本文主要是介绍小林Coding_操作系统_读书笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、硬件结构
1. CPU是如何执行的
冯诺依曼模型:中央处理器(CPU)、内存、输入设备、输出设备、总线
CPU中:寄存器(程序计数器、通用暂存器、指令暂存器),控制单元(控制CPU工作),逻辑运算单元(运算)
总线:控制总线(发信号),内存总线(指定内存地址),数据总线(内存读写)
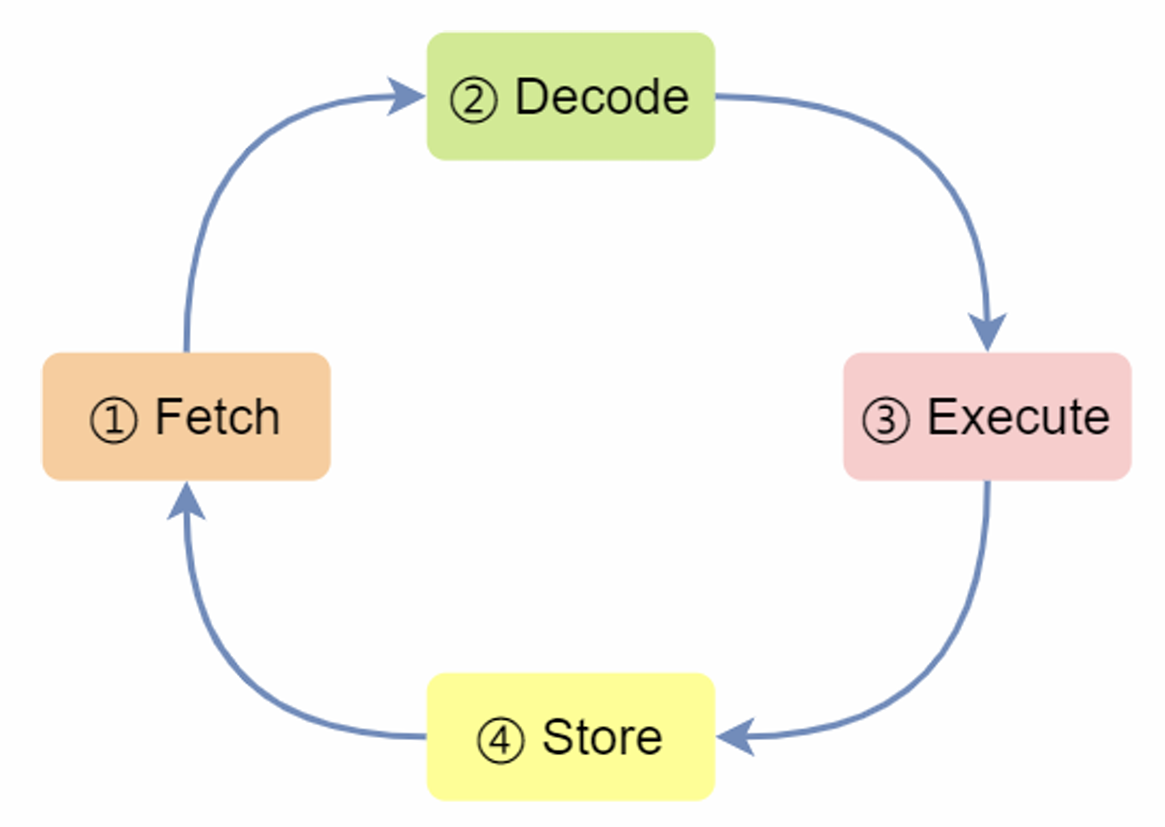
CPU 执行程序的过程:
第一步,CPU读取“程序计数器”中指令的地址,然后“控制单元”操作“地址总线”指定需要访问的内存地址,接着通知内存设备准备数据,通过“数据总线”将指令数据传给CPU,CPU收到内存传来的数据后,将指令数据存到“指令寄存器”。
第二步,CPU分析“指令寄存器”中的指令,确定指令的类型和参数,计算类型的指令交给“逻辑运算单元”运算;存储类型的指令交由“控制单元”执行;
第三步,CPU执行完指令后,“程序计数器”自增,表示指向下一条指令。自增的大小,由CPU位宽决定(如32位的CPU,指令是4个字节,需要4个内存地址存放,自增 4);
时钟周期和CPU主频:
每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期。不同指令消耗的时钟周期不同。对于程序的CPU执行时间,可以拆解成CPU时钟周期数(CPU Cycles)和时钟周期时间(Clock Cycle Time)的乘积。
![]()
时钟周期时间就是CPU主频。
32位和64位的区别:
只有运算大数字的时候,64位CPU的优势才能体现出来,否则和32 位CPU的计算性能相差不大。
64位CPU可以寻址更大的内存空间。
操作系统分成32位和64位,其代表意义就是操作系统中程序的指令是多少位。
2. 存储器的结构层次
存储器的存储结构:
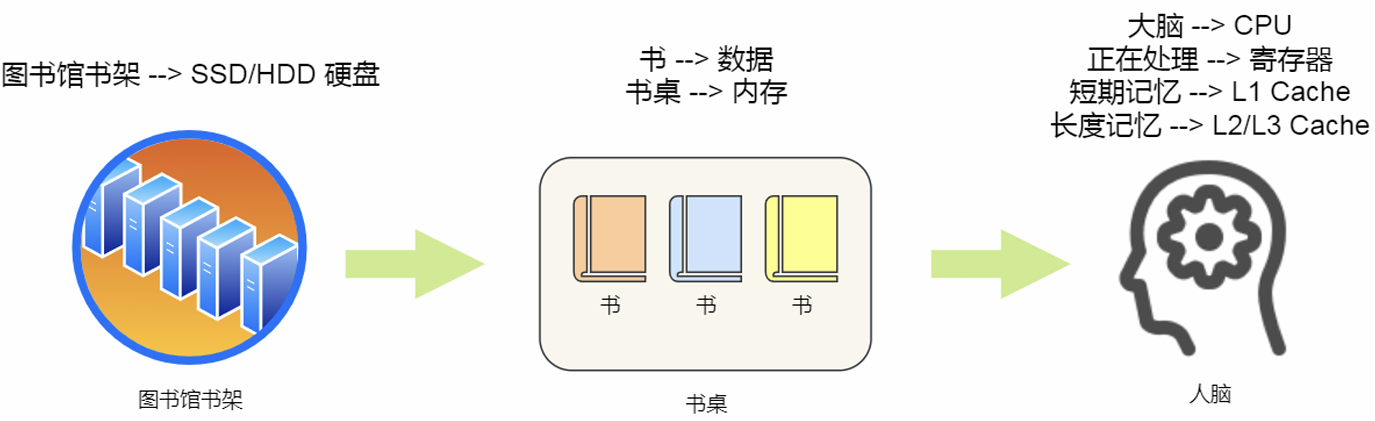
不同存储器之间性能差距很大,分级的目的是构造缓存体系。
寄存器:
32位CPU中寄存器存4字节,64位CPU中寄存器中存8字节。一般要求在半个CPU时钟周期完成读写(2GHz主频,时钟周期1/2G,也就是0.5ns)
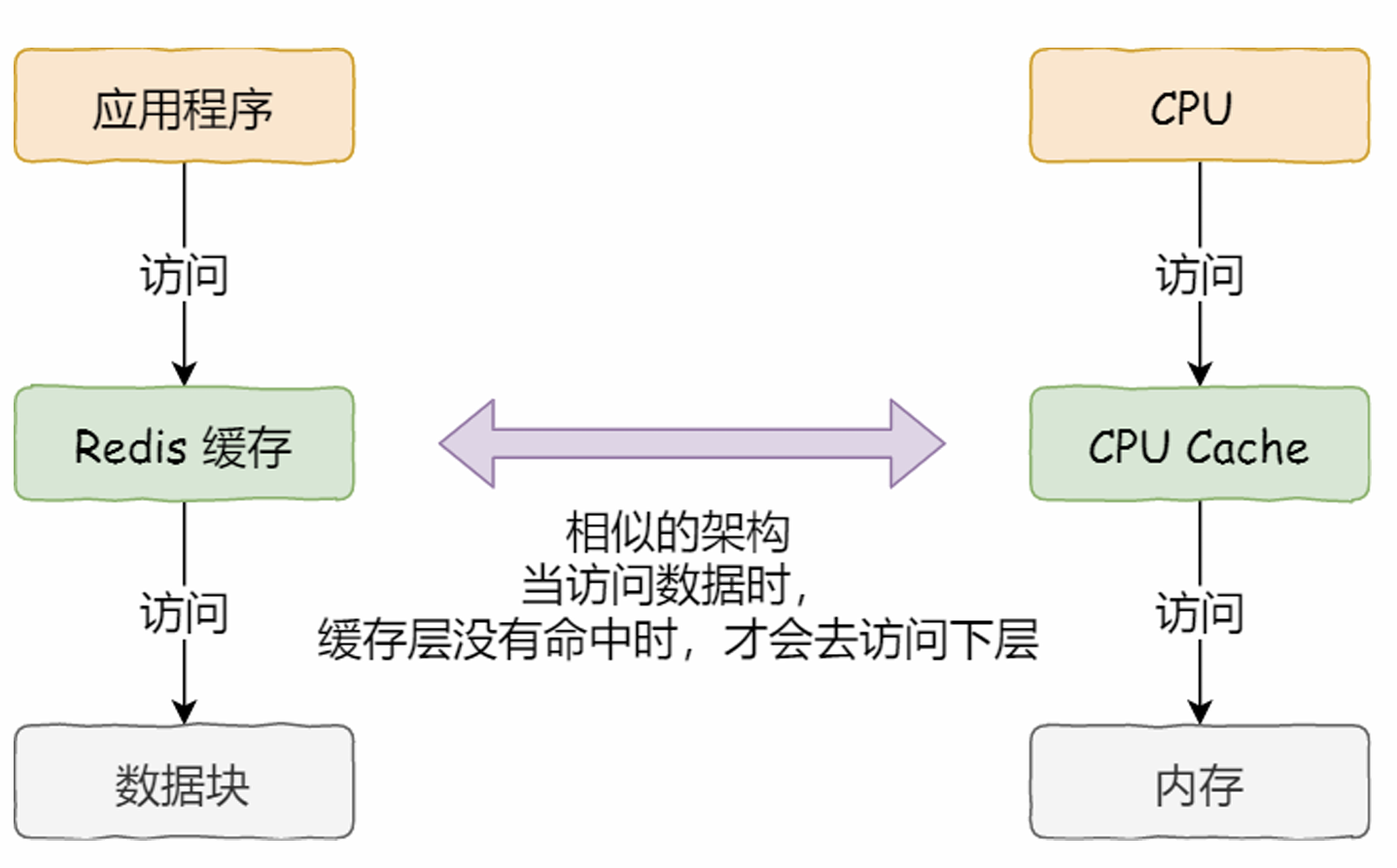
CPU Cache:
SRAM(Static Random-Acess Memory)静态随机存储器,只要有电,数据就可以保持存在。
L1高速缓存:通常分为指令缓存、数据缓存,访问时间一般是2~4个时钟周期,大小在几十KB到几百KB不等。
L2高速缓存:访问时间10~20个时钟周期,大小几百KB到几MB不等。
L3高速缓存:通常是多个核心共用,访问速度是20~60个时钟周期,大小是几MB和几十MB。
内存:
DRAM(Dynamic Random-Access Memory) 存储一个 bit 数据,只需要一个晶体管和一个电容,但是因为数据存储在电容里,电容会不断漏电,所以需要“定时刷新”电容,才能保证数据不会被丢失,这就是DRAM 之所以被称为「动态」存储器的原因,内存访问速度200~300个时钟周期。
SSD/HDD硬盘:
这两个存储器的结构和内存相似,但是其中的数据在断电后仍旧存在,内存比SSD快10~1000倍,比HDD(机械硬盘物理读写)快10W倍。
3. Cache的读取过程、提升缓存命中率
CPU Cache的数据结构和读取过程:
CPU Cache从内存中读取数据,按块读取,Cache Line(缓存块)。
比如,有一个int array[100]的数组,当载入array[0]时,由于这个数组元素的大小在内存只占 4 字节,不足 64 字节,CPU就会顺序加载数组元素到array[15]。
直接映射Cache:一个内存的访问地址,包括组标记(Tag)、CPU Line索引(Index)、偏移量(Offset)这三种信息。而对于CPU Cache里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。

CPU分支预测器:如果分支预测可以预测(比如连续50次if判断都是true)接下来要执行if里的指令,还是else指令的话,就可以“提前”把这些指令放在指令缓存中,这样CPU可以直接从Cache读取到指令,执行速度就会很快。在C/C++中编译器提供了likely和unlikely这两种宏进行分支预测(CPU自身的动态分支预测就是比较准的)。
如何提升多核CPU的缓存命中率:
了解了上面的读取过程,不难想到,如果一个进程在同一个核心上执行,那么速度就会更快(缓存命中率更高)。Linux上提供了sched_setaffinity方法,来将线程绑定到某个核心。
4. CPU缓存一致性
写直达和写回:
写直达:把数据同时写入内存和Cache中,这称为写直达(Write Through),如果在Cache,就先更新Cache,再写在内存;如果不在,就直接写到内存(不过这样性能会较差)。
写回:在写回(Write Back)中,写时,新的数据仅仅被写入Cache Block,只有当修改过的Cache Block“被替换”时,才需要写到内存中,减少了数据写回内存的频率。只有在缓存不命中,同时数据对应的Cache Block标记为脏,才会将数据写到内存中。而在缓存命中时,写入Cache后,把该数据对应的Cache Block标记为脏(如果大量缓存命中,就不需要频繁写内存)。
为了确保缓存一致性:写传播(Write Propagation,确保数据更新)、事务的串行化(Transaction Serialization,确保数据变化的顺序)。
写传播和事务串行化如何实现:
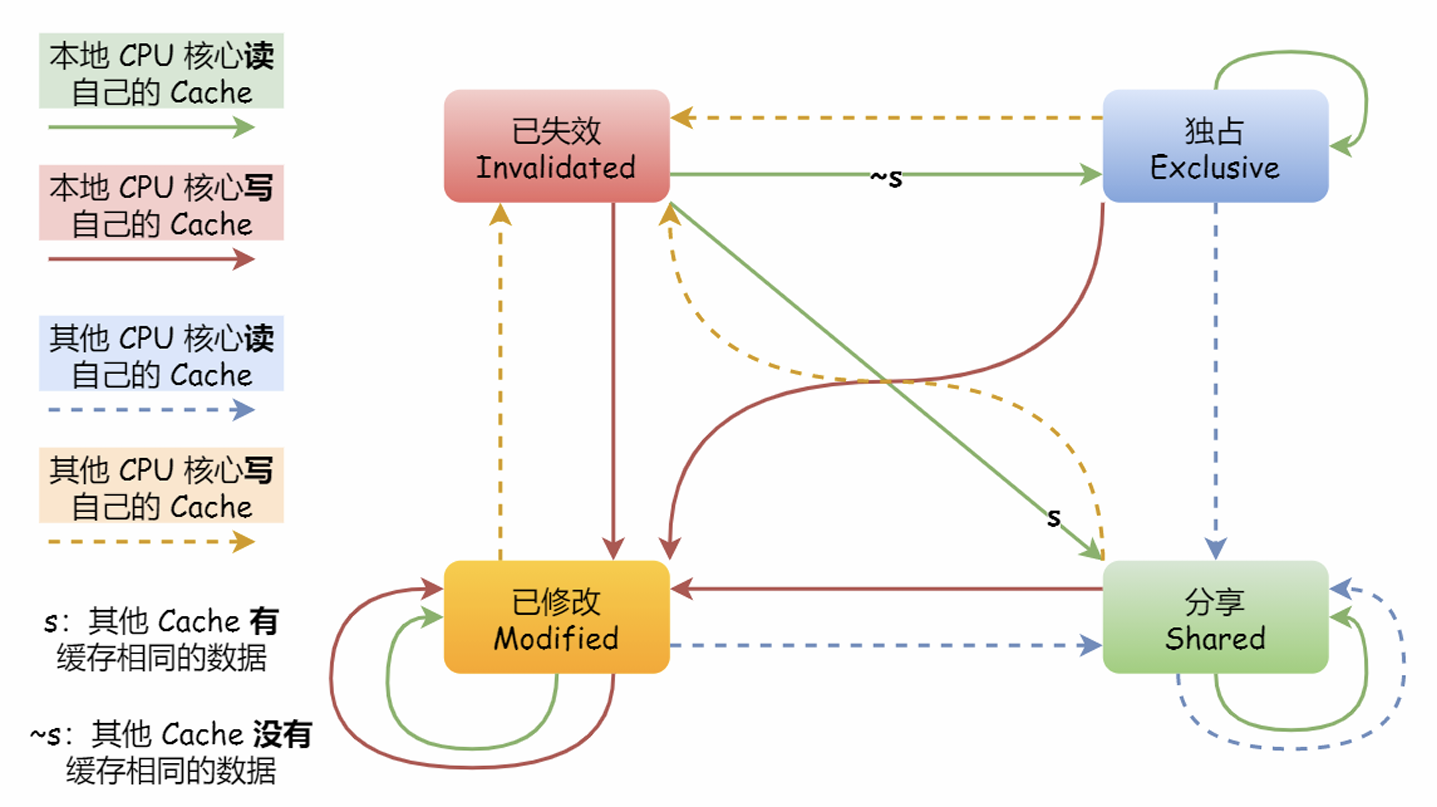
总线嗅探(Bus Snooping):CPU监听总线上的一切活动,但是不管别的核心的 Cache是否缓存相同的数据,都需要发出一个广播事件(总线负载会加大)。
MESI协议:Modified(已修改,标记为脏)、Exclusive(独占,数据干净,只在一个核心)、Shared(数据在多个核心,从内存读取到其他核心中相同的数据,标记为共享)、Invalidate(失效,一个核心修改后,广播要求其他核心设置为失效),这个协议基于总线嗅探机制实现了事务串形化。(如此也减轻了总线的带宽压力)
5. CPU是如何执行任务的
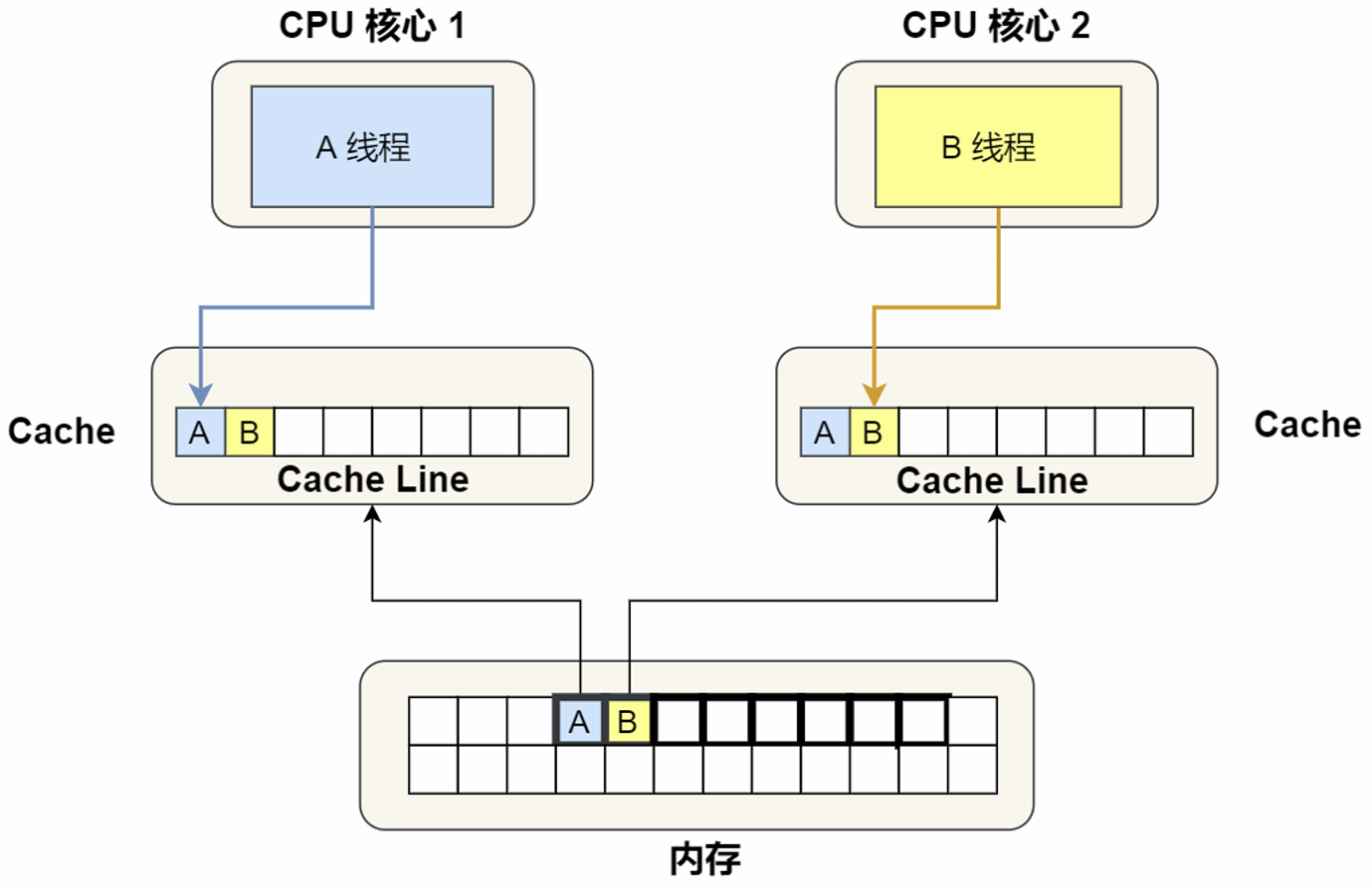
Cache的伪共享问题:
多个线程同时读写同一个Cache Line的不同变量时(独占->共享),而导致CPU Cache变为失效态的现象称为伪共享(False Sharing)。
解决:①通过__cacheline_aligned_in_smp设置Cache Line对齐地址(读成两个缓存块),②Java并发框架Disruptor字节填充。
CPU如何选择线程:
优先级:Linux中任务优先级的数值越小,优先级越高。(实时任务0~99,普通任务100~139)
Linux中的调度类:
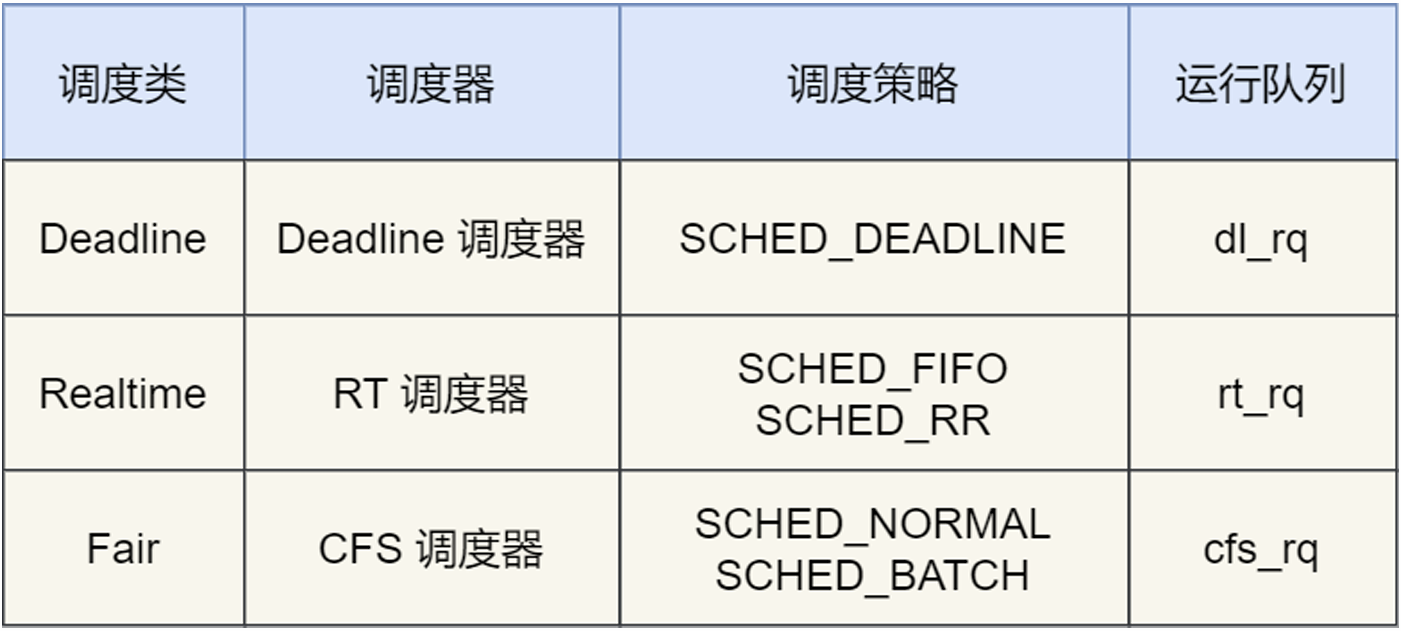
Deadline、Realtime作用于实时任务:
SCHED_DEADLINE:按照距离当前时间最近的deadline优先调度
SCHED_FIFO:先来先服务,但是可“插队”(受优先级影响)
SCHED_RR:轮询,不过还是可以“插队”
Fair调度类作用于普通任务:
SCHED_NORMAL:普通任务的调度策略
SCHED_BATCH:后台任务的调度策略
完全公平调度CFS算法:
在CFS(Completely Fair Scheduling)算法调度的时,每个任务都安排一个虚拟运行时间,运行越久vruntime越大。优先选择vruntime少的任务,在计算虚拟运行时间vruntime还要考虑普通任务的权重值。
nice级别越低,权重值就越大,vruntime越小,优先被调度。nice 值并不是表示优先级,而是表示优先级的修正数值,priority(new) = priority(old) + nice。nice调整的是普通任务的优先级,不管怎么缩小nice值(范围是-20~19),永远都是普通任务。
![]()
CPU运行队列:
每个CPU都有自己的运行队列(Run Queue, rq),用于描述在此CPU上运行的所有进程,其队列包含三个运行队列,Deadline队列dl_rq、实时任务队列rt_rq、CFS队列 cfs_rq。
其中cfs_rq是用红黑树来描述的,按vruntime大小来排序的,最左侧的叶子节点,就是下次会被调度的任务。调度类优先级如下:Deadline > Realtime > Fair,因此实时任务总是会比普通任务先执行。
软中断:
中断请求的响应程序,也就是中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度的影响。
Linux中断处理分为上半部和下半部。
上半部(硬中断)用来快速处理,一般会暂时关闭中断请求,主要负责跟硬件紧密相关的或时间敏感的
下半部(软中断)以内核线程的方式执行,延迟处理上半部未完成的工作。每个 CPU 核心都对应着一个内核线程ksoftirqd。此外,一些内核自定义事件也属于软中断,比如内核调度、RCU锁(内核里常用的一种锁)等。
这篇关于小林Coding_操作系统_读书笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








