.swappiness (RHEL 5 and 6:默认值 = 60, RHEL 7:默认值 = 30)
- 此参数控制内核是否更趋向于交换非活动内存页页至交换分区(此值越高,代表非活动内存页越可能被交换至交换分区)。
- 减少此值使内核更倾向于保持非活动内存页在物理内存中,从而释放页高速缓存中的页, 从而限制页高速缓存的大小。
2、如何查看你的脏页刷脏情况
使用sar命令,重点关注pgscank指标,格式
sar -B 1 5

pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
majflt/s:每秒钟产生的主缺页数 pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被 kswapd 扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从 cache 中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank + pgscand)的百分比
这篇关于内存刷脏机制触发的系统故障案例一则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



